
Ako si vedú prípadové štúdie vo výsledkoch AI vyhľadávania
Zistite, ako sa prípadové štúdie umiestňujú vo vyhľadávačoch s AI ako ChatGPT, Perplexity a Google AI Overviews. Objavte, prečo systémy AI citujú prípadové štúd...
9 min čítania

Zistite, ako formátovať prípadové štúdie pre AI citácie. Objavte plán na štruktúrovanie úspešných príbehov, ktoré LLM citujú v AI Overview, ChatGPT a Perplexity.
AI systémy ako ChatGPT, Perplexity a Google AI Overviews zásadne menia spôsob, akým B2B zákazníci objavujú a overujú prípadové štúdie – no väčšina firiem ich stále publikuje vo formátoch, ktoré LLM ledva dokážu spracovať. Keď sa firemný zákazník opýta AI systému „Ktoré SaaS platformy najlepšie fungujú v našom prípade?“, systém prehľadáva milióny dokumentov, aby našiel relevantné dôkazy, no zle naformátované prípadové štúdie ostávajú pre tieto vyhľadávacie systémy neviditeľné. Vzniká tak kritická medzera: kým tradičné prípadové štúdie zvyšujú pravdepodobnosť výhry v neskorých fázach obchodov v priemere o 21 %, AI-optimalizované prípadové štúdie môžu zvýšiť pravdepodobnosť citácie o 28–40 %, ak sú správne štruktúrované pre strojové učenie. Víťazi v tomto novom prostredí chápu, že konkurenčná výhoda z vlastných dát prichádza vtedy, keď sú objaviteľné AI systémami, nielen ľudskými čitateľmi. Bez cielenej optimalizácie na LLM vyhľadávanie ostávajú vaše najpresvedčivejšie zákaznícke príbehy prakticky uzamknuté pred AI systémami, ktoré dnes ovplyvňujú viac než 60 % firemných nákupných rozhodnutí.
AI-pripravená prípadová štúdia nie je len dobre napísaný príbeh—je to strategicky štruktúrovaný dokument, ktorý slúži súčasne ľudským čitateľom aj modelom strojového učenia. Najefektívnejšie prípadové štúdie nasledujú jednotnú architektúru, ktorá umožňuje LLM extrahovať kľúčové informácie, pochopiť kontext a s istotou citovať vašu spoločnosť. Nižšie je základný plán, ktorý oddeľuje AI-objaviteľné prípadové štúdie od tých, ktoré sa vo vyhľadávacích systémoch stratia:
| Sekcia | Účel | AI optimalizácia |
|---|---|---|
| TL;DR Zhrnutie | Okamžitý kontext pre zaneprázdnených čitateľov | Umiestnené navrchu pre skorú konzumáciu tokenov; 50–75 slov |
| Zákaznícky profil | Rýchla identifikácia profilu spoločnosti | Štruktúrované ako: Odvetvie / Veľkosť spoločnosti / Lokalita / Rola |
| Obchodný kontext | Definovanie problému a trhová situácia | Používajte konzistentnú terminológiu; vyhnite sa variáciám žargónu |
| Ciele | Špecifické, merateľné ciele zákazníka | Formátujte ako číslovaný zoznam; uvádzajte kvantifikované ciele |
| Riešenie | Ako váš produkt/služba pokryl potrebu | Vysvetlite previazanie funkcií na benefity explicitne |
| Implementácia | Časová os, proces a detaily adopcie | Rozdeľte do fáz; uveďte trvanie a míľniky |
| Výsledky | Kvantifikované dopady a metriky | Uveďte ako: Metrika / Základ / Konečný stav / Zlepšenie % |
| Dôkazy | Dáta, screenshoty alebo nezávislé overenie | Pridajte tabuľky metrík; jasne uvádzajte zdroje |
| Citáty zákazníka | Autentický hlas a emočné potvrdenie | Priraďte meno, pozíciu, spoločnosť; po 1–2 vetách |
| Signály na ďalšie využitie | Interné prepojenia a cross-promo odkazy | Navrhnite súvisiace prípadovky, webináre či zdroje |
Táto štruktúra zaručuje, že každá sekcia slúži dvojitému účelu: je prirodzene čitateľná pre ľudí a zároveň poskytuje sémantickú jasnosť pre RAG (Retrieval-Augmented Generation) systémy používané modernými LLM. Konzistentnosť tohto formátu v celej knižnici prípadových štúdií výrazne uľahčuje AI systémom extrahovať porovnateľné údaje a s istotou citovať vašu spoločnosť.
Okrem štruktúry konkrétne formátovacie rozhodnutia dramaticky ovplyvňujú, či AI systémy vaše prípadové štúdie vôbec nájdu a citujú. LLM spracúvajú dokumenty inak než ľudia—neskrolujú alebo nepoužívajú vizuálnu hierarchiu ako čitatelia, ale sú veľmi citlivé na sémantické značky a konzistentné formátovacie vzory. Tu sú prvky, ktoré najviac zvyšujú AI vyhľadateľnosť:
Tieto formátovacie voľby neslúžia estetike—ide o zabezpečenie, že vaša prípadová štúdia je strojovo čitateľná, aby pri vyhľadávaní LLM vašej firmy bola práve tá vaša citovaná.
Najsofistikovanejší prístup k AI-pripraveným prípadovým štúdiám zahŕňa vloženie JSON schémy priamo do dokumentu alebo metadátovej vrstvy, čím vzniká dvojvrstvový model: ľudia čítajú príbeh, stroje spracúvajú štruktúrované dáta. JSON schémy poskytujú LLM jednoznačné, strojovo čitateľné reprezentácie kľúčových informácií prípadovej štúdie, čím dramaticky zvyšujú presnosť a relevantnosť citácií. Tu je príklad štruktúry:
{
"@context": "https://schema.org",
"@type": "CaseStudy",
"name": "Enterprise SaaS Platform Reduces Onboarding Time by 60%",
"customer": {
"name": "TechCorp Industries",
"industry": "Financial Services",
"companySize": "500-1000 employees",
"location": "San Francisco, CA"
},
"solution": {
"productName": "Your Product Name",
"category": "Workflow Automation",
"implementationDuration": "8 weeks"
},
"results": {
"metrics": [
{"name": "Onboarding Time Reduction", "baseline": "120 days", "final": "48 days", "improvement": "60%"},
{"name": "User Adoption Rate", "baseline": "45%", "final": "89%", "improvement": "97%"},
{"name": "Support Ticket Reduction", "baseline": "450/month", "final": "120/month", "improvement": "73%"}
]
},
"datePublished": "2024-01-15",
"author": {"@type": "Organization", "name": "Your Company"}
}
Implementáciou JSON schém kompatibilných so schema.org v podstate poskytujete LLM štandardizovaný spôsob, ako pochopiť a citovať vašu prípadovú štúdiu. Tento prístup sa hladko integruje s RAG systémami, AI modely tak môžu presne extrahovať metriky, rozumieť zákazníckemu kontextu a s vysokou dôverou pripísať citáciu vašej firme. Firmy využívajúce JSON-štruktúrované prípadové štúdie dosahujú 3–4x vyššiu presnosť citácií v AI odpovediach v porovnaní s čisto naratívnym formátom.
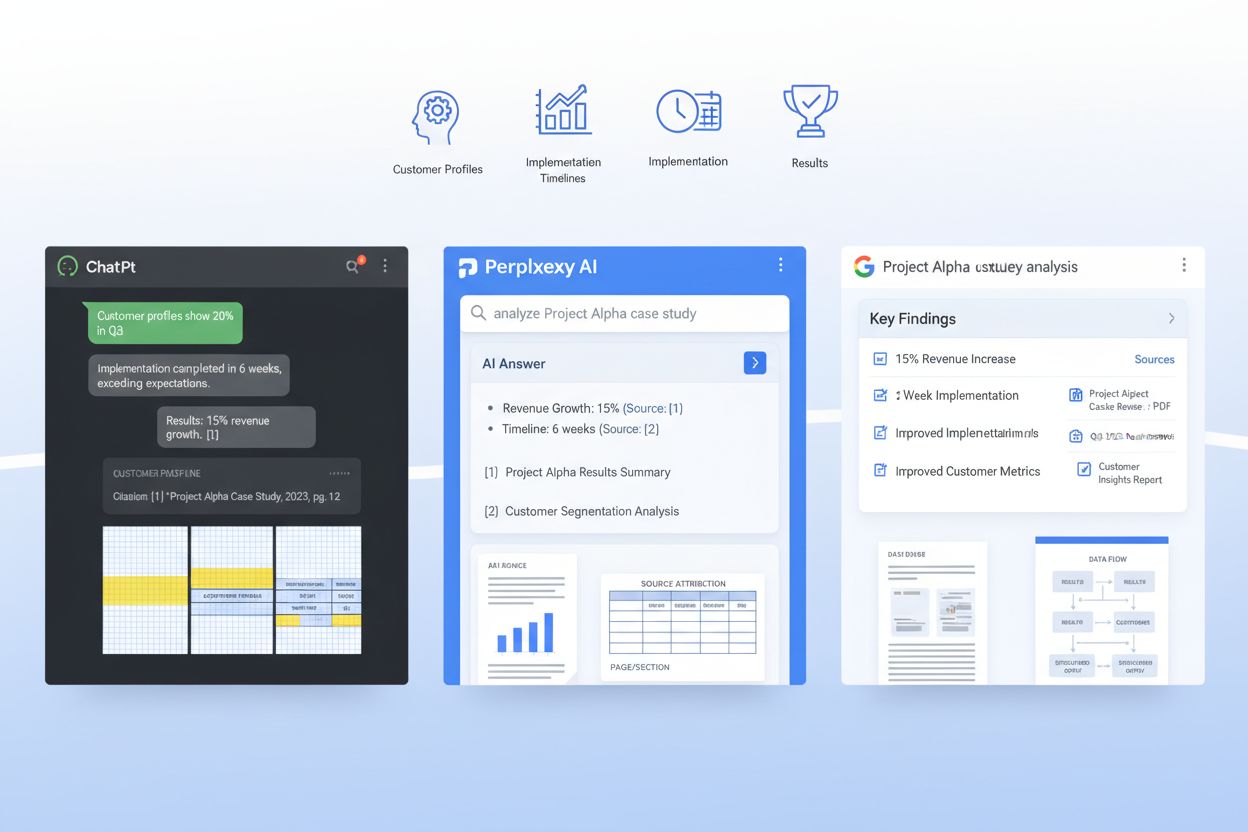
RAG systémy nespracúvajú celú prípadovú štúdiu ako jeden celok – rozdeľujú ju na sémantické bloky, ktoré sa zmestia do kontextového okna LLM, a štruktúra dokumentu priamo ovplyvňuje, či sú tieto bloky použiteľné alebo roztrieštené. Efektívna segmentácia znamená organizovať prípadovku tak, aby prirodzené sémantické hranice zodpovedali spôsobu, akým RAG systémy delia obsah. Vyžaduje to zámerné dávkovanie odsekov: každý by mal obsahovať jednu myšlienku či údaj, typicky 100–150 slov, aby pri extrakcii blok obsahoval úplné, zmysluplné informácie a nie len vytrhnuté vety. Oddelenie jednotlivých častí je kľúčové – používajte jasné sekčné predely medzi problémom, opisom riešenia a výsledkami, aby LLM mohlo extrahovať napríklad „sekciu výsledkov“ ako ucelenú jednotku bez miešania s implementačnými detailmi. Navyše záleží na efektívnosti tokenov: používaním tabuliek pre metriky namiesto textu znížite počet tokenov potrebných na prezentáciu rovnakých informácií, čo umožní LLM zahrnúť do odpovede viac z vašej prípadovej štúdie bez prekročenia limitov. Cieľom je, aby bola vaša prípadovka „RAG-friendly“, teda každý blok, ktorý AI systém extrahuje, bol samostatne hodnotný a správne zasadený do kontextu.
Publikovanie prípadových štúdií pre AI systémy si vyžaduje vyvážiť špecifickosť, ktorá im dáva dôveryhodnosť, a povinnosť zachovať dôvernosť zákazníkov. Mnohé firmy váhajú publikovať detailné prípadové štúdie zo strachu pred zverejnením citlivých informácií, no strategické začiernenie a anonymizácia vám umožnia zachovať transparentnosť aj dôveru. Najefektívnejší prístup znamená vytvoriť viacero verzií každej prípadovej štúdie: plne detailnú internú verziu s menami, presnými metrikami a proprietárnymi detailmi implementácie a verejnú AI-optimalizovanú verziu, ktorá anonymizuje zákazníka, ale zachováva kvantifikované dopady a strategické poznatky. Napríklad namiesto „TechCorp Industries ušetrila 2,3 mil. USD ročne“ môžete publikovať „stredne veľká finančná spoločnosť znížila prevádzkové náklady o 34 %“ – metrika je stále dostatočne konkrétna pre LLM, no identita zákazníka je chránená. Riadenie verzií a sledovanie súladu je nevyhnutné: uchovávajte záznamy o tom, čo a prečo bolo začiernené, aby bola vaša knižnica prípadových štúdií auditovateľná. Tento prístup k správe dát posilňuje vašu AI citáciovú stratégiu, pretože vám umožní publikovať viac prípadových štúdií častejšie bez právnych prekážok, čím dávate LLM viac dôkazných bodov na objavenie a citovanie.
Pred publikovaním prípadovej štúdie overte, či naozaj dosahuje požadované výsledky pri spracovaní LLM a RAG systémami – nespoliehajte sa na to, že dobré formátovanie automaticky znamená dobrý AI výkon. Testovanie vašich prípadových štúdií na reálnych AI systémoch odhalí, či vaša štruktúra, metadáta a obsah skutočne umožňujú presnú citáciu a vyhľadávanie. Tu je päť základných testovacích prístupov:
Kontrola relevantnosti: Zadajte svoju prípadovku do ChatGPT, Perplexity či Claude s otázkami z vašej kategórie. Vyhľadá a cituje AI vašu prípadovku pri odpovedi na relevantné otázky?
Presnosť sumarizácie: Požiadajte LLM o zhrnutie prípadovej štúdie a overte, či zhrnutie obsahuje kľúčové metriky, kontext zákazníka a obchodný dopad bez skreslenia či halucinácií.
Extrakcia metrík: Testujte, či AI systém dokáže presne vyťažiť konkrétne čísla z vašej prípadovky (napr. „Aké bolo zlepšenie time-to-value?“). Tabuľky by mali dosiahnuť viac ako 96 % presnosť; text testujte zvlášť.
Vernosť atribúcie: Overte, že keď LLM cituje vašu prípadovku, správne priraďuje informácie vašej firme a zákazníkovi, nie konkurencii alebo všeobecnému zdroju.
Otázky na hranici prípadu: Skúšajte aj netradičné či okrajové otázky, aby ste sa uistili, že vaša prípadovka nebude aplikovaná na prípady, ktoré v skutočnosti nerieši.
Tieto testy realizujte štvrťročne, ako sa mení správanie LLM, a výsledky využite na vylepšenie formátu a štruktúry.
Meranie dopadu AI-optimalizovaných prípadových štúdií si vyžaduje sledovať AI-metriky (ako často vaše prípady cituje LLM) aj ľudské metriky (ako tieto citácie ovplyvňujú reálne obchody). Na AI strane použite AmICited.com na monitorovanie frekvencie citácií v ChatGPT, Perplexity a Google AI Overviews – sledujte, ako často sa vaša firma objavuje v AI odpovediach na relevantné otázky a či sa počet citácií zvyšuje po publikovaní nových AI-pripravených prípadových štúdií. Zmerajte si aktuálnu mieru citácií a nastavte si cieľ zvýšiť ich o 40–60 % do šiestich mesiacov od nasadenia AI-ready formátu. Na ľudskej strane sledujte, ako sa zvýšenie AI citácií premieta do ďalších metrík: koľko obchodov spomenie „našli sme vás cez AI vyhľadávanie“ alebo „AI odporučilo vašu prípadovku“, sledujte zlepšenie win-rate v obchodoch, kde vašu prípadovku citoval AI systém (cieľ: 28–40 % zlepšenie oproti 21 % základni), a merajte skrátenie sales cyklu tam, kde zákazníci objavili vašu prípadovku cez AI. Sledujte aj SEO metriky – AI-optimalizované prípadové štúdie so správnym schéma označením často lepšie rankujú aj v tradičnom vyhľadávaní. Rovnako dôležitá je kvalitatívna spätná väzba od obchodníkov: pýtajte sa ich, či prichádzajú zákazníci s hlbšími znalosťami produktu a či AI citácie prípadoviek skracujú čas na zvládnutie námietok. Najvyšším KPI je tržba: sledujte prírastkové ARR pripísané obchodom ovplyvneným AI-citovanými prípadovkami a získate jasné ROI pre ďalšie investície do tohto formátu.
Optimalizácia prípadových štúdií na AI citácie prinesie ROI len vtedy, ak sa proces stane operatívne opakovateľným, nie jednorazovým projektom. Začnite tým, že si AI-ready šablónu prípadovej štúdie zakotvíte ako štandard, ktorý marketingový a obchodný tím použije pri každom novom úspešnom príbehu – zabezpečíte tým konzistentnosť naprieč knižnicou a znížite čas potrebný na publikovanie nových prípadoviek. Implementujte šablónu do CMS alebo content management systému, aby publikovanie novej prípadovej štúdie automaticky generovalo JSON schému, metadátové hlavičky a formátovacie prvky bez manuálnej práce. Zaraďte tvorbu prípadových štúdií do štvrťročného alebo mesačného cyklu, nie do ročnej agendy, pretože LLM častejšie objavujú a citujú firmy s hlbšou a aktuálnejšou knižnicou prípadoviek. Prípadové štúdie by mali byť jadrom vašej širšej revenue enablement stratégie: napájať sales materiály, produktový marketing, dopytové kampane aj playbooky customer success. Nakoniec nastavte nepretržitý cyklus zlepšovania – sledujte, ktoré prípady generujú najviac AI citácií, ktoré metriky najviac rezonujú s LLM, a ktoré segmenty zákazníkov sa citujú najčastejšie – a tieto poznatky využite pri tvorbe ďalšej generácie prípadových štúdií. Víťazi AI éry nepíšu len lepšie prípadové štúdie; pristupujú k nim ako k strategickým aktívam na tvorbu tržieb, ktoré si vyžadujú neustálu optimalizáciu, meranie a zdokonaľovanie.
Začnite extrakciou textu z vašich PDF súborov a mapujte existujúci obsah na štandardnú schému s poľami, ako sú profil zákazníka, výzva, riešenie a výsledky. Potom vytvorte ľahkú HTML alebo CMS verziu každého príbehu s jasnými nadpismi a metadátami, pričom pôvodné PDF ponechajte ako stiahnuteľný súbor namiesto primárneho zdroja pre AI vyhľadávanie.
Za rozprávanie príbehu zvyčajne zodpovedá marketing alebo produktový marketing, ale predaj, solutions engineering a customer success by mali poskytnúť surové dáta, detaily implementácie a validáciu. Právny, privacy a RevOps tím pomáhajú zabezpečiť správu, správne začiernenie a súlad s existujúcimi systémami, ako sú CRM a platformy na podporu predaja.
Ideálnou voľbou na ukladanie schém a metadát je headless CMS alebo platforma so štruktúrovaným obsahom, zatiaľ čo CRM alebo nástroj na podporu predaja vie zobrazovať správne príbehy v pracovnom postupe. Pre AI vyhľadávanie zvyčajne spárujete vektorovú databázu s LLM orchestračnou vrstvou, ako je LangChain alebo LlamaIndex.
Prepisujte video referencie a webináre, pričom prepisy označte rovnakými poľami a sekciami ako písomné prípadové štúdie, aby ich AI vedela citovať. Pri grafoch a diagramoch pridajte krátky alt-text alebo popis, ktorý vystihuje kľúčový poznatok, aby vyhľadávacie modely mohli vizuálne podklady prepojiť s konkrétnymi otázkami.
Zachovajte svoju hlavnú schému a ID globálne konzistentné, potom vytvorte preložené varianty, ktoré lokalizujú jazyk, menu a regulačný kontext, pričom zachovávajú kanonické metriky. Lokálne verzie ukladajte ako samostatné, ale prepojené objekty, aby AI systémy mohli uprednostniť odpovede v jazyku používateľa bez fragmentácie dátového modelu.
Zrevidujte vysoko vplyvné prípadové štúdie aspoň raz ročne, alebo skôr, ak dôjde k zásadným produktovým zmenám, novým metrikám alebo posunom v zákazníckom kontexte. Používajte jednoduchý workflow verzovania s dátumami poslednej kontroly a stavovými príznakmi, aby AI systémy aj ľudia vedeli, ktoré príbehy sú najaktuálnejšie.
Integrujte vyhľadávanie prípadových štúdií priamo do nástrojov, ktoré obchodníci už používajú, a vytvorte konkrétne playbooky ukazujúce, ako zadať asistentovi správnu požiadavku na relevantné dôkazy. Podporujte prijatie zdieľaním úspešných príbehov, kde personalizované, AI-vybrané prípadové štúdie pomohli uzavrieť obchody rýchlejšie alebo osloviť nových rozhodovateľov.
Tradičné prípadové štúdie sú písané pre ľudí s dôrazom na príbeh a vizuálny dizajn. AI-optimalizované prípadové štúdie tento príbeh zachovávajú, ale pridávajú štruktúrované metadáta, konzistentné formátovanie, JSON schémy a sémantickú jasnosť, vďaka ktorej môžu LLM extrahovať, rozumieť a citovať konkrétne informácie s viac ako 96% presnosťou.
Sledujte, ako AI systémy citujú vašu značku v ChatGPT, Perplexity a Google AI Overviews. Získajte prehľad o svojej AI viditeľnosti a optimalizujte svoju obsahovú stratégiu.
Zistite, ako sa prípadové štúdie umiestňujú vo vyhľadávačoch s AI ako ChatGPT, Perplexity a Google AI Overviews. Objavte, prečo systémy AI citujú prípadové štúd...
Diskusia komunity o tom, ako si prípadové štúdie vedú vo výsledkoch AI vyhľadávania. Skutočné skúsenosti marketérov, ktorí sledujú citácie prípadových štúdií v ...
Zistite, ako Smart Rent získal o 345 % viac leadov pomocou AI citácií. Skutočná prípadová štúdia ukazujúca stratégiu generovania B2B leadov, výsledky a implemen...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.