
Fereastră de Context Conversațional
Află ce este o fereastră de context conversațional, cum influențează răspunsurile AI și de ce contează pentru interacțiuni eficiente cu AI. Înțelege tokenii, li...
8 min citire
Încadrarea contextuală este o tehnică de optimizare a conținutului care stabilește limite clare în jurul informațiilor pentru a preveni interpretarea greșită și halucinațiile AI. Utilizează delimitatori expliciți și marcatori de context pentru a asigura că modelele AI înțeleg exact unde începe și se termină informația relevantă, prevenind generarea de răspunsuri bazate pe presupuneri sau detalii fabricate.
Încadrarea contextuală este o tehnică de optimizare a conținutului care stabilește limite clare în jurul informațiilor pentru a preveni interpretarea greșită și halucinațiile AI. Utilizează delimitatori expliciți și marcatori de context pentru a asigura că modelele AI înțeleg exact unde începe și se termină informația relevantă, prevenind generarea de răspunsuri bazate pe presupuneri sau detalii fabricate.
Încadrarea contextuală este o tehnică de optimizare a conținutului care stabilește limite clare în jurul informațiilor pentru a preveni interpretarea greșită și halucinația AI. Această metodă presupune utilizarea de delimitatori expliciți—precum etichete XML, antete markdown sau caractere speciale—pentru a marca începutul și sfârșitul unor blocuri specifice de informații, creând ceea ce experții numesc o „limită de context”. Prin structurarea prompturilor și datelor cu acești markeri clari, dezvoltatorii se asigură că modelele AI înțeleg exact unde începe și se termină informația relevantă, prevenind generarea de răspunsuri bazate pe presupuneri sau detalii fabricate. Încadrarea contextuală reprezintă o evoluție a ingineriei tradiționale de prompturi, extinzându-se în disciplina mai largă a ingineriei contextului, care se concentrează pe optimizarea tuturor informațiilor furnizate unui LLM pentru a obține rezultatele dorite. Tehnica este deosebit de valoroasă în mediile de producție unde acuratețea și consistența sunt critice, deoarece oferă ghidaje matematice și structurale ce direcționează comportamentul AI fără a necesita logică condițională complexă.
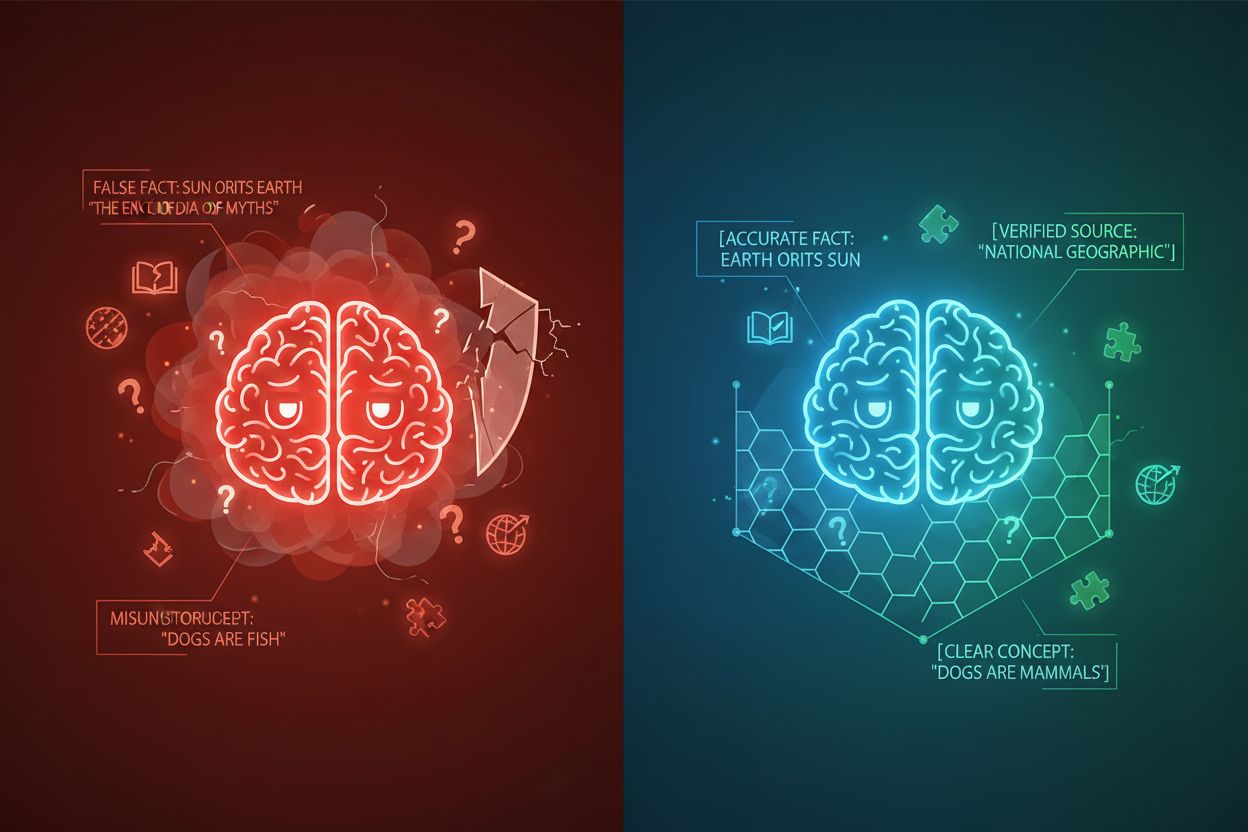
Halucinația AI apare atunci când modelele de limbaj generează răspunsuri care nu sunt bazate pe informații factuale sau pe contextul specific furnizat, rezultând în fapte false, afirmații înșelătoare sau referințe către surse inexistente. Cercetările arată că chatbot-urile inventează fapte aproximativ 27% din timp, 46% din textele lor conținând erori factuale, iar citatele jurnalistice ale ChatGPT au fost greșite în proporție de 76%. Aceste halucinații provin din mai multe surse: modelele pot învăța tipare din date de antrenament părtinitoare sau incomplete, pot înțelege greșit relația dintre tokeni sau pot duce lipsă de constrângeri suficiente care să limiteze outputurile posibile. Consecințele sunt severe în diverse industrii—în sănătate, halucinațiile pot duce la diagnosticări greșite și intervenții medicale inutile; în contexte juridice, pot rezulta citări fabricate de cazuri (așa cum s-a văzut în cazul Mata vs. Avianca, unde un avocat a fost sancționat pentru citări legale false generate de ChatGPT); în afaceri, se pierd resurse prin analize și prognoze greșite. Problema fundamentală este că, fără limite de context clare, modelele AI operează într-un vid informațional unde sunt mai predispuse să „umple golurile” cu informații plauzibile dar inexacte, tratând halucinația ca pe o caracteristică, nu ca pe o eroare.
| Tip de Halucinație | Frecvență | Impact | Exemplu |
|---|---|---|---|
| Inexactități factuale | 27-46% | Răspândirea dezinformării | Caracteristici false de produs |
| Fabricarea surselor | 76% (citate) | Pierderea credibilității | Citări inexistente |
| Concepte înțelese greșit | Variabil | Analiză incorectă | Precedente juridice greșite |
| Tipare părtinitoare | Permanent | Outputuri discriminatorii | Răspunsuri stereotipice |
Eficiența încadrării contextuale se bazează pe cinci principii fundamentale:
Utilizarea Delimitatorilor: Folosește markeri consistenți și neambigui (etichete XML precum <context>, antete markdown sau caractere speciale) pentru a delimita clar blocurile de informații și pentru a preveni confuzia modelului între surse de date sau tipuri de instrucțiuni diferite.
Gestionarea Ferestrei de Context: Alocă strategic tokenii între instrucțiunile de sistem, inputurile utilizatorului și cunoștințele recuperate, asigurându-te că cele mai relevante informații ocupă bugetul limitat de atenție al modelului, în timp ce detaliile mai puțin critice sunt filtrate sau recuperate la nevoie.
Ierarhizarea Informațiilor: Stabilește niveluri clare de prioritate pentru diferite tipuri de informații, semnalând modelului ce date trebuie tratate ca surse autoritare și care sunt context suplimentar, prevenind acordarea aceleiași greutăți informațiilor primare și secundare.
Definirea Limitelor: Specifică explicit ce informații ar trebui să ia în considerare modelul și ce să ignore, creând opriri ferme care împiedică modelul să extrapoleze dincolo de datele furnizate sau să facă presupuneri despre informații nespecificate.
Markeri de Scop: Utilizează elemente structurale pentru a indica scopul instrucțiunilor, exemplelor și datelor, clarificând dacă ghidajul se aplică global, unor secțiuni specifice sau doar anumitor tipuri de întrebări.
Implementarea încadrării contextuale necesită atenție la modul în care informația este structurată și prezentată modelelor AI. Formatarea structurată a inputului folosind scheme JSON sau XML oferă definiții explicite de câmpuri care ghidează comportamentul modelului—de exemplu, încadrând întrebările utilizatorului în etichete <user_query> și outputurile așteptate în <expected_output>, se creează limite neambigue. Prompturile sistemului ar trebui organizate în secțiuni distincte folosind antete markdown sau etichete XML: <background_information>, <instructions>, <tool_guidance>, și <output_description> servesc fiecare scopuri specifice și ajută modelul să înțeleagă ierarhia informațională. Exemplele few-shot trebuie să includă context încadrat, arătând exact cum ar trebui modelul să structureze răspunsurile, cu delimitatori clari între inputuri și outputuri. Definițiile de instrumente beneficiază de descrieri explicite de parametri și constrângeri de utilizare, prevenind folosirea greșită sau aplicarea instrumentelor în afara scopului lor. Sistemele de Generare cu Recuperare (RAG) pot implementa încadrări contextuale încadrând documentele recuperate în markeri de sursă (<source>document_name</source>) și folosind scoruri de grounding pentru a verifica dacă răspunsurile generate rămân în limitele informațiilor recuperate. De exemplu, funcția de delimitare a contextului din CustomGPT funcționează prin antrenarea modelelor exclusiv pe seturi de date încărcate, asigurând că răspunsurile nu depășesc niciodată baza de cunoștințe furnizată—o implementare practică a încadrării contextuale la nivel arhitectural.
Deși încadrările contextuale prezintă similarități cu alte tehnici, ele ocupă o poziție distinctă în peisajul ingineriei AI. Ingineria de prompturi de bază se concentrează în principal pe crearea de instrucțiuni și exemple eficiente, dar îi lipsește abordarea sistematică de gestionare a tuturor elementelor de context pe care o oferă încadrările contextuale. Ingineria contextului, disciplina mai largă, include încadrările contextuale ca un component între multe altele—cuprinde optimizarea prompturilor, designul instrumentelor, managementul memoriei și recuperarea dinamică a contextului, fiind astfel un supraset față de abordarea mai focalizată a încadrării contextuale. Urmărirea simplă a instrucțiunilor se bazează pe abilitatea modelului de a înțelege directive în limbaj natural fără delimitări structurale explicite, ceea ce eșuează adesea când instrucțiunile sunt complexe sau modelul întâlnește situații ambigue. Ghidajele și sistemele de validare operează la nivelul outputului, verificând răspunsurile după generare, în timp ce încadrările contextuale acționează la nivelul inputului pentru a preveni halucinațiile din start. Diferența cheie este că încadrările contextuale sunt preventive și structurale—modelează peisajul informațional în care operează modelul—nu corective sau reactive, ceea ce le face mai eficiente și fiabile pentru menținerea acurateței în sistemele de producție.
Încadrarea contextuală oferă valoare măsurabilă în diverse aplicații. Chatbot-urile pentru servicii clienți folosesc limite de context pentru a restricționa răspunsurile la baze de cunoștințe aprobate de companie, prevenind inventarea de caracteristici de produs sau promisiuni neautorizate. Sistemele de analiză juridică a documentelor încadrează jurisprudența relevantă, legile și precedentele, asigurând că AI face referire doar la surse verificate și nu fabrică citări legale. Sistemele AI medicale implementează limite stricte de context în jurul ghidurilor clinice, datelor pacienților și protocoalelor aprobate de tratament, prevenind halucinațiile periculoase care pot dăuna pacienților. Platformele de generare de conținut folosesc încadrări contextuale pentru a impune reguli de brand, cerințe de ton și restricții factuale, asigurând alinierea conținutului generat cu standardele organizației. Instrumentele de cercetare și analiză încadrează sursele primare, seturile de date și informațiile verificate, permițând AI-ului să sintetizeze concluzii cu păstrarea atribuirii clare și prevenind invenția de statistici sau studii false. AmICited.com exemplifică acest principiu monitorizând modul în care sistemele AI citează și fac referire la branduri în GPT-uri, Perplexity și Google AI Overviews—practic, urmărind dacă modelele AI rămân în limitele adecvate de context când discută companii sau produse specifice, ajutând organizațiile să înțeleagă dacă AI-ul halucinează despre brandul lor sau reprezintă corect informațiile acestuia.
Implementarea cu succes a încadrării contextuale necesită respectarea unor bune practici dovedite:
Începe cu Context Minim: Pornește de la cel mai mic set posibil de informații necesare pentru răspunsuri corecte, extinzând doar când testarea evidențiază lacune, prevenind poluarea contextului și păstrând focusul modelului.
Folosește Tipare Consistente de Delimitatori: Stabilește și menține convenții uniforme de delimitare în întregul sistem, facilitând recunoașterea limitelor de către model și reducând confuzia cauzată de formatare inconsistentă.
Testează și Validează Limitele: Testează sistematic dacă modelul respectă limitele definite încercând să-l provoci să le depășească, identificând și corectând eventualele breșe înainte de implementare.
Monitorizează Derapajul de Context: Urmărește continuu dacă răspunsurile modelului rămân în limitele dorite în timp, deoarece comportamentul se poate schimba în funcție de patternurile de input sau pe măsură ce evoluează bazele de cunoștințe.
Implementează Buclă de Feedback: Creează mecanisme prin care utilizatorii sau evaluatori umani să poată semnala cazurile în care modelul a depășit limitele, folosind acest feedback pentru a rafina definițiile contextului și a îmbunătăți performanța viitoare.
Versionează Definițiile de Context: Tratează limitele de context ca pe cod, menținând istoric de versiuni și documentație a modificărilor, pentru a putea reveni la o variantă anterioară dacă noile limite produc rezultate mai slabe.
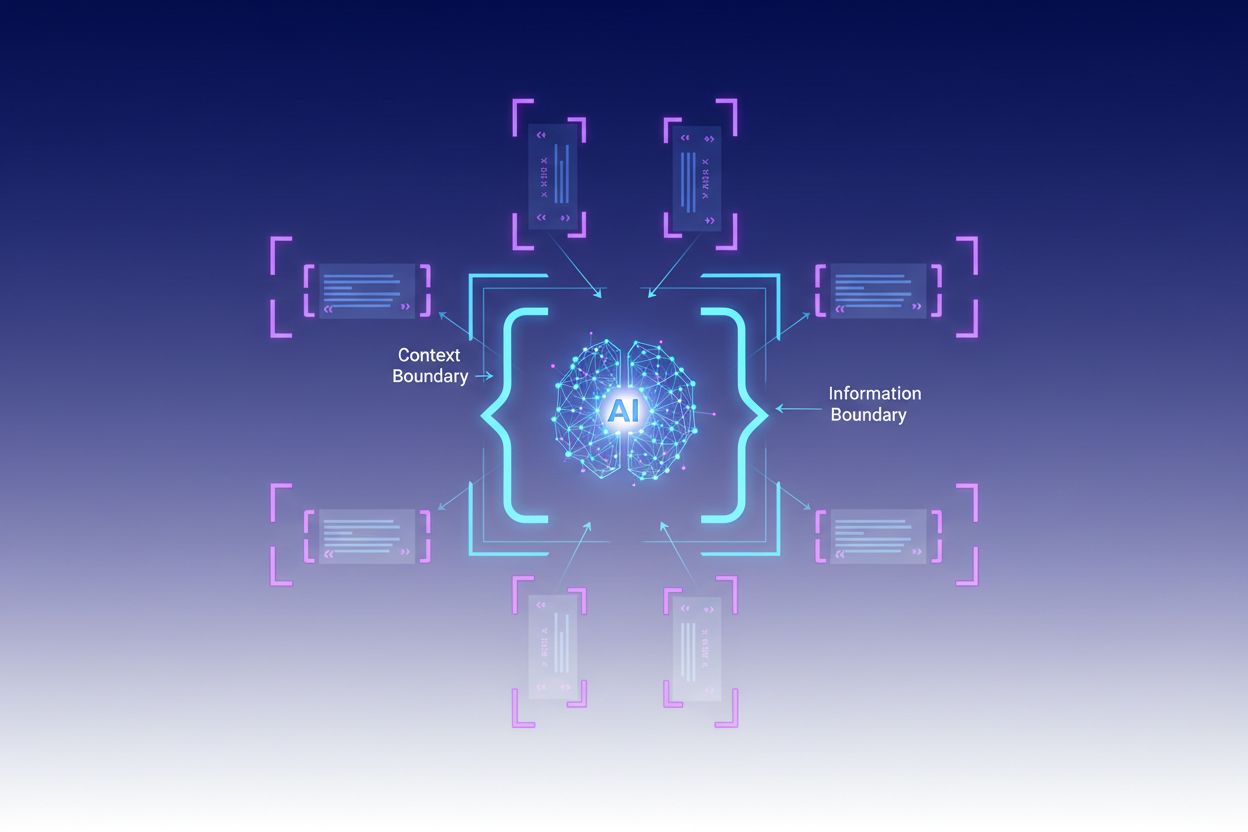
Mai multe platforme au integrat capabilități de încadrări contextuale în ofertele lor de bază. CustomGPT.ai implementează limite de context prin funcția de „context boundary”, care acționează ca un zid protector, asigurând că AI-ul folosește doar datele furnizate de utilizator, fără a accesa cunoștințe generale sau a fabrica informații—această abordare s-a dovedit eficientă pentru organizații precum MIT, care cer acuratețe absolută în livrarea cunoștințelor. Claude de la Anthropic pune accent pe principiile ingineriei contextului, oferind documentație detaliată despre structurarea prompturilor, gestionarea ferestrei de context și implementarea de ghidaje care mențin răspunsurile în limitele definite. AWS Bedrock Guardrails oferă verificări automate de raționament care validează conținutul generat pe baza unor reguli matematice sau logice, cu scoruri de grounding ce indică dacă răspunsurile rămân în sursa originală (scoruri peste 0,85 fiind necesare pentru aplicații financiare). Shelf.io furnizează soluții RAG cu capabilități de management al contextului, permițând organizațiilor să implementeze generare cu recuperare menținând limite stricte asupra informațiilor accesate și referențiate de model. AmICited.com joacă un rol complementar, monitorizând modul în care sistemele AI citează și fac referire la brandul tău pe multiple platforme AI, astfel încât să poți înțelege dacă modelele AI respectă limitele adecvate de context când discută despre organizația ta sau rămân în informații corecte și verificate despre brandul tău—practic, oferind vizibilitate asupra eficienței încadrării contextuale în mediul real.
Ingineria de prompturi se concentrează în principal pe crearea de instrucțiuni și exemple eficiente, în timp ce încadrările contextuale reprezintă o abordare sistematică de gestionare a tuturor elementelor de context prin delimitatori expliciți și limite clare. Încadrarea contextuală este mai structurată și preventivă, acționând la nivelul inputului pentru a preveni halucinațiile înainte ca acestea să apară, pe când ingineria de prompturi este mai largă și include diverse tehnici de optimizare.
Încadrarea contextuală previne halucinațiile prin stabilirea unor limite clare ale informațiilor, utilizând delimitatori precum etichetele XML sau antetele markdown. Acest lucru spune modelului AI exact ce informație trebuie să ia în considerare și ce să ignore, prevenind fabricarea detaliilor sau asumarea unor informații nespecificate. Limitând atenția modelului la limitele definite, se reduce probabilitatea generării de fapte false sau surse inexistente.
Delimitatorii comuni includ etichete XML (precum
Principiile încadrării contextuale pot fi aplicate majorității modelelor moderne de limbaj, deși eficacitatea variază. Modelele antrenate cu abilități mai bune de urmărire a instrucțiunilor (precum Claude, GPT-4 și Gemini) tind să respecte limitele mai fiabil. Tehnica funcționează cel mai bine când este combinată cu modele care suportă outputuri structurate și au fost antrenate pe date diverse, bine structurate.
Începe prin organizarea prompturilor sistemului în secțiuni distincte folosind delimitatori clari. Structurează inputurile și outputurile folosind scheme JSON sau XML. Utilizează tipare consistente de delimitatori peste tot. Implementează exemple few-shot care arată modelului exact cum să respecte limitele. Testează extensiv pentru a te asigura că modelul respectă limitele definite și monitorizează performanța în timp pentru a surprinde eventualul derapaj de context.
Încadrarea contextuală poate crește ușor consumul de tokeni datorită delimitatorilor suplimentari și markerilor structurali, însă aceasta este de obicei compensată de acuratețea îmbunătățită și reducerea halucinațiilor. Tehnica, de fapt, îmbunătățește eficiența prin prevenirea consumului de tokeni pentru informații fabricate. În sistemele de producție, câștigurile de acuratețe depășesc cu mult costul minim de tokeni suplimentari.
Încadrările contextuale și RAG sunt tehnici complementare. RAG recuperează informații relevante din surse externe, în timp ce încadrările contextuale se asigură că modelul rămâne în limitele acelor informații recuperate. Împreună, creează un sistem puternic în care modelul poate accesa cunoștințe externe fiind constrâns să facă referire doar la surse verificate și recuperate.
Mai multe platforme oferă suport integrat: CustomGPT.ai oferă funcționalități de delimitare a contextului, Claude de la Anthropic pune la dispoziție documentație pentru ingineria contextului și suport pentru outputuri structurate, AWS Bedrock Guardrails include verificări automate de raționament, iar Shelf.io oferă RAG cu management de context. AmICited.com monitorizează modul în care sistemele AI citează brandul tău, ajutând la verificarea eficienței încadrărilor contextuale.
Încadrarea contextuală asigură că sistemele AI oferă informații corecte despre brandul tău. Folosește AmICited pentru a urmări modul în care modelele AI citează și fac referire la conținutul tău în GPT-uri, Perplexity și Google AI Overviews.
Află ce este o fereastră de context conversațional, cum influențează răspunsurile AI și de ce contează pentru interacțiuni eficiente cu AI. Înțelege tokenii, li...

Află ce sunt ferestrele de context în modelele de limbaj AI, cum funcționează, impactul lor asupra performanței modelelor și de ce contează pentru aplicațiile b...

Fereastra de context explicată: numărul maxim de tokeni pe care un LLM îi poate procesa simultan. Află cum influențează ferestrele de context acuratețea AI, hal...