
Server-Side Rendering vs CSR: Vplyv na viditeľnosť v AI
Zistite, ako stratégie SSR a CSR ovplyvňujú viditeľnosť pre AI crawlerov, citácie značky v ChatGPT a Perplexity, a celkovú AI prítomnosť vo vyhľadávaní....
8 min čítania

Kompletný referenčný sprievodca AI crawlermi a botmi. Identifikujte GPTBot, ClaudeBot, Google-Extended a viac ako 20 ďalších AI crawlerov s user agentmi, rýchlosťami prehľadávania a stratégiami blokovania.
AI crawleri sa zásadne líšia od tradičných crawlerov vyhľadávačov, ktoré poznáte už desaťročia. Zatiaľ čo Googlebot a Bingbot indexujú obsah, aby používateľom pomohli nájsť informácie vo výsledkoch vyhľadávania, AI crawleri ako GPTBot a ClaudeBot zbierajú dáta špecificky na trénovanie veľkých jazykových modelov. Tento rozdiel je kľúčový: tradičné crawleri vytvárajú cesty k objaveniu obsahu ľuďmi, zatiaľ čo AI crawleri zásobujú databázy znalostí umelej inteligencie. Podľa nedávnych údajov AI crawleri dnes tvoria takmer 80% všetkej bot návštevnosti na weboch, pričom trénovacie crawleri spotrebujú obrovské množstvo obsahu a pritom posielajú vydavateľom minimum návštevnosti. Na rozdiel od tradičných crawlerov, ktoré majú problém s dynamickými stránkami s veľkým podielom JavaScriptu, AI crawleri využívajú pokročilé strojové učenie na kontextové pochopenie obsahu podobne ako ľudský čitateľ. Vedia interpretovať význam, tón aj účel bez potreby manuálnych aktualizácií konfigurácie. Ide o kvantový skok v technológiách indexácie webu, ktorý si vyžaduje, aby majitelia stránok úplne prehodnotili svoje stratégie správy crawlerov.
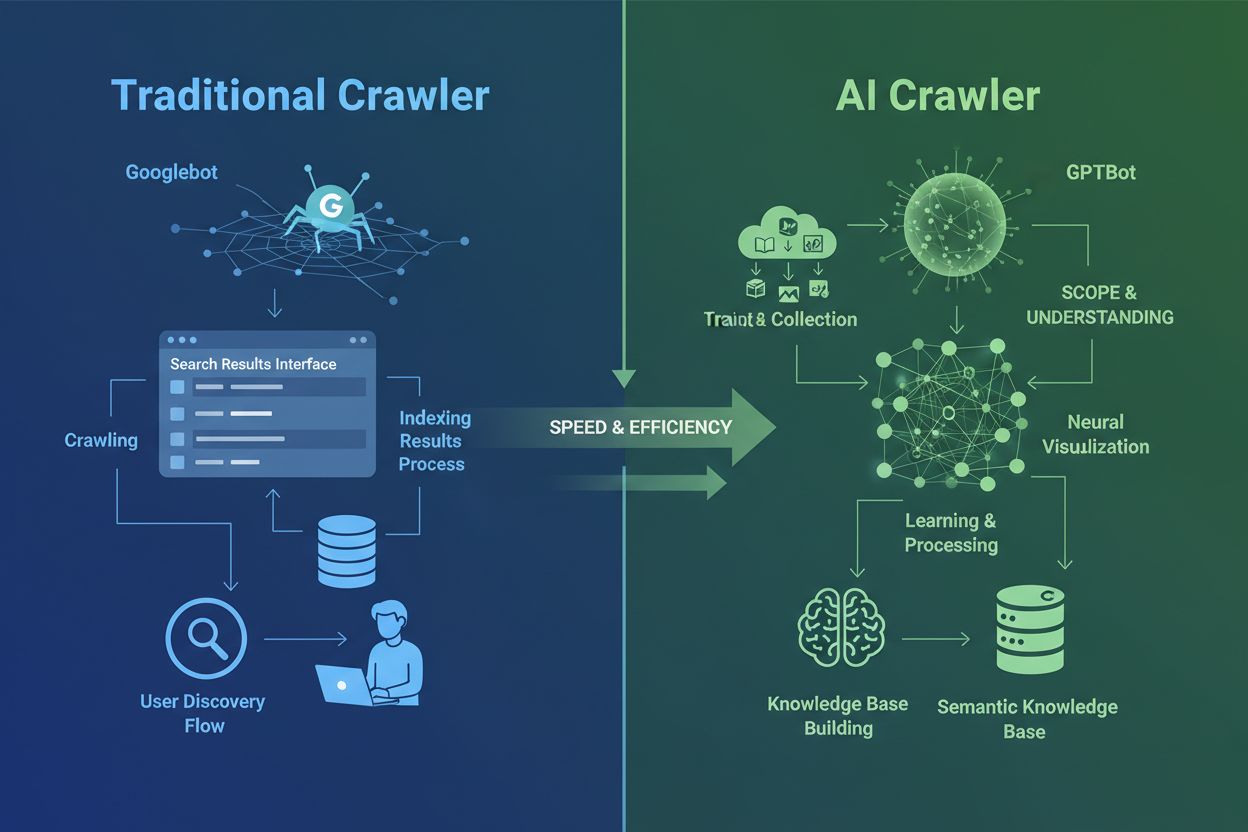
Prostredie AI crawlerov je čoraz preplnenejšie, keď veľké technologické firmy súťažia o vývoj vlastných jazykových modelov. OpenAI, Anthropic, Google, Meta, Amazon, Apple a Perplexity prevádzkujú viaceré špecializované crawleri, z ktorých každý plní odlišnú funkciu v príslušnom AI ekosystéme. Firmy nasadzujú viac crawlerov, pretože rôzne účely vyžadujú rôzne správanie: niektoré crawleri sa venujú masovému zbieraniu dát na trénovanie, iné zabezpečujú indexáciu na reálne vyhľadávanie a ďalšie získavajú obsah na požiadanie, keď si ho vyžiada používateľ. Pochopenie tohto ekosystému znamená rozpoznanie troch hlavných kategórií crawlerov: trénovacie crawleri zbierajúce dáta na vylepšovanie modelov, vyhľadávacie a citačné crawleri indexujúce obsah pre AI-vyhľadávanie, a fetcheri spúšťaní používateľom pri špecifickom dopyte cez AI asistenta. Nasledujúca tabuľka ponúka stručný prehľad hlavných hráčov:
| Spoločnosť | Názov crawlera | Primárny účel | Rýchlosť crawl | Trénovacie dáta |
|---|---|---|---|---|
| OpenAI | GPTBot | Tréning modelu | 100 strán/hod | Áno |
| OpenAI | ChatGPT-User | Dopyty používateľov v reálnom čase | 2400 strán/hod | Nie |
| OpenAI | OAI-SearchBot | Indexácia na vyhľadávanie | 150 strán/hod | Nie |
| Anthropic | ClaudeBot | Tréning modelu | 500 strán/hod | Áno |
| Anthropic | Claude-User | Web prístup v reálnom čase | <10 strán/hod | Nie |
| Google-Extended | Tréning Gemini AI | Variabilné | Áno | |
| Gemini-Deep-Research | Výskumná funkcia | <10 strán/hod | Nie | |
| Meta | Meta-ExternalAgent | Tréning AI modelu | 1100 strán/hod | Áno |
| Amazon | Amazonbot | Zlepšovanie služieb | 1050 strán/hod | Áno |
| Perplexity | PerplexityBot | Indexácia na vyhľadávanie | 150 strán/hod | Nie |
| Apple | Applebot-Extended | AI tréning | <10 strán/hod | Áno |
| Common Crawl | CCBot | Otvorený dataset | <10 strán/hod | Áno |
OpenAI prevádzkuje tri rozdielne crawleri, každý so špecifickou úlohou v ekosystéme ChatGPT. Poznanie týchto crawlerov je dôležité, pretože GPTBot od OpenAI patrí medzi najagresívnejšie a najrozšírenejšie AI crawleri na internete:
GPTBot – Hlavný trénovací crawler OpenAI, ktorý systematicky zbiera verejne dostupné dáta na trénovanie a zlepšovanie GPT modelov vrátane ChatGPT a GPT-4o. Tento crawler funguje zhruba na 100 strán za hodinu a rešpektuje pravidlá robots.txt. OpenAI zverejňuje oficiálne IP adresy na https://openai.com/gptbot.json na účely overenia.
ChatGPT-User – Tento crawler sa objaví, keď reálny používateľ interaguje s ChatGPT a požiada o prehliadanie konkrétnej stránky. Funguje omnoho rýchlejšie (až 2400 strán/hod), pretože je aktivovaný používateľskými akciami, nie automatizovaným prehľadávaním. Obsah získaný cez ChatGPT-User sa nepoužíva na trénovanie modelov, čo je hodnotné pre okamžitú viditeľnosť vo výsledkoch vyhľadávania ChatGPT.
OAI-SearchBot – Určený špeciálne pre vyhľadávaciu funkciu ChatGPT, indexuje obsah pre vyhľadávanie v reálnom čase bez zbierania trénovacích dát. Funguje zhruba na 150 strán za hodinu a pomáha vášmu obsahu objaviť sa vo vyhľadávaní ChatGPT pri relevantných otázkach.
Crawleri OpenAI rešpektujú robots.txt a fungujú z overených IP rozsahov, čo ich robí relatívne jednoduchými na správu v porovnaní s menej transparentnou konkurenciou.
Anthropic, spoločnosť stojaca za Claude AI, prevádzkuje viacero crawlerov s rôznymi účelmi a úrovňami transparentnosti. Firma poskytla menej dokumentácie v porovnaní s OpenAI, no ich správanie je dobre zdokumentované analýzou serverových logov:
ClaudeBot – Hlavný trénovací crawler Anthropicu, ktorý zbiera webový obsah na vylepšenie znalostnej bázy a schopností modelu Claude. Tento crawler funguje na zhruba 500 strán za hodinu a je hlavným cieľom, ak nechcete, aby bol váš obsah použitý na tréning modelu Claude. Plný user agent je Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com).
Claude-User – Aktivovaný, keď používatelia Claude žiadajú prístup na web v reálnom čase, tento crawler získava obsah na požiadanie v minimálnom objeme. Rešpektuje autentifikáciu a nesnaží sa obchádzať prístupové obmedzenia, takže z pohľadu serverových zdrojov je relatívne neškodný.
Claude-SearchBot – Podporuje vnútorné vyhľadávanie Claude, pomáha vášmu obsahu objaviť sa vo výsledkoch vyhľadávania Claude pri otázkach používateľov. Tento crawler funguje vo veľmi nízkych objemoch a slúži prioritne na indexáciu, nie tréning.
Kritickým problémom u crawlerov Anthropicu je pomer crawl/referral: Podľa údajov Cloudflare na každé jedno referral kliknutie, ktoré Anthropic pošle na web, jeho crawleri už navštívili približne 38 000 až 70 000 stránok. Táto obrovská nerovnováha znamená, že váš obsah je spotrebovávaný omnoho agresívnejšie, než je citovaný, čo vyvoláva otázky ohľadom spravodlivého odmeňovania za využitie obsahu.
Prístup Google k AI crawlrom sa výrazne líši od konkurencie, pretože firma prísne oddeľuje indexáciu na vyhľadávanie od AI trénovania. Google-Extended je špecifický crawler zodpovedný za zbieranie dát na tréning Gemini (predtým Bard) a ďalších AI produktov Google, úplne oddelený od tradičného Googlebotu:
User agent pre Google-Extended je: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0. Toto rozdelenie je zámerné a výhodné pre majiteľov stránok, pretože môžete Google-Extended zablokovať cez robots.txt bez toho, aby ste ovplyvnili viditeľnosť vo vyhľadávaní Google. Google oficiálne uvádza, že blokovanie Google-Extended nemá žiadny vplyv na pozície vo vyhľadávaní ani zaradenie do AI Overviews, hoci niektorí webmasteri hlásili obavy, ktoré treba sledovať. Gemini-Deep-Research je ďalší Google crawler podporujúci výskumnú funkciu Gemini, funguje však vo veľmi nízkych objemoch bez významného dopadu na serverové zdroje. Veľkou technickou výhodou crawlerov Google je ich schopnosť vykonávať JavaScript a renderovať dynamický obsah, na rozdiel od väčšiny konkurencie. Google-Extended tak dokáže efektívne prehľadávať React, Vue, či Angular aplikácie, čo GPTBot ani ClaudeBot nevedia. Pre majiteľov stránok s aplikáciami založenými na JavaScripte je toto významný rozdiel pre AI viditeľnosť.
Okrem technologických gigantov prevádzkuje AI crawleri aj množstvo ďalších organizácií, ktoré si zaslúžia pozornosť. Meta-ExternalAgent, ticho spustený v júli 2024, zbiera webový obsah na tréning AI modelov Mety a zlepšovanie produktov ako Facebook, Instagram a WhatsApp. Tento crawler funguje zhruba na 1100 strán za hodinu a napriek agresívnemu správaniu sa mu venovalo menej pozornosti ako konkurentom. Bytespider od ByteDance (materskej spoločnosti TikToku) sa od apríla 2024 stal jedným z najagresívnejších crawlerov na internete. Monitorovanie tretích strán naznačuje, že Bytespider prehľadáva omnoho agresívnejšie než GPTBot či ClaudeBot, aj keď presná miera sa môže líšiť. Niektoré správy uvádzajú, že nemusí dôsledne rešpektovať robots.txt, preto je spoľahlivejšie blokovať ho na úrovni IP.
Crawleri Perplexity zahŕňajú PerplexityBot na indexáciu vyhľadávania a Perplexity-User na získavanie obsahu v reálnom čase. O Perplexity sa objavili anekdotické správy o ignorovaní robots.txt, hoci firma tvrdí opak. Amazonbot poháňa odpovedanie Alexa a rešpektuje robots.txt, funguje zhruba na 1050 strán/hod. Applebot-Extended, predstavený v júni 2024, určuje, ako bude už indexovaný obsah Applebotom využitý pre AI tréning, neprehľadáva však stránky priamo. CCBot od Common Crawl (nezisková organizácia) buduje otvorené web archívy, ktoré využíva viacero AI firiem vrátane OpenAI, Google, Meta a Hugging Face. Novovznikajúce crawleri od xAI (Grok), Mistral a DeepSeek sa začínajú objavovať v serverových logoch, čo signalizuje pokračujúcu expanziu AI crawler ekosystému.
Nižšie je komplexná referenčná tabuľka overených AI crawlerov, ich účelov, user agent reťazcov a syntaxe pre blokovanie cez robots.txt. Tabuľka je pravidelne aktualizovaná na základe analýzy serverových logov a oficiálnej dokumentácie. Každý záznam bol overený voči oficiálnym IP zoznamom, ak sú dostupné:
| Názov crawlera | Spoločnosť | Účel | User Agent | Rýchlosť crawl | Overenie IP | Syntax robots.txt |
|---|---|---|---|---|---|---|
| GPTBot | OpenAI | Zber trénovacích dát | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot) | 100/hod | ✓ Oficiálne | User-agent: GPTBot Disallow: / |
| ChatGPT-User | OpenAI | Dopyty používateľov v reálnom čase | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0 | 2400/hod | ✓ Oficiálne | User-agent: ChatGPT-User Disallow: / |
| OAI-SearchBot | OpenAI | Indexácia na vyhľadávanie | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36; compatible; OAI-SearchBot/1.3 | 150/hod | ✓ Oficiálne | User-agent: OAI-SearchBot Disallow: / |
| ClaudeBot | Anthropic | Zber trénovacích dát | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | 500/hod | ✓ Oficiálne | User-agent: ClaudeBot Disallow: / |
| Claude-User | Anthropic | Web prístup v reálnom čase | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0) | <10/hod | ✗ Nedostupné | User-agent: Claude-User Disallow: / |
| Claude-SearchBot | Anthropic | Indexácia na vyhľadávanie | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0) | <10/hod | ✗ Nedostupné | User-agent: Claude-SearchBot Disallow: / |
| Google-Extended | Tréning Gemini AI | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0) | Variabilné | ✓ Oficiálne | User-agent: Google-Extended Disallow: / | |
| Gemini-Deep-Research | Výskumná funkcia | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Gemini-Deep-Research) | <10/hod | ✓ Oficiálne | User-agent: Gemini-Deep-Research Disallow: / | |
| Bingbot | Microsoft | Bing vyhľadávanie & Copilot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0) | 1300/hod | ✓ Oficiálne | User-agent: Bingbot Disallow: / |
| Meta-ExternalAgent | Meta | Tréning AI modelu | meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler) | 1100/hod | ✗ Nedostupné | User-agent: Meta-ExternalAgent Disallow: / |
| Amazonbot | Amazon | Zlepšovanie služieb | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1) | 1050/hod | ✓ Oficiálne | User-agent: Amazonbot Disallow: / |
| Applebot-Extended | Apple | AI tréning | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15; compatible; Applebot-Extended | <10/hod | ✓ Oficiálne | User-agent: Applebot-Extended Disallow: / |
| PerplexityBot | Perplexity | Indexácia na vyhľadávanie | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0) | 150/hod | ✓ Oficiálne | User-agent: PerplexityBot Disallow: / |
| Perplexity-User | Perplexity | Získavanie v reálnom čase | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0) | <10/hod | ✓ Oficiálne | User-agent: Perplexity-User Disallow: / |
| Bytespider | ByteDance | AI tréning | Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36; compatible; Bytespider | <10/hod | ✗ Nedostupné | User-agent: Bytespider Disallow: / |
| CCBot | Common Crawl | Otvorený dataset | CCBot/2.0 (https://commoncrawl.org/faq/ ) | <10/hod | ✓ Oficiálne | User-agent: CCBot Disallow: / |
| DuckAssistBot | DuckDuckGo | AI vyhľadávanie | DuckAssistBot/1.2; (+http://duckduckgo.com/duckassistbot.html) | 20/hod | ✓ Oficiálne | User-agent: DuckAssistBot Disallow: / |
| Diffbot | Diffbot | Extrakcia dát | Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.1.2) Gecko/20090729 Firefox/3.5.2 Diffbot/0.1 | <10/hod | ✗ Nedostupné | User-agent: Diffbot Disallow: / |
| MistralAI-User | Mistral | Získavanie v reálnom čase | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; MistralAI-User/1.0) | <10/hod | ✗ Nedostupné | User-agent: MistralAI-User Disallow: / |
| ICC-Crawler | NICT | AI/ML tréning | ICC-Crawler/3.0 (Mozilla-compatible; https://ucri.nict.go.jp/en/icccrawler.html ) | <10/hod | ✗ Nedostupné | User-agent: ICC-Crawler Disallow: / |
Nie všetci AI crawleri plnia rovnakú úlohu a pochopenie týchto rozdielov je kľúčové pre informované rozhodovanie o blokovaní. Trénovacie crawleri tvoria približne 80% všetkej AI bot prevádzky a zbierajú obsah špecificky na tvorbu datasetov pre vývoj veľkých jazykových modelov. Akonáhle sa váš obsah dostane do trénovacieho datasetu, stáva sa súčasťou znalostnej bázy modelu, čo môže znižovať potrebu používateľov navštevovať vašu stránku kvôli odpovediam. Trénovacie crawleri ako GPTBot, ClaudeBot a Meta-ExternalAgent operujú vo vysokom objeme a systematicky, pričom vracajú minimum až žiadnu návštevnosť späť vydavateľom.
Vyhľadávacie a citačné crawleri indexujú obsah pre AI-vyhľadávanie a môžu skutočne posielať určitú návštevnosť späť cez citácie. Keď sa používateľ pýta v ChatGPT alebo Perplexity, tieto crawleri pomáhajú ponúkať relevantné zdroje. Na rozdiel od trénovacích crawlerov, vyhľadávacie crawleri ako OAI-SearchBot a PerplexityBot pracujú v strednom objeme so zameraním na vyhľadávanie a môžu obsahovať atribúciu a odkazy. Fetcheri spúšťaní používateľom sa aktivujú iba vtedy, keď používateľ konkrétne požiada o obsah cez AI asistenta. Keď niekto vloží URL do ChatGPT alebo požiada Perplexity o analýzu stránky, tieto fetcheri získajú obsah na požiadanie. Fetcheri fungujú vo veľmi nízkom objeme s jednorazovými požiadavkami, nie systematickým crawlom, a väčšina AI firiem potvrdzuje, že sa nepoužívajú na trénovanie modelov. Poznanie týchto kategórií vám pomáha robiť strategické rozhodnutia, ktorým crawlerom povoliť prístup a ktorých blokovať podľa vašich biznis priorít.
Prvým krokom pri správe AI crawlerov je pochopenie, ktorí z nich skutočne navštevujú vašu stránku. Serverové prístupové logy obsahujú podrobné záznamy o každej požiadavke vrátane user agent reťazca, ktorý identifikuje crawler. Väčšina hostingových panelov ponúka nástroje na analýzu, no môžete pristupovať aj k surovým logom. Pre Apache servery sú logy zvyčajne v /var/log/apache2/access.log, pri Nginx v /var/log/nginx/access.log. Aktivitu crawlerov v logoch vyfiltrujete napríklad takto:
grep -i "gptbot\|claudebot\|google-extended\|bytespider" /var/log/apache2/access.log | head -20
Tento príkaz zobrazí 20 najnovších požiadaviek od hlavných AI crawlerov. Google Search Console poskytuje štatistiky pre Google crawleri, aj keď ukazuje iba ich vlastné boti. Cloudflare Radar ponúka globálne prehľady o AI bot návštevnosti a môže pomôcť identifikovať najaktívnejšie crawleri. Ak chcete overiť, či je crawler legitímny alebo falošný, porovnajte IP adresu požiadavky s oficiálnymi IP zoznamami veľkých firiem. OpenAI zverejňuje IP na https://openai.com/gptbot.json, Amazon na https://developer.amazon.com/amazonbot/ip-addresses/ a ďalší udržiavajú podobné zoznamy. Falošný crawler predstierajúci legitímny user agent z neoverenej IP by mal byť okamžite zablokovaný, keďže pravdepodobne ide o škodlivú aktivitu.
Súbor robots.txt je vaším hlavným nástrojom na kontrolu prístupu crawlerov. Tento jednoduchý textový súbor umiestnený v koreňovom adresári vášho webu hovorí crawlerom, ktoré časti stránky môžu navštevovať. Ak chcete blokovať konkrétnych AI crawlerov, pridajte napríklad:
# Blokovať GPTBot od OpenAI
User-agent: GPTBot
Disallow: /
# Blokovať ClaudeBot od Anthropicu
User-agent: ClaudeBot
Disallow: /
# Blokovať AI trénovanie od Google (nie vyhľadávanie)
User-agent: Google-Extended
Disallow: /
# Blokovať Common Crawl
User-agent: CCBot
Disallow: /
Crawlerom môžete povoliť prístup, ale nastaviť im obmedzenia rýchlosti:
User-agent: GPTBot
Crawl-delay: 10
Disallow: /private/
Tým poviete GPTBotovi, aby medzi požiadavkami čakal 10 sekúnd a nechodil do súkromného adresára. Pre vyvážený prístup, ktorý povolí vyhľadávacie crawleri a blokuje trénovacie:
# Povoliť tradičné vyhľadávače
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Blokovať všetky AI trénovacie crawleri
User-agent: GPTBot
User-agent: ClaudeBot
User-agent: CCBot
User-agent: Google-Extended
User-agent: Bytespider
User-agent: Meta-ExternalAgent
Disallow: /
# Povoliť AI vyhľadávacie crawleri
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
Väčšina dôveryhodných AI crawlerov rešpektuje robots.txt, no niektoré agresívne crawleri ho úplne ignorujú. Preto samotný robots.txt nestačí na úplnú ochranu.
Robots.txt je len odporúčanie, nie vynútiteľné pravidlo, čo znamená, že crawlery môžu vaše pokyny ignorovať. Na silnejšiu ochranu voči crawlerom, ktoré robots.txt nerespektujú, implementujte blokovanie na úrovni IP priamo na serveri. Tento prístup je spoľahlivejší, keďže IP sa falšuje oveľa ťažšie ako user agent. Môžete povoliť iba oficiálne IP z overených zdrojov a všetky ostatné požiadavky deklarujúce AI crawler blokovať.
Pre servery Apache použite pravidlá v .htaccess na blokovanie crawlerov na úrovni servera:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|anthropic-ai|Bytespider|CCBot) [NC]
RewriteRule .* - [F,L]
</IfModule>
Tým vrátite odpoveď 403 Forbidden na všetky požiadavky týchto user agentov bez ohľadu na robots.txt. Firewall pravidlá ponúkajú ďalšiu vrstvu ochrany – povolíte iba overené IP rozsahy z oficiálnych zdrojov, ostatné požiadavky deklarujúce AI crawler blokujete. HTML meta tagy umožňujú detailnú kontrolu na úrovni stránky. Amazon a niektorí ďalší crawleri rešpektujú direktívu noarchive:
<meta name="robots" content="noarchive">
Tým crawlerom poviete, aby stránku nepoužívali na trénovanie modelu, ale mohli ju indexovať. Vyberte si metódu blokovania podľa technických možností a konkrétnych crawlerov. IP blokovanie je najspoľahlivejšie, ale náročnejšie na nastavenie, robots.txt je najjednoduchší, ale najmenej účinný pri nevyhovujúcich crawleroch.
Implementácia blokovania crawlerov je len polovica úspechu; musíte si overiť, že naozaj funguje. Pravidelný monitoring vám pomôže včas odhaliť problémy a identifikovať nové crawleri, s ktorými ste sa ešte nestretli. Kontrolujte serverové logy každý týždeň na neobvyklú bot aktivitu, sledujte user agent reťazce obsahujúce “bot”, “crawler”, “spider”
AI crawleri ako GPTBot a ClaudeBot zbierajú obsah špecificky na trénovanie veľkých jazykových modelov, zatiaľ čo crawleri vyhľadávačov ako Googlebot indexujú obsah, aby ho ľudia našli cez výsledky vyhľadávania. AI crawleri zásobujú databázy znalostí AI systémov, zatiaľ čo vyhľadávacie crawleri pomáhajú používateľom objavovať váš obsah. Kľúčový rozdiel je účel: trénovanie verzus vyhľadávanie.
Nie, blokovanie AI crawlerov neovplyvní vaše tradičné pozície vo vyhľadávačoch. AI crawleri ako GPTBot a ClaudeBot sú úplne oddelení od crawlerov vyhľadávačov ako Googlebot. Môžete zablokovať Google-Extended (pre AI trénovanie) a zároveň povoliť Googlebot (pre vyhľadávanie). Každý crawler slúži na iný účel a blokovanie jedného neovplyvní druhého.
Skontrolujte prístupové logy vášho servera a zistite, ktoré user agenty navštevujú vašu stránku. Hľadajte názvy botov ako GPTBot, ClaudeBot, CCBot a Bytespider v reťazcoch user agentov. Väčšina hostingových panelov ponúka nástroje na analýzu logov. Môžete tiež použiť Google Search Console na sledovanie aktivít crawlerov, aj keď zobrazuje iba Google crawleri.
Nie všetci AI crawleri rešpektujú robots.txt rovnako. GPTBot od OpenAI, ClaudeBot od Anthropic a Google-Extended vo všeobecnosti dodržiavajú pravidlá robots.txt. Bytespider a PerplexityBot čelili hláseniam, že nemusia vždy dôsledne dodržiavať robots.txt. Pri crawlroch, ktoré robots.txt nerešpektujú, je potrebné implementovať blokovanie na úrovni IP adresy cez firewall alebo .htaccess súbor.
Rozhodnutie závisí od vašich cieľov. Blokujte trénovacie crawleri, ak máte proprietárny obsah alebo obmedzené serverové zdroje. Povoľte vyhľadávacie crawleri, ak chcete byť viditeľní vo výsledkoch AI vyhľadávania a chatbotov, ktoré môžu privádzať návštevnosť a budovať autoritu. Mnohé firmy volia selektívny prístup – povolia špecifické crawleri, zatiaľ čo agresívne ako Bytespider blokujú.
Nové AI crawleri vznikajú pravidelne, preto by ste mali svoj blocklist kontrolovať aspoň štvrťročne. Sledujte zdroje ako projekt ai.robots.txt na GitHub-e pre komunitne udržiavané zoznamy. Kontrolujte serverové logy mesačne, aby ste identifikovali nové crawleri, ktoré nie sú vo vašej aktuálnej konfigurácii. AI crawler ekosystém sa rýchlo vyvíja, rovnako by sa mala vyvíjať aj vaša stratégia.
Áno, skontrolujte IP adresu požiadavky voči oficiálnym zoznamom IP, ktoré zverejňujú veľké spoločnosti. OpenAI zverejňuje overené IP na https://openai.com/gptbot.json, Amazon na https://developer.amazon.com/amazonbot/ip-addresses/ a iní udržiavajú podobné zoznamy. Crawler, ktorý predstiera legitímneho user agenta z neoverenej IP adresy, by mal byť okamžite zablokovaný, pretože pravdepodobne ide o škodlivé scrapovanie.
AI crawleri môžu spotrebovať značnú šírku pásma a serverové zdroje. Bytespider a Meta-ExternalAgent patria medzi najagresívnejšie crawleri. Niektorí vydavatelia uvádzajú, že blokovaním AI crawlerov znížili spotrebu pásma z 800GB na 200GB denne, čím mesačne ušetrili približne 1 500 USD. Sledujte svoje serverové zdroje počas období intenzívneho prehľadávania a pri potrebe implementujte obmedzovanie rýchlosti pre agresívne boty.
Sledujte, ktoré AI crawleri citujú váš obsah a optimalizujte svoju viditeľnosť v ChatGPT, Perplexity, Google Gemini a ďalších.
Zistite, ako stratégie SSR a CSR ovplyvňujú viditeľnosť pre AI crawlerov, citácie značky v ChatGPT a Perplexity, a celkovú AI prítomnosť vo vyhľadávaní....

Naučte sa, ako blokovať alebo povoliť AI crawlery ako GPTBot a ClaudeBot pomocou robots.txt, serverového blokovania a pokročilých ochranných metód. Kompletný te...

Objavte kľúčové technické SEO faktory ovplyvňujúce vašu viditeľnosť v AI vyhľadávačoch ako ChatGPT, Perplexity a Google AI Mode. Zistite, ako rýchlosť stránok, ...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.