
Referenčná karta AI crawlerov: Všetky boty na prvý pohľad
Kompletný referenčný sprievodca AI crawlermi a botmi. Identifikujte GPTBot, ClaudeBot, Google-Extended a viac ako 20 ďalších AI crawlerov s user agentmi, rýchlo...
12 min čítania

Naučte sa, ako blokovať alebo povoliť AI crawlery ako GPTBot a ClaudeBot pomocou robots.txt, serverového blokovania a pokročilých ochranných metód. Kompletný technický sprievodca s príkladmi.
Digitálne prostredie sa zásadne zmenilo od tradičnej optimalizácie pre vyhľadávače k správe úplne novej kategórie automatizovaných návštevníkov: AI crawlerov. Na rozdiel od bežných vyhľadávacích botov, ktoré privádzajú návštevnosť späť na váš web prostredníctvom výsledkov vyhľadávania, AI tréningové crawlery spotrebúvajú váš obsah na budovanie veľkých jazykových modelov bez toho, aby vám nutne poslali spätnú návštevnosť. Tento rozdiel má zásadné dôsledky pre vydavateľov, tvorcov obsahu a firmy, ktoré sú závislé na webovej návštevnosti ako zdroji príjmu. Ide o veľa—kontrola toho, ktoré AI systémy majú prístup k vášmu obsahu, priamo ovplyvňuje vašu konkurenčnú výhodu, ochranu dát a výsledky hospodárenia.
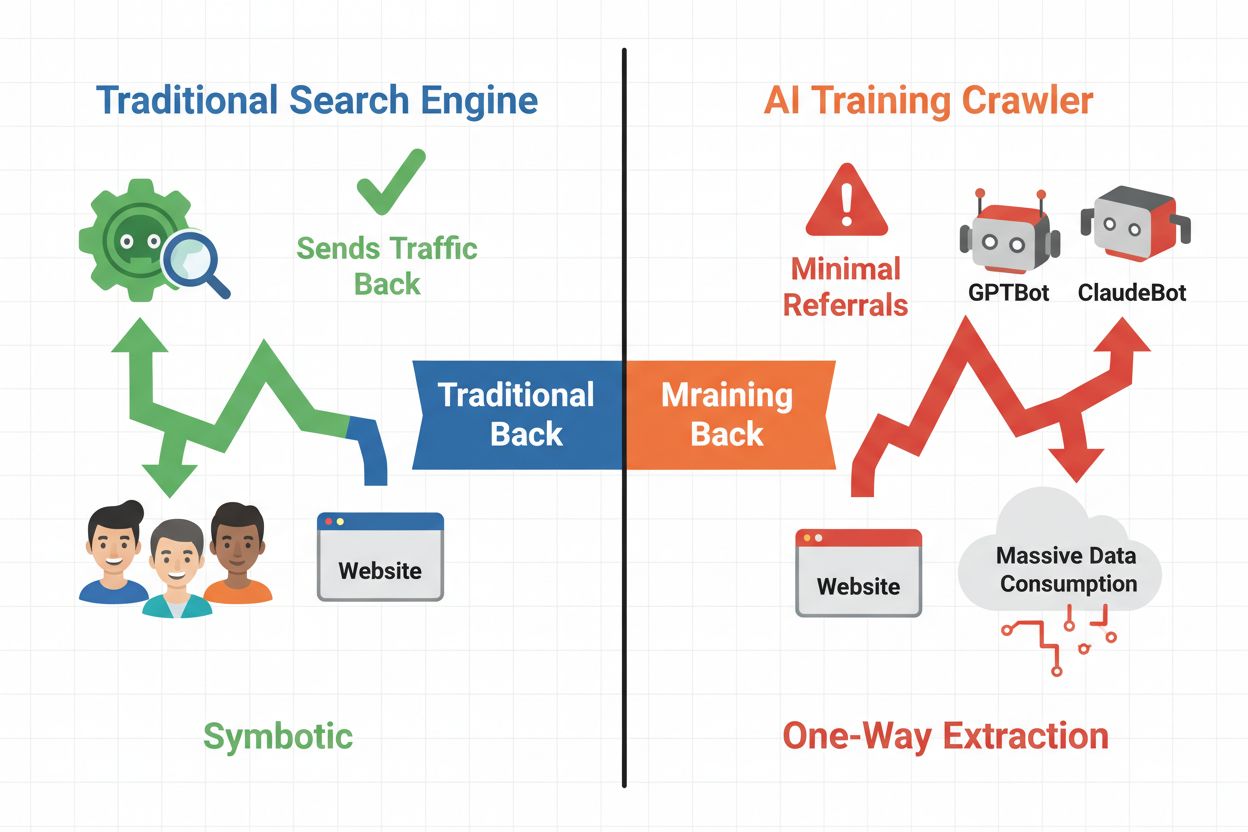
AI crawlery spadajú do troch odlišných kategórií, pričom každá má iný účel a dopad na návštevnosť. Tréningové crawlery používajú AI spoločnosti na budovanie a zlepšovanie svojich jazykových modelov, typicky v obrovskom rozsahu s minimálnou návratnosťou návštevnosti. Vyhľadávacie a citačné crawlery indexujú obsah pre AI vyhľadávače a citačné systémy, často privádzajú aspoň nejakú návštevnosť späť k vydavateľom. Crawlery spustené používateľom získavajú obsah na požiadanie, keď používatelia interagujú s AI aplikáciami – ide o menší, ale rastúci segment. Poznanie týchto kategórií vám pomôže informovane rozhodnúť, ktorým crawlerom povolíte alebo zablokujete prístup podľa vášho obchodného modelu.
| Typ crawlera | Účel | Dopad na návštevnosť | Príklady |
|---|---|---|---|
| Tréningový | Budovanie/zlepšovanie LLM | Minimálny až žiadny | GPTBot, ClaudeBot, Bytespider |
| Vyhľadávací/Citačný | Indexácia pre AI vyhľadávanie & citácie | Stredná návratnosť návštevnosti | Googlebot-Extended, Perplexity |
| Spustený používateľom | Na požiadanie pre používateľov | Nízky, ale stabilný | ChatGPT pluginy, Claude prehliadanie |
Ekosystém AI crawlerov zahŕňa crawlery najväčších technologických firiem sveta, pričom každý má špecifický user agent a účel. OpenAI GPTBot (user agent: GPTBot/1.0) crawlery trénuje ChatGPT a ďalšie modely, zatiaľ čo ClaudeBot od Anthropic (user agent: Claude-Web/1.0) slúži podobnému účelu pre Claude. Googlebot-Extended od Google (user agent: Mozilla/5.0 ... Googlebot-Extended) indexuje obsah pre AI Overviews a Bard, zatiaľ čo Meta-ExternalFetcher crawlery pre AI iniciatívy od Meta. Medzi ďalších veľkých hráčov patria:
Každý crawler funguje v inom rozsahu a rešpektuje blokovacie pravidlá s rôznou mierou dôslednosti.
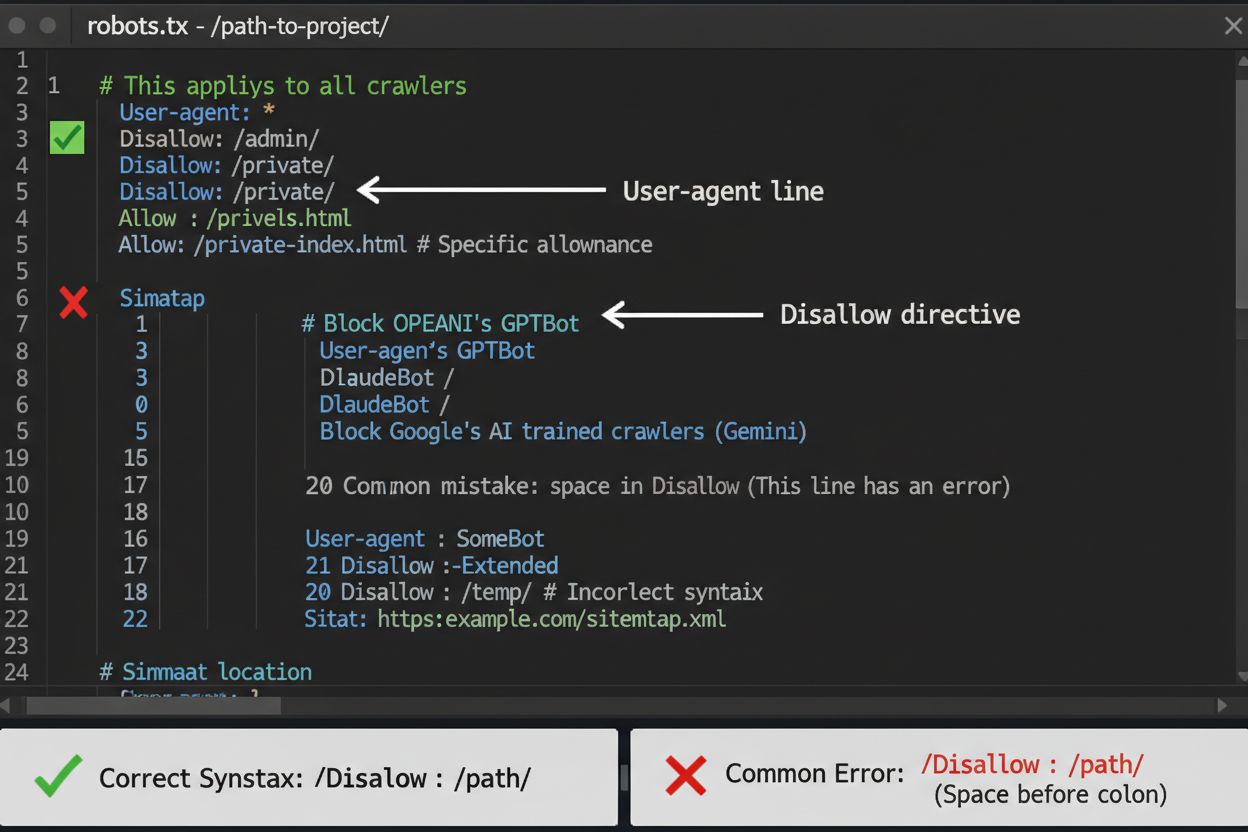
Súbor robots.txt je vašou prvou líniou obrany pri kontrole prístupu AI crawlerov, treba si však uvedomiť, že ide skôr o odporúčanie než právne záväzný nástroj. Nachádza sa v koreňovom adresári vašej domény (napr. vasweb.sk/robots.txt) a využíva jednoduchú syntax na usmernenie crawlerov, ktorým oblastiam sa majú vyhnúť. Ak chcete komplexne zablokovať všetky AI crawlery, pridajte tieto pravidlá:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Ak preferujete selektívne blokovanie – povoliť vyhľadávacie crawlery, ale blokovať tréningové – použite tento prístup:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
Častou chybou je použitie príliš širokých pravidiel ako Disallow: *, ktoré môžu zmiasť parsre, alebo zabudnutie špecifikovať jednotlivých crawlerov, keď chcete blokovať iba niektoré. Veľké firmy ako OpenAI, Anthropic a Google vo všeobecnosti rešpektujú pravidlá robots.txt, no niektoré crawlery, ako Perplexity, sú známe tým, že ich úplne ignorujú.
Ak samotný robots.txt nestačí, existuje viacero silnejších ochranných metód na zvýšenie kontroly nad prístupom AI crawlerov. Blokovanie na základe IP zahŕňa identifikáciu IP rozsahov AI crawlerov a ich blokovanie na úrovni firewallu alebo servera – je to veľmi účinné, ale vyžaduje priebežnú údržbu, keďže IP sa menia. Blokovanie na úrovni servera cez .htaccess (Apache) alebo konfiguračné súbory Nginx poskytuje detailnejšiu kontrolu a je ťažšie ho obísť ako robots.txt. Pre Apache servery použite toto blokovacie pravidlo:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
Blokovanie meta tagom cez <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> zabraňuje indexácii, no nezastaví tréningové crawlery. Overovanie hlavičiek požiadaviek kontroluje, či crawlery skutočne pochádzajú z deklarovaných zdrojov (overenie reverse DNS a SSL certifikátov). Ak potrebujete absolútnu istotu, že crawlery sa k vášmu obsahu nedostanú, použite blokovanie na úrovni servera a kombinujte viacero metód pre maximálnu ochranu.
Rozhodnutie, či blokovať AI crawlery, si vyžaduje zváženie niekoľkých protichodných záujmov. Blokovaním tréningových crawlerov (GPTBot, ClaudeBot, Bytespider) zabránite použitiu vášho obsahu na tréning AI modelov a ochránite svoje duševné vlastníctvo a konkurenčnú výhodu. Povolením vyhľadávacích crawlerov (Googlebot-Extended, Perplexity) môžete získať referral návštevnosť a zvýšiť viditeľnosť vo výsledkoch AI vyhľadávania – čo je rastúci kanál objavovania obsahu. Komplexnejšie je to v prípade, že niektoré AI firmy majú veľmi zlý pomer crawl/referral: crawlery od Anthropic vygenerujú približne 38 000 požiadaviek na každú jednu návštevu, OpenAI má pomer asi 400:1. Zaťaženie servera a šírka pásma sú ďalším faktorom – AI crawlery spotrebúvajú veľa zdrojov a ich blokovaním môžete znížiť náklady na infraštruktúru. Rozhodnutie by malo zodpovedať vášmu obchodnému modelu: spravodajské weby a vydavatelia môžu ťažiť z referral návštevnosti, zatiaľ čo SaaS firmy a tvorcovia vlastného obsahu zvyčajne preferujú blokovanie.
Zavedením blokovania crawlerov práca nekončí – musíte overiť, či crawlery naozaj rešpektujú vaše pravidlá. Analýza serverových logov je vaším hlavným nástrojom na overenie; prehliadajte svoje prístupové logy a hľadajte user agent reťazce a IP adresy crawlerov, ktoré sa pokúšajú o prístup po zablokovaní. Použite grep na prehľadanie logov:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
Tento príkaz spočíta, koľkokrát tieto crawlery pristúpili na váš web. Testovacie nástroje ako curl dokážu simulovať požiadavky crawlera a overiť, či vaše blokovacie pravidlá fungujú správne:
curl -A "GPTBot/1.0" https://vasweb.sk/robots.txt
Prvé štyri týždne po implementácii blokovania kontrolujte logy každý týždeň, potom aspoň raz za štvrťrok. Ak zistíte, že crawlery ignorujú váš robots.txt, prejdite na blokovanie na úrovni servera alebo kontaktujte abuse tím prevádzkovateľa crawlera.
Ekosystém AI crawlerov sa rýchlo vyvíja, keďže nové firmy spúšťajú AI produkty a existujúce crawlery menia svoje user agent reťazce a IP rozsahy. Štvrťročné kontroly zoznamu blokovaných crawlerov vám pomôžu nezabudnúť na nové crawlery alebo náhodne neblokovať legitímnu návštevnosť. Prostredie crawlerov je roztrieštené a decentralizované, preto nie je možné vytvoriť trvalo platný zoznam. Sledujte tieto zdroje pre novinky:
Nastavte si pripomienky na kontrolu robots.txt a serverových pravidiel každých 90 dní a prihláste sa na odber bezpečnostných mailinglistov, ktoré sledujú nové crawler nasadenia.
Zatiaľ čo blokovanie AI crawlerov im zabraňuje v prístupe k vášmu obsahu, AmICited rieši doplnkovú výzvu: monitoruje, či AI systémy citujú a odkazujú na vašu značku alebo obsah vo svojich odpovediach. AmICited sleduje zmienky vašej organizácie v AI generovaných výstupoch, čím vám poskytuje prehľad o tom, ako váš obsah ovplyvňuje výstupy AI modelov a kde sa vaša značka objavuje vo výsledkoch AI vyhľadávania. Tak vzniká komplexná AI stratégia: prístup crawlerov riadite cez robots.txt a serverové blokovania, zatiaľ čo AmICited vám dáva prehľad o skutočnom dosahu vášho obsahu v AI systémoch. Spolu tieto nástroje poskytujú úplnú kontrolu a prehľad o vašej prítomnosti v AI ekosystéme – od prevencie nechceného použitia obsahu na tréning až po meranie reálnych citácií a odkazov, ktoré váš obsah generuje naprieč AI platformami.
Nie. Blokovanie tréningových AI crawlerov ako GPTBot, ClaudeBot a Bytespider neovplyvňuje vaše pozície vo vyhľadávačoch Google alebo Bing. Tradičné vyhľadávače používajú iné crawlery (Googlebot, Bingbot), ktoré fungujú nezávisle. Tie blokujte len v prípade, ak chcete úplne zmiznúť z výsledkov vyhľadávania.
Hlavné crawlery od OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) a Perplexity (PerplexityBot) oficiálne uvádzajú, že rešpektujú pokyny v robots.txt. Menšie alebo menej transparentné boty však môžu vaše nastavenia ignorovať, preto existujú vrstvené ochranné stratégie.
Závisí to od vašej stratégie. Blokovaním iba tréningových crawlerov (GPTBot, ClaudeBot, Bytespider) ochránite svoj obsah pred použitím na tréning modelov, pričom vyhľadávacie crawlery vám môžu pomôcť objaviť sa vo výsledkoch AI vyhľadávania. Úplné blokovanie vás z AI ekosystémov úplne odstráni.
Minimálne štvrťročne skontrolujte svoje nastavenia. AI spoločnosti pravidelne zavádzajú nové crawlery. Anthropic zlúčil svoje boty 'anthropic-ai' a 'Claude-Web' do 'ClaudeBot', čím nový bot dočasne získal neobmedzený prístup na stránky, ktoré nemali aktualizované pravidlá.
Blokovanie úplne zabraňuje prístupu crawlerov k vášmu obsahu a chráni ho pred zberom tréningových dát alebo indexáciou. Povoľovanie crawlerov im umožňuje prístup, ale váš obsah môže byť použitý na tréning modelov alebo sa objaviť vo výsledkoch AI vyhľadávania, často s minimálnou návštevnosťou späť na váš web.
Áno, robots.txt je odporúčanie, právne nevynútiteľné. Dobre sa správajúce crawlery od veľkých firiem zvyčajne robots.txt rešpektujú, ale niektoré crawlery ho ignorujú. Pre silnejšiu ochranu použite blokovanie na úrovni servera cez .htaccess alebo firewall pravidlá.
Skontrolujte serverové logy pre user agent reťazce zablokovaných crawlerov. Ak vidíte požiadavky od crawlerov, ktoré ste zablokovali, pravdepodobne robots.txt nerešpektujú. Na overenie konfigurácie použite nástroje ako Google Search Console robots.txt tester alebo príkazy curl.
Blokovanie tréningových crawlerov má zvyčajne minimálny priamy dopad na návštevnosť, pretože neposielajú takmer žiadnu návštevnosť. Blokovanie vyhľadávacích crawlerov však môže znížiť vašu viditeľnosť v AI poháňaných platformách. Sledujte analytiku 30 dní po zavedení blokovania, aby ste zmerali skutočný dopad.
Aj keď kontrolujete prístup crawlerov cez robots.txt, AmICited vám pomáha sledovať, ako AI systémy citujú a odkazujú na váš obsah vo svojich výstupoch. Získajte úplný prehľad o vašej AI prítomnosti.
Kompletný referenčný sprievodca AI crawlermi a botmi. Identifikujte GPTBot, ClaudeBot, Google-Extended a viac ako 20 ďalších AI crawlerov s user agentmi, rýchlo...

Zistite, ktorým AI crawlerom povoliť alebo zablokovať prístup vo vašom robots.txt. Komplexný sprievodca pokrývajúci GPTBot, ClaudeBot, PerplexityBot a ďalších 2...

Zistite, ako vykonať audit prístupu AI crawlerov na vašej webstránke. Objavte, ktoré roboty vidia váš obsah a opravte prekážky, ktoré bránia AI vo viditeľnosti ...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.