Ako LLM vyberajú, čo citovať: Pochopenie výberu zdrojov AI
Zistite, ako veľké jazykové modely vyberajú a citujú zdroje cez váženie dôkazov, rozpoznávanie entít a štruktúrované dáta. Spoznajte 7-fázový proces rozhodovania o citáciách a optimalizujte svoj obsah pre viditeľnosť v AI.
Publikované dňa Jan 3, 2026.Naposledy upravené dňa Jan 3, 2026 o 3:24 am
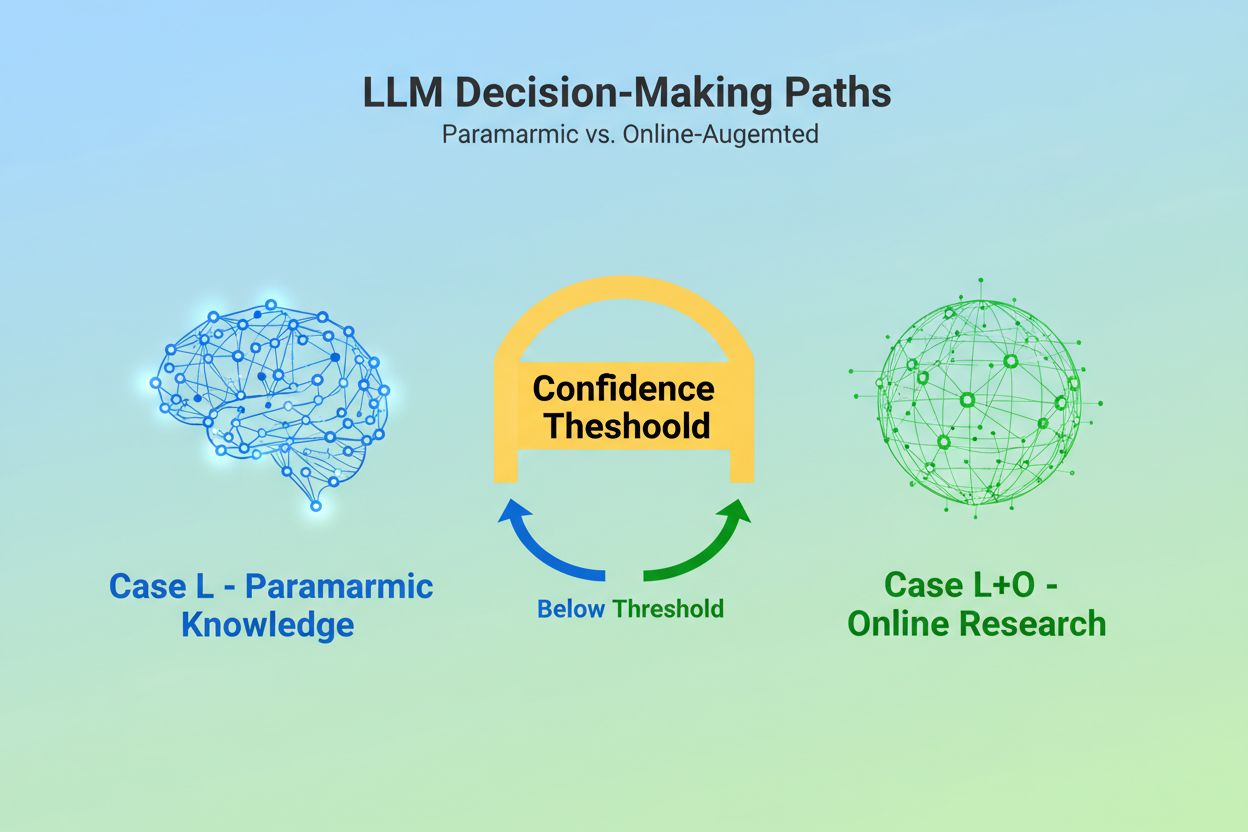
Keď veľký jazykový model dostane otázku, stojí pred zásadným rozhodnutím: má sa spoľahnúť len na vedomosti zabudované počas tréningu, alebo má vyhľadať aktuálne informácie na internete? Táto binárna voľba — ktorú vedci označujú ako Case L (iba tréningové dáta) verzus Case L+O (tréningové dáta plus online výskum) — rozhoduje o tom, či LLM vôbec bude citovať zdroje. V režime Case L model čerpá výlučne zo svojej parametričnej znalostnej bázy, čo je zhustená reprezentácia vzorcov naučených počas tréningu a odráža informácie obvykle niekoľko mesiacov až vyše roka pred vydaním modelu. V režime Case L+O model aktivuje prah istoty, ktorý spustí externý výskum a otvorí takzvaný „kandidátsky priestor“ URL a zdrojov. Toto rozhodnutie je pre väčšinu monitorovacích nástrojov neviditeľné, no práve tu sa začína celý mechanizmus citácií — pretože bez spustenia fázy vyhľadávania nemožno žiadne externé zdroje hodnotiť ani citovať.
Pochopenie váženia dôkazov
Hneď ako sa LLM rozhodne vyhľadať externé zdroje, vstupuje do najkritickejšej fázy výberu citácií: váženia dôkazov. Práve tu sa rozhoduje, či sa zdroj stane iba zmienkou alebo autoritatívnym odporúčaním. Model nesčíta len výskyt zdroja alebo jeho umiestnenie vo výsledkoch vyhľadávania; hodnotí štruktúrnu integritu samotného dôkazu. Skúma architektúru dokumentu — či zdroje obsahujú jasné dátové vzťahy, opakujúce sa identifikátory a odkazy — a interpretuje ich ako signály dôveryhodnosti. Model vytvára tzv. „graf dôkazov“, kde uzly predstavujú entity a hrany vzťahy medzi dokumentmi. Každý zdroj je vážený nielen podľa relevantnosti obsahu, ale aj podľa toho, ako konzistentne sú fakty potvrdené v rôznych dokumentoch, ako tematicky súvisí informácia a ako autoritatívne pôsobí doména. Toto viacrozmerné hodnotenie vytvára tzv. maticu dôkazov — komplexné posúdenie, ktoré určí, ktoré zdroje sú dostatočne spoľahlivé na citáciu. Kriticky, táto fáza prebieha v rozumovej vrstve LLM, takže je neviditeľná pre tradičné GEO monitorovacie nástroje, ktoré merajú len signály vyhľadávania.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Štruktúrované dáta — najmä JSON-LD, značenie Schema.org a RDFa — pôsobia ako násobiteľ vo vážení dôkazov. Zdroje, ktoré správne implementujú štruktúrované dáta, získavajú 2-3-násobne vyššiu váhu v matici dôkazov než neštruktúrovaný obsah. Nie je to preto, že by LLM uprednostňovali formátované dáta kvôli vzhľadu; je to preto, že štruktúrované dáta umožňujú prepojenie entít — proces spájania zmienok naprieč dokumentmi cez strojovo čitateľné identifikátory ako @id, sameAs, a Q-IDs (Wikidata identifikátory). Keď LLM narazí na zdroj s Q-ID organizácie, môže túto entitu okamžite overiť v viacerých dokumentoch, čím vytvára tzv. „naprieč-dokumentovú koreferenciu entít“. Tento proces výrazne zvyšuje dôveru v spoľahlivosť zdroja.
Formát dát
Presnosť citácie
Prepojenie entít
Overenie naprieč dokumentmi
Neštruktúrovaný text
62%
Žiadne
Manuálna inferencia
Základné HTML značkovanie
71%
Obmedzené
Čiastočné zhodovanie
RDFa/Microdata
81%
Dobré
Na základe vzorcov
JSON-LD s Q-ID
94%
Výborné
Overené odkazy
Formát znalostného grafu
97%
Dokonalé
Automatické overenie
Vplyv štruktúrovaných dát pôsobí na dvoch časových osiach. Prechodne, keď LLM vyhľadáva online, číta JSON-LD a Schema.org v reálnom čase a ihneď započítava túto štruktúrovanú informáciu do váženia dôkazov pre aktuálnu odpoveď. Pretrvávajúco sa konzistentné štruktúrované dáta integrujú do parametričnej znalostnej bázy počas budúcich tréningov modelu, čo ovplyvňuje, ako model rozpoznáva a hodnotí entity aj bez online výskumu. Tento dvojitý mechanizmus znamená, že značky implementujúce správne štruktúrované dáta zabezpečujú okamžitú citovateľnosť aj dlhodobú autoritu v internom vedomostnom priestore modelu.
Rozpoznávanie a rozlíšenie entít
Skôr ako LLM môže citovať zdroj, musí najprv pochopiť o čom zdroj je a koho reprezentuje. O to sa stará rozpoznávanie entít — proces, ktorý premieňa nejasný ľudský jazyk na strojovo čitateľné entity. Ak dokument spomenie „Apple“, LLM musí určiť, či ide o Apple Inc., ovocie, alebo niečo úplne iné. Model to dosahuje pomocou naučených vzorcov entít zo zdrojov ako Wikipedia, Wikidata a Common Crawl, v kombinácii s kontextovou analýzou okolia textu. V režime Case L+O je tento proces ešte sofistikovanejší: model overuje entity voči externým štruktúrovaným dátam, kontroluje @id atribúty, sameAs odkazy a Q-IDs, ktoré poskytujú jednoznačnú identifikáciu. Tento overovací krok je zásadný, pretože nejednoznačné alebo nekonzistentné entity sa v šume uvažovania modelu strácajú. Značka, ktorá používa nekonzistentné pomenovania, neetabluje jasné identifikátory alebo neimplementuje Schema.org, je pre stroj nejasná — objavuje sa ako viacero rôznych entít namiesto jednej. Naopak, organizácie s konzistentne odkazovanými entitami naprieč dokumentmi sú rozpoznané ako spoľahlivé uzly vedomostného grafu LLM, čo výrazne zvyšuje pravdepodobnosť ich citácie.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Proces rozhodovania o citáciách
Cesta od otázky k citácii sleduje štruktúrovaný sedem-fázový proces, ktorý výskumníci zmapovali analýzou správania LLM. Fáza 0: Analýza zámeru začína tokenizáciou vstupu od používateľa, sémantickou analýzou a vytvorením vektora zámeru — abstraktnej reprezentácie toho, čo používateľ naozaj žiada. Táto fáza určuje, ktoré témy, entity a vzťahy sú relevantné. Fáza 1: Vyhľadávanie vo vnútornej pamäti pristupuje k parametričným znalostiam modelu a vypočíta skóre istoty. Ak toto skóre presiahne prah, model zostáva v režime Case L; ak nie, pokračuje na externý výskum. Fáza 2: Generovanie rozvetvených dopytov (iba Case L+O) vytvára niekoľko sémanticky rôznych vyhľadávacích dotazov — zvyčajne po 1-6 tokenov — s cieľom čo najširšie otvoriť kandidátsky priestor. Fáza 3: Extrakcia dôkazov získava URL a úryvky z výsledkov vyhľadávania, analyzuje HTML a extrahuje JSON-LD, RDFa a mikrodata. Tu sa štruktúrované dáta prvýkrát stávajú viditeľnými pre mechanizmus citácie. Fáza 4: Prepojenie entít identifikuje entity v získaných dokumentoch a overuje ich voči externým identifikátorom, čím vytvára dočasný vedomostný graf vzťahov. Fáza 5: Váženie dôkazov hodnotí silu dôkazov zo všetkých zdrojov, berie do úvahy architektúru dokumentu, rozmanitosť zdrojov, frekvenciu potvrdenia a konzistenciu naprieč zdrojmi. Fáza 6: Uvažovanie a syntéza kombinuje interné a externé dôkazy, rieši rozpory a určuje, či si zdroj zaslúži zmienku alebo odporúčanie. Fáza 7: Finalizácia odpovede prekladá vážené dôkazy do prirodzeného jazyka a integruje citácie podľa potreby. Každá fáza nadväzuje na predchádzajúcu, pričom spätné väzby umožňujú modelu v prípade nekonzistencií upraviť vyhľadávanie alebo dôkazy.
Retrieval-Augmented Generation (RAG)
Moderné LLM čoraz viac využívajú Retrieval-Augmented Generation (RAG) — techniku, ktorá zásadne mení spôsob výberu a zdôvodňovania citácií. Namiesto spoliehania sa iba na parametričné vedomosti systémy RAG aktívne získavajú relevantné dokumenty, extrahujú dôkazy a zakladajú odpovede na konkrétnych zdrojoch. Tento prístup mení citáciu z implicitného vedľajšieho produktu tréningu na explicitný a dohľadateľný proces. Implementácie RAG zvyčajne využívajú hybridné vyhľadávanie, ktoré kombinuje kľúčové slová s vektorovým vyhľadávaním pre maximálny záber. Po získaní kandidátskych dokumentov nasleduje sémantické hodnotenie, ktoré prehodnocuje výsledky na základe významu, nie len zhody kľúčových slov, aby najrelevantnejšie zdroje vystúpili na vrchol. Tento explicitný vyhľadávací mechanizmus robí proces citovania transparentnejším a auditovateľným — každý citovaný zdroj možno vystopovať k pasážam, ktoré odôvodnili jeho zaradenie. Pre organizácie, ktoré sledujú svoju AI viditeľnosť, sú RAG systémy obzvlášť dôležité, pretože vytvárajú merateľné vzorce citácií. Nástroje ako AmICited sledujú, ako RAG systémy odkazujú na vašu značku na rôznych AI platformách, čím poskytujú pohľad na to, či sa objavujete ako citovaný zdroj alebo len ako podklad v procese získavania dôkazov.
Zmienka verzus odporúčanie
Nie všetky citácie sú rovnaké. LLM môže zdroj spomenúť ako kontext, kým iný odporučí ako autoritatívny dôkaz — a tento rozdiel určuje výlučne váženie dôkazov, nie samotné vyhľadanie. Zdroj sa môže objaviť v kandidátskom priestore (fázy 2-3), no ak jeho skóre dôkazov nestačí, status odporúčania nezíska. Toto rozlíšenie medzi zmienkou a odporúčaním je miestom, kde tradičné GEO metriky zlyhávajú. Štandardné monitorovacie nástroje merajú rozvetvenie — či sa váš obsah objaví vo výsledkoch vyhľadávania — ale nemôžu zmerať, či ho LLM považuje za dostatočne dôveryhodný na odporúčanie. Zmienka môže znieť ako „Niektoré zdroje naznačujú…“, zatiaľ čo odporúčanie je „Podľa [zdroja] dôkazy ukazujú…“. Rozdiel spočíva v skóre matice dôkazov z fázy 5. Zdroje s konzistentnými Q-ID, dobre štruktúrovanou architektúrou dokumentu a potvrdením naprieč nezávislými zdrojmi dosahujú status odporúčania. Zdroje s nejednoznačnými entitami, slabou štruktúrou alebo izolovanými tvrdeniami zostávajú len zmienkami. Pre značky je toto rozlíšenie zásadné: byť vyhľadaný nie je to isté ako byť citovaný ako autorita. Cesta od vyhľadania k odporúčaniu vyžaduje sémantickú jasnosť, štruktúrnu integritu a hustotu dôkazov — faktory, ktoré tradičné SEO neadresuje.
Praktické dôsledky pre tvorcov obsahu
Pochopenie spôsobu výberu zdrojov LLM má okamžité a praktické dôsledky pre stratégiu obsahu. Po prvé, implementujte Schema.org značkovanie konzistentne na celom webe, najmä pri organizačných údajoch, článkoch a kľúčových entitách. Používajte formát JSON-LD so správnymi @id atribútmi a sameAs odkazmi na Wikidata, Wikipediu alebo iné autoritatívne zdroje. Tieto štruktúrované dáta priamo zvyšujú vašu váhu dôkazov v 5. fáze. Po druhé, zavádzajte jasné identifikátory entít pre vašu organizáciu, produkty a kľúčové koncepty. Používajte konzistentné pomenovania, vyhýbajte sa skratkám, ktoré vytvárajú nejednoznačnosť, a prepájajte entity cez hierarchické vzťahy (isPartOf, about, mentions). Po tretie, vytvárajte strojovo čitateľné dôkazy publikovaním štruktúrovaných údajov o vašich tvrdeniach, referenciách a vzťahoch. Nepíšte len „Sme popredný poskytovateľ X“ — štruktúrujte toto tvrdenie podpornými dátami, citáciami a overiteľnými vzťahmi. Po štvrté, udržujte konzistenciu obsahu naprieč platformami a časom. LLM hodnotia hustotu dôkazov tým, že overujú tvrdenia naprieč nezávislými zdrojmi; izolované tvrdenia na jednej platforme majú menšiu váhu. Po piate, pochopte, že tradičné SEO metriky nepredpovedajú AI citáciu. Vysoké pozície vo vyhľadávači negarantujú odporúčanie LLM; sústreďte sa namiesto toho na sémantickú jasnosť a štruktúrnu integritu. Po šieste, sledujte svoje vzorce citácií pomocou nástrojov ako AmICited, ktoré sledujú, ako rôzne AI systémy odkazujú na vašu značku. Zistíte tak, či dosahujete status zmienky alebo odporúčania a ktoré typy obsahu spúšťajú citácie. Nakoniec, uvedomte si, že AI viditeľnosť je dlhodobá investícia. Štruktúrované dáta, ktoré implementujete dnes, ovplyvňujú okamžitú pravdepodobnosť citácie (prechodný efekt) aj vnútornú pamäť modelu v budúcich tréningových cykloch (pretrvávajúci efekt).
Budúcnosť AI citácií
Ako sa LLM vyvíjajú, mechanizmy citovania sú čoraz prepracovanejšie a transparentnejšie. Budúce modely pravdepodobne zavedú grafy citácií — explicitné mapovania ukazujúce nielen to, ktoré zdroje boli citované, ale aj ako ovplyvnili konkrétne tvrdenia v odpovedi. Niektoré pokročilé systémy už experimentujú s pravdepodobnostnými skóre istoty priradenými k citáciám, ktoré ukazujú, nakoľko si model je istý relevantnosťou a spoľahlivosťou zdroja. Ďalším trendom je overovanie s človekom v slučke, kde používatelia môžu spochybniť citácie a poskytnúť spätnú väzbu, ktorá upraví váženie dôkazov modelu pri budúcich otázkach. Integrácia štruktúrovaných dát do tréningových cyklov znamená, že organizácie, ktoré zavádzajú správnu sémantickú infraštruktúru už dnes, si budujú dlhodobú autoritu v AI systémoch. Na rozdiel od pozícií vo vyhľadávači, ktoré sa menia s aktualizáciami algoritmov, pretrvávajúci efekt štruktúrovaných dát vytvára stabilnejší základ pre AI viditeľnosť. Tento posun od tradičnej viditeľnosti (byť nájdený) k sémantickej autorite (byť dôveryhodný) predstavuje zásadnú zmenu v prístupe značiek ku digitálnej komunikácii. Víťazmi v tomto novom prostredí nebudú tí s najväčším obsahom alebo najvyššími pozíciami, ale tí, ktorí štruktúrujú svoje informácie tak, aby im stroje rozumeli, mohli ich overiť a odporučiť.
Najčastejšie kladené otázky
Aký je rozdiel medzi Case L a Case L+O pri citovaní LLM?
Case L používa iba tréningové dáta z parametričnej znalostnej bázy modelu, zatiaľ čo Case L+O ich dopĺňa o aktuálny výskum na webe. O tom, ktorú cestu model zvolí, rozhoduje jeho prah istoty. Tento rozdiel je kľúčový, pretože určuje, či je možné vôbec hodnotiť a citovať externé zdroje.
Prečo sú niektoré zdroje citované a iné iba spomenuté?
O tomto rozdiele rozhoduje váženie dôkazov. Zdroje so štruktúrovanými dátami, konzistentnými identifikátormi a potvrdením naprieč dokumentmi sú povýšené na 'odporúčania', nie len na zmienky. Zdroj sa môže objaviť vo výsledkoch vyhľadávania, no ak jeho skóre dôkazov nestačí, nedosiahne status odporúčania.
Ako ovplyvňuje výber citácií štruktúrované dáta ako Schema.org?
Štruktúrované dáta (JSON-LD, @id, sameAs, Q-IDs) získavajú 2-3x vyššiu váhu v matici dôkazov. Tento zápis umožňuje prepojenie entít a overenie naprieč dokumentmi, čím dramaticky zvyšuje spoľahlivosť zdroja. Zdroje so správnou implementáciou Schema.org majú výrazne vyššiu šancu byť citované ako autoritatívne.
Čo je rozpoznávanie entít a prečo je dôležité pre citácie?
Rozpoznávanie entít je spôsob, akým LLM identifikujú a rozlišujú rôzne entity (organizácie, osoby, koncepty). Jasná identifikácia entít prostredníctvom konzistentného pomenovania a štruktúrovaných identifikátorov predchádza zámene a zvyšuje pravdepodobnosť citácie. Nejednoznačné entity sa v procese uvažovania modelu strácajú.
Ako mení RAG (Retrieval-Augmented Generation) prax citovania?
RAG systémy aktívne vyhľadávajú a hodnotia zdroje v reálnom čase, čím robia výber citácií transparentnejším a viac založeným na dôkazoch než čisté parametričné vedomosti. Tento explicitný mechanizmus vyhľadávania vytvára merateľné vzorce citácií, ktoré možno sledovať a analyzovať nástrojmi ako AmICited.
Môžem optimalizovať svoj obsah, aby ho LLM citovali?
Áno. Implementujte schému Schema.org konzistentne, zavádzajte jasné identifikátory entít, vytvárajte strojovo čitateľné dôkazy, udržujte konzistenciu obsahu naprieč platformami a sledujte vzorce citácií. Tieto faktory priamo ovplyvňujú, či váš obsah dosiahne status zmienky alebo odporúčania v odpovediach LLM.
Aký je rozdiel medzi AI viditeľnosťou a tradičnou vyhľadávacou viditeľnosťou?
Tradičná viditeľnosť meria dosah a umiestnenie vo výsledkoch vyhľadávania. AI viditeľnosť meria, či je váš obsah rozpoznaný ako autoritatívny dôkaz v uvažovaní LLM. Byť vyhľadaný nie je to isté ako byť citovaný ako dôveryhodný – na to je potrebná sémantická jasnosť a štruktúrna integrita.
Ako AmICited pomáha sledovať citácie LLM?
AmICited sleduje, ako AI systémy odkazujú na vašu značku v GPT, Perplexity a Google AI Overviews. Ukazuje, či dosahujete status zmienky alebo odporúčania, ktoré typy obsahu spúšťajú citácie a ako sa vaše vzorce citácií líšia naprieč AI platformami.
Sledujte svoje AI citácie už dnes
Zistite, ako LLM systémy odkazujú na vašu značku v ChatGPT, Perplexity a Google AI Overviews. Sledovaním vzorcov citácií optimalizujte viditeľnosť v AI s AmICited.
Údaje z prieskumov pre AI viditeľnosť: Ako vlastné štatistiky zlepšujú citácie
Zistite, ako sa vlastné údaje z prieskumov a originálne štatistiky stávajú magnetmi na citácie pre LLM. Objavte stratégie na zlepšenie AI viditeľnosti a získani...
Stratégia citovania zdrojov: Ako spraviť váš obsah dôveryhodný pre LLM
Naučte sa overené stratégie citovania zdrojov, aby bol váš obsah dôveryhodný pre LLM. Objavte, ako získavať AI citácie od ChatGPT, Perplexity a Google AI Overvi...
Cielenie na zdrojové stránky LLM pre spätné odkazy
Zistite, ako identifikovať a cieliť zdrojové stránky LLM pre strategické spätné odkazy. Objavte, ktoré AI platformy najčastejšie citujú zdroje a optimalizujte s...
10 min čítania
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.