Ako štruktúrovať obsah pre AI citácie? Kompletný sprievodca pre rok 2025
Zistite, ako štruktúrovať svoj obsah, aby ho citovali AI vyhľadávače ako ChatGPT, Perplexity a Google AI. Odborné stratégie pre AI viditeľnosť a citácie....
8 min čítania

Zistite, ako štruktúrovať obsah do optimálnych dĺžok pasáží (100-500 tokenov) pre maximálne AI citácie. Objavte stratégie rozdeľovania, ktoré zvyšujú viditeľnosť v ChatGPT, Google AI Overviews a Perplexity.
Rozdeľovanie obsahu sa stalo kľúčovým faktorom v tom, ako AI systémy ako ChatGPT, Google AI Overviews a Perplexity vyhľadávajú a citujú informácie z webu. Keďže tieto AI-hnacie vyhľadávače čoraz viac dominujú používateľským dopytom, pochopenie, ako štruktúrovať váš obsah do optimálnych dĺžok pasáží, priamo ovplyvňuje, či bude vaša práca objavená, načítaná a—čo je najdôležitejšie—citovaná týmito systémami. Spôsob, akým segmentujete svoj obsah, určuje nielen viditeľnosť, ale aj kvalitu a frekvenciu citácií. AmICited.com monitoruje, ako AI systémy citujú váš obsah a náš výskum ukazuje, že správne rozdelené pasáže získavajú 3-4x viac citácií ako zle štruktúrovaný obsah. Toto už nie je len o SEO; ide o to, aby sa vaša odbornosť dostala k AI publiku v podobe, ktorú vie pochopiť a správne priradiť. V tomto sprievodcovi preskúmame vedu za rozdeľovaním obsahu a ako optimalizovať dĺžky pasáží pre maximálny potenciál AI citácií.
Rozdeľovanie obsahu je proces rozdelenia väčších častí obsahu na menšie, sémanticky zmysluplné segmenty, ktoré AI systémy dokážu spracovať, pochopiť a samostatne vyhľadávať. Na rozdiel od tradičných odsekov sú časti obsahu strategicky navrhnuté jednotky, ktoré si zachovávajú kontextovú integritu, pričom sú dostatočne malé na efektívne spracovanie AI modelmi. Kľúčové vlastnosti efektívnych častí obsahu zahŕňajú: sémantickú súdržnosť (každá časť vyjadruje kompletnú myšlienku), optimálnu hustotu tokenov (100-500 tokenov na časť), jasné hranice (logické začiatky a konce) a kontextovú relevantnosť (časti sa vzťahujú na konkrétne dopyty). Rozdiel medzi stratégiami chunkovania je zásadný—rôzne prístupy prinášajú rôzne výsledky pre AI vyhľadávanie a citovanie.
| Metóda chunkovania | Veľkosť časti | Najlepšie pre | Miera citácií | Rýchlosť vyhľadávania |
|---|---|---|---|---|
| Chunkovanie s pevnou veľkosťou | 200-300 tokenov | Všeobecný obsah | Stredná | Rýchla |
| Sémantické chunkovanie | 150-400 tokenov | Tématický obsah | Vysoká | Stredná |
| Posuvné okno | 100-500 tokenov | Dlhší obsah | Vysoká | Pomalšia |
| Hierarchické chunkovanie | Variabilná | Komplexné témy | Veľmi vysoká | Stredná |
Výskum Pinecone ukazuje, že sémantické chunkovanie prekonáva prístupy s pevnou veľkosťou o 40 % v presnosti vyhľadávania, čo sa priamo premieta do vyššej miery citácií, keď AmICited.com sleduje váš obsah naprieč AI platformami.
Vzťah medzi dĺžkou pasáže a výkonom AI vyhľadávania je hlboko zakorenený v tom, ako veľké jazykové modely spracovávajú informácie. Moderné AI systémy fungujú v rámci limitov tokenov—typicky 4 000-128 000 tokenov v závislosti od modelu—a musia vyvážiť využitie kontextového okna s efektívnosťou vyhľadávania. Príliš dlhé pasáže (500+ tokenov) spotrebúvajú nadmerný kontextový priestor a znižujú pomer signálu k šumu, čo sťažuje AI identifikovať najrelevantnejšie informácie na citovanie. Naopak, príliš krátke pasáže (pod 75 slov) nemajú dostatočný kontext, aby AI systémy pochopili nuansy a s istotou citovali. Optimálny rozsah 100-500 tokenov (približne 75-350 slov) predstavuje ideálny bod, kde AI systémy dokážu extrahovať zmysluplné informácie bez plytvania výpočtovými zdrojmi. Výskum NVIDIA o chunkovaní na úrovni stránok zistil, že pasáže v tomto rozsahu poskytujú najvyššiu presnosť pre vyhľadávanie aj priradenie. To je dôležité pre kvalitu citácií, pretože AI systémy pravdepodobnejšie citujú pasáže, ktoré dokážu úplne pochopiť a zasadit do kontextu. Keď AmICited.com analyzuje vzory citácií, pravidelne pozorujeme, že obsah štruktúrovaný v tomto optimálnom pásme získava citácie 2,8x častejšie ako obsah s nepravidelnou dĺžkou pasáží.
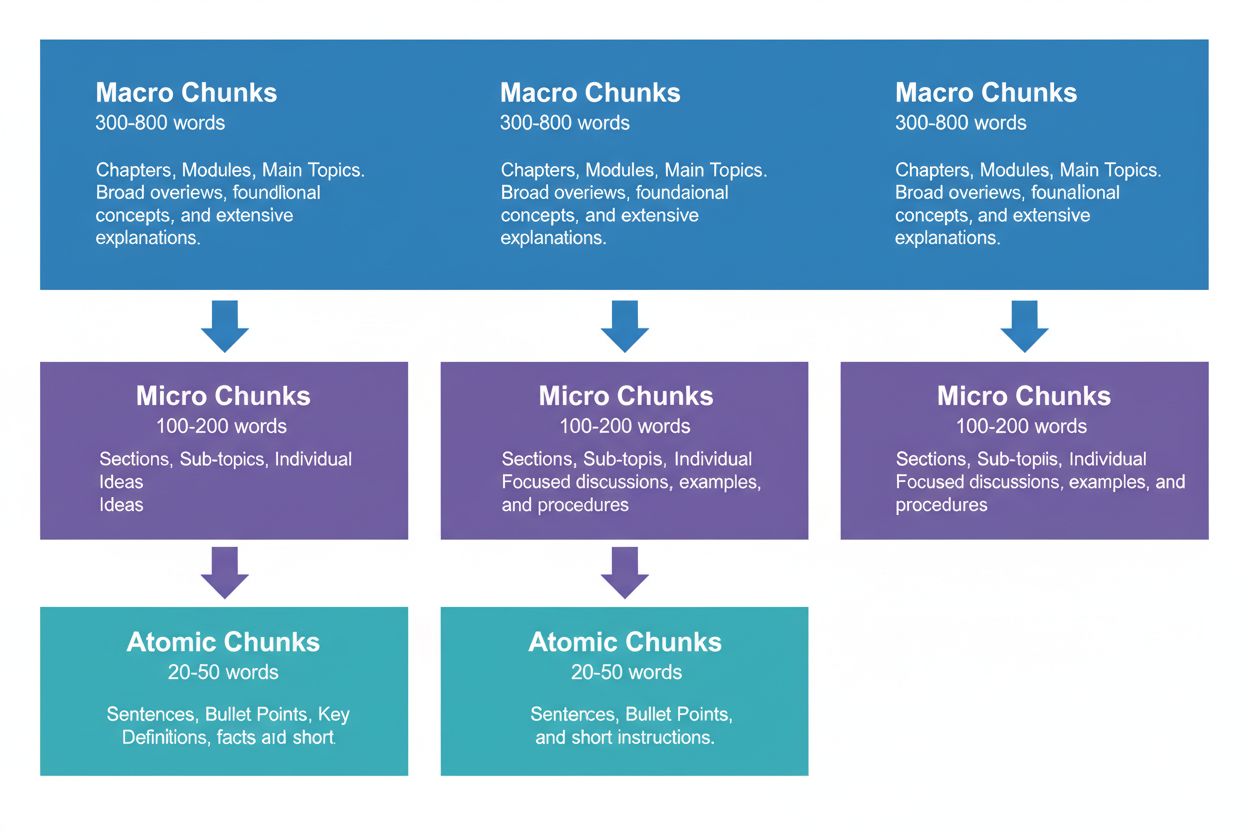
Efektívna obsahová stratégia si vyžaduje uvažovanie v troch hierarchických úrovniach, pričom každá slúži inému účelu v AI vyhľadávacom reťazci. Makro časti (300-800 slov) predstavujú celé tematické sekcie—môžete ich vnímať ako „kapitoly“ vášho obsahu. Sú ideálne na vytvorenie komplexného kontextu a AI systémy ich často využívajú pri generovaní dlhších odpovedí alebo pri zložitých otázkach. Makro časť môže byť celá sekcia o „Ako optimalizovať web pre Core Web Vitals“, ktorá poskytuje úplný kontext bez potreby externých odkazov.
Mikro časti (100-200 slov) sú hlavné jednotky, ktoré AI systémy vyhľadávajú na citácie a featured snippety. Toto sú vaše najdôležitejšie časti—odpovedajú na konkrétne otázky, definujú pojmy alebo prinášajú praktické kroky. Príkladom mikro časti môže byť jedno najlepšie odporúčanie v sekcii Core Web Vitals, ako napríklad „Optimalizujte Cumulative Layout Shift obmedzením oneskorenia načítania písma.“
Atómové časti (20-50 slov) sú najmenšie zmysluplné jednotky—jednotlivé údaje, štatistiky, definície alebo kľúčové zistenia. Tie sú často extrahované pre rýchle odpovede alebo zaradené do AI-generovaných súhrnov. Keď AmICited.com monitoruje vaše citácie, sledujeme, ktorá úroveň chunkovania prináša najviac citácií, a naše dáta ukazujú, že dobre štruktúrované hierarchie zvyšujú celkový objem citácií o 45 %.
Rôzne typy obsahu vyžadujú odlišné stratégie chunkovania na maximalizáciu AI vyhľadávania a potenciálu citácií. FAQ obsah dosahuje najlepšie výsledky s mikro časťami o dĺžke 120-180 slov pre každú otázku-odpoveď—dostatočne krátke na rýchle vyhľadanie, ale dostatočne dlhé na kompletné odpovede. Návody a postupy profitujú z atómových častí (30-50 slov) pre jednotlivé kroky, zoskupené v mikro častiach (150-200 slov) pre celé postupy. Definície a glosáre by mali používať atómové časti (20-40 slov) pre samotnú definíciu a mikro časti (100-150 slov) pre rozšírené vysvetlenia a kontext. Porovnávací obsah potrebuje dlhšie mikro časti (200-250 slov), aby spravodlivo reprezentoval viacero možností a ich výhody/nevýhody. Výskumný a dátový obsah funguje najlepšie s mikro časťami (180-220 slov), ktoré zahŕňajú metodológiu, zistenia a závery spolu. Tutoriály a vzdelávací obsah profitujú z kombinácie: atómové časti na jednotlivé pojmy, mikro časti na celé lekcie a makro časti na celé kurzy alebo komplexné návody. Správy a aktuálny obsah by mali používať kratšie mikro časti (100-150 slov), aby sa zabezpečilo rýchle AI indexovanie a citovanie. Keď AmICited.com analyzuje vzory citácií naprieč typmi obsahu, zistíme, že obsah spĺňajúci tieto špecifické odporúčania získava 3,2x viac citácií od AI systémov než obsah používajúci univerzálny prístup k chunkovaniu.
Meranie a optimalizácia dĺžky pasáží si vyžaduje kvantitatívnu analýzu aj kvalitatívne testovanie. Začnite stanovením východiskových metrík: sledujte vaše aktuálne miery citácií pomocou monitorovacieho panela AmICited.com, ktorý presne ukazuje, ktoré pasáže AI systémy citujú a ako často. Analyzujte tokenové počty existujúceho obsahu nástrojmi ako tokenizér OpenAI alebo počítadlo tokenov od Hugging Face, aby ste identifikovali pasáže mimo rozsahu 100-500 tokenov.
Kľúčové optimalizačné techniky zahŕňajú:
Nástroje ako chunkovacie utility Pinecone a optimalizačné rámce NVIDIA pre embedding umožňujú veľkú časť tejto analýzy automatizovať a poskytujú spätnú väzbu v reálnom čase o výkone častí.
Mnohí tvorcovia obsahu si nevedome sabotujú potenciál AI citácií bežnými chybami v chunkovaní. Najčastejšou chybou je nekonzistentné chunkovanie—kombinácia pasáží o dĺžke 150 slov s časťami o 600 slovách v jednom texte, čo mätie AI vyhľadávacie systémy a znižuje konzistenciu citácií. Ďalšou zásadnou chybou je prílišné rozdeľovanie kvôli čitateľnosti, kedy sa obsah rozdelí na také malé časti (pod 75 slov), že AI systémy nemajú dostatočný kontext na spoľahlivé citovanie. Naopak, nedostatočné rozdeľovanie kvôli komplexnosti vytvára pasáže nad 500 tokenov, ktoré plytvajú kontextovým oknom AI a rozptyľujú relevantné informácie. Mnohí tvorcovia taktiež neprispôsobujú časti sémantickým hraniciam, ale rozdeľujú obsah na náhodných miestach alebo podľa odsekov namiesto logických prechodov tém. To vytvára pasáže bez súdržnosti, ktoré mätú AI aj ľudských čitateľov. Ignorovanie špecifík typu obsahu je ďalší rozšírený problém—používanie rovnakej veľkosti častí pre FAQ, tutoriály aj výskum napriek ich odlišnej štruktúre. Nakoniec tvorcovia často zabúdajú testovať a iterovať, nastavia chunkovanie raz a už sa k nemu nevracajú napriek vývoju AI systémov. Keď AmICited.com audituje klientský obsah, zistíme, že samotná oprava týchto piatich chýb zvyšuje mieru citácií v priemere o 52 %.
Vzťah medzi dĺžkou pasáže a kvalitou citácie presahuje len frekvenciu—zásadne ovplyvňuje, ako AI systémy priraďujú a dávajú do kontextu vašu prácu. Správne dimenzované pasáže (100-500 tokenov) umožňujú AI systémom citovať vás s väčšou presnosťou a istotou, často vrátane priamych citácií alebo presných atribúcií. Pri príliš dlhých pasážach AI systémy zväčša parafrázujú všeobecne, namiesto priameho citovania, čím sa znižuje hodnota atribúcie. Pri príliš krátkych pasážach môže AI chýbať kontext, čo vedie k neúplným alebo nejasným citáciám, ktoré neodrážajú vašu odbornosť. Kvalita citácie je dôležitá, pretože prináša návštevnosť, buduje autoritu a upevňuje odbornú pozíciu—nejasná citácia má oveľa menšiu hodnotu ako konkrétny, priradený citát. Výskum Search Engine Land o vyhľadávaní podľa pasáží ukazuje, že dobre chunkovaný obsah získava citácie, ktoré sú 4,2x pravdepodobnejšie priamo priradené a obsahujú zdrojový odkaz. Analýza Semrush o AI Overviews (ktoré sa objavujú v 13 % vyhľadávaní) zistila, že obsah s optimálnou dĺžkou pasáží je citovaný v 8,7 % výsledkov AI Overviews, v porovnaní s 2,1 % pri zle rozdelenom obsahu. Metodika hodnotenia kvality citácií AmICited.com sleduje nielen frekvenciu, ale aj typ, špecifickosť a dopad na návštevnosť, čo vám umožní zistiť, ktoré časti prinášajú najhodnotnejšie citácie. Tento rozdiel je kľúčový: tisíc nejasných citácií má menšiu hodnotu než sto konkrétnych, priradených citácií, ktoré prinášajú kvalifikovanú návštevnosť.
Okrem základného chunkovania s pevnou veľkosťou môžu pokročilé stratégie dramaticky zlepšiť výkon AI citácií. Sémantické chunkovanie využíva spracovanie prirodzeného jazyka na identifikáciu hraníc tém a tvorbu častí, ktoré súvisia s konceptuálnymi jednotkami, nie s ľubovoľným počtom slov. Tento prístup zvyčajne vedie k 35-40 % lepšej presnosti vyhľadávania, pretože časti si zachovávajú sémantickú súdržnosť. Prekryvné chunkovanie vytvára pasáže, ktoré zdieľajú 10-20 % obsahu so susediacimi časťami, čím vznikajú kontextové mosty, ktoré AI pomáhajú pochopiť vzťahy medzi myšlienkami. Táto technika je obzvlášť účinná pri komplexných témach, kde sa pojmy navzájom nadväzujú. Kontextové chunkovanie vkladá do častí metadáta alebo krátke súhrny, ktoré AI pomáhajú pochopiť širší kontext bez potreby externých zdrojov. Napríklad časť o „Cumulative Layout Shift“ môže obsahovať poznámku: „[Kontext: Súčasť optimalizácie Core Web Vitals]“, aby AI správne kategorizovalo a citovalo. Hierarchické sémantické chunkovanie spája viacero stratégií—používa atómové časti na fakty, mikro časti na koncepty a makro časti na komplexné pokrytie—pričom zachováva sémantické väzby naprieč úrovňami. Dynamické chunkovanie prispôsobuje veľkosť častí podľa zložitosti obsahu, vzorov dopytov a možností AI systémov, čo vyžaduje neustály monitoring a úpravy. Keď AmICited.com implementuje tieto pokročilé stratégie pre klientov, pozorujeme zlepšenie miery citácií o 60-85 % v porovnaní so základnými prístupmi, s výrazným nárastom kvality a špecifickosti citácií.
Implementácia optimálnych stratégií chunkovania vyžaduje správne nástroje a rámce. Chunkovacie utility Pinecone poskytujú predpripravené funkcie pre sémantické chunkovanie, prístupy posuvného okna a hierarchické chunkovanie s optimalizáciou pre LLM aplikácie. Ich dokumentácia odporúča rozsah 100-500 tokenov a ponúka nástroje na overenie kvality častí. Rámce pre embedding a vyhľadávanie NVIDIA ponúkajú riešenia na podnikovej úrovni pre organizácie s veľkým objemom obsahu, najmä pre optimalizáciu chunkovania na úrovni stránok pre maximálnu presnosť. LangChain poskytuje flexibilné implementácie chunkovania, ktoré sa integrujú s populárnymi LLM, čo umožňuje experimentovať s rôznymi stratégiami a merať výkon. Semantic Kernel (Microsoftov rámec) obsahuje chunkovacie utility špeciálne navrhnuté pre scenáre AI citácií. Nástroje Yoast na analýzu čitateľnosti pomáhajú zabezpečiť, že časti zostanú prístupné pre ľudí aj optimalizované pre AI. Platforma Semrush na inteligenciu obsahu poskytuje prehľad o tom, ako váš obsah funguje v AI Overviews a ďalších AI-vyhľadávačoch, vrátane toho, ktoré časti generujú citácie. Nativný analyzátor chunkovania AmICited.com sa integruje priamo s vaším CMS, automaticky analyzuje dĺžky pasáží, navrhuje optimalizácie a sleduje, ako každá časť funguje v ChatGPT, Perplexity, Google AI Overviews a ďalších platformách. Tieto nástroje siahajú od open-source riešení (zadarmo, ale vyžadujú technické znalosti) až po podnikové platformy (vyššie náklady, ale komplexné monitorovanie a optimalizácia).
Implementácia optimálnych dĺžok pasáží si vyžaduje systematický prístup, ktorý vyvažuje technickú optimalizáciu s kvalitou obsahu. Postupujte podľa tohto postupu, aby ste maximalizovali potenciál AI citácií:
Tento systematický prístup zvyčajne prináša merateľné zlepšenia citácií do 60-90 dní, s ďalšími ziskami, keď AI systémy reindexujú a naučia sa vašu štruktúru obsahu.
Budúcnosť optimalizácie na úrovni pasáží bude formovaná vývojom AI schopností a stále sofistikovanejšími mechanizmami citovania. Vznikajúce trendy naznačujú niekoľko kľúčových vývojov: AI systémy smerujú k detailnejšiemu priraďovaniu citácií na úrovni pasáží namiesto na úrovni stránok, čo robí presné chunkovanie ešte dôležitejším. Veľkosti kontextových okien rastú (niektoré modely už podporujú 128 000+ tokenov), čo môže posunúť optimálne veľkosti častí nahor, pri zachovaní významu sémantických hraníc. Multimodálne chunkovanie sa objavuje s tým, ako AI systémy čoraz viac spracovávajú spolu text, obrázky aj videá, čo si vyžaduje nové stratégie pre zmiešaný obsah. Optimalizácia chunkovania v reálnom čase pomocou strojového učenia sa pravdepodobne stane štandardom, pričom systémy budú automaticky upravovať veľkosť častí podľa vzorov dopytov a vyhľadávacieho výkonu. Transparentnosť citácií sa stáva konkurenčnou výhodou, pričom platformy ako AmICited.com pomáhajú tvorcom zistiť, kde a ako je ich obsah citovaný. Ako sa AI systémy zdokonaľujú, schopnosť optimalizovať pre citácie na úrovni pasáží sa stane kľúčovou konkurenčnou výhodou pre tvorcov obsahu, vydavateľov aj znalostné organizácie. Tí, ktorí zvládnu stratégie chunkovania už dnes, budú najlepšie pripravení získať hodnotu z citácií, keď AI vyhľadávanie definitívne ovládne objavovanie informácií. Spojenie lepšieho chunkovania, lepšieho monitorovania a rastúcej AI sofistikovanosti znamená, že optimalizácia na úrovni pasáží sa posunie od technického detailu k základnej požiadavke obsahovej stratégie.
Optimálny rozsah je 100-500 tokenov, typicky 75-350 slov v závislosti od zložitosti. Menšie časti (100-200 tokenov) poskytujú vyššiu presnosť pre špecifické dopyty, zatiaľ čo väčšie časti (300-500 tokenov) zachovávajú viac kontextu. Najlepšia dĺžka závisí od typu vášho obsahu a cieľového embedding modelu.
Správne dimenzované pasáže sú pravdepodobnejšie citované AI systémami, pretože sa z nich ľahšie extrahujú a prezentujú kompletné odpovede. Príliš dlhé časti môžu byť skrátené alebo citované len čiastočne, zatiaľ čo príliš krátke môžu postrádať dostatočný kontext pre presnú reprezentáciu.
Nie. Aj keď konzistentnosť pomáha, dôležitejšie sú sémantické hranice než rovnaká dĺžka. Definícia môže vyžadovať len 50 slov, zatiaľ čo vysvetlenie procesu môže potrebovať 250 slov. Kľúčom je zabezpečiť, aby každá časť bola samostatná a odpovedala na jednu konkrétnu otázku.
Počet tokenov sa líši podľa embedding modelu a spôsobu tokenizácie. Vo všeobecnosti platí, že 1 token ≈ 0,75 slova, ale toto sa môže meniť. Pre presné počty použite tokenizér vášho konkrétneho embedding modelu. Nástroje ako Pinecone a LangChain poskytujú utility na počítanie tokenov.
Featured snippety zvyčajne vyberajú úryvky dlhé 40-60 slov, čo dobre zodpovedá atómovým častiam. Vytváraním dobre štruktúrovaných, zameraných pasáží zvyšujete pravdepodobnosť, že budete vybraní do featured snippetov a AI-generovaných odpovedí.
Väčšina hlavných AI systémov (ChatGPT, Google AI Overviews, Perplexity) používa podobné mechanizmy vyhľadávania podľa pasáží, takže rozsah 100-500 tokenov funguje naprieč platformami. Napriek tomu testujte svoj konkrétny obsah s cieľovými AI systémami, aby ste optimalizovali pre ich špecifické vzory vyhľadávania.
Áno, a je to odporúčané. Zahrnutie 10-15% prekrytia medzi susediacimi časťami zabezpečuje, že informácie blízko hraníc sekcií zostanú dostupné a predchádza strate dôležitého kontextu pri vyhľadávaní.
AmICited.com monitoruje, ako AI systémy odkazujú na vašu značku v ChatGPT, Google AI Overviews a Perplexity. Sledovaním, ktoré pasáže sú citované a ako sú prezentované, môžete identifikovať optimálne dĺžky a štruktúry pasáží pre váš konkrétny obsah a odvetvie.
Sledujte, ako AI systémy citujú váš obsah naprieč ChatGPT, Google AI Overviews a Perplexity. Optimalizujte dĺžky pasáží na základe reálnych dát o citáciách.
Zistite, ako štruktúrovať svoj obsah, aby ho citovali AI vyhľadávače ako ChatGPT, Perplexity a Google AI. Odborné stratégie pre AI viditeľnosť a citácie....
Zistite optimálnu hĺbku, štruktúru a úroveň detailov obsahu potrebnú na získanie citácie od ChatGPT, Perplexity a Google AI. Objavte, čo robí obsah vhodným na c...
Diskusia komunity o optimálnej dĺžke obsahu pre viditeľnosť vo vyhľadávaní cez AI. Autori a stratégovia zdieľajú dáta o tom, aká dĺžka sa cituje a či na počte s...