Ako systémy RAG riešia zastarané informácie?
Zistite, ako systémy Retrieval-Augmented Generation spravujú aktuálnosť znalostnej bázy, predchádzajú zastaraným údajom a udržiavajú aktuálne informácie pomocou...
10 min čítania

Zistite, ako Retrieval-Augmented Generation mení AI citácie, umožňuje presné pripisovanie zdrojov a odpovede podložené dôkazmi v ChatGPT, Perplexity a Google AI Overviews.
Veľké jazykové modely spôsobili revolúciu v AI, no zároveň majú zásadnú chybu: časové obmedzenia poznatkov. Tieto modely sú trénované na dátach po určitý časový bod, čo znamená, že nemôžu pristupovať k informáciám po tomto dátume. Okrem zastaranosti trpia tradičné LLM aj halucináciami—s istotou generujú nepravdivé informácie, ktoré znejú dôveryhodne—a neposkytujú žiadne zdroje pre svoje tvrdenia. Keď podnik potrebuje aktuálne trhové údaje, vlastný výskum alebo overiteľné fakty, tradičné LLM zlyhávajú a zanechávajú používateľov s odpoveďami, ktorým nemôžu veriť ani ich overiť.
Retrieval-Augmented Generation (RAG) je rámec, ktorý kombinuje generatívnu silu LLM s presnosťou systémov na vyhľadávanie informácií. Namiesto toho, aby sa spoliehal výhradne na trénovacie dáta, RAG systémy získavajú relevantné informácie z externých zdrojov ešte pred generovaním odpovedí, čím vytvárajú pipeline, ktorá ukotvuje odpovede v reálnych dátach. Štyri základné komponenty spolupracujú: Ingestion (konverzia dokumentov do vyhľadávateľných formátov), Retrieval (vyhľadávanie najrelevantnejších zdrojov), Augmentation (obohatenie promptu získaným kontextom) a Generation (vytvorenie finálnej odpovede s citáciami). Tu je porovnanie RAG s tradičnými prístupmi:
| Aspekt | Tradičný LLM | RAG systém |
|---|---|---|
| Zdroj poznatkov | Statické trénovacie dáta | Externé indexované zdroje |
| Schopnosť citovať | Žiadna/vymyslená | Sledovateľné ku zdrojom |
| Presnosť | Náchylné na chyby | Ukotvené vo faktoch |
| Dáta v reálnom čase | Nie | Áno |
| Riziko halucinácií | Vysoké | Nízke |
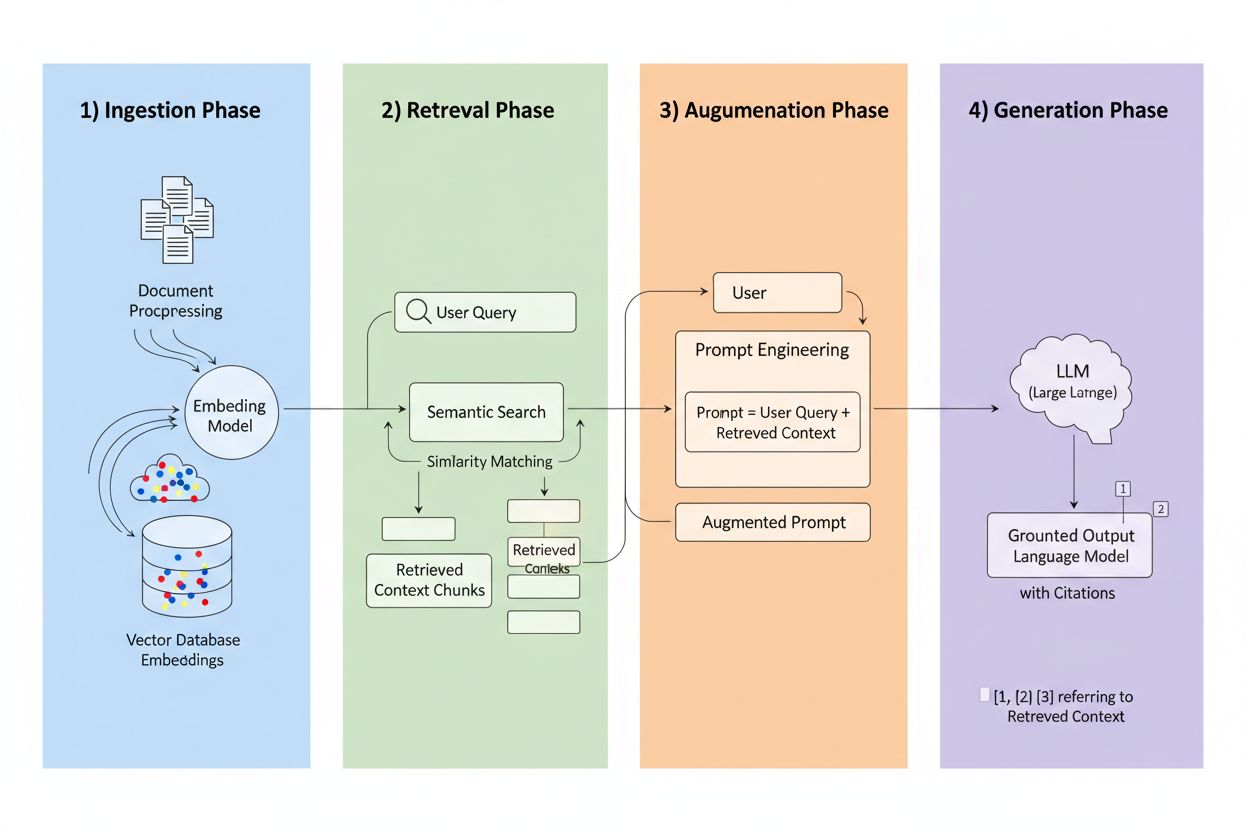
Retrieval engine je srdcom RAG a je oveľa sofistikovanejší než jednoduché porovnávanie kľúčových slov. Dokumenty sa konvertujú na vektorové embeddingy—matematické reprezentácie zachytávajúce sémantický význam—umožňujúce systému nájsť konceptuálne podobný obsah, aj keď presné slová nesedia. Systém rozdeľuje dokumenty na zvládnuteľné kúsky, typicky 256-1024 tokenov, čím vyvažuje zachovanie kontextu s presnosťou vyhľadávania. Väčšina pokročilých RAG systémov využíva hybridné vyhľadávanie, ktoré kombinuje sémantickú podobnosť s tradičným porovnávaním kľúčových slov, aby zachytila konceptuálne aj presné zhody. Reranking mechanizmus potom hodnotí tieto kandidáty, často použitím cross-encoder modelov, ktoré vyhodnocujú relevantnosť presnejšie než počiatočné vyhľadávanie. Relevantnosť sa vypočítava na základe viacerých signálov: skóre sémantickej podobnosti, prekryvu kľúčových slov, zhody v metadátach a autority domény. Celý proces trvá len milisekundy a zabezpečuje rýchle, presné odpovede bez citeľného oneskorenia.
Tu RAG mení prostredie citácií: keď systém získa informáciu z konkrétneho indexovaného zdroja, tento zdroj sa stáva sledovateľným a overiteľným. Každý kúsok textu možno vystopovať späť k pôvodnému dokumentu, URL alebo publikácii, takže citácia je automatická, nie vymyslená. Tento zásadný posun prináša bezprecedentnú transparentnosť rozhodovania AI—používatelia môžu presne vidieť, ktoré zdroje ovplyvnili odpoveď, overovať tvrdenia nezávisle a sami posudzovať dôveryhodnosť zdroja. Na rozdiel od tradičných LLM, kde sú citácie často vymyslené alebo všeobecné, citácie v RAG sú ukotvené v skutočných retrieval udalostiach. Táto sledovateľnosť dramaticky buduje dôveru používateľov, pretože si môžu informácie overiť namiesto slepej dôvery. Pre autorov a vydavateľov to znamená, že ich práca môže byť objavená a ocenená AI systémami, čo otvára úplne nové kanály viditeľnosti.
Nie všetky zdroje sú v RAG systémoch rovnocenné a viacero faktorov určuje, ktorý obsah je citovaný najčastejšie:
Každý faktor znásobuje účinok ostatných—dobre štruktúrovaný, často aktualizovaný článok z autoritatívnej domény so silnými spätnými odkazmi a prítomnosťou v znalostnom grafe sa stáva magnetom na citácie v RAG systémoch. Vzniká tak nový optimalizačný prístup, kde viditeľnosť závisí menej od SEO a viac od toho, či ste dôveryhodným, štruktúrovaným zdrojom informácií.
Rôzne AI platformy implementujú RAG s odlišnými stratégiami, čo vytvára rôznorodé vzory citácií. ChatGPT silno preferuje zdroje z Wikipédie, pričom štúdie ukazujú, že približne 26-35 % citácií pochádza len z Wikipédie, čo odráža jej autoritu a štruktúrovaný formát. Google AI Overviews využíva rozmanitejší výber zdrojov, čerpá zo spravodajských webov, akademických prác a fór, pričom Reddit sa objavuje v približne 5 % citácií napriek nižšej tradičnej autorite. Perplexity AI zvyčajne cituje 3-5 zdrojov na odpoveď a výrazne uprednostňuje odvetvové publikácie a aktuálne novinky, čím optimalizuje komplexnosť a aktuálnosť. Tieto platformy pripisujú autorite domény rôznu váhu—niektoré uprednostňujú tradičné znaky ako spätné odkazy a vek domény, iné zdôrazňujú čerstvosť a sémantickú relevantnosť obsahu. Pochopenie týchto retrieval stratégií špecifických pre platformu je kľúčové pre tvorcov obsahu, keďže optimalizácia pre RAG systém jednej platformy sa môže výrazne líšiť od inej.
Vzostup RAG zásadne narúša tradičné SEO princípy. V optimalizácii pre vyhľadávače citácie a viditeľnosť priamo korelujú s návštevnosťou—potrebujete kliknutia, aby ste boli relevantní. RAG túto rovniciu obracia: obsah môže byť citovaný a ovplyvňovať AI odpovede bez toho, aby generoval akúkoľvek návštevnosť. Dobre štruktúrovaný, autoritatívny článok sa môže objaviť v desiatkach AI odpovedí denne, zatiaľ čo reálne nedostane žiadny klik, keďže používatelia dostanú odpoveď priamo zo sumáru AI. To znamená, že signály autority sú dôležitejšie než kedykoľvek predtým, keďže sú hlavným mechanizmom hodnotenia kvality zdrojov v RAG systémoch. Konzistentnosť naprieč platformami je kritická—ak sa váš obsah objavuje na vašom webe, LinkedIne, odvetvových databázach a v znalostných grafoch, RAG systémy vnímajú posilnené signály autority. Prítomnosť v znalostnom grafe sa mení z príjemného bonusu na základnú infraštruktúru, keďže tieto štruktúrované databázy sú hlavnými retrieval zdrojmi pre mnohé implementácie RAG. Hra o citácie sa zásadne zmenila z „privádzania návštevnosti“ na „stať sa dôveryhodným zdrojom informácií“.
Na maximalizáciu RAG citácií sa musí stratégia obsahu posunúť od optimalizácie na návštevnosť k optimalizácii na zdroj. Zavádzajte cykly aktualizácie každých 48-72 hodín pre stále aktuálny obsah, čím dávate retrieval systémom signál, že vaše informácie sú aktuálne. Implementujte štruktúrované dáta (Schema.org, JSON-LD), aby systémy mohli správne analyzovať význam a vzťahy vo vašom obsahu. Zosúlaďte svoj obsah sémanticky s bežnými vzormi dopytov—používajte prirodzený jazyk, ktorý zodpovedá spôsobu, akým ľudia kladú otázky, nielen tomu, ako vyhľadávajú. Formátujte obsah pomocou FAQ a Q&A sekcií, keďže tie priamo zodpovedajú vzoru otázka-odpoveď v RAG systémoch. Vyvíjajte alebo prispievajte do Wikipédie a znalostných grafov, keďže tie sú hlavnými retrieval zdrojmi pre väčšinu platforiem. Budujte autoritu cez spätné odkazy prostredníctvom strategických partnerstiev a citácií z iných autoritatívnych zdrojov, keďže profily odkazov ostávajú silným signálom autority. Nakoniec udržiavajte konzistentnosť naprieč platformami—uistite sa, že vaše základné tvrdenia, údaje a komunikácia sú zladené na vašom webe, sociálnych profiloch, odvetvových databázach a v znalostných grafoch, čím vytvárate posilnené signály spoľahlivosti.
Technológia RAG sa neustále rýchlo vyvíja a viaceré trendy menia spôsob, akým citácie fungujú. Sofistikovanejšie retrieval algoritmy pôjdu za hranicu sémantickej podobnosti k hlbšiemu pochopeniu zámeru a kontextu dopytu, čím zvýšia relevantnosť citácií. Vzniknú špecializované znalostné bázy pre konkrétne oblasti—medicínske RAG systémy využívajúce kurátorovanú lekársku literatúru, právne systémy používajúce judikatúru a zákony—čo vytvorí nové príležitosti na citácie pre autoritatívne doménové zdroje. Integrácia s multiagentnými systémami umožní RAG koordinovať viaceré špecializované retrievery a kombinovať poznatky z rôznych znalostných báz pre komplexnejšie odpovede. Prístup k dátam v reálnom čase sa dramaticky zlepší, čo umožní RAG systémom zapájať živé informácie z API, databáz a streamovaných zdrojov. Agentický RAG—kde AI agenti autonómne rozhodujú, čo získať, ako to spracovať a kedy iterovať—vytvorí dynamickejšie vzory citácií a potenciálne bude citovať zdroje viackrát, ako agenti zdokonaľujú svoje uvažovanie.
Ako RAG mení spôsob, akým AI systémy objavujú a citujú zdroje, pochopenie vašej citovanej výkonnosti sa stáva nevyhnutnosťou. AmICited monitoruje AI citácie naprieč platformami, sleduje, ktoré vaše zdroje sa objavujú v ChatGPT, Google AI Overviews, Perplexity a vznikajúcich AI systémoch. Uvidíte ktoré konkrétne zdroje sú citované, ako často sa objavujú a v akom kontexte—čo vám odhalí, ktorý obsah rezonuje s retrieval algoritmami RAG. Naša platforma vám pomôže pochopiť vzory citácií v celom vašom portfóliu, identifikovať, čo robí niektoré príspevky hodné citácie a iné neviditeľnými. Merajte viditeľnosť svojej značky v AI odpovediach pomocou metrík, ktoré sú dôležité v ére RAG, nie len tradičnej analytiky návštevnosti. Vykonajte konkurenčnú analýzu výkonnosti citácií a porovnajte, ako si vaše zdroje vedú v porovnaní s konkurenciou v AI-generovaných odpovediach. Vo svete, kde AI citácie určujú viditeľnosť a autoritu, mať jasný prehľad o výkone vašich citácií nie je voliteľné—je to spôsob, ako zostať konkurencieschopný.
Tradičné LLM sa spoliehajú na statické trénovacie dáta s časovým obmedzením poznatkov a nemajú prístup k aktuálnym informáciám, čo často vedie k halucináciám a neoveriteľným tvrdeniam. RAG systémy získavajú informácie z externých indexovaných zdrojov pred generovaním odpovedí, čo umožňuje presné citácie a odpovede podložené aktuálnymi, overiteľnými údajmi.
RAG sleduje každý získaný údaj späť k jeho pôvodnému zdroju, vďaka čomu sú citácie automatické a overiteľné namiesto vymyslených. Vytvára to priamy odkaz medzi odpoveďou a zdrojovým materiálom, čo používateľom umožňuje nezávisle overiť tvrdenia a posúdiť dôveryhodnosť zdroja.
RAG systémy hodnotia zdroje na základe autority (reputácia domény a spätné odkazy), aktuálnosti (obsah aktualizovaný v rámci 48-72 hodín), sémantickej relevantnosti k dopytu, štruktúry a zrozumiteľnosti obsahu, faktickej hustoty s konkrétnymi údajmi a prítomnosti v znalostných grafoch ako Wikipedia. Tieto faktory sa kombinujú a určujú pravdepodobnosť citácie.
Aktualizujte obsah každých 48-72 hodín, aby ste udržali signály čerstvosti, implementujte štruktúrované dáta (Schema.org), zosúlaďte obsah sémanticky s bežnými dopytmi, použite formátovanie FAQ a Q&A, vybudujte prítomnosť na Wikipédii a v znalostných grafoch, získajte autoritu cez spätné odkazy a udržiavajte konzistentnosť naprieč všetkými platformami.
Znalostné grafy ako Wikipedia a Wikidata sú hlavnými zdrojmi pre väčšinu RAG systémov. Prítomnosť v týchto štruktúrovaných databázach výrazne zvyšuje pravdepodobnosť citácie a vytvára základné signály dôveryhodnosti, na ktoré sa AI systémy opakovane odvolávajú pri rôznych dopytoch.
Obsah by mal byť aktualizovaný každých 48-72 hodín na udržanie silných signálov aktuálnosti v RAG systémoch. Nie je nutné kompletné prepisy – stačí pridať nové údaje, aktualizovať štatistiky alebo rozšíriť sekcie o najnovší vývoj, aby ste si udržali oprávnenosť na citácie.
Autorita domény slúži ako proxy spoľahlivosti v RAG algoritmoch a predstavuje približne 5 % pravdepodobnosti citácie. Hodnotí sa podľa veku domény, SSL certifikátov, profilu spätných odkazov, odborných atribúcií a prítomnosti v znalostných grafoch, pričom všetky tieto faktory spolu ovplyvňujú výber zdrojov.
AmICited sleduje, ktoré z vašich zdrojov sa objavujú v AI-generovaných odpovediach v ChatGPT, Google AI Overviews, Perplexity a na iných platformách. Uvidíte frekvenciu citácií, kontext a konkurenčné výkony, čo vám pomôže pochopiť, čo robí obsah hodný citácie v ére RAG.
Zistite, ako sa vaša značka objavuje v AI-generovaných odpovediach v ChatGPT, Perplexity, Google AI Overviews a ďalších. Sledujte vzory citácií, merajte viditeľnosť a optimalizujte svoju prítomnosť v prostredí vyhľadávania poháňaného AI.
Zistite, ako systémy Retrieval-Augmented Generation spravujú aktuálnosť znalostnej bázy, predchádzajú zastaraným údajom a udržiavajú aktuálne informácie pomocou...
Zistite, čo je RAG (Retrieval-Augmented Generation) v AI vyhľadávaní. Objavte, ako RAG zlepšuje presnosť, znižuje halucinácie a poháňa ChatGPT, Perplexity a Goo...
Zistite, ako RAG kombinuje LLM s externými zdrojmi dát na generovanie presných AI odpovedí. Porozumiete päťstupňovému procesu, komponentom a významu pre AI syst...