
Embedding
Află ce sunt embedding-urile, cum funcționează și de ce sunt esențiale pentru sistemele AI. Descoperă cum textul se transformă în vectori numerici care surprind...
13 min citire

Află cum embeddingurile vectoriale permit sistemelor AI să înțeleagă sensul semantic și să asocieze conținutul cu interogările. Explorează tehnologia din spatele căutării semantice și asocierii de conținut prin AI.

Embeddingurile vectoriale sunt fundația numerică ce alimentează sistemele moderne de inteligență artificială, transformând date brute în reprezentări matematice pe care mașinile le pot înțelege și procesa. În esență, embeddingurile convertesc texte, imagini, audio și alte tipuri de conținut în șiruri de numere—de obicei de la câteva zeci la mii de dimensiuni—care surprind sensul semantic și relațiile contextuale din acele date. Această reprezentare numerică este fundamentală pentru modul în care sistemele AI realizează potrivirea conținutului, căutarea semantică și recomandările, permițând mașinilor să înțeleagă nu doar ce cuvinte sau imagini sunt prezente, ci și ce înseamnă ele cu adevărat. Fără embeddinguri, sistemele AI ar avea dificultăți în a surprinde relațiile nuanțate dintre concepte, făcându-le infrastructură esențială pentru orice aplicație AI modernă.
Transformarea datelor brute în embeddinguri vectoriale se realizează prin modele sofisticate de rețele neuronale antrenate pe seturi de date masive pentru a învăța modele și relații semnificative. Când introduci text într-un model de embedding, acesta trece prin mai multe straturi de rețele neuronale care extrag progresiv informații semantice, rezultând într-un vector de dimensiune fixă ce reprezintă esența acelui conținut. Modele populare de embedding precum Word2Vec, GloVE și BERT folosesc abordări diferite—Word2Vec utilizează rețele neuronale superficiale optimizate pentru viteză, GloVE combină factorizarea globală a matricii cu ferestre de context local, în timp ce BERT folosește arhitectura transformer pentru a înțelege contextul bidirecțional.
| Model | Tip de date | Dimensiuni | Caz de utilizare principal | Avantaj cheie |
|---|---|---|---|---|
| Word2Vec | Text (cuvinte) | 100-300 | Relații între cuvinte | Rapid, eficient |
| GloVE | Text (cuvinte) | 100-300 | Relații semantice | Combină context global și local |
| BERT | Text (propoziții/documente) | 768-1024 | Înțelegere contextuală | Conștientizare a contextului bidirecțional |
| Sentence-BERT | Text (propoziții) | 384-768 | Similaritate între propoziții | Optimizat pentru căutare semantică |
| Universal Sentence Encoder | Text (propoziții) | 512 | Sarcini cross-linguale | Indiferent de limbă |
Aceste modele produc vectori cu dimensiuni mari (adesea între 300 și 1.536 dimensiuni), unde fiecare dimensiune surprinde un aspect diferit al sensului, de la proprietăți gramaticale la relații conceptuale. Frumusețea acestei reprezentări numerice este că permite operații matematice—poți aduna, scădea și compara vectori pentru a descoperi relații invizibile în textul brut. Această fundație matematică face posibilă căutarea semantică și potrivirea inteligentă a conținutului la scară largă.
Adevărata putere a embeddingurilor apare prin similaritatea semantică, adică abilitatea de a recunoaște că termeni sau expresii diferite pot însemna, în fond, același lucru în spațiul vectorial. Când embeddingurile sunt create eficient, conceptele semantic similare se grupează natural în spațiul multidimensional—“rege” și “regină” stau aproape una de alta, la fel ca “mașină” și “vehicul”, chiar dacă sunt cuvinte diferite. Pentru a măsura această similaritate, sistemele AI folosesc metrici de distanță precum similaritatea cosinusului (măsurând unghiul dintre vectori) sau produsul scalar (măsurând magnitudine și direcție), care cuantifică cât de apropiate sunt două embeddinguri. De exemplu, o interogare despre “transport auto” va avea o similaritate cosinus mare cu documente despre “călătorii cu mașina”, permițând sistemului să asocieze conținut pe bază de sens, nu potrivire exactă de cuvinte cheie. Această înțelegere semantică deosebește căutarea AI modernă de potrivirea simplă pe cuvinte cheie, permițând sistemelor să înțeleagă intenția utilizatorului și să livreze rezultate cu adevărat relevante.
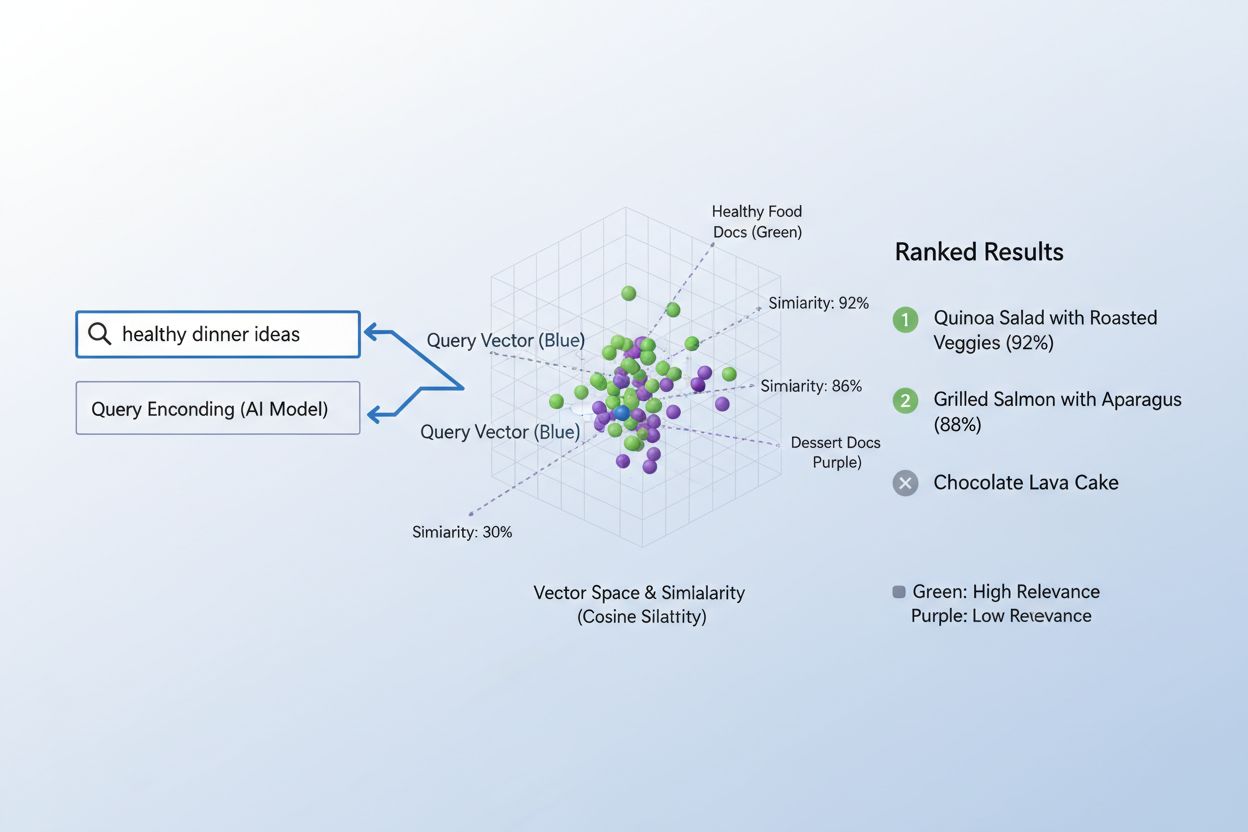
Procesul de asociere a conținutului cu interogările folosind embeddinguri urmează un flux elegant în doi pași care alimentează totul, de la motoare de căutare la sisteme de recomandare. Mai întâi, atât interogarea utilizatorului, cât și conținutul disponibil sunt convertite independent în embeddinguri folosind același model—o interogare precum “cele mai bune practici pentru machine learning” devine un vector, la fel ca fiecare articol, document sau produs din baza de date a sistemului. Apoi, sistemul calculează similaritatea dintre embeddingul interogării și embeddingurile de conținut, de obicei folosind similaritatea cosinus, care oferă un scor ce indică cât de relevant este fiecare conținut pentru interogare. Aceste scoruri sunt apoi ordonate, iar conținutul cu scorul cel mai ridicat este afișat utilizatorului ca fiind cel mai relevant. Într-un scenariu real de motor de căutare, când cauți “cum să antrenezi rețele neuronale”, sistemul codează interogarea ta, o compară cu milioane de embeddinguri de documente și returnează articole despre deep learning, optimizarea modelelor și tehnici de antrenament—toate fără să fie nevoie de potriviri exacte de cuvinte cheie. Acest proces de asociere are loc în milisecunde, fiind practic pentru aplicații în timp real cu milioane de utilizatori simultan.
Diferite tipuri de embeddinguri servesc scopuri diferite, în funcție de ceea ce dorești să asociezi sau să înțelegi. Embeddingurile de cuvinte surprind sensul fiecărui cuvânt și sunt utile pentru sarcini care necesită înțelegere semantică detaliată, în timp ce embeddingurile de propoziții și de documente agregă sensul pe segmente de text mai lungi, fiind ideale pentru asocierea interogărilor cu articole sau documente întregi. Embeddingurile de imagini reprezintă conținutul vizual numeric, permițând sistemelor să găsească imagini vizual similare sau să asocieze imagini cu descrieri textuale, în timp ce embeddingurile de utilizator și de produs surprind tipare comportamentale și caracteristici, alimentând sisteme de recomandare care sugerează produse pe baza preferințelor utilizatorului. Alegerea între aceste tipuri de embeddinguri implică compromisuri: embeddingurile de cuvinte sunt eficiente computațional dar pierd contextul, în timp ce embeddingurile de documente păstrează sensul complet dar necesită mai multă putere de procesare. Embeddingurile specializate pe domenii, ajustate pe seturi de date specifice precum literatură medicală sau documente juridice, depășesc adesea modelele generice pentru aplicații de industrie, deși necesită date suplimentare de antrenament și resurse computaționale.
În practică, embeddingurile stau la baza unora dintre cele mai influente aplicații AI pe care le folosim zilnic, de la rezultatele căutărilor la recomandările de produse online. Motoarele de căutare semantică folosesc embeddinguri pentru a înțelege intenția interogării și a afișa conținut relevant indiferent de potrivirile exacte de cuvinte cheie, în timp ce sistemele de recomandare de la Netflix, Amazon și Spotify utilizează embeddinguri de utilizator și produs pentru a prezice ce vei dori să vizionezi, cumperi sau asculți în continuare. Sistemele de moderare a conținutului folosesc embeddinguri pentru a detecta conținut dăunător comparând postările utilizatorilor cu embeddinguri ale încălcărilor cunoscute ale politicilor, iar sistemele de întrebări și răspunsuri asociază întrebările utilizatorilor cu articole relevante din baze de cunoștințe identificând conținut semantic similar. Motoarele de personalizare folosesc embeddinguri pentru a înțelege preferințele utilizatorilor și a adapta experiențele, iar sistemele de detecție a anomaliilor identifică tipare neobișnuite recunoscând când noi puncte de date se află la distanță mare de clusterele de embedding așteptate. La AmICited, folosim embeddinguri pentru a monitoriza modul în care sistemele AI sunt utilizate pe internet, asociind interogări și conținut pentru a urmări unde apare conținut generat sau asistat de AI, ajutând brandurile să-și înțeleagă amprenta AI și să se asigure că li se atribuie corect conținutul.
Implementarea embeddingurilor eficient necesită atenție la numeroase considerații tehnice care influențează atât performanța, cât și costurile. Selecția modelului este crucială—trebuie să echilibrezi calitatea semantică a embeddingurilor cu cerințele computaționale, modelele mari precum BERT oferind reprezentări mai bogate dar necesitând mai multă putere de procesare decât alternativele ușoare. Dimensionalitatea implică un compromis important: embeddingurile cu dimensiuni mari surprind mai multă nuanță dar consumă mai multă memorie și încetinesc calculele de similaritate, în timp ce embeddingurile cu dimensiuni mici sunt mai rapide dar pot pierde informații semantice importante. Pentru a gestiona potrivirea la scară mare eficient, sistemele folosesc strategii speciale de indexare precum FAISS (Facebook AI Similarity Search) sau Annoy (Approximate Nearest Neighbors Oh Yeah), care permit găsirea embeddingurilor similare în milisecunde, nu secunde, organizând vectorii în structuri arborescente sau scheme de hashing sensibile la localitate. Ajustarea fină a modelelor de embedding pe date specifice domeniului poate îmbunătăți dramatic relevanța pentru aplicații specializate, deși necesită date etichetate de antrenament și costuri computaționale suplimentare. Organizațiile trebuie să echilibreze constant viteza versus acuratețea, costul computațional versus calitatea semantică și modelele generice versus alternativele specializate, în funcție de cazurile lor de utilizare și constrângeri.
Viitorul embeddingurilor tinde spre mai multă sofisticare, eficiență și integrare cu sisteme AI mai largi, promițând capabilități și mai puternice de potrivire și înțelegere a conținutului. Embeddingurile multimodale care procesează simultan text, imagini și audio sunt în curs de apariție, permițând sistemelor să asocieze între tipuri diferite de conținut—găsind imagini relevante pentru interogări text sau invers—deschizând noi posibilități pentru descoperirea și înțelegerea conținutului. Cercetătorii dezvoltă modele de embedding tot mai eficiente care oferă calitate semantică comparabilă cu mult mai puțini parametri, făcând capabilitățile AI avansate accesibile organizațiilor mici și dispozitivelor edge. Integrarea embeddingurilor cu modelele lingvistice mari creează sisteme care nu doar asociază conținut semantic, ci și înțeleg context, nuanță și intenție la un nivel fără precedent. Pe măsură ce sistemele AI devin tot mai răspândite pe internet, abilitatea de a urmări, monitoriza și înțelege modul în care conținutul este asociat și folosit devine tot mai importantă—aici platforme precum AmICited valorifică embeddingurile pentru a ajuta organizațiile să monitorizeze prezența brandului, să urmărească tiparele de utilizare AI și să se asigure că propriul conținut este atribuit și folosit corespunzător. Convergența embeddingurilor mai bune, modelelor mai eficiente și instrumentelor sofisticate de monitorizare creează un viitor în care sistemele AI sunt mai transparente, responsabile și aliniate cu valorile umane.
Un embedding vectorial este o reprezentare numerică a datelor (text, imagini, audio) într-un spațiu cu dimensiuni mari, care surprinde sensul semantic și relațiile. Acesta transformă datele abstracte în șiruri de numere pe care mașinile le pot procesa și analiza matematic.
Embeddingurile transformă datele abstracte în numere pe care mașinile le pot procesa, permițând AI-ului să identifice tipare, similarități și relații între diferite părți de conținut. Această reprezentare matematică permite sistemelor AI să înțeleagă sensul, nu doar să potrivească cuvinte cheie.
Potrivirea pe baza cuvintelor cheie caută corespodențe exacte de cuvinte, pe când similaritatea semantică înțelege sensul. Acest lucru permite sistemelor să găsească conținut relevant chiar și fără cuvinte identice—de exemplu, să potrivească 'automobil' cu 'mașină' pe bază de relație semantică, nu potrivire exactă de text.
Da, embeddingurile pot reprezenta text, imagini, audio, profiluri de utilizator, produse și multe altele. Modele diferite de embedding sunt optimizate pentru tipuri diferite de date, de la Word2Vec pentru text la CNN pentru imagini sau spectrograme pentru audio.
AmICited folosește embeddinguri pentru a înțelege modul în care sistemele AI asociază semantic și fac referire la brandul tău pe diferite platforme și în răspunsuri AI. Acest lucru ajută la urmărirea prezenței conținutului tău în răspunsuri generate de AI și la asigurarea atribuirii corecte.
Provocările cheie includ alegerea modelului potrivit, gestionarea costurilor de calcul, manipularea datelor de dimensiuni mari, ajustarea pentru domenii specifice și echilibrarea vitezei cu acuratețea în calculele de similaritate.
Embeddingurile permit căutarea semantică, care înțelege intenția utilizatorului și returnează rezultate relevante pe baza sensului, nu doar a potrivirilor de cuvinte cheie. Astfel, sistemele de căutare pot găsi conținut conceptual apropiat chiar dacă nu conține exact termenii interogării.
Modelele lingvistice mari folosesc embeddinguri intern pentru a înțelege și genera text. Embeddingurile sunt fundamentale pentru modul în care aceste modele procesează informația, asociază conținut și generează răspunsuri contextual adecvate.
Embeddingurile vectoriale alimentează sisteme AI precum ChatGPT, Perplexity și Google AI Overviews. AmICited urmărește modul în care aceste sisteme citează și fac referire la conținutul tău, ajutându-te să înțelegi prezența brandului tău în răspunsurile generate de AI.
Află ce sunt embedding-urile, cum funcționează și de ce sunt esențiale pentru sistemele AI. Descoperă cum textul se transformă în vectori numerici care surprind...

Află cum funcționează embedding-urile în motoarele de căutare AI și modelele de limbaj. Înțelege reprezentările vectoriale, căutarea semantică și rolul lor în r...
Află cum căutarea vectorială folosește embedding-uri de învățare automată pentru a găsi elemente similare pe baza sensului, nu doar a cuvintelor-cheie exacte. Î...