
Kompletný sprievodca blokovaním (alebo povoľovaním) AI crawlerov
Naučte sa, ako blokovať alebo povoliť AI crawlery ako GPTBot a ClaudeBot pomocou robots.txt, serverového blokovania a pokročilých ochranných metód. Kompletný te...
7 min čítania
Naučte sa, ako implementovať selektívne blokovanie AI crawlerov na ochranu vášho obsahu pred trénovacími botmi a zároveň zachovať viditeľnosť vo výsledkoch AI vyhľadávania. Technické stratégie pre vydavateľov.
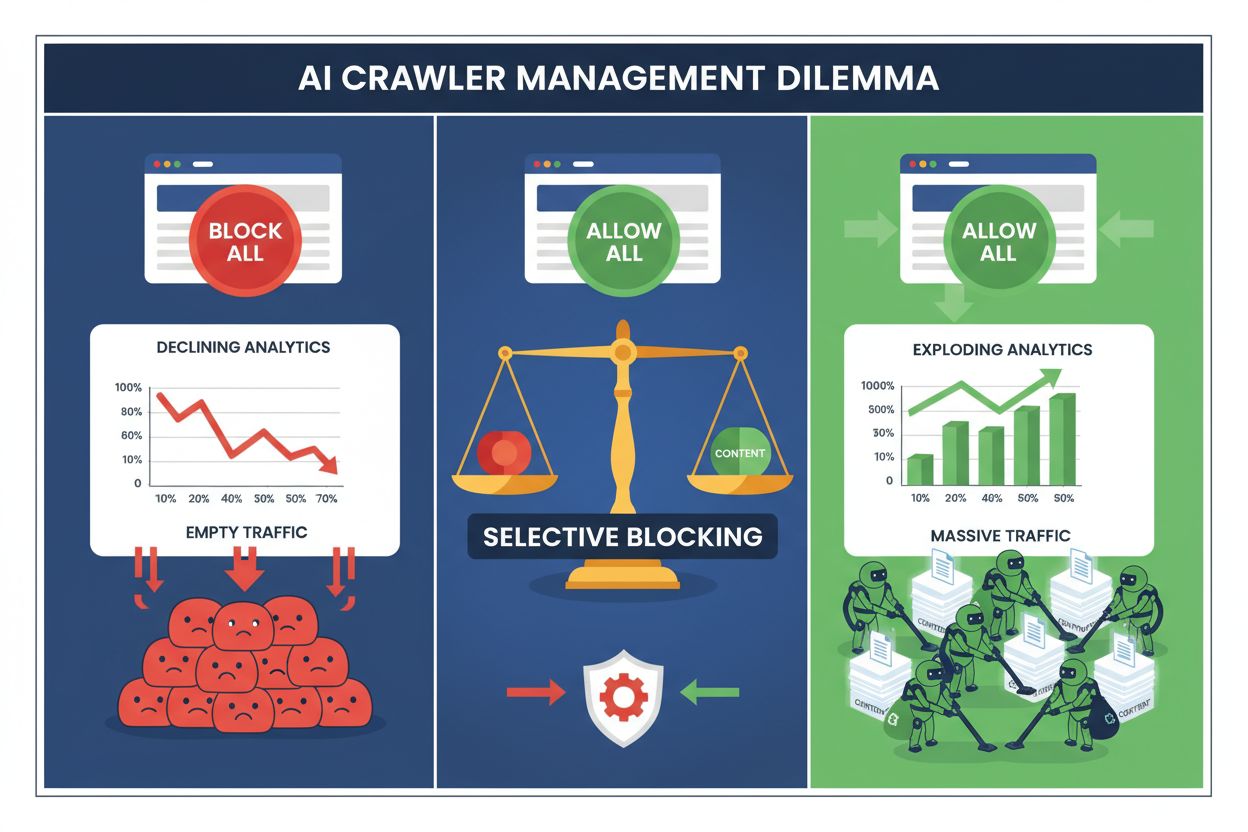
Vydavatelia dnes čelia nemožnej voľbe: zablokovať všetky AI crawlery a prísť o cennú návštevnosť z vyhľadávačov, alebo ich všetky povoliť a sledovať, ako ich obsah bez náhrady poháňa trénovacie datasety. Vzostup generatívnej AI vytvoril rozdelený ekosystém crawlerov, kde tie isté pravidlá robots.txt platia nerozlišujúco pre vyhľadávače, ktoré generujú príjmy, aj pre trénovacie crawlery, ktoré len odoberajú hodnotu. Tento paradox prinútil progresívnych vydavateľov vyvíjať selektívne stratégie kontroly crawlerov, ktoré rozlišujú medzi rôznymi typmi AI botov na základe ich skutočného vplyvu na obchodné metriky.
Spektrum AI crawlerov sa delí na dve odlišné kategórie s úplne iným účelom a obchodným dopadom. Trénovacie crawlery – prevádzkované spoločnosťami ako OpenAI, Anthropic a Google – sú navrhnuté na získavanie obrovského množstva textových dát na budovanie a zlepšovanie veľkých jazykových modelov, zatiaľ čo vyhľadávacie crawlery indexujú obsah na vyhľadávanie a objavovanie. Trénovacie boty tvoria približne 80 % všetkej AI súvisiacej robotickej aktivity, no neprinášajú vydavateľom žiadny priamy príjem, zatiaľ čo vyhľadávacie crawlery ako Googlebot a Bingbot každý rok privádzajú milióny návštev a reklamných zobrazení. Rozdiel je zásadný, pretože jediný trénovací crawler môže spotrebovať šírku pásma rovnajúcu sa tisícom ľudských užívateľov, pričom vyhľadávacie crawlery sú optimalizované na efektivitu a obvykle rešpektujú limity zaťaženia.
| Názov bota | Operátor | Primárny účel | Potenciál návštevnosti |
|---|---|---|---|
| GPTBot | OpenAI | Tréning modelov | Žiadny (extrakcia dát) |
| Claude Web Crawler | Anthropic | Tréning modelov | Žiadny (extrakcia dát) |
| Googlebot | Indexácia vyhľadávania | 243,8M návštev (apríl 2025) | |
| Bingbot | Microsoft | Indexácia vyhľadávania | 45,2M návštev (apríl 2025) |
| Perplexity Bot | Perplexity AI | Vyhľadávanie + trénovanie | 12,1M návštev (apríl 2025) |
Údaje sú jasné: crawler ChatGPT sám poslal v apríli 2025 vydavateľom 243,8 milióna návštev, no tieto návštevy priniesli nulové kliknutia, nulové reklamné zobrazenia a nulový príjem. Medzitým návštevnosť z Googlebota konvertovala na skutočný záujem užívateľov a príležitosti na monetizáciu. Pochopenie tohto rozdielu je prvým krokom k implementácii selektívnej blokovacej stratégie, ktorá chráni váš obsah a zároveň zachováva vašu viditeľnosť vo vyhľadávaní.
Plošné blokovanie všetkých AI crawlerov je pre väčšinu vydavateľov ekonomicky sebadeštruktívne. Zatiaľ čo trénovacie crawlery odoberajú hodnotu bez náhrady, vyhľadávacie crawlery zostávajú jedným z najspoľahlivejších zdrojov návštevnosti v čoraz fragmentovanejšom digitálnom prostredí. Finančný argument pre selektívne blokovanie stojí na niekoľkých kľúčových faktoroch:
Vydavatelia, ktorí zaviedli selektívne blokovanie, uvádzajú, že si udržali alebo zlepšili návštevnosť z vyhľadávačov a zároveň znížili neautorizovanú extrakciu obsahu až o 85 %. Strategický prístup uznáva, že nie všetky AI crawlery sú rovnaké, a že nuansovaná politika lepšie slúži obchodným záujmom ako prístup “spálenej zeme”.
Súbor robots.txt zostáva hlavným mechanizmom na komunikáciu povolení crawlerom a pri správnej konfigurácii je prekvapivo účinný pri rozlišovaní medzi rôznymi typmi robotov. Tento jednoduchý textový súbor, umiestnený v koreňovom adresári vašej stránky, používa direktívy user-agent na určenie, ktoré crawlery majú prístup k akému obsahu. Pri selektívnej kontrole AI crawlerov môžete povoliť vyhľadávače a zároveň presne zablokovať trénovacie crawlery.
Praktický príklad, ktorý blokuje trénovacie crawlery a zároveň povolí vyhľadávače:
# Blokovať GPTBot od OpenAI
User-agent: GPTBot
Disallow: /
# Blokovať Claude crawler od Anthropic
User-agent: Claude-Web
Disallow: /
# Blokovať ďalšie trénovacie crawlery
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Povoliť vyhľadávače
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Tento prístup poskytuje jasné inštrukcie dobre sa správajúcim crawlerom a zároveň zachováva objaviteľnosť vášho webu vo výsledkoch vyhľadávania. Robots.txt je však v podstate dobrovoľný štandard – spolieha sa na to, že operátori crawlerov budú rešpektovať vaše pokyny. Pre vydavateľov, ktorí si potrpia na dodržiavanie pravidiel, sú potrebné ďalšie vynucovacie vrstvy.
Samo robots.txt nedokáže zaručiť dodržiavanie, pretože približne 13 % AI crawlerov ignoruje pokyny robots.txt úplne, či už z nedbanlivosti alebo úmyselného obchádzania. Vynucovanie na úrovni webového servera alebo aplikačnej vrstvy poskytuje technickú zábranu, ktorá zabraňuje neautorizovanému prístupu bez ohľadu na správanie crawlera. Tento prístup blokuje požiadavky na úrovni HTTP ešte predtým, než spotrebujú výrazné množstvo šírky pásma alebo systémových zdrojov.
Implementácia blokovania na úrovni servera cez Nginx je jednoduchá a veľmi účinná:
# V server bloku Nginxu
location / {
# Blokovať trénovacie crawlery na úrovni servera
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Blokovať podľa rozsahov IP (pre crawlery, ktoré spoofujú user-agentov)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Pokračovať v bežnom spracovaní požiadaviek
proxy_pass http://backend;
}
Táto konfigurácia vracia odpoveď 403 Forbidden blokovaným crawlerom, spotrebuje minimum serverových zdrojov a jasne komunikuje, že prístup je odmietnutý. V kombinácii s robots.txt vytvára vynucovanie na úrovni servera dvojvrstvovú obranu, ktorá zachytí poslušné aj nevyhovujúce crawlery. Miera obchádzania 13 % klesá na takmer nulu, keď sú serverové pravidlá správne implementované.
Siete na doručovanie obsahu (CDN) a webové aplikačné firewally poskytujú ďalšiu vrstvu vynucovania, ktorá funguje ešte predtým, než požiadavky dorazia na vaše pôvodné servery. Služby ako Cloudflare, Akamai a AWS WAF umožňujú vytvárať pravidlá, ktoré blokujú konkrétnych user agentov alebo rozsahy IP adries na edge úrovni a bránia škodlivým či nežiadaným crawlerom spotrebovávať vaše infraštruktúrne zdroje. Tieto služby udržiavajú aktualizované zoznamy známych trénovacích crawlerov podľa IP a user-agenta a automaticky ich blokujú bez potreby manuálnej konfigurácie.
Kontroly na úrovni CDN majú oproti serverovému vynucovaniu niekoľko výhod: znižujú záťaž na pôvodné servery, poskytujú geografické blokovanie a ponúkajú prehľady o blokovaných požiadavkách v reálnom čase. Mnohé CDN už ponúkajú AI-špecifické blokovacie pravidlá ako štandard, keďže otázka neautorizovanej extrakcie dát trápi čoraz viac vydavateľov. Pre používateľov Cloudflare stačí povoliť možnosť “Block AI Crawlers” v nastaveniach zabezpečenia, čím získate jedným kliknutím ochranu pred hlavnými trénovacími crawlermi a zároveň zachováte prístup vyhľadávačov.
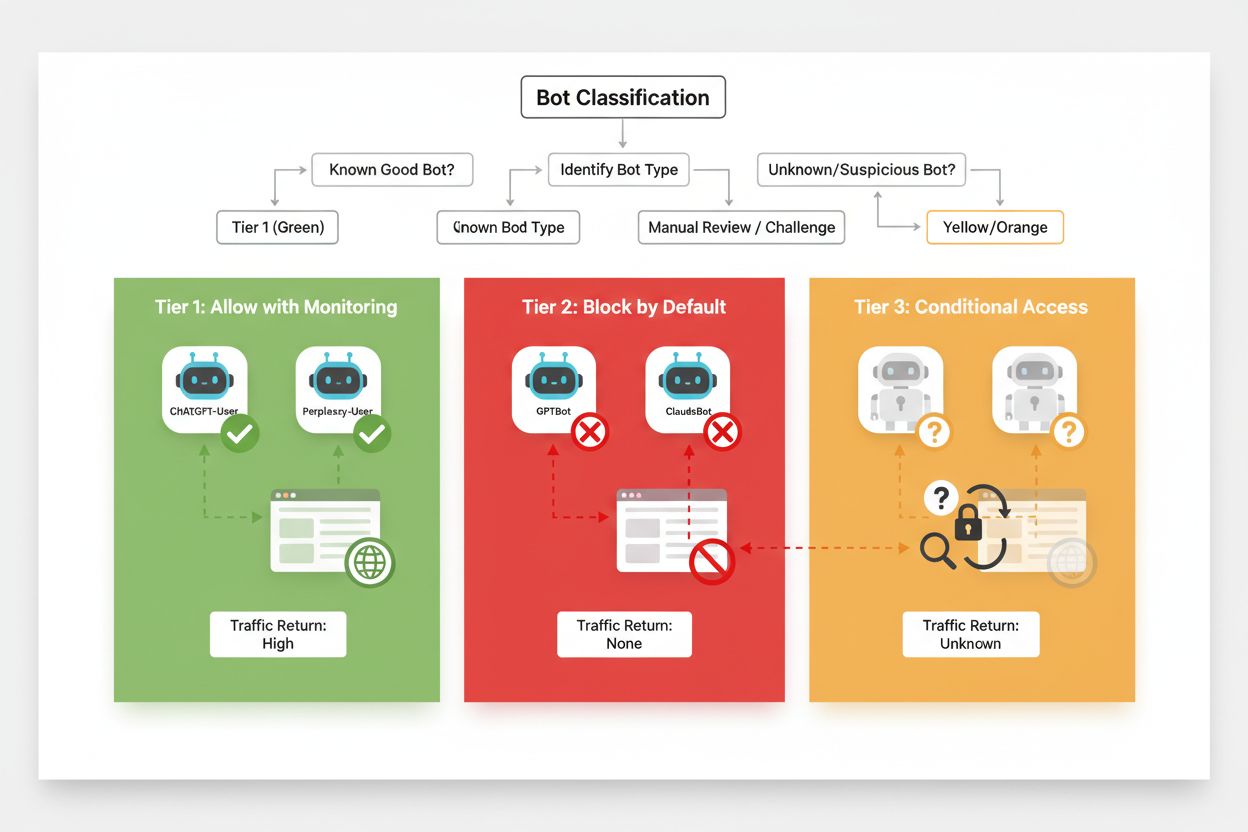
Efektívne selektívne blokovanie si vyžaduje systematický prístup ku klasifikácii crawlerov na základe ich dopadu na obchod a dôveryhodnosti. Namiesto jednotného prístupu by mali vydavatelia implementovať trojstupňový rámec, ktorý odráža skutočný prínos a riziko každého crawlera. Tento rámec umožňuje nuansované rozhodovanie, ktoré vyvažuje ochranu obsahu s obchodnou príležitosťou.
| Úroveň | Klasifikácia | Príklady | Akcia |
|---|---|---|---|
| Úroveň 1: Generátori príjmov | Vyhľadávače a zdroje veľkej návštevnosti | Googlebot, Bingbot, Perplexity Bot | Povoliť všetok prístup, optimalizovať pre crawlery |
| Úroveň 2: Neutrálne/nepreukázané | Nové alebo vznikajúce crawlery s nejasným zámerom | Menšie AI startupy, výskumné boty | Pozorne monitorovať, povoliť s limity rýchlosti |
| Úroveň 3: Odoberatelia hodnoty | Trénovacie crawlery bez priameho prínosu | GPTBot, Claude-Web, CCBot | Úplne zablokovať, vynucovať na viacerých vrstvách |
Implementácia tohto rámca si vyžaduje nepretržitý výskum nových crawlerov a ich obchodných modelov. Vydavatelia by mali pravidelne auditovať svoje logy prístupov, identifikovať nové boty, skúmať podmienky služieb ich prevádzkovateľov a upravovať klasifikáciu podľa potreby. Crawler, ktorý začína ako úroveň 3, sa môže posunúť do úrovne 2, ak jeho prevádzkovateľ začne ponúkať podiel na príjmoch, zatiaľ čo predtým dôveryhodný crawler môže klesnúť na úroveň 3, ak začne porušovať limity či robots.txt.
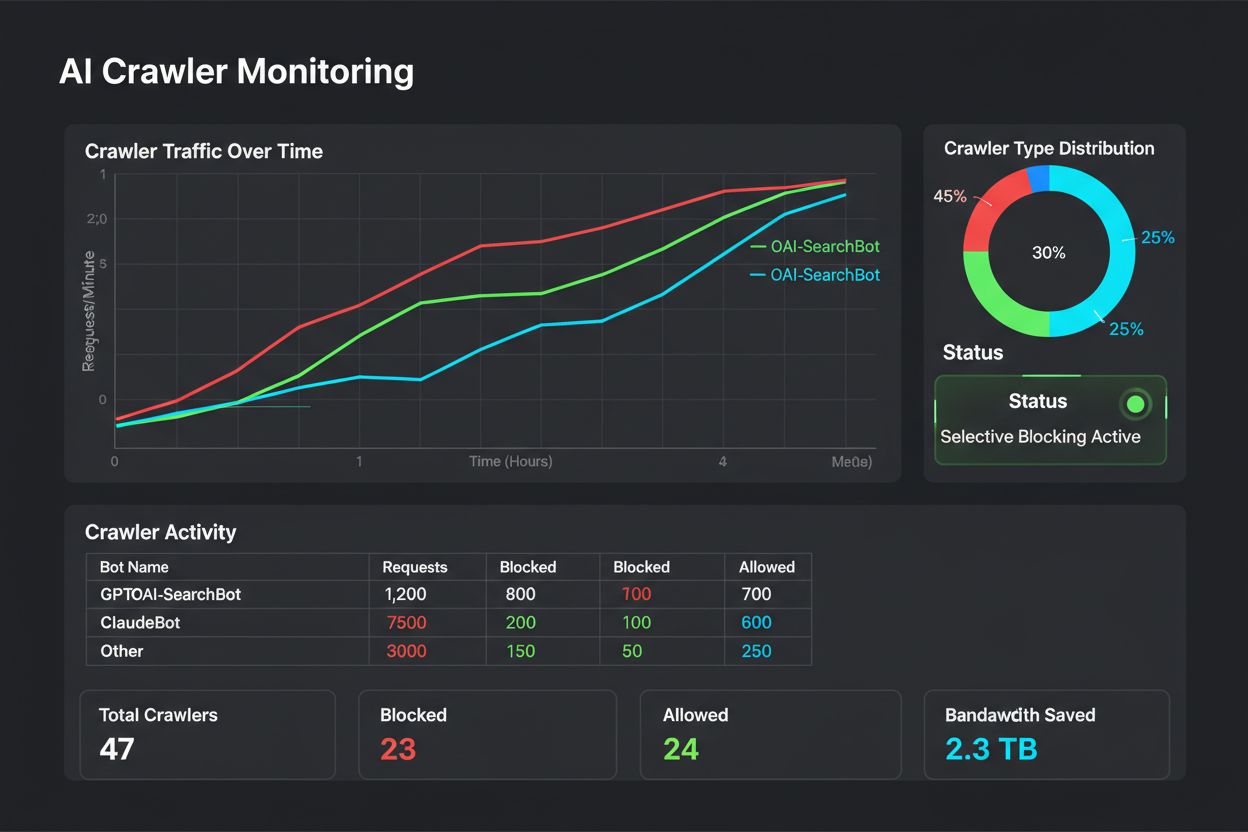
Selektívne blokovanie nie je jednorazová konfigurácia – vyžaduje pravidelné monitorovanie a úpravy podľa toho, ako sa ekosystém crawlerov vyvíja. Vydavatelia by mali implementovať komplexné logovanie a analýzu, aby vedeli, ktoré crawlery pristupujú k ich obsahu, koľko šírky pásma spotrebujú a či rešpektujú nastavené obmedzenia. Tieto dáta informujú o strategických rozhodnutiach, ktoré crawlery povoliť, zablokovať alebo limitovať.
Analýza prístupových logov odhalí vzorce správania crawlerov, ktoré ovplyvňujú úpravu politiky:
# Identifikovať všetky AI crawlery pristupujúce na web
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Vypočítať prenos dát spotrebovaný konkrétnymi crawlermi
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot bandwidth: " sum/1024/1024 " MB"}'
# Monitorovať 403 odpovede pre blokované crawlery
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Pravidelná analýza týchto údajov – ideálne týždenne alebo mesačne – odhalí, či vaša blokovacia stratégia funguje, či sa objavili nové crawlery a či niektoré predtým blokované crawlery nezmenili svoje správanie. Tieto informácie sa vracajú do vášho klasifikačného rámca, aby vaše politiky zostali v súlade s obchodnými cieľmi a technickou realitou.
Vydavatelia, ktorí implementujú selektívne blokovanie crawlerov, často robia chyby, ktoré ich stratégiu oslabujú alebo spôsobujú nežiaduce dôsledky. Pochopenie týchto nástrah vám pomôže vyhnúť sa drahým chybám a od začiatku zaviesť účinnejšiu politiku.
Indiskriminátne blokovanie všetkých crawlerov: Najčastejšou chybou je použitie príliš širokých blokovacích pravidiel, ktoré spolu s trénovacími crawlermi zablokujú aj vyhľadávače, čím zničia viditeľnosť vo vyhľadávaní v snahe chrániť obsah.
Spoliehanie sa len na robots.txt: Predpokladať, že robots.txt sám zabráni neautorizovanému prístupu, ignoruje 13 % crawlerov, ktoré ho úplne ignorujú, čím zostáva váš obsah zraniteľný voči odhodlaným extraktorom dát.
Nemonitorovanie a neupravovanie: Zavedenie statickej blokovacej politiky bez jej revízie znamená, že prehliadate nové crawlery, neprispôsobujete sa meniacim obchodným modelom a možno blokujete užitočné crawlery, ktoré zlepšili svoje praktiky.
Blokovanie len podľa user-agenta: Sofistikované crawlery spoofujú user-agentov alebo ich často menia, takže blokovanie len podľa user-agenta je neúčinné bez doplňujúcich IP pravidiel a limitovania rýchlosti.
Ignorovanie limitovania rýchlosti: Aj povolené crawlery môžu spotrebovať neprimerane veľa šírky pásma, ak nie sú limitované, čo zhoršuje výkon pre ľudských užívateľov a zbytočne zaťažuje infraštruktúru.
Budúcnosť vzťahov medzi vydavateľmi a AI crawlermi bude pravdepodobne zahŕňať sofistikovanejšie vyjednávanie a modely kompenzácie, nie len jednoduché blokovanie. Kým však nevzniknú odvetvové štandardy, selektívna kontrola crawlerov zostáva najpraktickejším spôsobom ochrany obsahu pri zachovaní viditeľnosti vo vyhľadávaní. Vydavatelia by mali svoju blokovaciu stratégiu vnímať ako dynamickú politiku, ktorá sa vyvíja spolu s ekosystémom crawlerov a pravidelne prehodnocovať, ktoré crawlery si zaslúžia prístup na základe ich obchodného dopadu a dôveryhodnosti.
Najúspešnejší budú tí vydavatelia, ktorí implementujú viacvrstvovú ochranu – kombináciu robots.txt pravidiel, vynucovania na úrovni servera, CDN kontrol a neustáleho monitorovania v rámci komplexnej stratégie. Tento prístup chráni pred poslušnými aj nevyhovujúcimi crawlermi a zároveň zachováva návštevnosť z vyhľadávačov, ktorá generuje príjmy a záujem užívateľov. S tým, ako AI spoločnosti čoraz viac uznávajú hodnotu vydavateľského obsahu a začnú ponúkať kompenzácie alebo licenčné dohody, rámec, ktorý vybudujete dnes, sa ľahko prispôsobí novým obchodným modelom a zároveň zachová kontrolu nad vašimi digitálnymi aktívami.
Trénovacie crawlery ako GPTBot a ClaudeBot zbierajú dáta na tvorbu AI modelov bez toho, aby vracali návštevnosť na váš web. Vyhľadávacie crawlery ako OAI-SearchBot a PerplexityBot indexujú obsah pre AI vyhľadávače a môžu priviesť výraznú návštevnosť späť na váš web. Pochopenie tohto rozdielu je kľúčové pre efektívnu selektívnu blokovaciu stratégiu.
Áno, toto je základná stratégia selektívnej kontroly crawlerov. Môžete použiť robots.txt na zakázanie trénovacích botov a zároveň povoliť vyhľadávacie boty, následne to vynútiť na úrovni servera pre boty, ktoré robots.txt ignorujú. Tento prístup chráni váš obsah pred neautorizovaným trénovaním a zároveň zachováva vašu viditeľnosť vo výsledkoch AI vyhľadávania.
Väčšina veľkých AI spoločností tvrdí, že rešpektuje robots.txt, ale dodržiavanie je dobrovoľné. Výskumy ukazujú, že približne 13 % AI botov úplne ignoruje pokyny robots.txt. Preto je vynucovanie na úrovni servera nevyhnutné pre vydavateľov, ktorí to s ochranou svojho obsahu pred nevyhovujúcimi crawlermi myslia vážne.
Významne a rastúco. ChatGPT poslal 243,8 milióna návštev na 250 spravodajských a mediálnych webov v apríli 2025, čo je nárast o 98 % od januára. Blokovanie týchto crawlerov znamená stratu tohto nového zdroja návštevnosti. Pre mnohých vydavateľov dnes AI vyhľadávacia návštevnosť predstavuje 5-15 % z celkovej odporúčanej návštevnosti.
Pravidelne prezerajte serverové logy pomocou grep príkazov na identifikáciu bot user agentov, sledujte frekvenciu crawlovania a monitorujte dodržiavanie pravidiel robots.txt. Prezerajte logy aspoň mesačne, aby ste zistili nové boty, nezvyčajné vzory správania a či blokované boty skutočne zostávajú mimo. Tieto údaje informujú o strategických rozhodnutiach vašej crawler politiky.
Ochrániťe svoj obsah pred neautorizovaným trénovaním, ale stratíte viditeľnosť vo výsledkoch AI vyhľadávania, prídete o nové zdroje návštevnosti a potenciálne znížite zmienky o vašej značke v AI generovaných odpovediach. Vydavatelia, ktorí zavedú plošné blokovanie, často zaznamenajú zníženie viditeľnosti vo vyhľadávaní o 40-60 % a prídu o príležitosti na objavenie značky prostredníctvom AI platforiem.
Aspoň mesačne, pretože neustále vznikajú nové boty a existujúce menia svoje správanie. Ekosystém AI crawlerov sa rýchlo mení, nové subjekty spúšťajú crawlery a existujúci hráči ich zlúčujú alebo premenúvajú. Pravidelné revízie zabezpečia, že vaša politika zostane v súlade s obchodnými cieľmi aj technickou realitou.
Je to počet stránok, ktoré crawler prejde, v porovnaní s počtom návštevníkov, ktorých pošle späť na váš web. Anthropic prejde 38 000 stránok na jedného návštevníka, ktorého odporučí späť, OpenAI udržiava pomer 1 091:1 a Perplexity má 194:1. Nižší pomer znamená lepšiu hodnotu za povolenie crawlera. Táto metrika vám pomáha rozhodnúť, ktoré crawlery si zaslúžia prístup na základe ich skutočného obchodného vplyvu.
AmICited sleduje, ktoré AI platformy citujú vašu značku a obsah. Získajte prehľad o svojej AI viditeľnosti a zabezpečte správne pripísanie naprieč ChatGPT, Perplexity, Google AI Overviews a ďalšími.
Naučte sa, ako blokovať alebo povoliť AI crawlery ako GPTBot a ClaudeBot pomocou robots.txt, serverového blokovania a pokročilých ochranných metód. Kompletný te...

Kompletný referenčný sprievodca AI crawlermi a botmi. Identifikujte GPTBot, ClaudeBot, Google-Extended a viac ako 20 ďalších AI crawlerov s user agentmi, rýchlo...

Zistite, ktorým AI crawlerom povoliť alebo zablokovať prístup vo vašom robots.txt. Komplexný sprievodca pokrývajúci GPTBot, ClaudeBot, PerplexityBot a ďalších 2...