
Ako identifikovať AI crawlerov vo vašich serverových logoch
Naučte sa identifikovať a monitorovať AI crawlery ako GPTBot, ClaudeBot a PerplexityBot vo vašich serverových logoch. Kompletný sprievodca s user-agent reťazcam...
8 min čítania

Zistite, ako vykonať audit prístupu AI crawlerov na vašej webstránke. Objavte, ktoré roboty vidia váš obsah a opravte prekážky, ktoré bránia AI vo viditeľnosti v ChatGPT, Perplexity a ďalších AI vyhľadávačoch.
Prostredie vyhľadávania a objavovania obsahu sa dramaticky mení. S raketovým rastom AI vyhľadávacích nástrojov ako ChatGPT, Perplexity a Google AI Overviews je viditeľnosť vášho obsahu pre AI crawlery rovnako kritická ako tradičná optimalizácia pre vyhľadávače. Ak AI roboty nemajú prístup k vášmu obsahu, vaša stránka je neviditeľná pre milióny používateľov, ktorí tieto platformy používajú na získavanie odpovedí. Hrá sa o veľa: zatiaľ čo Google sa na vašu stránku môže vrátiť, keď niečo zlyhá, AI crawlery fungujú podľa iného princípu—a zmeškanie toho prvého dôležitého crawlovania môže znamenať mesiace strateného dosahu a nevyužitých príležitostí na citácie, návštevnosť a budovanie autority značky.
AI crawlery fungujú podľa zásadne odlišných pravidiel než Google a Bing roboty, na ktoré ste roky optimalizovali. Najzásadnejší rozdiel: AI crawlery nerenderujú JavaScript, teda dynamický obsah načítaný cez klientské skripty je pre ne neviditeľný—na rozdiel od sofistikovaných schopností Google. Navyše AI crawlery navštevujú stránky s oveľa vyššou frekvenciou, niekedy až 100-násobne častejšie ako tradičné vyhľadávače, čo predstavuje príležitosti aj výzvy pre serverové zdroje. Na rozdiel od Google nemajú AI crawlery trvalý index, ktorý sa obnovuje; crawlujú na požiadanie, keď používateľ zadá dopyt do ich systému. Znamená to, že neexistuje front na reindexáciu, žiadna Search Console na žiadosť o opätovné prehľadanie a žiadna druhá šanca, ak vaša stránka nezanechá dobrý dojem hneď na prvýkrát. Pochopenie týchto rozdielov je kľúčové pre optimalizáciu obsahu.
| Funkcia | AI crawlery | Tradičné roboty |
|---|---|---|
| JavaScript renderovanie | Nie (iba statické HTML) | Áno (plné renderovanie) |
| Frekvencia crawlovania | Veľmi vysoká (100x+ častejšie) | Stredná (týždenne/mesačne) |
| Schopnosť reindexácie | Žiadna (iba na požiadanie) | Áno (priebežné aktualizácie) |
| Požiadavky na obsah | Čisté HTML, schéma značkovanie | Flexibilné (zvládne dynamický obsah) |
| Blokovanie podľa User-Agent | Špecifické podľa bota (GPTBot, ClaudeBot, atď.) | Všeobecné (Googlebot, Bingbot) |
| Stratégia cachovania | Krátkodobé snímky | Dlhodobá údržba indexu |
Váš obsah môže byť pre AI crawlery neviditeľný z dôvodov, ktoré ste možno nikdy nezvážili. Tu sú hlavné prekážky, ktoré bránia AI robotom v prístupe a pochopení vášho obsahu:
Súbor robots.txt je hlavný mechanizmus na riadenie toho, ktoré AI roboty majú prístup k vášmu obsahu, a funguje cez špecifické pravidlá User-Agent pre jednotlivé crawlery. Každá AI platforma používa vlastný user-agent reťazec—GPTBot od OpenAI, ClaudeBot od Anthropic, PerplexityBot od Perplexity—a každému môžete povoliť alebo zakázať prístup samostatne. Táto detailná kontrola vám umožňuje rozhodnúť, ktorým AI systémom dovolíte trénovať na vašom obsahu alebo ho citovať, čo je dôležité pre ochranu dôverných informácií alebo pri konkurenčných obavách. Množstvo webov však nevedomky blokuje AI crawlery príliš všeobecnými pravidlami, ktoré boli určené pre staršie roboty, alebo vôbec správne pravidlá nezavádza.
Takto môžete nakonfigurovať robots.txt pre rôzne AI roboty:
# Povoliť GPTBot od OpenAI
User-agent: GPTBot
Allow: /
# Zablokovať ClaudeBot od Anthropic
User-agent: ClaudeBot
Disallow: /
# Povoliť Perplexity, ale obmedziť niektoré adresáre
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Predvolené pravidlo pre všetkých ostatných robotov
User-agent: *
Allow: /
Na rozdiel od Google, ktorý vašu stránku neustále prehľadáva a reindexuje, AI crawlery fungujú na princípe jednej šance—navštívia vás v momente, keď používateľ zadá dopyt, a ak váš obsah nie je v tej chvíli prístupný, príležitosť je preč. Tento zásadný rozdiel znamená, že vaša stránka musí byť technicky pripravená od prvého dňa; nie je žiadne prechodné obdobie ani druhá šanca opraviť chyby pred stratou viditeľnosti. Zlý prvý crawl—kvôli problémom s JavaScriptom, chýbajúcemu schéma značkovaniu alebo serverovým chybám—môže spôsobiť, že váš obsah bude z AI odpovedí vylúčený na celé týždne či mesiace. Neexistuje manuálna možnosť reindexácie, žiadne tlačidlo „Požiadať o indexáciu“ v konzole, preto je proaktívne monitorovanie a optimalizácia nevyhnutnosťou. Tlak byť pripravený hneď na prvýkrát je väčší než kedykoľvek predtým.
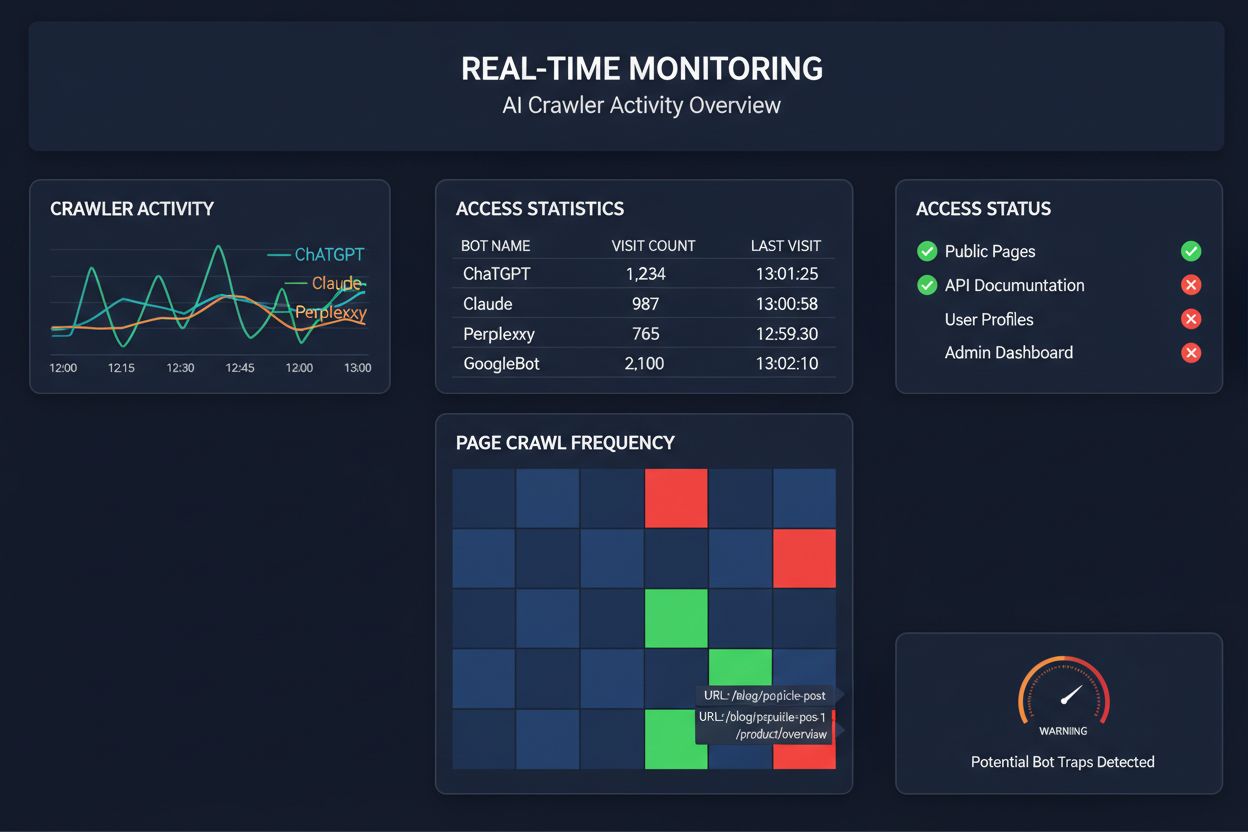
Spoliehať sa na plánované crawlery pri monitorovaní AI prístupu je ako kontrolovať dom, či nehorí, raz za mesiac—zmeškáte tie kritické momenty, keď nastane problém. Monitorovanie v reálnom čase zachytí chyby v okamihu, keď sa stanú, takže môžete reagovať skôr, než sa váš obsah stane pre AI systémy neviditeľným. Plánované audity (typicky týždenné či mesačné) vytvárajú nebezpečné slepé miesta, kde môže vaša stránka zlyhávať pre AI crawlerov celé dni bez vášho vedomia. Riešenia v reálnom čase neustále sledujú správanie crawlerov, upozorňujú vás na zlyhania JavaScriptu, chybné schéma značkovanie, blokovanie firewallom alebo serverové problémy hneď, ako sa objavia. Tento proaktívny prístup mení audit z reaktívnej kontroly na aktívne riadenie viditeľnosti. Pri tom, ako je AI crawlerová návštevnosť až 100-násobne vyššia než pri tradičných vyhľadávačoch, môže stáť aj niekoľko hodín nedostupnosti veľa.
Niekoľko platforiem dnes ponúka špecializované nástroje na monitorovanie a optimalizáciu prístupu AI crawlerov. Cloudflare AI Crawl Control poskytuje správu AI robotov na úrovni infraštruktúry, kde môžete nastaviť limity a prístupové pravidlá. Conductor ponúka komplexné prehľadové dashboardy, ktoré sledujú interakcie rôznych AI crawlerov s vaším obsahom. Elementive sa zameriava na technické SEO audity so špecifickým dôrazom na potreby AI crawlerov. AdAmigo a MRS Digital poskytujú špecializované poradenstvo a monitoring pre AI viditeľnosť. Pre nepretržité monitorovanie v reálnom čase, zamerané práve na AI crawlerov a upozorňovanie na chyby skôr, než ovplyvnia viditeľnosť, však vyniká AmICited ako dedikované riešenie. AmICited sa špecializuje na sledovanie, ktoré AI systémy pristupujú k vášmu obsahu, ako často crawlú a či narážajú na technické prekážky. Tento špecifický pohľad na správanie AI crawlerov—na rozdiel od tradičných SEO metrík—robí z AmICitedu kľúčový nástroj pre organizácie, ktoré to s AI viditeľnosťou myslia vážne.
Komplexný audit AI crawlerov si vyžaduje systematický prístup. Krok 1: Stanovte východiskový stav kontrolou aktuálneho robots.txt a určením, ktorým AI robotom povolujete alebo blokujete prístup. Krok 2: Auditujte technickú infraštruktúru testovaním prístupnosti webu pre roboty bez JavaScriptu, kontrolou odozvy servera a overením, že kľúčový obsah je podávaný v statickom HTML. Krok 3: Implementujte a overte schéma značkovanie naprieč obsahom, zabezpečte správne štruktúrované údaje o autorstve, dátume publikácie, type obsahu a ďalších metadátach v JSON-LD formáte. Krok 4: Monitorujte správanie crawlerov pomocou nástrojov ako AmICited na sledovanie, ktoré AI roboty pristupujú na váš web, ako často a či narážajú na chyby. Krok 5: Analyzujte výsledky vyhodnotením crawl logov, identifikovaním vzorcov zlyhaní a stanovením priorít opráv podľa vplyvu. Krok 6: Opravte zistené chyby začnite s najdôležitejšími - problémy s JavaScriptom, chýbajúcim schéma značkovaním - potom pokračujte sekundárnymi optimalizáciami. Krok 7: Zaveste priebežné monitorovanie na zachytenie nových problémov pred ovplyvnením viditeľnosti, nastavte upozornenia na crawl zlyhania alebo blokovanie prístupu.
Na zlepšenie prístupu AI crawlerov netreba hneď celkovú prestavbu—niekoľko zásadných opatrení môžete zaviesť rýchlo. Podávajte kľúčový obsah v čistom HTML namiesto spoliehania sa na JavaScript; ak JavaScript musíte použiť, zabezpečte, aby dôležité texty a metadáta boli už v úvodnom HTML. Doplňte komplexné schéma značkovanie v JSON-LD formáte—vrátane schémy článku, údajov o autorovi, dátume publikácie a vzťahoch obsahu—AI crawlery tak lepšie pochopia kontext a správne priradia autorstvo. Zabezpečte jasné informácie o autorstve cez schéma značkovanie a byline, keďže AI systémy čoraz viac preferujú dôveryhodné zdroje. Monitorujte a optimalizujte Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift), lebo pomalé stránky môžu crawlery opustiť skôr, než ich spracujú. Skontrolujte a aktualizujte robots.txt, aby ste neblokovali AI roboty, ktorým chcete umožniť prístup. Opravte technické chyby ako reťazce presmerovaní, nefunkčné odkazy a serverové chyby, ktoré by mohli spôsobiť, že crawlery váš web opustia počas crawlovania.
Nie všetky AI crawlery slúžia na to isté a pochopenie týchto rozdielov vám umožní lepšie rozhodovať o kontrole prístupu. GPTBot (OpenAI) slúži najmä na zber trénovacích dát a zlepšovanie modelov, čo je dôležité, ak chcete, aby váš obsah ovplyvnil odpovede ChatGPT. OAI-SearchBot (OpenAI) crawlje špeciálne kvôli citovaniu vo vyhľadávaní, teda je zodpovedný za zahrnutie vášho obsahu do odpovedí ChatGPT prepojených s vyhľadávaním. ClaudeBot (Anthropic) plní podobnú funkciu pre asistentku Claude od Anthropic. PerplexityBot (Perplexity) crawlje kvôli citáciám v AI vyhľadávači Perplexity, ktorý sa stal významným zdrojom návštevnosti pre mnohých publisherov. Každý robot má iné crawl vzorce, frekvenciu a účel—niektoré sú zamerané na trénovanie dát, iné na reálne citácie vo vyhľadávaní. Rozhodnutie, ktoré boty povolíte alebo zablokujete, by malo vychádzať zo stratégie vášho obsahu: ak chcete citácie vo výsledkoch AI vyhľadávania, povoľte roboty určené na vyhľadávanie; ak vás znepokojuje využitie na trénovanie, môžete zablokovať roboty na zber dát a povoliť len tie pre vyhľadávanie. Tento jemný prístup k správe robotov je oveľa sofistikovanejší než tradičný prístup „povoliť všetko“ alebo „zablokovať všetko“.
Audit AI crawlerov je komplexné posúdenie prístupnosti vašej webstránky pre AI roboty ako ChatGPT, Claude a Perplexity. Identifikuje technické prekážky, problémy s JavaScript renderovaním, chýbajúce schéma značkovanie a ďalšie faktory, ktoré bránia AI crawlerom v prístupe a pochopení vášho obsahu. Audit poskytuje konkrétne odporúčania, ako zlepšiť vašu viditeľnosť vo vyhľadávačoch a odpovediach poháňaných AI.
Odporúčame vykonávať komplexný audit aspoň štvrťročne, prípadne vždy, keď urobíte významné zmeny v technickej infraštruktúre webu, štruktúre obsahu alebo v robots.txt súbore. Ideálne je však nepretržité monitorovanie v reálnom čase, ktoré okamžite zachytí vzniknuté problémy. Mnohé organizácie používajú automatizované monitorovacie nástroje, ktoré ich v reálnom čase upozornia na zlyhanie crawlova, pričom štvrťročne dopĺňajú hĺbkovými auditmi.
Povolenie AI crawlerov znamená, že váš obsah môže byť prístupný, analyzovaný a potenciálne citovaný AI systémami, čo zvyšuje vašu viditeľnosť v AI generovaných odpovediach a odporúčaniach. Blokovanie AI crawlerov im bráni v prístupe k vášmu obsahu, čím chránite dôverné informácie, ale zároveň znižujete svoju viditeľnosť vo výsledkoch AI vyhľadávania. Správna voľba závisí od vašich obchodných cieľov, citlivosti obsahu a konkurenčného postavenia.
Áno, určite. Váš robots.txt súbor umožňuje detailnú kontrolu pomocou pravidiel User-Agent. Môžete zablokovať GPTBot a zároveň povoliť PerplexityBot, alebo povoliť roboty zamerané na vyhľadávanie (napr. OAI-SearchBot) a blokovať roboty pre zber dát (napr. GPTBot). Tento jemný prístup vám umožňuje optimalizovať stratégiu obsahu podľa toho, na ktorých AI platformách vám najviac záleží.
Ak AI crawlery nemôžu pristupovať k vášmu obsahu, znamená to, že vaša stránka je pre AI vyhľadávače a odpovedacie platformy prakticky neviditeľná. Váš obsah nebude citovaný, odporúčaný ani zahrnutý do AI generovaných odpovedí, aj keď je veľmi relevantný. Môže to viesť k strate návštevnosti, zníženiu viditeľnosti značky a nevyužitým príležitostiam na budovanie autority vo výsledkoch AI vyhľadávania.
Môžete skontrolovať serverové logy na výskyt User-Agent reťazcov známych AI crawlerov (GPTBot, ClaudeBot, PerplexityBot, atď.), alebo použiť špecializované monitorovacie nástroje ako AmICited, ktoré sledujú aktivitu AI crawlerov v reálnom čase. Tieto nástroje vám ukážu, ktoré roboty pristupujú na váš web, ako často crawlú, ktoré stránky navštevujú a či pri tom narážajú na chyby alebo blokovanie.
To závisí od vašej konkrétnej situácie. Ak je váš obsah dôverný, citlivý, alebo máte obavy z využitia na trénovanie dát, blokovanie môže byť vhodné. Ak však chcete byť viditeľný vo výsledkoch AI vyhľadávania a získať citácie od AI systémov, povolenie crawlerov je nevyhnutné. Mnohé organizácie volia strednú cestu: povolia roboty zamerané na vyhľadávanie, ktoré prinášajú citácie, a blokujú roboty na zber dát.
AI crawlery nerenderujú JavaScript, čo znamená, že akýkoľvek obsah načítaný dynamicky cez skripty na strane klienta je pre ne neviditeľný. Ak váš web vo veľkej miere využíva JavaScript na zobrazovanie dôležitého obsahu, navigácie alebo štruktúrovaných dát, AI crawlery uvidia len čisté HTML a prehliadnu dôležité informácie. To môže výrazne ovplyvniť, ako je váš obsah pochopený a prezentovaný v AI odpovediach. Je nevyhnutné poskytovať kľúčový obsah v statickom HTML kvôli crawlabilite AI.
Získajte prehľad v reálnom čase o tom, ktoré AI roboty pristupujú k vášmu obsahu a ako vidia vašu webstránku. Spustite si bezplatný audit ešte dnes a zabezpečte, aby bola vaša značka viditeľná vo všetkých AI vyhľadávačoch.
Naučte sa identifikovať a monitorovať AI crawlery ako GPTBot, ClaudeBot a PerplexityBot vo vašich serverových logoch. Kompletný sprievodca s user-agent reťazcam...

Objavte kľúčové technické SEO faktory ovplyvňujúce vašu viditeľnosť v AI vyhľadávačoch ako ChatGPT, Perplexity a Google AI Mode. Zistite, ako rýchlosť stránok, ...
Zistite, ako otestovať, či AI crawlery ako ChatGPT, Claude a Perplexity môžu pristupovať k obsahu vašej webstránky. Objavte metódy testovania, nástroje a najlep...