
Halucinácie AI a bezpečnosť značky: Ochrana vašej reputácie
Zistite, ako halucinácie AI ohrozujú bezpečnosť značky v Google AI Overviews, ChatGPT a Perplexity. Objavte stratégie monitorovania, techniky posilnenia obsahu ...
9 min čítania

Zistite, ako uzemnenie LLM a webové vyhľadávanie umožňuje AI systémom prístup k informáciám v reálnom čase, znižuje halucinácie a poskytuje presné citácie. Naučte sa RAG, stratégie implementácie a najlepšie podnikové postupy.
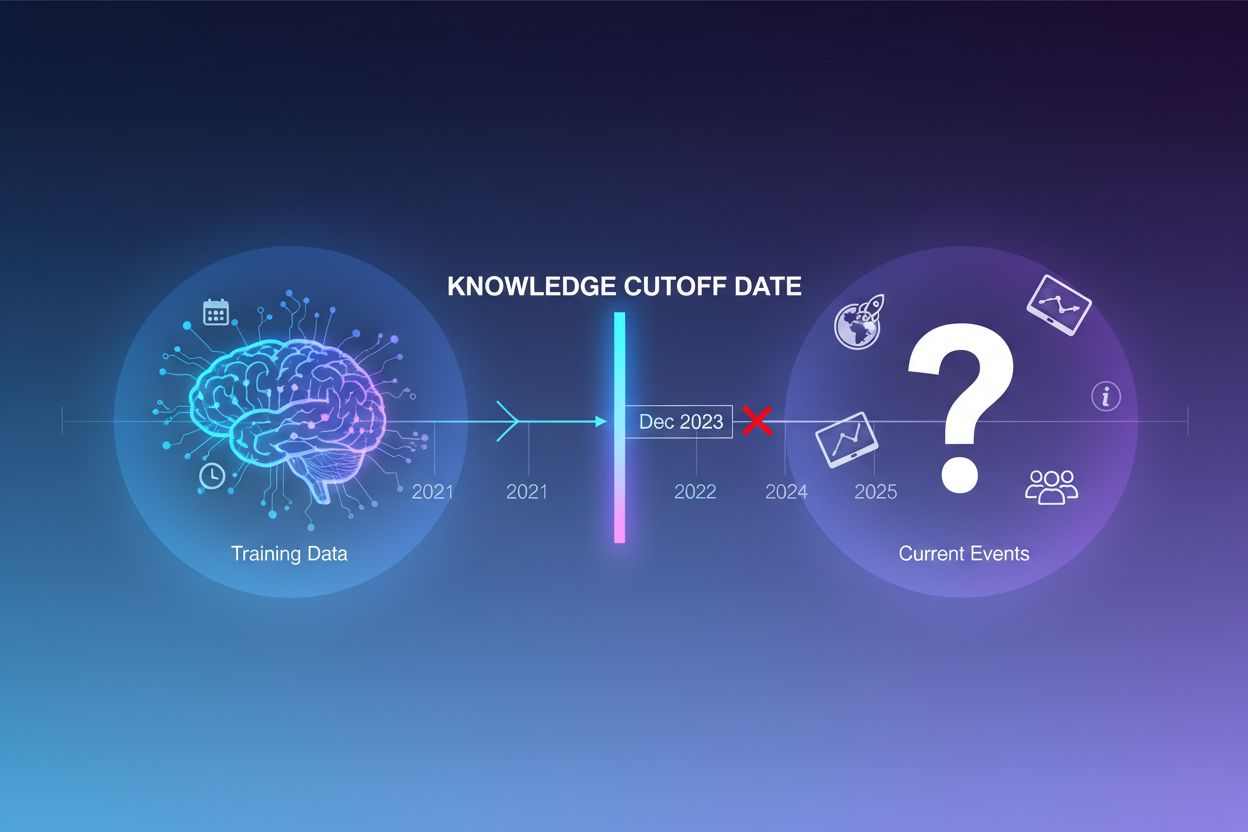
Veľké jazykové modely sú trénované na obrovskom množstve textových dát, no tento proces má zásadné obmedzenie: zachytáva len informácie dostupné do určitého bodu v čase, označovaného ako dátum znalostného cutoffu. Napríklad ak bol LLM trénovaný na dátach do decembra 2023, nepozná udalosti, objavy ani vývoj, ktoré nastali po tomto dátume. Keď sa používatelia pýtajú na aktuálne udalosti, nedávne uvedenia produktov či horúce novinky, model nemá k týmto informáciám prístup vo svojich tréningových dátach. Namiesto priznania neistoty často LLM generujú odpovede znejúce dôveryhodne, no fakticky nesprávne—fenomén známy ako halucinácia. Táto tendencia je obzvlášť problematická v aplikáciách, kde je presnosť kritická, ako je zákaznícka podpora, finančné poradenstvo či zdravotnícke informácie, kde neaktuálne alebo vymyslené informácie môžu mať vážne následky.
Uzemnenie je proces rozšírenia predtrénovaných znalostí LLM o externé, kontextové informácie v čase inferencie. Namiesto spoliehania sa iba na vzory naučené počas tréningu uzemnenie pripája model k reálnym zdrojom dát—či už sú to webové stránky, interné dokumenty, databázy alebo API. Tento koncept vychádza z kognitívnej psychológie, konkrétne z teórie situačnej kognície, ktorá tvrdí, že poznatky sú najefektívnejšie aplikované, keď sú ukotvené v kontexte, v ktorom budú použité. Prakticky uzemnenie mení problém z “generuj odpoveď z pamäti” na “syntetizuj odpoveď z poskytnutých informácií”. Prísna definícia podľa nedávneho výskumu vyžaduje, aby LLM použil všetky zásadné znalosti z poskytnutého kontextu a držal sa jeho rozsahu bez halucinovania ďalších informácií.
| Aspekt | Neuzemnená odpoveď | Uzemnená odpoveď |
|---|---|---|
| Zdroj informácií | Iba predtrénované znalosti | Predtrénované znalosti + externé dáta |
| Presnosť pre aktuálne udalosti | Nízka (obmedzenia cutoffu) | Vysoká (prístup k aktuálnym informáciám) |
| Riziko halucinácie | Vysoké (model tipuje) | Nízke (obmedzené kontextom) |
| Možnosť citovania | Obmedzená alebo nemožná | Úplná dohľadateľnosť k zdrojom |
| Škálovateľnosť | Fixná (veľkosť modelu) | Flexibilná (možno pridať nové zdroje) |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
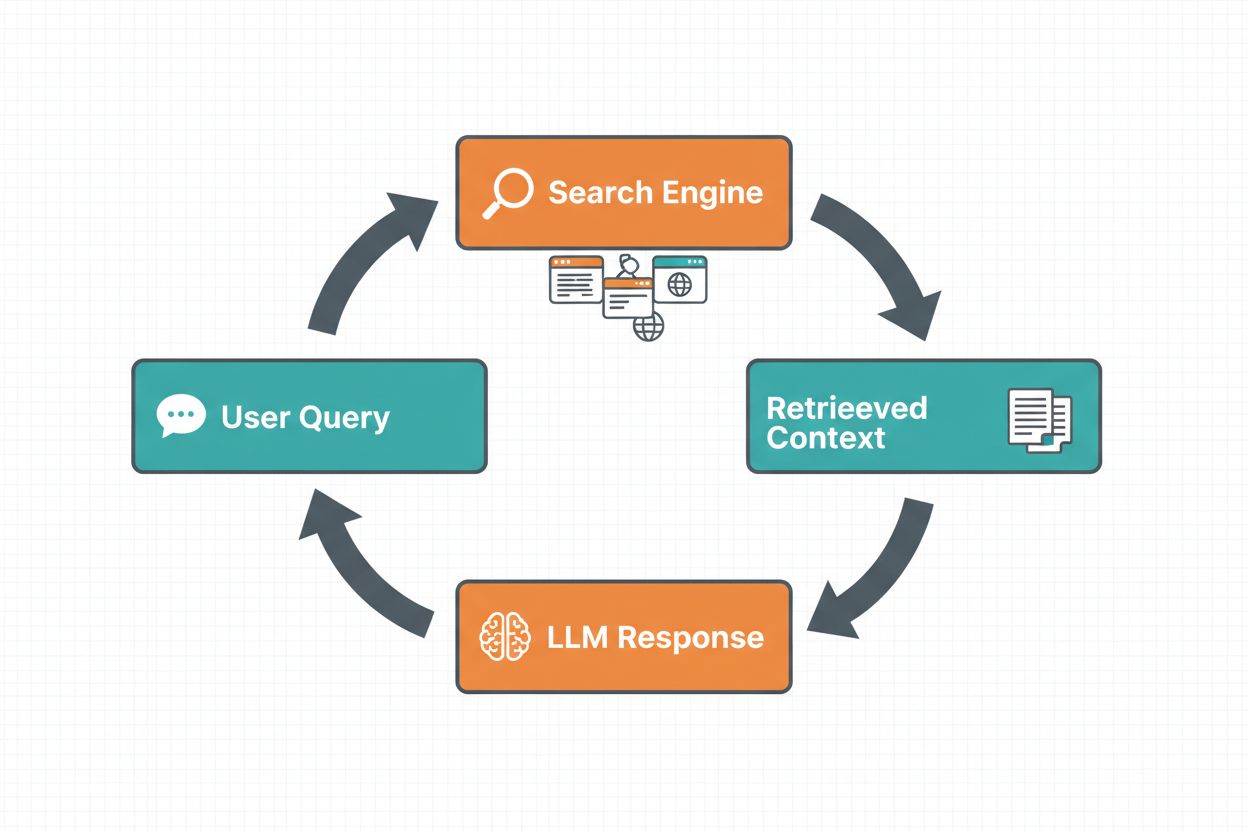
Webové uzemnenie umožňuje LLM prístup k informáciám v reálnom čase automatickým vyhľadávaním na internete a začlenením výsledkov do procesu generovania odpovede. Pracovný postup nasleduje štruktúrovanú sekvenciu: najprv systém analyzuje používateľský prompt, či by webové vyhľadávanie zlepšilo odpoveď; potom vygeneruje jedno alebo viac vyhľadávacích dopytov optimalizovaných na získanie relevantných informácií; následne vykoná tieto dopyty vo vyhľadávači (napr. Google Search alebo DuckDuckGo); potom spracuje výsledky vyhľadávania a extrahuje relevantný obsah; a nakoniec poskytne tento kontext LLM ako súčasť promptu, čo umožní modelu vygenerovať uzemnenú odpoveď. Systém taktiež vracia metadata uzemnenia—štruktúrované informácie o tom, ktoré vyhľadávacie dopyty boli spustené, ktoré zdroje získané a ako konkrétne časti odpovede sú podporené danými zdrojmi. Tieto metadáta sú kľúčové pre budovanie dôvery a umožnenie overenia tvrdení.
Pracovný postup webového uzemnenia:
Retrieval Augmented Generation (RAG) sa stal dominantnou technikou uzemnenia, ktorá kombinuje desaťročia výskumu informačného vyhľadávania s modernými schopnosťami LLM. RAG funguje tak, že najprv z externého zdroja znalostí (zvyčajne indexovaného vo vektorovej databáze) vyhľadá relevantné dokumenty alebo pasáže, ktoré následne poskytne modelu ako kontext. Proces vyhľadávania má typicky dve fázy: retriever využíva efektívne algoritmy (ako BM25 alebo sémantické vyhľadávanie s embeddingami) na identifikáciu kandidátskych dokumentov a ranker používa sofistikovanejšie neurónové modely na ich re-rankovanie podľa relevantnosti. Získaný kontext sa začlení do promptu, čo umožní LLM syntetizovať odpovede ukotvené v autoritatívnych informáciách. RAG prináša výrazné výhody oproti doladeniu: je nákladovo efektívnejší (netreba preučiť model), lepšie škálovateľný (stačí pridať nové dokumenty do znalostnej bázy) a jednoduchšie udržiavateľný (aktualizácia informácií bez preučenia). Príklad promptu v RAG:
Použite nasledujúce dokumenty na zodpovedanie otázky.
[Otázka]
Aké je hlavné mesto Kanady?
[Dokument 1]
Ottawa je hlavné mesto Kanady, nachádza sa v Ontáriu...
[Dokument 2]
Kanada je krajina v Severnej Amerike s desiatimi provinciami...
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Jednou z najpútavejších výhod webového uzemnenia je schopnosť začleniť do odpovedí LLM informácie v reálnom čase. To je mimoriadne cenné pre aplikácie vyžadujúce aktuálne údaje—analýzu správ, prieskum trhu, informácie o udalostiach či dostupnosti produktov. Nad rámec samotného prístupu k čerstvým dátam uzemnenie poskytuje citácie a atribúciu zdrojov, čo je zásadné pre budovanie dôvery používateľov a umožnenie overenia. Pri generovaní uzemnenej odpovede LLM vracia štruktúrované metadáta, ktoré mapujú konkrétne tvrdenia na zdrojové dokumenty, čo umožňuje priamu citáciu ako “[1] source.com” priamo v texte odpovede. Táto schopnosť je priamo v súlade s misiou platforiem ako AmICited.com, ktoré monitorujú, ako AI systémy odkazujú na zdroje naprieč rôznymi platformami. Schopnosť sledovať, ktoré zdroje AI systém použil a ako informácie atribuoval, sa stáva čoraz dôležitejšou pre monitoring značky, atribúciu obsahu a zabezpečenie zodpovedného nasadenia AI.
Halucinácie vznikajú, pretože LLM sú od základu navrhnuté na predikciu ďalšieho tokenu na základe predchádzajúcich tokenov a naučených vzorov, bez akéhokoľvek vnútorného povedomia o hraniciach svojich znalostí. Pri otázkach mimo svojich tréningových dát generujú dôveryhodne znejúci text namiesto priznania neistoty. Uzemnenie tento problém zásadne mení: model už negeneruje z pamäti, ale syntetizuje z poskytnutých informácií. Z technického hľadiska, keď je relevantný externý kontext súčasťou promptu, posúva sa pravdepodobnostné rozdelenie tokenov smerom k odpovediam ukotveným v tomto kontexte, čím sa znižuje pravdepodobnosť halucinácií. Výskumy dokazujú, že uzemnenie dokáže znížiť mieru halucinácií o 30–50 % v závislosti od úlohy a implementácie. Napríklad na otázku “Kto vyhral Euro 2024?” bez uzemnenia môže starší model poskytnúť nesprávnu odpoveď; s uzemnením cez webové vyhľadávanie správne identifikuje Španielsko ako víťaza s konkrétnymi detailmi o zápase. Tento mechanizmus funguje, pretože pozornosť modelu sa môže sústrediť na poskytnutý kontext namiesto spoliehania sa na (možno neúplné či protichodné) vzory z tréningových dát.
Implementácia webového uzemnenia vyžaduje integráciu viacerých komponentov: vyhľadávacie API (napr. Google Search, DuckDuckGo cez Serp API alebo Bing Search), logiku na určenie, kedy je uzemnenie potrebné, a prompt engineering pre efektívne začlenenie výsledkov vyhľadávania. Praktická implementácia začína hodnotením, či používateľský dopyt vyžaduje aktuálne informácie—dá sa to realizovať aj tým, že sa LLM samo opýta, či prompt potrebuje informácie novšie než jeho knowledge cutoff. Ak je uzemnenie potrebné, systém vykoná webové vyhľadávanie, spracuje výsledky na extrakciu relevantných útržkov a zostaví prompt, ktorý obsahuje pôvodnú otázku aj získaný kontext z vyhľadávania. Nákladové hľadisko je dôležité: každé vyhľadávanie znamená API náklady, preto dynamické uzemnenie (vyhľadávanie len v prípade potreby) môže náklady výrazne znížiť. Napríklad na otázku “Prečo je obloha modrá?” netreba webové vyhľadávanie, ale na “Kto je súčasný prezident?” určite áno. Pokročilé implementácie využívajú menšie, rýchlejšie modely na rozhodnutie o uzemnení, čím znižujú latenciu a náklady, pričom väčší model sa použije len na finálnu odpoveď.
Aj keď je uzemnenie silný nástroj, prináša viacero výziev, ktoré treba starostlivo riešiť. Relevantnosť údajov je kľúčová—ak získané informácie v skutočnosti neodpovedajú na otázku používateľa, uzemnenie nepomôže a môže pridať irelevantný kontext. Množstvo údajov predstavuje paradox: hoci viac informácií vyzerá ako výhoda, výskum ukazuje, že výkonnosť LLM často klesá pri nadmernom vstupe—fenomén “stratené v strede”, keď modely sťažene nachádzajú a využívajú informácie v strede dlhých kontextov. Efektivita tokenov je dôležitá, pretože každý úsek získaného kontextu spotrebúva tokeny, čím rastie latencia a náklady. Platí zásada “menej je viac”: získavajte len najrelevantnejšie (typicky 3–5) výsledky, pracujte s menšími útržkami namiesto celých dokumentov a zvážte extrakciu kľúčových viet z dlhších pasáží.
| Výzva | Dopad | Riešenie |
|---|---|---|
| Relevantnosť údajov | Irelevantný kontext mätie model | Použiť sémantické vyhľadávanie + rankery; testovať kvalitu vyhľadávania |
| Zaujatosť ‘stratené v strede’ | Model prehliada dôležité informácie v strede | Minimalizovať veľkosť vstupu; kľúčové info na začiatok/koniec |
| Efektivita tokenov | Vysoká latencia a náklady | Získavať menej výsledkov; menšie útržky |
| Zastaralé informácie | Neaktuálny kontext v znalostnej báze | Zaviesť politiky obnovy; verzovanie znalostnej bázy |
| Latencia | Pomalé odpovede kvôli vyhľadávaniu + inferencii | Použiť asynchrónne operácie; cache bežných dopytov |
Nasadzovanie uzemňovacích systémov do produkčného prostredia si vyžaduje dôslednú pozornosť voči správe, bezpečnosti a prevádzkovým otázkam. Kontrola kvality údajov je základná—informácie, na ktorých uzemňujete, musia byť presné, aktuálne a relevantné pre vaše použitie. Prístupové práva sú kritické pri uzemnení na proprietárnych alebo citlivých dokumentoch; musíte zabezpečiť, že LLM má prístup len k informáciám primeraným právam každého používateľa. Správa aktualizácií a driftu vyžaduje nastavenie politík na obnovu znalostnej bázy a riešenie rozporuplných informácií naprieč zdrojmi. Auditné logovanie je nevyhnutné pre súlad a ladenie—treba zaznamenávať, ktoré dokumenty boli získané, ako boli zoradené a aký kontext bol poskytnutý modelu. Ďalšie aspekty zahŕňajú:
Oblasť uzemnenia LLM sa rýchlo vyvíja nad rámec jednoduchého textového vyhľadávania. Objavuje sa multimodálne uzemnenie, kde systémy môžu ukotvovať odpovede v obrázkoch, videách a štruktúrovaných dátach spolu s textom—čo je obzvlášť dôležité pre oblasti ako právna analýza, medicínske zobrazovanie či technická dokumentácia. Automatizované uvažovanie sa vrství na RAG, čím agenti nielen vyhľadávajú informácie, ale aj syntetizujú naprieč viacerými zdrojmi, robia logické závery a vysvetľujú svoje rozhodovanie. Ochranné mantinely sa integrujú s uzemnením, aby modely aj napriek prístupu k externým informáciám dodržiavali bezpečnostné a politické požiadavky. Ďalšou oblasťou sú priame aktualizácie modelu—namiesto úplného spoliehania sa na externé vyhľadávanie výskumníci skúmajú cesty, ako priamo aktualizovať váhy modelu novými informáciami, čím by sa mohla znížiť potreba rozsiahlych externých znalostných báz. Tieto pokroky naznačujú, že budúce uzemňovacie systémy budú inteligentnejšie, efektívnejšie a schopnejšie zvládať komplexné viacstupňové úlohy pri zachovaní faktickej presnosti a dohľadateľnosti.
AmICited sleduje, ako GPT, Perplexity a Google AI Overviews citujú a odkazujú na váš obsah. Získajte prehľad v reálnom čase o monitorovaní AI odpovedí a atribúcii značky.
Zistite, ako halucinácie AI ohrozujú bezpečnosť značky v Google AI Overviews, ChatGPT a Perplexity. Objavte stratégie monitorovania, techniky posilnenia obsahu ...

Zistite, ako Retrieval-Augmented Generation mení AI citácie, umožňuje presné pripisovanie zdrojov a odpovede podložené dôkazmi v ChatGPT, Perplexity a Google AI...

Zistite, čo je AI halucinácia, prečo vzniká v ChatGPT, Claude a Perplexity a ako rozpoznať nepravdivé AI-generované informácie vo výsledkoch vyhľadávania....