
Rozpoznávanie entít
Rozpoznávanie entít je schopnosť AI a NLP identifikovať a kategorizovať pomenované entity v texte. Zistite, ako funguje, jeho využitie v AI monitoringu a jeho ú...
10 min čítania

Preskúmajte, ako AI systémy rozpoznávajú a spracúvajú entity v texte. Zistite viac o modeloch NER, architektúrach transformerov a reálnych aplikáciách porozumenia entít.
Porozumenie entitám sa stalo základnou schopnosťou moderných systémov umelej inteligencie, ktorá umožňuje strojom identifikovať a chápať kľúčových aktérov, miesta a pojmy v neštruktúrovanom texte. Od poháňania vyhľadávačov, ktoré rozumejú zámeru používateľa, až po umožnenie chatbotom odpovedať na zložité otázky o konkrétnych ľuďoch a organizáciách, rozpoznávanie entít tvorí základ zmysluplnej interakcie človek-počítač. Táto technická schopnosť je kľúčová naprieč odvetviami—finančné inštitúcie ju využívajú na monitorovanie súladu, zdravotnícke systémy na správu pacientskych záznamov a e-commerce platformy sa na ňu spoliehajú pri porozumení zmienkam o produktoch a spätnej väzbe zákazníkov. Pochopenie toho, ako AI systémy extrahujú a interpretujú entity, je nevyhnutné pre každého, kto buduje alebo nasadzuje NLP aplikácie v produkčnom prostredí.
Rozpoznávanie pomenovaných entít (NER) je NLP úloha identifikácie a klasifikácie pomenovaných entít—konkrétnych, významových jednotiek informácie—v texte do vopred definovaných kategórií. Tieto entity predstavujú konkrétne subjekty, ktoré nesú sémantickú váhu v jazyku: ľudia, ktorí vykonávajú činnosti, organizácie, ktoré robia rozhodnutia, lokality, kde sa dejú udalosti, časové výrazy, ktoré kotvia udalosti v čase, menovité hodnoty vyjadrujúce transakcie a produkty, ktoré sa kupujú a predávajú. Klasifikácia entít je dôležitá, pretože premieňa surový text na štruktúrované poznatky, na základe ktorých môžu stroje uvažovať a konať; bez nej systém nerozozná “Apple firmu” od “apple ovocia” alebo nepochopí, že “John Smith” a “J. Smith” označujú tú istú osobu. Schopnosť presne klasifikovať entity umožňuje následné aplikácie ako stavbu znalostných grafov, extrakciu informácií, zodpovedanie otázok a detekciu vzťahov.
| Typ entity | Definícia | Príklad |
|---|---|---|
| OSOBA | Jednotlivé ľudské bytosti | “Steve Jobs,” “Marie Curie” |
| ORGANIZÁCIA | Spoločnosti, inštitúcie, skupiny | “Microsoft,” “Organizácia spojených národov,” “Harvardská univerzita” |
| LOKALITA | Geografické miesta a regióny | “New York,” “Amazonka,” “Silicon Valley” |
| DÁTUM | Časové výrazy a obdobia | “15. január 2024,” “budúci utorok,” “3. štvrťrok 2023” |
| PENIAZE | Menovité hodnoty a meny | “50 miliónov $,” “€100,” “5000 jenov” |
| PRODUKT | Tovary, služby a výtvory | “iPhone 15,” “Windows 11,” “ChatGPT” |
Moderné AI systémy spracúvajú entity cez sofistikovaný viacstupňový pipeline, ktorý začína tokenizáciou, teda rozdelením surového textu na diskrétne tokeny, ktoré slúžia ako základné jednotky pre ďalšie spracovanie. Každý token je následne prevedený na číselnú reprezentáciu cez word embeddingy—husté vektory zachytávajúce sémantiku—ktoré sú vkladané do neurónových sietí navrhnutých na pochopenie kontextu a vzťahov. Modely založené na transformeroch, ktoré sa stali dominantnou architektúrou v súčasnom NLP, spracúvajú celé sekvencie paralelne namiesto sekvenčného spracovania, čo im umožňuje zachytiť dlhodobé závislosti a zložité kontextové vzťahy, ktoré sú kľúčové pre presné porozumenie entít. Self-attention mechanizmus v transformeroch umožňuje každému tokenu dynamicky zvažovať dôležitosť každého iného tokenu v sekvencii, čím vytvára bohaté kontextové reprezentácie, kde význam slova určuje jeho okolité prostredie; preto je “banka” chápaná inak v “riečna banka” a “sporiteľná banka”. Predtrénované jazykové modely ako BERT a GPT sa učia všeobecné jazykové vzory z masívnych textových korpusov pred tým, než sú doladené na úlohy rozpoznávania entít, vďaka čomu využívajú naučené reprezentácie syntaxe, sémantiky a znalostí o svete. Záverečná vrstva systémov na rozpoznávanie entít spravidla využíva sekvenčné označovanie—často implementované ako Conditional Random Field (CRF) alebo jednoduchú klasifikačnú hlavu—ktorá prideľuje entitné štítky jednotlivým tokenom na základe kontextových reprezentácií naučených neurónovou sieťou. Táto architektúra umožňuje AI systémom pochopiť nielen to, aké entity sa v texte nachádzajú, ale aj ako spolu súvisia a aké úlohy v rámci širšieho kontextu zohrávajú.
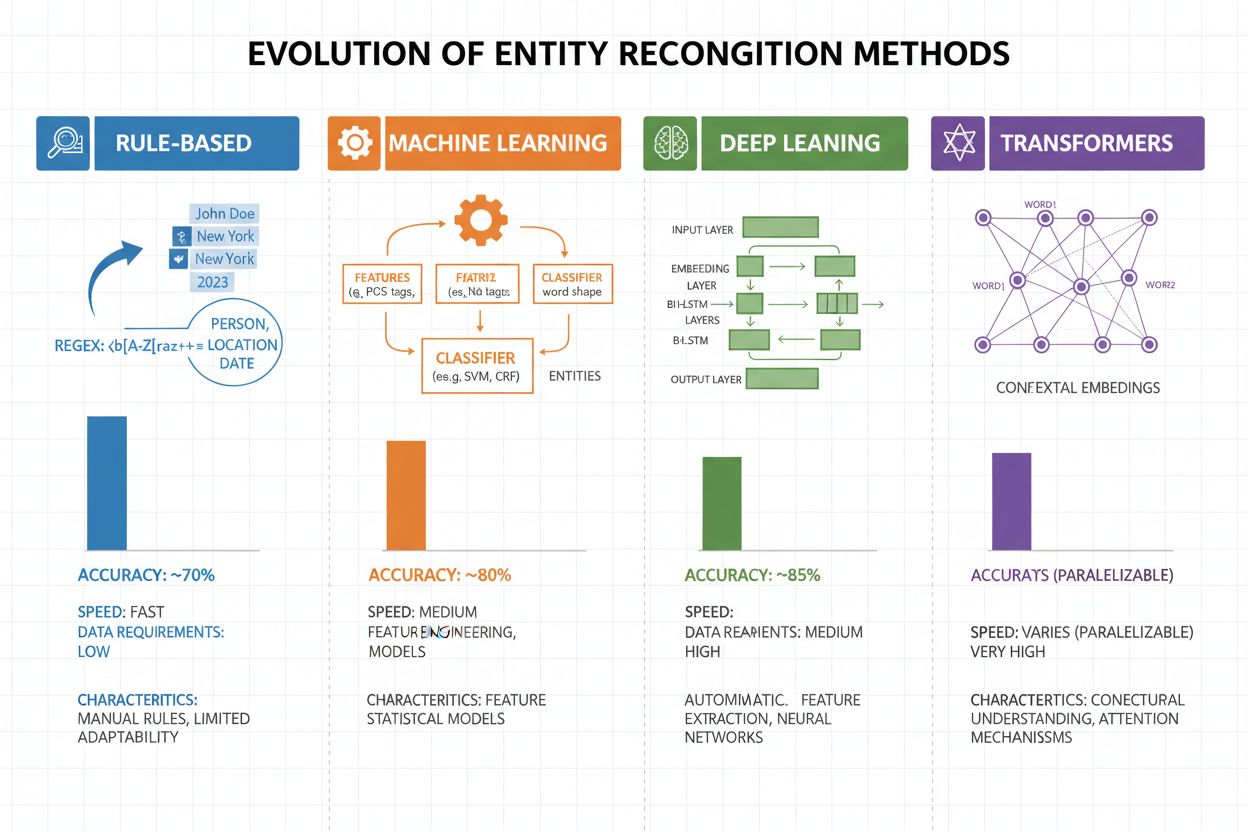
Rozpoznávanie entít sa v priebehu posledných dvoch dekád dramaticky vyvinulo od jednoduchých pravidlových prístupov po sofistikované neurónové architektúry. Rané systémy sa spoliehali na ručne vytvárané pravidlá a slovníky, využívajúc regulárne výrazy a párovanie vzorov na identifikáciu entít—metódy, ktoré boli interpretovateľné a vyžadovali minimum tréningových dát, no trpeli slabou generalizáciou a vysokou náročnosťou na údržbu. Príchod strojového učenia priniesol supervizované prístupy ako Support Vector Machines (SVM) a Conditional Random Fields (CRF), ktoré sa učili zo značených dát pomocou návrhu čŕt a významne zlepšili presnosť, aj keď stále vyžadovali expertov na návrh vlastností. Metódy hlbokého učenia, najmä LSTM a BiLSTM, automatizovali extrakciu čŕt učením reprezentácií priamo zo surového textu, dosiahli výrazne vyššiu presnosť bez manuálneho návrhu vlastností, no vyžadovali väčšie množstvo značených dát. Modely na báze transformerov ako BERT a RoBERTa spôsobili revolúciu v oblasti využitím mechanizmov self-attention na zachytávanie dlhodobých závislostí a kontextových nuáns, dosahujúc špičkové výsledky (BERT dosiahol 90,9 % F1 na CoNLL-2003) a umožnili transfer learning z veľkých predtrénovaných modelov. Kompromis medzi komplexnosťou a presnosťou sa dramaticky posunul: zatiaľ čo pravidlové systémy sú stále užitočné v prostrediach s obmedzenými zdrojmi a vysoko špecializovaných doménach, transformerové modely dnes dominujú tam, kde sú dostupné dostatočné výpočtové zdroje a značené dáta, pričom ľahšie alternatívy ako DistilBERT ponúkajú kompromis pre produkčné systémy s nízkou latenciou.
Modely na báze transformerov zásadne zmenili rozpoznávanie entít tým, že nahradili sekvenčné spracovanie paralelnými self-attention mechanizmami, ktoré naraz zvažujú všetky tokeny vo vete, čím umožňujú bohatšie pochopenie kontextu ako predchádzajúce architektúry. BERT a jeho varianty (RoBERTa, DistilBERT, ALBERT) využívajú obojsmerné predtrénovanie na masívnych neznačených korpusoch, učia sa univerzálne jazykové reprezentácie zachytávajúce syntaktické aj sémantické informácie pred doladením na NER úlohy s relatívne malými značenými datasetmi. Paradigma predtrénovania a doladenia je obzvlášť silná pre rozpoznávanie entít: modely predtrénované na miliardách tokenov získajú robustné reprezentácie jazykovej štruktúry a entitných vzorov, ktoré sa následne dajú prispôsobiť na špecifické domény už s tisíckami značených príkladov, čím dramaticky klesajú požiadavky na dáta v porovnaní s tréningom od nuly. Transformery vynikajú v porozumení entít vďaka multi-head attention mechanizmu, kde rôzne heads sa špecializujú na rozličné typy vzťahov medzi entitami—niektoré sa zameriavajú na syntaktické hranice, iné zachytávajú sémantické súvislosti medzi entitami a ich kontextom. Viacjazyčné rozpoznávanie entít prešlo revolúciou vďaka modelom ako mBERT a XLM-RoBERTa, ktoré sú predtrénované na viac než 100 jazykoch súčasne, umožňujúc zero-shot a few-shot transfer do málo zdrojových jazykov a cross-lingválne prepojenie entít. Nové modely ako GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) posúvajú hranice ďalej tým, že umožňujú rozpoznávanie entít na základe zadania v prirodzenom jazyku, bez potreby doladenia na konkrétnu úlohu, čo predstavuje posun k flexibilnejším a generalizovateľným systémom porozumenia entít.
Napriek pozoruhodnému pokroku čelia systémy na rozpoznávanie entít pretrvávajúcim reálnym výzvam, ktoré obmedzujú ich praktické nasadenie, pričom viacvýznamovosť a citlivosť na kontext patria medzi najťažšie riešiteľné—slovo “Apple” si žiada pochopenie, či ide o ovocie alebo technologickú firmu na základe okolia, a aj špičkové modely majú problém so sémantickou dezambiguáciou v šume alebo nejednoznačnom texte. Entity mimo slovníka (OOV) sú ďalšou zásadnou výzvou: modely trénované na štandardných datasetoch sa často nestretnú s raritnými entitami, vlastnými menami z nových oblastí či preklepmi, čo vedie k nesprávnej klasifikácii alebo úplnému nerozpoznaniu týchto entít. Adaptácia na doménu zostáva problematická, pretože modely trénované na spravodajských korpusoch (ako CoNLL-2003) často zlyhávajú na biomedicínskom, právnom či sociálno-mediálnom texte, kde rozloženie entít a jazykové vzorce dramaticky odlišujú, čo si vyžaduje nákladné pre-annotovanie a doladenie pre každú novú doménu. Chyby pri určovaní hraníc—keď systém správne identifikuje existenciu entity, ale nesprávne určí jej začiatok alebo koniec—sú obzvlášť časté pri viacslovných entitách a vnorených štruktúrach, napríklad rozlíšenie “New York City” od “New York” alebo spracovanie entít ako “Chief Executive Officer of Apple Inc.” Viacjazyčné komplikácie tieto výzvy znásobujú, pretože rôzne jazyky majú iné konvencie kapitalizácie, morfologické štruktúry a vzory pomenovávania entít, čo spôsobuje, že modely trénované na angličtine často zlyhávajú pri aplikácii na jazyky s inými jazykovými vlastnosťami. Nedostatok dát pre špecializované domény ako názvy zriedkavých chorôb, nové technológie alebo špecifické firemné pojmy vytvára úzke hrdlo, kde je cena manuálnej anotácie prohibítivná, čím sú praktici nútení voliť medzi nižšou presnosťou alebo investovaním do zberu doménovo špecifických tréningových dát.
Porozumenie entít sa stalo nepostrádateľným naprieč odvetviami a mení spôsob, akým organizácie získavajú hodnotu z neštruktúrovaného textu. Pri extrakcii informácií a stavbe znalostných grafov umožňuje rozpoznávanie entít automatizované napĺňanie štruktúrovaných databáz z dokumentov, poháňa vyhľadávače a odporúčacie systémy chápuce vzťahy medzi ľuďmi, miestami a pojmami. Zdravotnícke organizácie využívajú porozumenie entít na identifikáciu názvov liekov, dávok, symptómov a demografie pacientov z klinických poznámok, čím zlepšujú podporu klinického rozhodovania a umožňujú farmakovigilančným systémom detekovať nežiaduce interakcie vo veľkom rozsahu. Finančné inštitúcie používajú rozpoznávanie entít na extrakciu burzových symbolov, hodnôt a trhových udalostí zo správ a výkazov, čím umožňujú algoritmickým obchodným systémom a platformám na riadenie rizík reagovať na trhovo významné informácie v reálnom čase. Firmy v právnych technológiách aplikujú porozumenie entít na automatickú identifikáciu strán, dátumov, záväzkov a zodpovednostných klauzúl v zmluvách, čím skracujú čas právnikov na revíziu dokumentov z týždňov na hodiny. Zákaznícke a chatbot platformy využívajú rozpoznávanie entít na extrakciu zámerov používateľov a relevantného kontextu—ako čísla objednávok, názvy produktov a typy problémov—umožňujúc presnejšie smerovanie a rýchlejšie vyriešenie požiadavky. E-commerce platformy využívajú porozumenie entít na identifikáciu názvov produktov, značiek, vlastností a špecifikácií z recenzií a vyhľadávaní, čím zlepšujú objavovanie produktov a personalizáciu. Systémy odporúčaní obsahu využívajú rozpoznávanie entít na pochopenie, s akými entitami používateľ interaguje, čo umožňuje sofistikovanejšie kolaboratívne filtrovanie a odporúčania založené na obsahu, ktoré zvyšujú angažovanosť a tržby.
Implementácia produkčného systému na porozumenie entít si vyžaduje starostlivú prípravu dát, výber modelu a hodnotenie. Začnite s kvalitne anotovanými dátami: stanovte jasné definície typov entít, používajte metriky zhodnosti medzi anotátormi na zabezpečenie konzistencie a snažte sa o aspoň 500-1000 značených príkladov na typ entity, hoci doménovo špecifické aplikácie môžu vyžadovať viac. Výber modelu závisí od vašich obmedzení: pravidlové systémy ponúkajú interpretovateľnosť a nízku latenciu pre dobre definované domény, tradičné ML modely (CRF, SVM) poskytujú dobrý výkon s miernym objemom dát, zatiaľ čo modely na báze transformerov (BERT, RoBERTa) dosahujú špičkovú presnosť, no vyžadujú viac výpočtových zdrojov a dát. Stratégie trénovania a doladenia by mali zahŕňať techniky augmentácie dát na zvládnutie nevyváženosti tried, krížovú validáciu na prevenciu overfittingu a starostlivé ladenie hyperparametrov pre learning rate a batch size. Vyhodnocujte systém pomocou presnosti (správne identifikované entity), recallu (nájdené entity zo všetkých skutočných entít) a F1 skóre (harmonický priemer oboch), so samostatnými metrikami pre každý typ entity, aby ste odhalili slabé miesta. Nasadzovanie zahŕňa požiadavky na latenciu (batch vs. real-time spracovanie), škálovateľnosť a integráciu s existujúcimi dátovými pipeline, pričom post-deployment monitoring by mal sledovať drift výkonu, mieru falošných pozitív a spätnú väzbu používateľov na spustenie cyklov pretrénovania.
Ekosystém nástrojov na porozumenie entít ponúka riešenia pre každú mierku aj prípad použitia. Open-source knižnice ako spaCy poskytujú produkčne pripravené NER pipeline s výborným výkonom (89,22 % F1 skóre na štandardných benchmarkoch) a skvelou dokumentáciou, čo je ideálne pre tímy s ML expertízou; NLTK ponúka vzdelávaciu hodnotu a základné NER schopnosti; Hugging Face Transformers poskytuje prístup k špičkovým predtrénovaným modelom, ktoré je možné doladiť na špecifické domény s minimom kódu. Cloudové managed služby odstraňujú starosti s infraštruktúrou: Google Cloud Natural Language API, AWS Comprehend a IBM Watson NLP ponúkajú predtrénované rozpoznávanie entít s podporou viacerých jazykov a typov entít, automaticky riešia škálovanie a jednoducho sa integrujú s cloudovými dátovými pipeline. Špecializované frameworky ako Flair (postavený na PyTorch s výbornou podporou sekvenčného označovania) a DeepPavlov (ponúkajúci predtrénované modely pre viacero jazykov a domén) sú vhodné pre výskumníkov a tímy, ktoré potrebujú viac prispôsobenia ako zaisťujú všeobecné knižnice. Rozhodnutie medzi stavbou vlastného riešenia a využitím hotových nástrojov závisí od citlivosti vašich dát (on-premise vs. cloud), požadovanej úrovne presnosti, doménovej špecifikácie a odbornosti tímu: použite managed API pre všeobecné aplikácie so štandardnými entitami, open-source knižnice pre doménovo špecifickú úpravu s internými dátami a vlastné modely len vtedy, keď existujúce riešenia nedokážu splniť vaše požiadavky na presnosť či latenciu.
Budúcnosť porozumenia entít formujú veľké jazykové modely, ktoré prinášajú nevídanú flexibilitu a výkon pre túto úlohu. Modely ako GPT-4 a Claude demonštrujú pozoruhodné few-shot a zero-shot schopnosti rozpoznávania entít, umožňujúce organizáciám identifikovať vlastné typy entít s len niekoľkými príkladmi alebo dokonca s popismi v prirodzenom jazyku, čím dramaticky klesá záťaž na anotáciu a urýchľuje sa čas do hodnoty. Multimodálne porozumenie entít sa stáva novou hranicou, kombinujúc text, obrázky a štruktúrované dáta na rozpoznávanie entít v dokumentoch, faktúrach a webstránkach s bohatším kontextom, čo umožňuje aplikácie ako automatizované spracovanie dokumentov a vizuálne vyhľadávanie. Vylepšenia spracovania v reálnom čase vďaka distilácii modelov a nasadzovaniu na edge zariadeniach umožňujú sofistikované rozpoznávanie entít aj na mobilných zariadeniach a IoT systémoch, otvárajúc nové možnosti v rozšírenej realite, preklade v reálnom čase a autonómnych systémoch. Pokroky v doménovo špecifickom doladení umožňujú vznik modelov pre biomedicínu, právo či financie, ktoré prekonávajú všeobecné modely o rády, pričom techniky ako doménovo adaptívne predtrénovanie a transfer learning tieto možnosti čoraz viac sprístupňujú. Ako tieto technológie dozrievajú, porozumenie entít sa stane neviditeľnou základnou vrstvou v AI systémoch, umožňujúc strojom chápať svet s ľudským sémantickým porozumením a otvárajúc možnosti, ktoré si dnes ešte len začíname predstavovať.
Ako sa AI systémy ako ChatGPT, Perplexity a Google AI Overviews čoraz viac integrujú do spôsobu, akým ľudia objavujú a konzumujú informácie, rozumieť tomu, ako tieto systémy rozpoznávajú a odkazujú na entity—vrátane vašej značky—sa stáva kľúčovým. Porozumenie entít je mechanizmus, ktorým AI systémy identifikujú a spracúvajú zmienky o firmách, produktoch, ľuďoch a pojmoch. Keď monitorujete, ako AI systémy rozumejú a odkazujú na vašu značku prostredníctvom rozpoznávania entít, získavate prehľad o tom:
Práve toto AmICited monitoruje—sleduje, ako AI systémy rozpoznávajú a odkazujú na vašu značku ako entitu naprieč viacerými AI platformami. Porozumením rozpoznávaniu entít môžete lepšie pochopiť, ako AI systémy vnímajú a komunikujú o vašom podnikaní.
Rozpoznávanie entít (NER) identifikuje a klasifikuje entity v texte (napr. 'Apple' ako ORGANIZÁCIA), zatiaľ čo prepojenie entít spája tieto entity so znalostnými bázami alebo kanonickými odkazmi (napr. prepojenie 'Apple' na stránku Wikipedia pre Apple Inc.). Rozpoznávanie entít je prvý krok; prepojenie entít pridáva sémantické zakotvenie.
Špičkové modely založené na transformeroch ako BERT dosahujú 90,9 % F1 skóre na štandardných benchmarkoch ako CoNLL-2003. Presnosť sa však výrazne líši podľa domény—modely trénované na správach dosahujú horšie výsledky na biomedicínskom alebo textoch zo sociálnych médií. Skutočná presnosť závisí najmä od adaptácie na doménu a kvality dát.
Áno, viacjazyčné modely ako mBERT a XLM-RoBERTa podporujú viac ako 100 jazykov súčasne. Výkon sa však mení v závislosti od jazyka kvôli rozdielom v konvenciách kapitalizácie, morfológii a dostupnosti tréningových dát. Jazykovo špecifické modely zvyčajne prekonávajú viacjazyčné pri kritických aplikáciách.
Pravidlové systémy používajú ručne vytvárané vzory a slovníky (rýchle, interpretovateľné, ale krehké). ML-systémy sa učia zo značených dát (flexibilnejšie, lepšie generalizujú, ale potrebujú tréningové dáta a návrh vlastností). Moderné hlboké učenie automatizuje extrakciu čŕt a dosahuje vyššiu presnosť.
Pravidlové systémy potrebujú len definície vzorov. Tradičné ML modely vyžadujú 300-500 označených príkladov. Modely založené na transformeroch fungujú s 800+ príkladmi, ale ťažia z transfer learningu—predtrénované modely môžu dosiahnuť dobré výsledky už so 100-200 doménovo špecifickými príkladmi pomocou doladenia.
Kľúčové výzvy sú: viacvýznamovosť (to isté slovo znamená rôzne veci), entity mimo slovníka, adaptácia na doménu (modely trénované na jednej doméne zlyhávajú v inej), chyby pri určovaní hraníc, viacjazyčné komplikácie a nedostatok dát pre špecializované domény. Vyžaduje si to starostlivý návrh systému a ladenie na mieru doméne.
Kontext je kľúčový—'banka' znamená niečo iné v 'riečna banka' než v 'sporiteľná banka'. Moderné transformery používajú self-attention na zváženie kontextu všetkých okolitých tokenov, čo im umožňuje rozlíšiť entity na základe jazykového a sémantického kontextu. Slabé zvládanie kontextu je hlavnou príčinou chýb v rozpoznávaní entít.
Budúci vývoj zahŕňa: veľké jazykové modely umožňujúce zero-shot rozpoznávanie entít, multimodálne porozumenie kombinujúce text a obrázky, spracovanie v reálnom čase na edge zariadeniach a pokrok v doménovo špecifickom doladení. Porozumenie entít sa stane neviditeľnou základnou vrstvou, ktorá umožní strojom chápať svet s ľudským sémantickým porozumením.
AmICited sleduje zmienky o entitách naprieč AI systémami ako ChatGPT, Perplexity a Google AI Overviews. Zistite, ako AI rozumie a odkazuje na vašu značku v reálnom čase.
Rozpoznávanie entít je schopnosť AI a NLP identifikovať a kategorizovať pomenované entity v texte. Zistite, ako funguje, jeho využitie v AI monitoringu a jeho ú...

Zistite, ako budovať viditeľnosť entity vo vyhľadávaní cez AI. Ovládnite optimalizáciu znalostného grafu, schému a stratégie entity SEO pre zvýšenie prítomnosti...

Zistite, ako AI systémy identifikujú, extrahujú a chápu vzťahy medzi entitami v texte. Objavte techniky extrakcie vzťahov entít, NLP metódy a reálne aplikácie....