
Ako riešiť duplicitný obsah pre AI vyhľadávače
Zistite, ako spravovať a predchádzať duplicitnému obsahu pri využívaní AI nástrojov. Objavte kanonické značky, presmerovania, nástroje na detekciu a najlepšie p...
11 min čítania

Zistite, ako kanonické URL adresy predchádzajú problémom s duplicitným obsahom v AI vyhľadávacích systémoch. Objavte najlepšie postupy implementácie kanoník na zvýšenie viditeľnosti v AI a zabezpečenie správneho pripisovania obsahu.
Veľké jazykové modely a AI vyhľadávacie systémy používajú sofistikované algoritmy na zhlukovanie, aby identifikovali a zoskupili takmer duplicitné URL adresy, pričom viaceré verzie toho istého obsahu považujú za jednu entitu na účely hodnotenia a citovania. Keď AI systémy narazia na duplicitný obsah, musia si vybrať, ktorú verziu uprednostnia — rozhodnutie, ktoré priamo ovplyvňuje, ktorá URL adresa získa viditeľnosť, autoritatívne signály a pripísanie od používateľa. Kritický problém nastáva, ak AI vyberie nesprávnu verziu: ak vaša kanonická URL smeruje na preferovanú stránku, ale AI systém zhlukuje a hodnotí namiesto toho menej kvalitnú duplicitu, váš obsah stráca viditeľnosť a kredit za citácie. Signály zámeru sa rozptyľujú na viaceré duplicitné verzie, fragmentujú autoritu, ktorá by sa mala sústrediť na jednu URL, pričom každá duplicita dostáva slabšie hodnotiace signály, než keby všetka autorita bola zjednotená na kanonickej verzii.
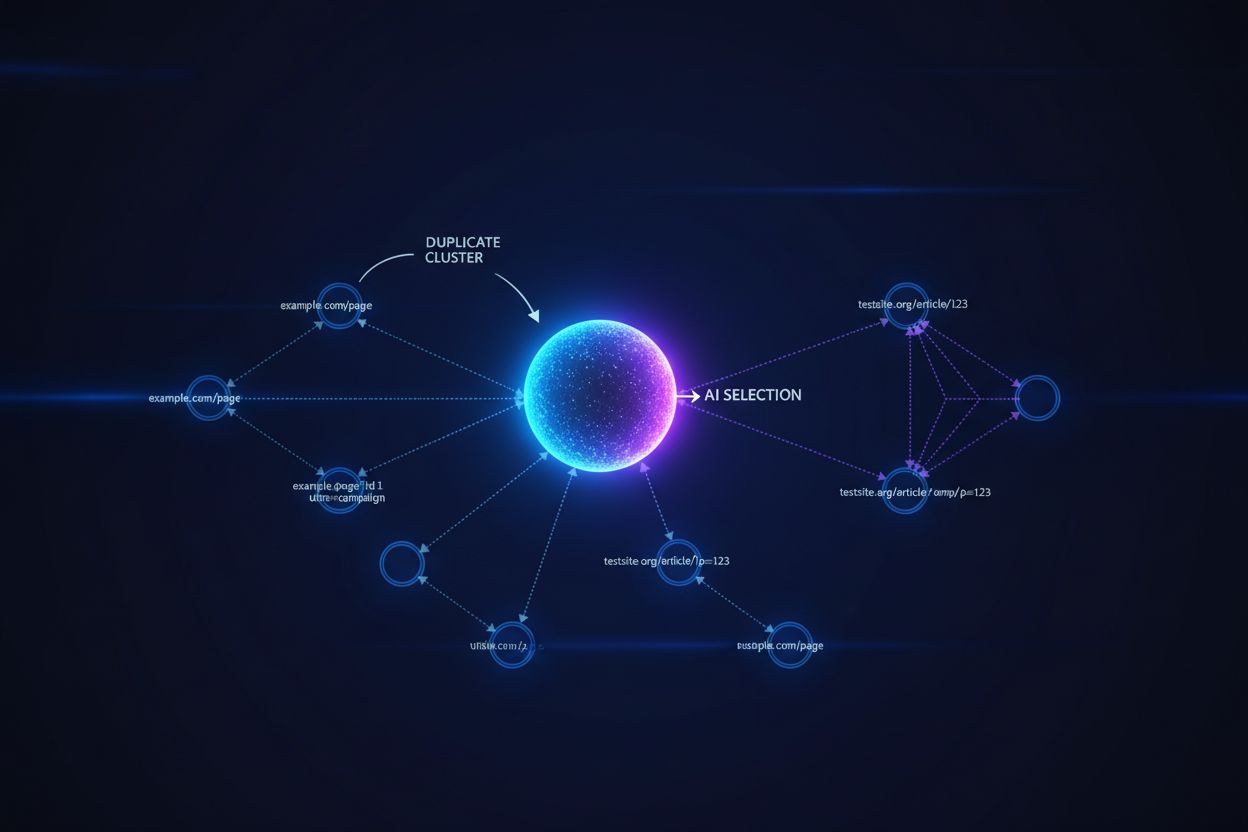
Kanonické tagy slúžia ako explicitné signály pre AI systémy, ktorá verzia duplicitného obsahu má byť považovaná za autoritatívnu, čím priamo ovplyvňujú, či sa vaša preferovaná URL objaví v AI-generovaných odpovediach a získa správne pripísanie. Bez kanonických tagov musia AI systémy robiť zhlukovacie rozhodnutia na základe podobnosti obsahu, vzorov odkazov a signálov aktuálnosti — čo často vedie k tomu, že za kanonický zdroj je vybratá nesprávna verzia. Ak existuje duplicitný obsah bez správneho kanonického označenia, AI odpovede môžu citovať syndikovanú verziu, cacheovanú kópiu alebo menej kvalitný variant namiesto vášho pôvodného obsahu, čím rozdeľujú vašu viditeľnosť medzi viaceré URL adresy. Kanonické URL zabezpečia, že keď AI systémy narazia na váš obsah na rôznych doménach, parametroch alebo verziách, rozumejú tomu, ktorá jediná URL si zaslúži kredit a má byť prezentovaná v odpovediach.
| Scenár | Bez kanonickej | S kanonickou |
|---|---|---|
| Vplyv na AI | AI zhlukuje duplicity nezávisle; môže vybrať nesprávnu verziu na hodnotenie | AI rozpozná jediný autoritatívny zdroj; konsoliduje všetky signály na kanonickú URL |
| Kredit za citácie | Pripísanie rozptýlené medzi viaceré URL; slabšia autorita na URL | Všetky citácie a autorita smerujú na kanonickú URL; silnejšia viditeľnosť |
| Výsledok | Obsah sa objaví v AI odpovediach, ale kredit získa nesprávna URL; fragmentovaná viditeľnosť | Preferovaná URL sa objaví v AI odpovediach so zjednotenými autoritatívnymi signálmi |
Kanonické tagy a presmerovania majú v správe duplicitného obsahu pre AI systémy odlišný účel: kanonické tagy signalizujú vyhľadávačom a AI systémom, ktorá verzia je preferovaná, pričom obe URL ostávajú prístupné, zatiaľ čo presmerovania natrvalo presúvajú používateľov a crawlerov z jednej URL na druhú. Presmerovania (301 pre trvalé presuny, 302 pre dočasné) sú silnejšie signály, pretože konsolidujú všetku autoritu na jednu URL a úplne odstránia duplicitu z webu, vďaka čomu sú ideálne, keď trvalo rušíte URL alebo konsolidujete domény. Kanonické tagy sú vhodnejšie, keď potrebujete z obchodných dôvodov udržať viacero URL — napríklad sledovanie parametrov kvôli analytike, zachovanie starších URL pre záložky používateľov, alebo poskytovanie rôznych verzií rôznym publikám — a zároveň signalizovať AI, ktorá verzia je autoritatívna. Presmerovania použite pri konsolidácii domén po migrácii, odstraňovaní zastaraných verzií alebo eliminovaní variantov parametrov, ktoré nemajú osobitný význam. Kanonické tagy použite, ak musíte udržať viacero URL, ale chcete zabrániť penalizácii za duplicitný obsah a zabezpečiť, že AI systémy chápu, ktorá verzia je preferovaná.
Kľúčové rozdiely medzi kanonikami a presmerovaniami:
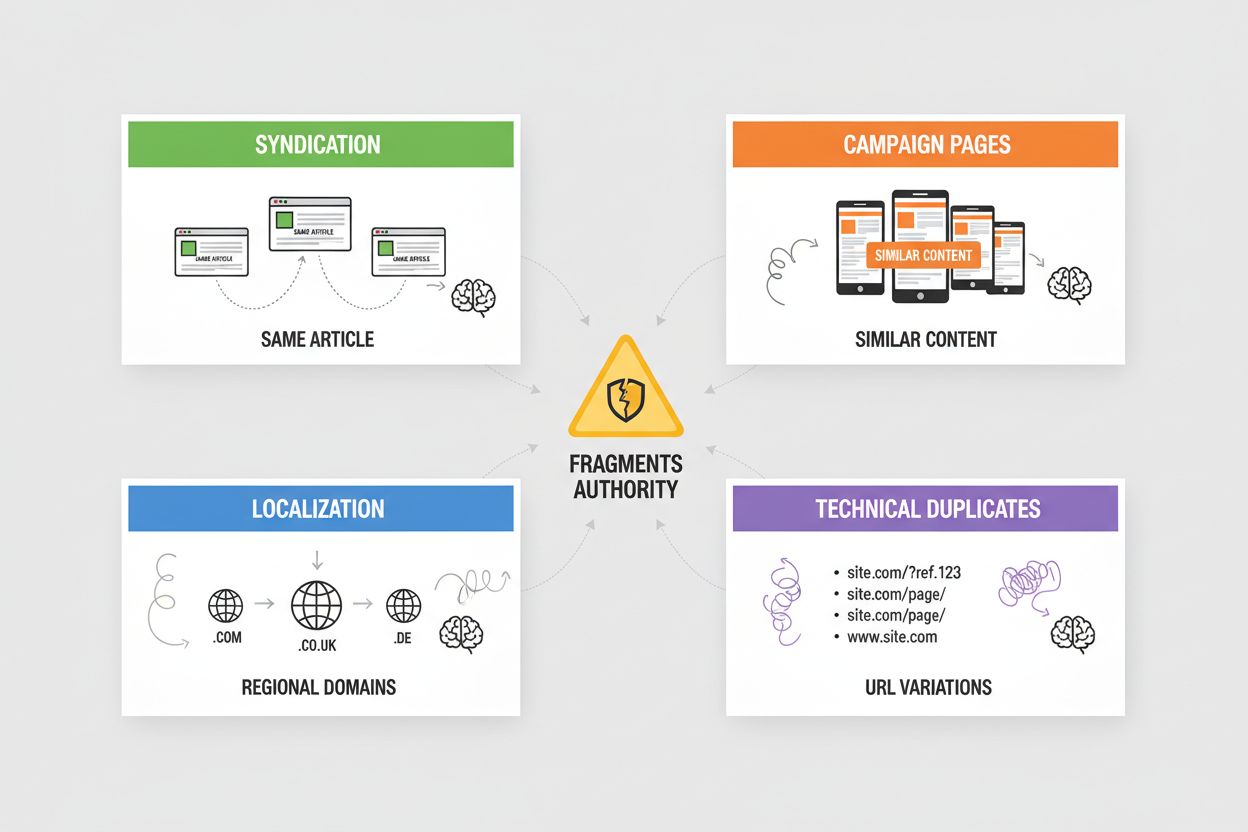
Syndikácia vytvára rozsiahly duplicitný obsah, keď sú vaše články publikované na partnerských stránkach, agregátoroch správ alebo v obsahových sieťach — AI systémy musia určiť, či kredit patrí pôvodnému zdroju alebo syndikovanej verzii, pričom často uprednostnia tú, ktorá sa objaví prvá pri crawlovaní. Kampaňové stránky generujú duplicity, keď vytvárate viacero landing stránok s rovnakým alebo takmer rovnakým obsahom pre rôzne marketingové kanály, UTM parametre alebo A/B testovanie, čo spôsobuje, že AI systémy fragmentujú autoritu medzi varianty, ktoré by mali byť konsolidované. Lokalizácia a internacionalizácia vytvára duplicity, keď poskytujete podobný obsah na regionálnych doménach (example.com, example.co.uk, example.de) alebo v jazykových verziách, čo si vyžaduje použitie hreflang tagov a kanoník, aby AI systémy tieto úpravy nepovažovali za duplicity, ale za zámerné varianty. Technické duplicity vznikajú zo session ID, sledovacích parametrov, tlačiteľných verzií a variácií URL (www verzus non-www, http verzus https, koncové lomky), ktoré vytvárajú viaceré URL s rovnakým obsahom — AI systémy ich vnímajú ako duplicity a musia určiť, ktorú verziu uprednostniť. Každý z týchto prípadov rozptyľuje autoritu, ktorá by sa mala sústrediť na vašu preferovanú URL, čím znižuje vašu viditeľnosť v AI-generovaných odpovediach a kredit za citácie sa rozdeľuje medzi viaceré verzie.
Vždy používajte absolútne URL vo svojich kanonických tagoch namiesto relatívnych URL, čím zabezpečíte, že AI systémy a vyhľadávače môžu jednoznačne identifikovať cieľovú URL bez ohľadu na to, kde sa tag nachádza. Zahrňte samoodkazujúce kanoniky na preferované stránky — aj stránky bez duplicít by mali odkazovať na seba ako na kanonické, aby AI systémy nepredpokladali kanoniky na základe vzorov odkazov či podobnosti obsahu. Umiestnite kanonické tagy do sekcie <head> v HTML dokumente a pre ne-HTML obsah (PDF, obrázky) implementujte kanoniky cez HTTP hlavičky, aby AI crawlery rozpoznali vašu preferenciu bez ohľadu na typ obsahu.
<!-- Správna implementácia kanoniky v HTML head -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
Zahrňte kanonické URL do svojich XML sitemapov na posilnenie toho, ktoré verzie sú autoritatívne, a párujte kanoniky s hreflang tagmi pri správe medzinárodného alebo lokalizovaného obsahu, aby AI systémy nepovažovali regionálne variácie za duplicity. Vyhnite sa bežným chybám: nikdy nevytvárajte kanonické reťazce (A→B→C), nikdy neodkazujte kanonikou na noindexované stránky a nikdy nepoužívajte kanoniku na manipuláciu s hodnotením smerovaním na nesúvisiaci obsah. Sledujte implementáciu kanoník pomocou nástrojov ako Google Search Console, Bing Webmaster Tools a AmICited.com na overenie, že AI systémy rozpoznávajú vaše preferované URL a správne pripisujú obsah.
<!-- Správna implementácia s hreflang pre medzinárodný obsah -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/article/canonical-urls-ai" />
<link rel="alternate" hreflang="de" href="https://example.de/artikel/canonical-urls-ai" />
Auditujte svoje kanonické URL prelezením celej stránky nástrojmi ako Screaming Frog, SEMrush alebo Ahrefs na identifikáciu stránok s chýbajúcimi kanonikami, rozbitými kanonickými reťazcami alebo kanonikami smerujúcimi na noindexované stránky — tieto problémy bránia AI systémom správne konsolidovať autoritu. Využite Správu pokrytia v Google Search Console na identifikáciu stránok s duplicitným obsahom a overenie, že Google rozpoznáva vaše kanonické preferencie, následne to porovnajte s Bing Webmaster Tools pre konzistenciu medzi AI vyhľadávacími systémami. Implementujte IndexNow a informujte vyhľadávače a AI crawlery okamžite pri pridaní, aktualizácii alebo odstránení kanonických tagov, čím urýchlite objavenie vašich preferencií namiesto čakania na prirodzené crawl cykly. Monitorujte AI citácie pomocou nástrojov ako AmICited.com a manuálnym vyhľadávaním v ChatGPT, Claude a Perplexity, aby ste overili, že vaše preferované URL získavajú kredit v AI-generovaných odpovediach — ak sú citované duplicity, prehodnoťte implementáciu kanoník a skontrolujte, či sú tagy správne naformátované a umiestnené. Pravidelne sledujte nový duplicitný obsah vznikajúci syndikáciou, spustením kampaní alebo technickými zmenami a implementujte kanoniky proaktívne, aby ste si zachovali konzistentnú AI viditeľnosť.
Kanonická URL adresa je preferovaná verzia stránky, ktorú chcete, aby vyhľadávače a AI systémy rozpoznali ako autoritatívnu. Je dôležitá pre AI vyhľadávanie, pretože LLM zhlukujú takmer duplicitné URL a vyberajú jednu verziu na reprezentáciu celého súboru. Bez správnej kanonickej implementácie môžu AI systémy citovať nesprávnu verziu vášho obsahu, čo rozdeľuje vašu viditeľnosť a pripísanie naprieč viacerými URL adresami.
AI systémy používajú zhlukovacie algoritmy na zoskupovanie takmer duplicitných URL do jednotných entít a potom vyberajú jednu verziu na reprezentáciu celého zhluku. Je to iné ako tradičné vyhľadávače, pretože AI odpovede vyžadujú jednu zdrojovú URL na pripísanie. Ak vaša kanonika nie je správne implementovaná, AI môže vybrať syndikovanú verziu, cacheovanú kópiu alebo menej kvalitný variant namiesto vašej preferovanej URL.
Kanonické tagy používajte vtedy, keď potrebujete z obchodných dôvodov udržať viacero URL (sledovacie parametre, staršie URL, rôzne publikum) a zároveň signalizovať preferenciu AI systémom. Presmerovania používajte vtedy, keď trvalo rušíte URL, konsolidujete domény alebo eliminujete varianty parametrov, ktoré nemajú zmysel. Presmerovania sú silnejšie signály, pretože úplne konsolidujú autoritu, zatiaľ čo kanoniky autoritu rozdeľujú, ale signalizujú preferenciu.
Najčastejšie problémy sú: syndikácia (znovu publikované články na partnerských stránkach), kampaňové stránky (viacero landing stránok s rovnakým obsahom), lokalizácia (podobný obsah na regionálnych doménach) a technické duplicity (URL parametre, session ID, koncové lomky). Každý z týchto prípadov rozdeľuje autoritu medzi viaceré URL a znižuje viditeľnosť v AI-generovaných odpovediach.
Vždy používajte absolútne URL (https://example.com/page, nie /page), umiestnite kanonické tagy do sekcie HTML head, zahrňte samoodkazujúce kanoniky na všetky stránky a vyhýbajte sa kanonickým reťazcom (A→B→C). Pre ne-HTML obsah, ako sú PDF, používajte HTTP hlavičky. Zahrňte kanoniky do svojho XML sitemapu a párujte ich s hreflang tagmi pre medzinárodný obsah.
Použite Google Search Console a Bing Webmaster Tools na overenie rozpoznania kanoník, monitorujte AI citácie pomocou AmICited.com a manuálne vyhľadávanie v ChatGPT/Claude/Perplexity a auditujte stránku nástrojmi ako Screaming Frog alebo SEMrush. Ak sú citované duplicity namiesto vášho kanoniku, prehodnoťte implementáciu a uistite sa, že tagy sú správne naformátované a umiestnené v HTML hlavičke.
IndexNow je protokol, ktorý okamžite informuje vyhľadávače a AI crawlery, keď pridáte, aktualizujete alebo odstránite kanonické tagy, namiesto čakania na prirodzené crawl cykly. Týmto zrýchľuje objavenie vašich kanonických preferencií a zabezpečuje, že AI systémy rýchlejšie rozpoznajú vaše preferované URL, čím skracuje čas, kedy sa duplicity objavujú v AI odpovediach.
Áno, kanonické tagy sú silné signály, ale nie direktívy. AI systémy môžu ignorovať vašu kanonickú preferenciu, ak určia, že iná verzia je autoritatívnejšia na základe kvality obsahu, vzorov odkazov, aktuálnosti alebo iných signálov. Preto je dôležitá správna implementácia v kombinácii so silným obsahom a autoritou – zvyšuje to pravdepodobnosť, že AI systémy budú rešpektovať vašu kanonickú preferenciu.
Sledujte, ako AI systémy ako ChatGPT, Claude a Perplexity citujú váš obsah. Uistite sa, že vaše kanonické URL adresy sú správne rozpoznané a vaša značka dostáva správne pripísanie v AI-generovaných odpovediach.
Zistite, ako spravovať a predchádzať duplicitnému obsahu pri využívaní AI nástrojov. Objavte kanonické značky, presmerovania, nástroje na detekciu a najlepšie p...
Diskusia komunity o tom, ako AI systémy pracujú s duplicitným obsahom inak ako tradičné vyhľadávače. SEO odborníci zdieľajú postrehy o jedinečnosti obsahu pre v...

Duplicitný obsah je identický alebo podobný obsah na viacerých URL adresách, ktorý mätie vyhľadávače a rozptyľuje autoritu hodnotenia. Zistite, ako ovplyvňuje S...