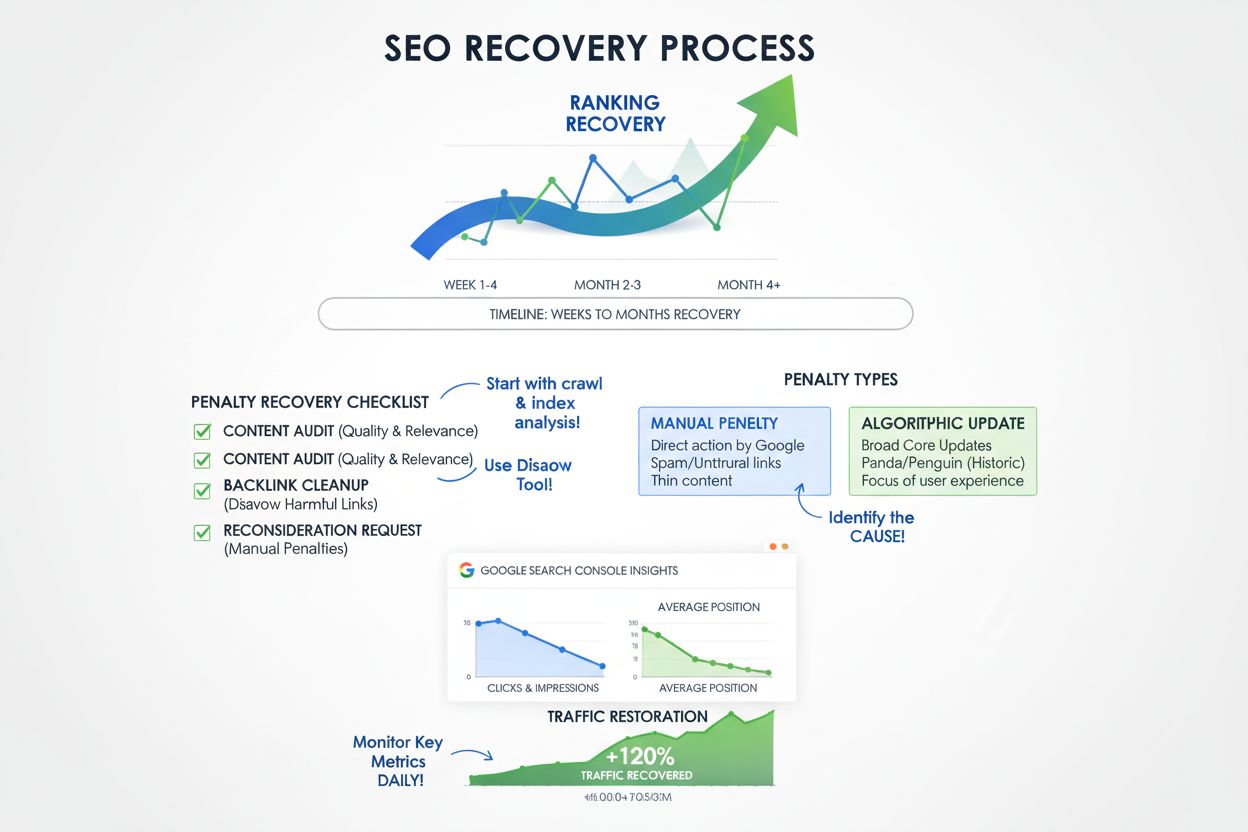
Recuperare - Recâștigarea pozițiilor după penalizare sau actualizare
Află cum să te recuperezi după penalizări Google și actualizări de algoritm. Descoperă procesul de recuperare pas cu pas, așteptările privind termenele și strat...
13 min citire

Scorarea recuperării AI este procesul de cuantificare a relevanței și calității documentelor sau pasajelor recuperate în raport cu o interogare a utilizatorului. Utilizează algoritmi sofisticați pentru a evalua sensul semantic, adecvarea contextuală și calitatea informației, determinând care surse sunt transmise modelelor de limbaj pentru generarea răspunsurilor în sistemele RAG.
Scorarea recuperării AI este procesul de cuantificare a relevanței și calității documentelor sau pasajelor recuperate în raport cu o interogare a utilizatorului. Utilizează algoritmi sofisticați pentru a evalua sensul semantic, adecvarea contextuală și calitatea informației, determinând care surse sunt transmise modelelor de limbaj pentru generarea răspunsurilor în sistemele RAG.
Scorarea recuperării AI este procesul de cuantificare a relevanței și calității documentelor sau pasajelor recuperate în raport cu o interogare sau o sarcină a utilizatorului. Spre deosebire de simpla potrivire a cuvintelor-cheie, care identifică doar suprapunerea la nivel de termeni, scorarea recuperării folosește algoritmi sofisticați pentru a evalua sensul semantic, adecvarea contextuală și calitatea informației. Acest mecanism de scorare este fundamental pentru sistemele de Generare Augmentată prin Recuperare (RAG), unde determină care surse sunt transmise modelelor de limbaj pentru generarea răspunsurilor. În aplicațiile moderne cu LLM, scorarea recuperării influențează direct acuratețea răspunsurilor, reducerea halucinațiilor și satisfacția utilizatorului, asigurând că doar cele mai relevante informații ajung la etapa de generare. Calitatea scorării recuperării este, așadar, o componentă critică a performanței și fiabilității generale a sistemului.
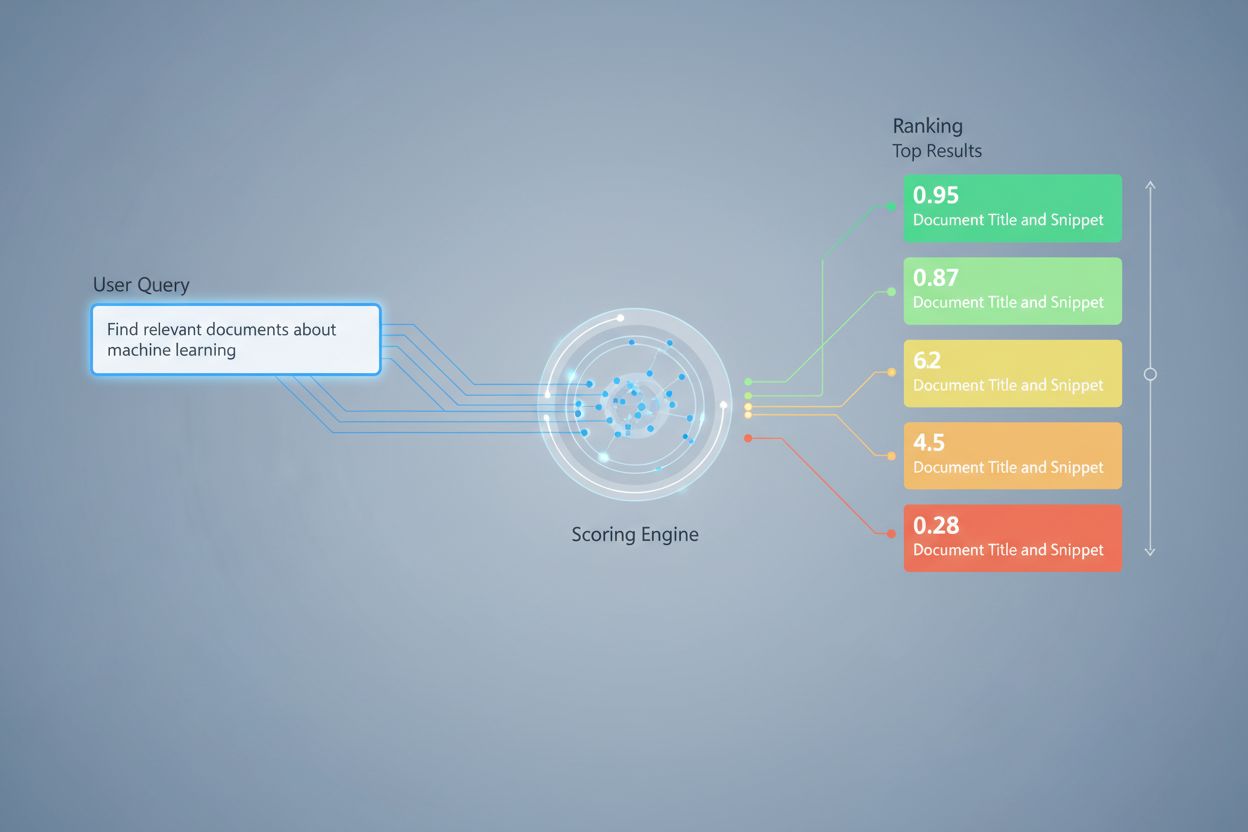
Scorarea recuperării utilizează mai multe abordări algoritmice, fiecare cu puncte forte distincte pentru diverse scenarii de utilizare. Scorarea similarității semantice folosește modele de embedding pentru a măsura alinierea conceptuală dintre interogări și documente în spațiul vectorial, captând sensul dincolo de cuvintele-cheie la suprafață. BM25 (Best Matching 25) este o funcție de clasificare probabilistică ce ia în considerare frecvența termenului, frecvența inversă a documentului și normalizarea lungimii documentului, fiind foarte eficientă pentru recuperarea tradițională de text. TF-IDF (Term Frequency-Inverse Document Frequency) pondera termenii în funcție de importanța lor în cadrul documentelor și a colecțiilor, deși îi lipsește înțelegerea semantică. Abordările hibride combină mai multe metode—cum ar fi îmbinarea scorurilor BM25 și semantice—pentru a valorifica atât semnalele lexicale, cât și cele semantice. Dincolo de metodele de scorare, metrici de evaluare precum Precision@k (procentul de rezultate de top-k relevante), Recall@k (procentul tuturor documentelor relevante găsite în top-k), NDCG (Normalized Discounted Cumulative Gain, care ține cont de poziția în clasament) și MRR (Mean Reciprocal Rank) oferă măsuri cantitative ale calității recuperării. Înțelegerea punctelor forte și a limitărilor fiecărei abordări—precum eficiența BM25 versus înțelegerea aprofundată a scorării semantice—este esențială pentru selectarea metodelor potrivite în funcție de aplicație.
| Metodă de scorare | Cum funcționează | Ideal pentru | Avantaj cheie |
|---|---|---|---|
| Similaritate semantică | Compară embedding-urile folosind similaritatea cosinusului sau alte metrici de distanță | Sens conceptual, sinonime, parafraze | Surprinde relații semantice dincolo de cuvintele-cheie |
| BM25 | Clasificare probabilistică ce ia în calcul frecvența termenului și lungimea documentului | Potrivirea expresiilor exacte, interogări bazate pe cuvinte-cheie | Rapid, eficient, dovedit în sisteme de producție |
| TF-IDF | Ponderează termenii în funcție de frecvența lor în document și raritatea în colecție | Recuperare tradițională de informații | Simplu, ușor de interpretat, ușor |
| Scorare hibridă | Combină abordările semantice și bazate pe cuvinte-cheie cu fuziune ponderată | Recuperare generală, interogări complexe | Valorifică punctele forte ale mai multor metode |
| Scorare bazată pe LLM | Folosește modele de limbaj pentru a evalua relevanța cu prompturi personalizate | Evaluare complexă a contextului, sarcini de domeniu specific | Surprinde relații semantice nuanțate |
În sistemele RAG, scorarea recuperării funcționează la mai multe niveluri pentru a asigura calitatea generării. Sistemul scorează de obicei fragmente sau pasaje individuale din documente, permițând o evaluare granulară a relevanței, în loc să trateze documentele ca unități atomice. Această scorare pe fragment permite sistemului să extragă doar cele mai relevante segmente informative, reducând zgomotul și contextul irelevant care ar putea deruta modelul de limbaj. Sistemele RAG implementează adesea praguri de scorare sau mecanisme de tăiere care filtrează rezultatele cu scoruri mici înainte de a ajunge la etapa de generare, prevenind ca sursele de calitate slabă să influențeze răspunsul final. Calitatea contextului recuperat corelează direct cu calitatea generării—fragmente cu scor mare și relevante duc la răspunsuri mai precise și fundamentate, în timp ce recuperările de calitate slabă introduc halucinații și erori factuale. Monitorizarea scorurilor de recuperare oferă semnale de avertizare timpurii pentru degradarea sistemului, fiind o metrică cheie pentru monitorizarea răspunsurilor AI și asigurarea calității în sistemele de producție.
Re-clasificarea servește ca un mecanism de filtrare suplimentară ce rafinează rezultatele inițiale ale recuperării, adesea îmbunătățind semnificativ acuratețea clasificării. După ce un recuperator inițial generează rezultate candidate cu scoruri preliminare, un re-clasificator aplică o logică de scorare mai sofisticată pentru a reordona sau filtra aceste rezultate, de obicei folosind modele mai costisitoare computațional care pot realiza o analiză mai profundă. Reciprocal Rank Fusion (RRF) este o tehnică populară ce combină clasificările mai multor recuperatori, atribuind scoruri pe baza poziției rezultatului, apoi fuzionează aceste scoruri pentru a produce un clasament unificat ce depășește adesea recuperatorii individuali. Normalizarea scorurilor devine critică la combinarea rezultatelor din metode diferite de recuperare, deoarece scorurile brute de la BM25, similaritate semantică și alte abordări operează pe scale diferite și trebuie calibrate la intervale comparabile. Abordările de recuperare în ansamblu valorifică simultan mai multe strategii de recuperare, re-clasificarea determinând ordinea finală pe baza dovezilor combinate. Această abordare multi-etapă îmbunătățește semnificativ acuratețea și robustețea clasificării comparativ cu recuperarea într-o singură etapă, în special în domenii complexe unde metodele diferite surprind semnale de relevanță complementare.
Precision@k: Măsoară proporția documentelor relevante în primele k rezultate; utilă pentru a evalua dacă rezultatele recuperate sunt de încredere (de exemplu, Precision@5 = 4/5 înseamnă 80% dintre primele 5 rezultate sunt relevante)
Recall@k: Calculează procentul tuturor documentelor relevante găsite în primele k rezultate; important pentru a asigura acoperirea completă a informațiilor relevante disponibile
Hit Rate: Metrică binară ce indică dacă cel puțin un document relevant apare în primele k rezultate; utilă pentru verificări rapide de calitate în sistemele de producție
NDCG (Normalized Discounted Cumulative Gain): Ține cont de poziția în clasament atribuind valoare mai mare documentelor relevante ce apar mai devreme; variază între 0-1 și este ideală pentru evaluarea calității clasificării
MRR (Mean Reciprocal Rank): Măsoară poziția medie a primului rezultat relevant pe mai multe interogări; utilă mai ales pentru a evalua dacă cel mai relevant document ocupă un loc fruntaș
F1 Score: Media armonică dintre precizie și recall; oferă o evaluare echilibrată când atât pozitivele false, cât și negativele false au importanță egală
MAP (Mean Average Precision): Media valorilor de precizie la fiecare poziție unde se găsește un document relevant; metrică cuprinzătoare pentru calitatea generală a clasificării pe mai multe interogări
Scorarea relevanței bazată pe LLM valorifică modelele de limbaj ca judecători ai relevanței documentelor, oferind o alternativă flexibilă la abordările algoritmice tradiționale. În această paradigmă, prompturi atent create instruiesc un LLM să evalueze dacă un pasaj recuperat răspunde unei interogări date, producând fie scoruri binare de relevanță (relevant/nu este relevant) fie scoruri numerice (de ex., pe o scară de la 1 la 5 care indică gradul de relevanță). Această abordare surprinde relații semantice nuanțate și relevanță specifică domeniului pe care algoritmii tradiționali le pot rata, în special pentru interogări complexe ce necesită înțelegere profundă. Totuși, scorarea bazată pe LLM introduce provocări, inclusiv costul computațional (inferența LLM este costisitoare față de similaritatea embedding-urilor), posibilă inconsistență între prompturi și modele diferite și nevoia de calibrare cu etichete umane pentru a asigura alinierea scorurilor cu relevanța reală. În ciuda acestor limitări, scorarea cu LLM s-a dovedit valoroasă pentru evaluarea calității sistemelor RAG și crearea de date de antrenament pentru modele de scorare specializate, fiind astfel un instrument important în monitorizarea AI pentru evaluarea calității răspunsurilor.
Implementarea unei scorări eficiente a recuperării necesită luarea în considerare atentă a mai multor factori practici. Selecția metodei depinde de cerințele cazului de utilizare: scorarea semantică excelează în surprinderea sensului dar necesită modele de embedding, în timp ce BM25 oferă viteză și eficiență pentru potrivire lexicală. Compromisul dintre viteză și acuratețe este esențial—scorarea bazată pe embedding oferă înțelegere superioară a relevanței dar implică costuri de latență, în timp ce BM25 și TF-IDF sunt mai rapide dar mai puțin sofisticate semantic. Costul computațional implică timpul de inferență al modelului, cerințele de memorie și nevoile de scalare a infrastructurii, deosebit de importante pentru sistemele de producție cu volum mare. Ajustarea parametrilor presupune setarea pragurilor, a greutăților în abordările hibride și a limitelor de re-clasificare pentru a optimiza performanța pe domenii și cazuri specifice. Monitorizarea continuă a performanței scorării prin metrici precum NDCG și Precision@k ajută la identificarea degradării în timp, permițând îmbunătățiri proactive ale sistemului și asigurând calitatea constantă a răspunsurilor în sistemele RAG de producție.
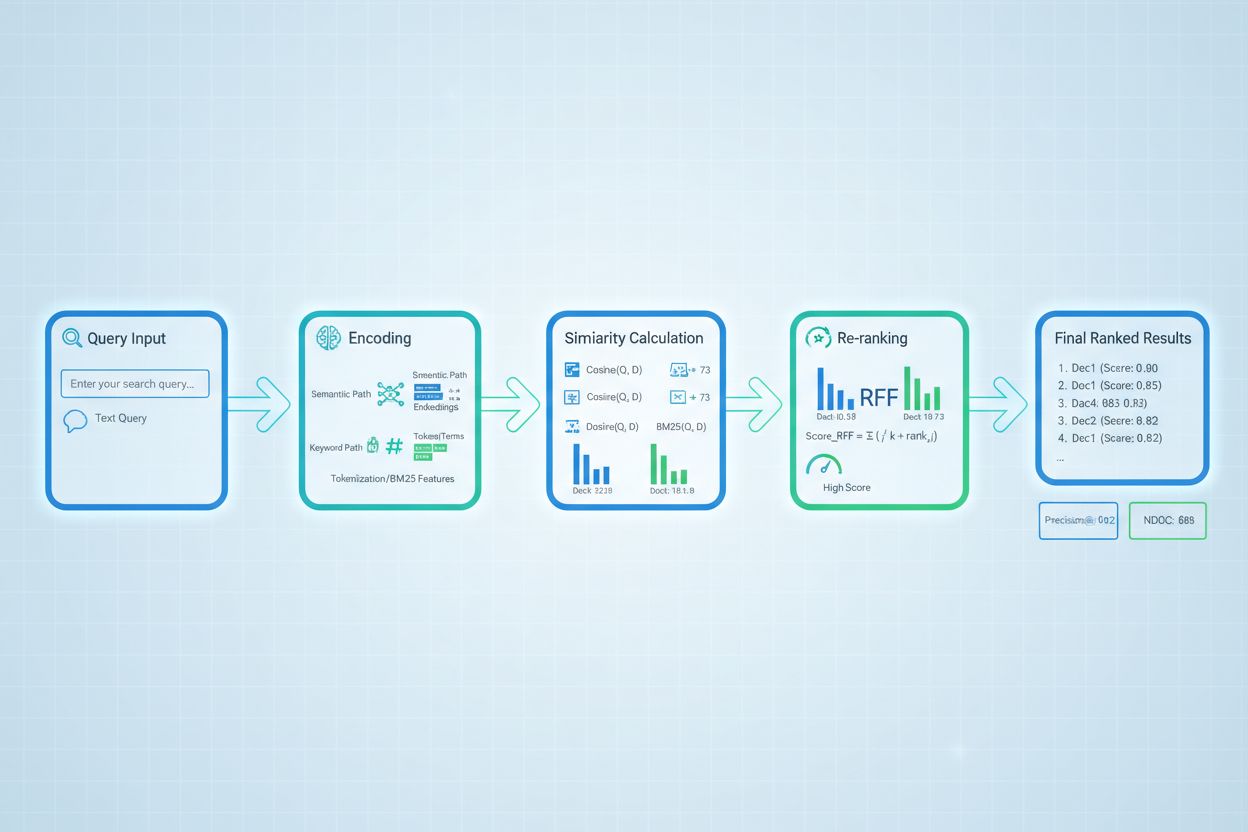
Tehnicile avansate de scorare a recuperării merg dincolo de evaluarea de bază a relevanței pentru a surprinde relații contextuale complexe. Rescrierea interogării poate îmbunătăți scorarea prin reformularea interogărilor utilizatorului în mai multe forme semantic echivalente, permițând recuperatorului să găsească documente relevante care ar putea fi omise prin potrivire literală. Hypothetical Document Embeddings (HyDE) generează documente sintetice relevante pornind de la interogări, apoi folosesc aceste ipotetice pentru a îmbunătăți scorarea recuperării prin găsirea documentelor reale similare cu conținutul relevant idealizat. Abordările multi-interogare trimit mai multe variații ale interogării către recuperatori și agregă scorurile acestora, îmbunătățind robustețea și acoperirea comparativ cu recuperarea cu o singură interogare. Modelele de scorare specifice domeniului, antrenate pe date etichetate din anumite industrii sau domenii de cunoaștere, pot atinge performanțe superioare față de modelele generale, fiind valoroase în special pentru aplicații specializate precum sisteme AI medicale sau juridice. Ajustările contextuale ale scorării țin cont de factori precum recența documentului, autoritatea sursei și contextul utilizatorului, permițând o evaluare a relevanței mai sofisticată care depășește similaritatea semantică pură pentru a integra factori de relevanță din lumea reală, critici pentru sistemele AI de producție.
Scorarea recuperării atribuie valori numerice de relevanță documentelor pe baza relației lor cu o interogare, în timp ce clasificarea ordonează documentele în funcție de aceste scoruri. Scorarea este procesul de evaluare, clasificarea este rezultatul ordonării. Ambele sunt esențiale pentru ca sistemele RAG să furnizeze răspunsuri precise.
Scorarea recuperării determină care surse ajung la modelul de limbaj pentru generarea răspunsului. O scorare de calitate asigură selectarea informațiilor relevante, reducând halucinațiile și îmbunătățind acuratețea răspunsului. O scorare slabă duce la context irelevant și răspunsuri AI nesigure.
Scorarea semantică folosește embedding-uri pentru a înțelege sensul conceptual și surprinde sinonime și concepte înrudite. Scorarea bazată pe cuvinte-cheie (precum BM25) potrivește termeni și expresii exacte. Scorarea semantică este mai bună pentru înțelegerea intenției, în timp ce scorarea cuvintelor-cheie excelează la găsirea informațiilor specifice.
Metricile cheie includ Precision@k (acuratețea rezultatelor de top), Recall@k (acoperirea documentelor relevante), NDCG (calitatea clasificării) și MRR (poziția primului rezultat relevant). Alege metricile în funcție de caz: Precision@k pentru sisteme axate pe calitate, Recall@k pentru acoperire completă.
Da, scorarea bazată pe LLM folosește modele de limbaj ca judecători ai relevanței. Această abordare surprinde relații semantice nuanțate, dar este costisitoare computațional. Este valoroasă pentru evaluarea calității RAG și crearea de date de antrenament, deși necesită calibrare cu etichete umane.
Re-clasificarea aplică o filtrare suplimentară folosind modele mai sofisticate pentru a rafina rezultatele inițiale. Tehnici precum Reciprocal Rank Fusion combină mai multe metode de recuperare, îmbunătățind acuratețea și robustețea. Re-clasificarea depășește semnificativ recuperarea într-o singură etapă în domenii complexe.
BM25 și TF-IDF sunt rapide și ușoare, potrivite pentru sisteme în timp real. Scorarea semantică necesită inferență de modele de embedding, adăugând latență. Scorarea bazată pe LLM este cea mai costisitoare. Alege în funcție de cerințele de latență și resursele computaționale disponibile.
Ia în considerare prioritățile tale: scorare semantică pentru sarcini orientate pe sens, BM25 pentru viteză și eficiență, abordări hibride pentru performanță echilibrată. Evaluează pe domeniul tău folosind metrici precum NDCG și Precision@k. Testează mai multe metode și măsoară impactul lor asupra calității finale a răspunsului.
Urmărește cum sistemele AI precum ChatGPT, Perplexity și Google AI fac referire la brandul tău și evaluează calitatea recuperării și clasificării surselor acestora. Asigură-te că conținutul tău este corect citat și clasat de sistemele AI.
Află cum să te recuperezi după penalizări Google și actualizări de algoritm. Descoperă procesul de recuperare pas cu pas, așteptările privind termenele și strat...

Află ce este Generarea Augmentată prin Recuperare (RAG), cum funcționează și de ce este esențială pentru răspunsuri AI precise. Explorează arhitectura, benefici...

Află cum scorarea relevanței conținutului folosește algoritmi AI pentru a măsura cât de bine corespunde conținutul cu interogările și intenția utilizatorilor. Î...