Listikly a AI: Prečo sú číslované zoznamy viac citované
Objavte, prečo AI modely preferujú listikly a číslované zoznamy. Naučte sa, ako optimalizovať obsah založený na zoznamoch pre citácie ChatGPT, Gemini a Perplexity s overenými stratégiami.
Publikované dňa Jan 3, 2026.Naposledy upravené dňa Jan 3, 2026 o 3:24 am
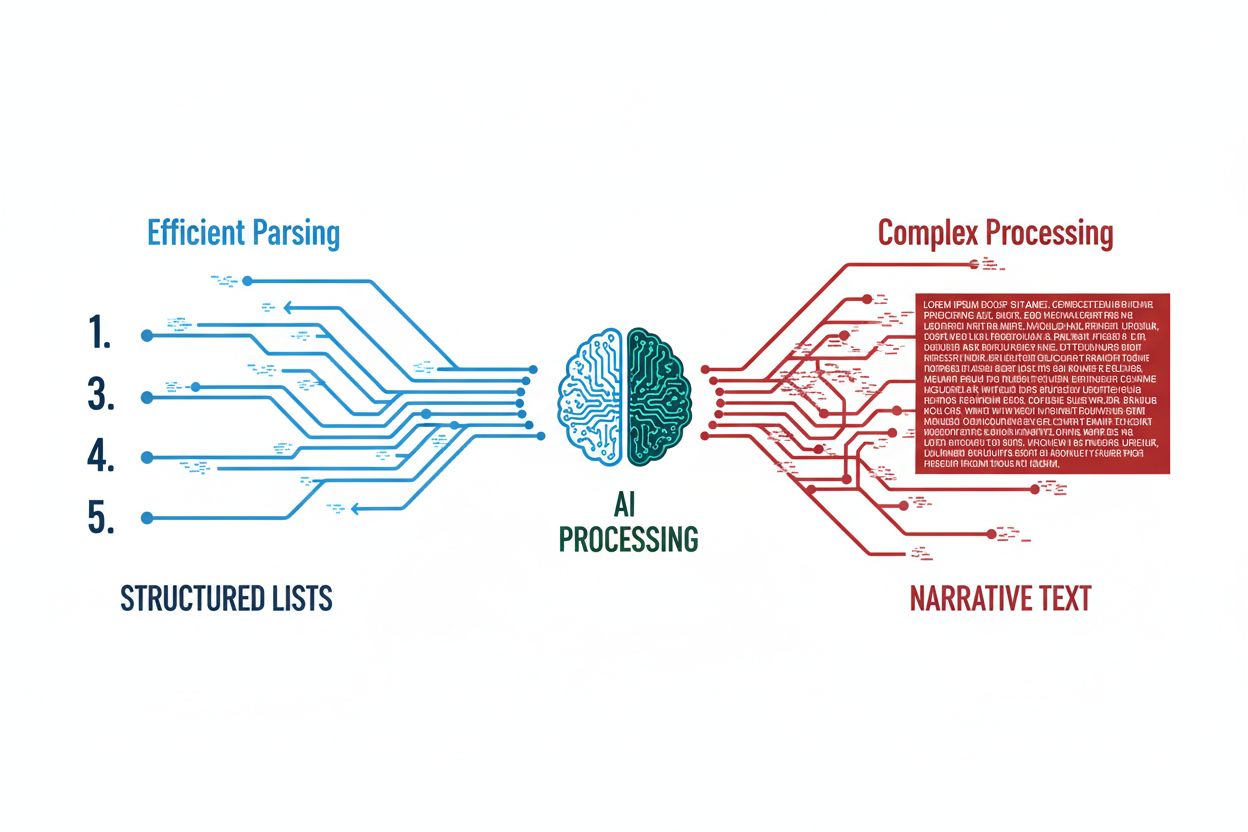
AI modely sú v podstate stroje na rozpoznávanie vzorcov, ktoré vynikajú v identifikovaní a spracovaní informácií organizovaných v predvídateľných, opakovateľných formátoch. Keď je obsah štruktúrovaný ako listikly, ponúka prehľadný, hierarchický formát, ktorý LLM dokáže analyzovať oveľa efektívnejšie ako naratívny text. Štruktúrovaný obsah znižuje výpočtovú náročnosť potrebnú na to, aby jazykové modely extrahovali, pochopili a citovali konkrétne informácie, pretože každá položka zoznamu funguje ako samostatná sémantická jednotka. Proces analýzy LLM je jednoduchší pri číslovaných alebo odrážkových zoznamoch, pretože model nemusí odvodzovať vzťahy medzi konceptami—sú jednoznačne zadefinované štruktúrou zoznamu. Táto efektivita sa priamo premieta do vyššej miery citácií, keďže AI systémy môžu s väčšou istotou extrahovať a odkazovať na jednotlivé položky bez potreby rozsiahleho kontextu z okolitých odsekov. Predvídateľná povaha formátov listiklov AI znamená, že modely míňajú menej tokenov na spracovanie štrukturálnej nejednoznačnosti a viac na skutočné porozumenie obsahu. V podstate, keď prezentujete informácie ako číslovaný zoznam, hovoríte „rodným jazykom“ veľkých jazykových modelov.
Ako rôzne AI platformy citujú zoznamy
Rôzne AI platformy vykazujú špecifické preferencie citácií, ktoré ukazujú, ako číslované zoznamy LLM systémy uprednostňujú objavovanie a overovanie obsahu. ChatGPT prejavuje silnú preferenciu encyklopedického obsahu, keďže 47,9 % jeho citácií pochádza z Wikipédie—platformy, ktorá výrazne využíva štruktúrovanú, na zoznamoch založenú informačnú architektúru. Gemini vykazuje vyváženejšie zdrojovanie, keď blogy tvoria 39 % a spravodajské zdroje 26 %, čo naznačuje preferenciu listiklov AI, ktoré kombinujú autoritatívnu štruktúru s aktuálnymi poznatkami. Perplexity AI, navrhnutý špeciálne pre výskumné dotazy, cituje blogový obsah v 38 % a správy v 23 %, pričom jasne preferuje odborné zoznamy kombinujúce hĺbku s prístupnosťou. Google AI Overviews uprednostňuje blogové články v 46 %, najmä tie so skenovateľnými, na zoznamoch založenými formátmi, ktoré zodpovedajú dôrazu platformy na rýchle získavanie informácií. Tieto vzorce AI citácií ukazujú, že platformy dôsledne odmeňujú tvorcov obsahu, ktorí štruktúrujú informácie ako AI zoznamové formáty namiesto hustých naratívnych odsekov. Porozumenie týmto preferenciám podľa platformy umožňuje obsahovým stratégiám prispôsobiť formáty listiklov pre maximalizáciu viditeľnosti naprieč viacerými AI systémami súčasne.
AI platforma
Primárny zdroj citácie
Percento
Preferencia obsahu
ChatGPT
Wikipedia
47,9 %
Encyklopedické, štruktúrované zoznamy
Gemini
Blogy
39 %
Vyvážené listikly s poznatkami
Perplexity
Blogy
38 %
Odborné zoznamy s hĺbkou
Google AI Overviews
Blogové články
46 %
Skenovateľné, zoznamové formáty
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Technický základ toho, prečo zoznamy fungujú tak dobre v AI systémoch, spočíva v sémantickom chunkingu a vektorových embeddingoch, matematických reprezentáciách, ktoré umožňujú jazykovým modelom rozumieť významu. Keď je obsah organizovaný ako zoznam, každá položka vytvára jasné sémantické hranice, vďaka ktorým môže embedding vrstva modelu jednoduchšie rozlišovať medzi samostatnými konceptmi a myšlienkami. Číslované sekvencie signalizujú hierarchiu a dôležitosť AI systémom spôsobom, ktorý naratívny text nedokáže, čím modely chápu, že položka č. 1 sa zásadne líši od položky č. 5 v poradí alebo postupnosti. Implementácia schema markup—najmä štruktúrovaných dát HowTo a FAQ—zvyšuje objaviteľnosť poskytnutím explicitných metadát, ktoré AI crawlery a indexery okamžite rozpoznajú a uprednostnia. Optimalizácia AI formátu zoznamu sa rozširuje aj na signály aktuálnosti, kde pravidelne aktualizované listikly vysielajú silnejšie signály sviežosti vyhľadávacím algoritmom než statický naratívny obsah. Vektorové databázy v moderných LLM dokážu efektívnejšie ukladať a vyhľadávať obsah zoznamov, pretože sémantická vzdialenosť medzi položkami zoznamu je konzistentnejšia a predvídateľnejšia než medzi odsekmi plynulého textu. Táto technická výhoda sa časom kumuluje, keďže AI systémy sa učia vážiť zdroje založené na zoznamoch vyššie vo svojich tréningových dátach a vyhľadávacích procesoch.
Listikly verzus naratívny obsah – porovnanie citácií
Výskumy dôsledne ukazujú, že formáty listiklov AI dostávajú o 20-30 % viac citácií od AI systémov v porovnaní s ekvivalentnými informáciami prezentovanými v naratívnej forme. Táto výhoda vyplýva zo zásadného rozdielu v tom, ako musia AI systémy spracovávať a získavať informácie z každého formátu: naratívny obsah vyžaduje od modelu náročnú extrakciu kontextu a inferenciu na identifikáciu citovateľných tvrdení, zatiaľ čo zoznamy prezentujú informácie ako vopred pripravené, samostatné jednotky. Číslované zoznamy LLM systémy môžu citovať konkrétne položky zoznamu bez potreby rozsiahleho okolitého kontextu, čo robí proces citácie rýchlejším a istejším pre AI model. Faktor použiteľnosti je kľúčový—keď AI systém narazí na dobre štruktúrovaný listikly, dokáže extrahovať a citovať jednotlivé položky samostatne, zatiaľ čo pri naratívnom obsahu často potrebuje citovať celé odseky alebo sekcie pre zachovanie kontextu. Dáta z viacerých AI monitorovacích platforiem ukazujú, že listikly dôsledne prekonávajú naratívny obsah v počte citácií, pozícii v AI odpovediach aj pravdepodobnosti výberu ako primárneho zdroja. Tento rozdiel ešte rastie pri porovnaní s dlhým naratívnym obsahom, keďže kognitívna záťaž na AI systémy pri analýze a citovaní hustého textu exponenciálne rastie. Pre tvorcov obsahu zameraných na AI viditeľnosť listiklov je dôkaz jasný: štruktúra vždy víťazí nad naratívom.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
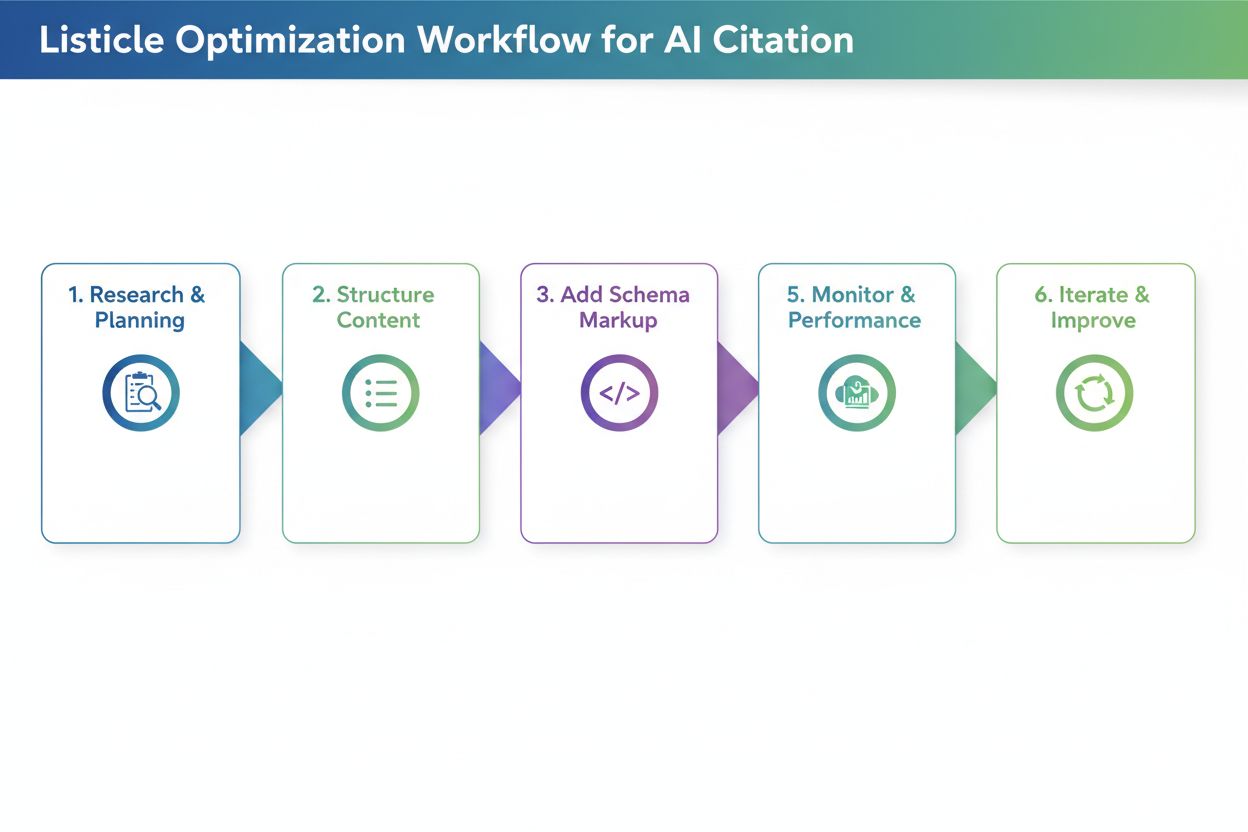
Najlepšie postupy pre AI-optimalizované listikly
Tvorba listiklov maximalizujúcich AI citácie vyžaduje dôraz na konkrétne štrukturálne a formátovacie prvky:
Používajte jasnú hierarchiu H2/H3, aby ste vytvorili sémantické vzťahy a pomohli AI systémom pochopiť organizáciu obsahu
Začnite priamou odpoveďou pomocou princípu BLUF (Bottom Line Up Front)—svoj hlavný bod uveďte hneď na začiatku
Zaraďte porovnávacie tabuľky v HTML formáte (nikdy ako obrázky), aby ste poskytli štruktúrované dáta, ktoré AI systémy môžu analyzovať a citovať
Pridajte schema markup prostredníctvom štruktúrovaných dát FAQ a HowTo, aby ste AI crawlerom výslovne signalizovali typ a štruktúru obsahu
Udržujte vyváženú hĺbku položiek—vyhnite sa tomu, aby jedna položka mala 500 slov a iné len 50, pretože nekonzistentnosť mätie AI pri analýze
Používajte číslované zoznamy pre postupný alebo zoradený obsah, kde záleží na poradí (Top 10, postupové návody, zoradené porovnania)
Používajte odrážky pre zoznamy vlastností a nepostupné informácie, kde poradie nie je dôležité
Aktualizujte štvrťročne kvôli sviežosti—AI systémy odmeňujú nedávno aktualizovaný AI formát zoznamu vyššou prioritou citácie
Reálne príklady AI-citovaných listiklov
Praktické príklady dokazujú silu dobre vypracovaných listiklov pri získavaní AI citácií naprieč platformami. Listikly typu „Top 5 AML Compliance Tools“ sa konzistentne objavujú v odpovediach Perplexity AI, pričom jednotlivé nástroje sú citované ako autoritatívne odporúčania v otázkach o dodržiavaní predpisov. Zoznamy „Najlepšie CRM alternatívy“ dominujú odpovediam ChatGPT, najmä pri požiadavkách na porovnania softvéru, pričom štruktúra listiklu umožňuje AI s istotou citovať konkrétne alternatívy. Porovnávacie listikly produktov sú dominantným formátom v Google AI Overviews, kde prehľadná štruktúra dokonale zodpovedá dôrazu platformy na rýchle, akčné informácie. Výskum MADX a tracking dáta Omnius ukazujú, že weby publikujúce dobre štruktúrované listikly zaznamenali nárast citácií o 40-60 % do 90 dní od zverejnenia. Analýza Tatareka o výkonnosti číslovaných zoznamov LLM odhalila, že listikly zamerané na „najlepšie v kategórii“ dostávajú 3,2x viac citácií ako naratívne recenzie tých istých produktov. Tieto skutočné príklady potvrdzujú, že AI listikly nie sú len teoreticky lepšie—prinášajú merateľné, kvantifikovateľné zlepšenia AI viditeľnosti a frekvencie citácií.
Ako štruktúrovať zoznamy pre maximálnu AI viditeľnosť
Maximalizovanie AI viditeľnosti si vyžaduje zámerný štrukturálny prístup, ktorý presahuje jednoduché číslovanie položiek. Začnite sekciou TL;DR na začiatku, ktorá zhrnie celý váš zoznam v 2–3 vetách, čím umožníte AI systémom okamžite pochopiť účel a rozsah obsahu. Vložte sekciu s vysvetlením kritérií, kde výslovne uvediete, prečo ste dané položky vybrali—táto transparentnosť pomáha AI pochopiť vašu metodológiu a zvyšuje dôveru v citáciu. Poskytnite vyvážené pokrytie každej položky zoznamu, aby každá mala primeranú hĺbku a analýzu, bez uprednostňovania. Kľúčové je uviesť silné stránky aj obmedzenia každej položky, keďže AI systémy oceňujú vyváženú a nuansovanú analýzu nad jednostranným promočným obsahom. Pridajte sekciu s rozpisom cien, ak je to relevantné, pretože tieto štruktúrované dáta sú vysoko citovateľné a často sa objavujú v AI odpovediach pri porovnaní produktov. Implementujte porovnávaciu tabuľku v HTML formáte (nie screenshoty/obrázky), aby AI systémy mohli priamo analyzovať a citovať konkrétne porovnania vlastností. Zaradte FAQ sekciu odpovedajúcu na časté otázky o položkách zoznamu, čím AI systémom poskytnete ďalšie štruktúrované dáta na indexovanie a citovanie. Na záver pridajte jasné ďalšie kroky a CTA, ktoré používateľov navigujú k akcii a signalizujú AI systémom, že váš obsah je komplexný a akčný.
Úloha číslovaných zoznamov verzus odrážky v AI citáciách
Výber medzi číslovanými zoznamami a odrážkami má zásadný vplyv na to, ako AI systémy spracúvajú a citujú váš obsah. Číslované zoznamy signalizujú postupnosť a poradie, čo je dôvod, prečo dominujú „Top X“ listiklom a návodom krok za krokom—AI systémy vnímajú číslovanie ako explicitnú hierarchiu vyjadrujúcu dôležitosť alebo poradí. Odrážky lepšie fungujú pre nepostupné informácie, napríklad zoznamy vlastností alebo porovnania atribútov, kde neexistuje prirodzené poradie. Výskumy ukazujú, že AI systémy považujú číslované zoznamy za autoritatívnejšie a vhodnejšie na citovanie, najmä v odpovediach na dotazy, ktoré explicitne žiadajú zoradené alebo postupné informácie. Keď používatelia požiadajú ChatGPT alebo Gemini „Aké sú top 5 nástrojov na X?“, AI systém uprednostňuje citácie zo zdrojov číslovaných zoznamov LLM, pretože číslovanie poskytuje jasné potvrdenie poradia. Naopak, odrážky vynikajú v kontexte porovnávania vlastností, kde AI potrebuje extrahovať a citovať konkrétne atribúty bez hierarchie. Kombinovanie číslovaných zoznamov a odrážok v jednom listikli vytvára pre AI systémy zmätok pri analýze, preto si zachovajte konzistentný formát pre maximálnu optimalizáciu AI formátu zoznamu.
Meranie výkonnosti listiklov vo vyhľadávaní AI
Sledovanie výkonnosti listiklov vyžaduje systematický monitoring naprieč viacerými AI platformami a nástrojmi. AtomicAGI, Writesonic a sledovacie nástroje Perplexity umožňujú automatizovane sledovať, ako často sa váš AI listikly obsah objavuje v AI-generovaných odpovediach. Manuálne testovanie v ChatGPT, Gemini a Perplexity zostáva nevyhnutné, keďže automatizované nástroje občas prehliadnu nuansované vzorce citácií alebo špecifické správanie platforiem. Stanovte si základné metriky sledovaním frekvencie a pozície citácií—sledujte nielen to, či je váš listikly citovaný, ale aj kde sa objavuje v AI odpovedi a ako často je vybraný ako hlavný zdroj. Sledujte, ktoré položky zoznamu sú najčastejšie citované, keďže to odhalí, ktoré odporúčania alebo poznatky najviac rezonujú s AI systémami a používateľskými otázkami. Merajte návštevnosť z AI zdrojov oddelene od tradičnej organickej návštevnosti, keďže AI návštevy často vykazujú iné konverzné vzorce a zámer než organické vyhľadávanie. Porovnávajte výkonnosť pred a po optimalizácii, pričom implementujte jednu štrukturálnu zmenu naraz, aby ste vedeli identifikovať, ktoré úpravy prispeli k nárastu citácií. Určte si mesačný monitorovací rytmus, aby ste identifikovali trendy a sezónne vzorce v tom, ako si váš číslovaný zoznam LLM vedie naprieč rôznymi AI platformami a typmi dotazov.
Bežné chyby listiklov, ktoré škodia AI viditeľnosti
Aj dobre mienené listikly môžu zlyhať v dosiahnutí optimálnych AI citácií, ak obsahujú štrukturálne alebo obsahové chyby, ktoré mätú AI pri analýze. Tendenčné zoznamy, ktoré uprednostňujú váš produkt/službu pred konkurenciou, signalizujú AI systémom nízku dôveryhodnosť, pričom tie čoraz viac penalizujú zjavne promočný obsah v prospech vyvážených odporúčaní. Nekonzistentná hĺbka položiek—keď niektoré položky dostanú 200 slov analýzy a iné 50—vyvoláva zmätok pri analýze a naznačuje AI systémom nedostatočný výskum. Chýbajúce porovnávacie tabuľky predstavujú výrazne premrhanú príležitosť, keďže AI systémy výrazne uprednostňujú štruktúrované dáta a radšej citujú tabuľky než slovné popisy. Žiadny schema markup znamená, že nútite AI systémy odvodiť štruktúru vášho obsahu namiesto explicitného vyhlásenia, čím znižujete dôveru v citáciu aj objaviteľnosť. Zastaralé informácie sú pre listikly obzvlášť škodlivé, keďže AI systémy rozpoznajú a penalizujú starý obsah, najmä v rýchlo sa meniacich kategóriách ako softvérové nástroje či požiadavky na súlad. Zlá štruktúra a hierarchia s nejasnými H2/H3 vzťahmi sťažuje AI systémom analýzu sémantických vzťahov medzi položkami. Nakoniec, prílišné zahltenie kľúčovými slovami a príliš dlhé zoznamy (50+ položiek) oslabujú autoritu aj zameranie listiklu, čo spôsobuje, že AI systémy ho vnímajú ako menej autoritatívny než zamerané, kvalitne kurátorované alternatívy.
Najčastejšie kladené otázky
Prečo AI modely preferujú listikly pred naratívnym obsahom?
AI modely sú stroje na rozpoznávanie vzorcov, ktoré spracúvajú štruktúrované, ľahko prehľadné formáty efektívnejšie ako hustý naratívny text. Listikly znižujú výpočtovú komplexnosť prezentovaním informácií ako samostatných sémantických jednotiek, čo umožňuje LLM jednoduchšie analyzovať, extrahovať a citovať konkrétne položky s väčšou istotou a rýchlosťou.
Aký je rozdiel medzi číslovanými zoznamami a odrážkami pre AI citáciu?
Číslované zoznamy signalizujú postupnosť a poradie, vďaka čomu sú ideálne pre 'Top X' listikly a návody krok za krokom. Odrážky sú vhodnejšie pre nepostupné informácie, napríklad porovnanie funkcií. AI systémy považujú číslované zoznamy za autoritatívnejšie pre dotazy s poradím, kým odrážky vynikajú v kontextoch porovnávania vlastností.
Ako často by som mal aktualizovať listikly pre AI viditeľnosť?
Aktualizujte svoje listikly minimálne štvrťročne, aby ste si udržali silné signály aktuálnosti. AI systémy odmeňujú nedávno aktualizovaný obsah vyššou prioritou citácie. Aj drobné úpravy—pridanie nových údajov, obnovenie štatistík či rozšírenie sekcií—pomáhajú udržať nárok na citáciu aj viditeľnosť.
Naozaj schéma markup zlepšuje AI citácie?
Áno, schéma markup výrazne zlepšuje objaviteľnosť pre AI. Štruktúrované dáta FAQ a HowTo môžu zvýšiť pravdepodobnosť citácie až o 10 %. Schéma markup poskytuje explicitné metadáta, ktoré AI crawlery okamžite rozpoznajú a uprednostnia, vďaka čomu je váš obsah jednoduchšie indexovať a citovať.
Môžem používať listikly pre všetky typy obsahu?
Listikly výborne fungujú pri porovnaniach, rebríčkoch, návodoch a odporúčaniach. Menej vhodné sú však pre naratívne rozprávanie, hĺbkové analýzy alebo koncepčné vysvetlenia. Zvoľte formát listiklu, keď sa váš obsah prirodzene rozdeľuje na samostatné, porovnateľné položky.
Ako zistím, či sú moje listikly citované AI?
Použite nástroje ako AtomicAGI, Writesonic alebo sledovanie Perplexity pre automatizované monitorovanie. Manuálne testujte relevantné dotazy v ChatGPT, Gemini a Perplexity, aby ste sledovali frekvenciu citácií a ich pozíciu. Sledujte, ktoré konkrétne položky zoznamu sú najčastejšie citované a merajte návštevnosť z AI zdrojov oddelene od organického vyhľadávania.
Aká je ideálna dĺžka listiklu pre AI citácie?
Kvalita je dôležitejšia ako kvantita. Zamerajte sa na 5-10 dobre preskúmaných položiek namiesto zoznamov s 50+ položkami. Každá položka by mala mať vyváženú, primeranú hĺbku (150-300 slov). Príliš dlhé zoznamy oslabujú autoritu a mätú AI pri analýze, zatiaľ čo zamerané, kurátorované listikly dosahujú podstatne lepšie výsledky.
Mám zaradiť svoj vlastný produkt do porovnávacích listiklov?
Áno, ale zachovajte transparentnosť a vyváženosť. Uveďte svoj produkt spolu s konkurenciou, poskytnite čestné silné stránky aj obmedzenia a zabezpečte rovnakú hĺbku popisu. Tendenčné zoznamy, ktoré uprednostňujú váš produkt, signalizujú AI systémom nízku dôveryhodnosť, pričom tie čoraz viac penalizujú zjavne promočný obsah.
Sledujte AI viditeľnosť vašej značky
Sledujte, ako často je váš obsah citovaný ChatGPT, Gemini a Perplexity pomocou AI monitorovacej platformy AmICited. Získajte prehľad o vašej AI prítomnosti v reálnom čase.
Preferujú AI vyhľadávače listikly? Kompletný sprievodca AI-optimalizovaným obsahom
Zistite, či AI vyhľadávače ako ChatGPT a Perplexity preferujú listikly. Naučte sa, ako optimalizovať obsah vo forme zoznamov pre AI citácie a viditeľnosť....
Zistite, čo je optimalizácia listiklov a ako štruktúrovať číslované a odrážkové zoznamy na AI extrakciu. Objavte osvedčené postupy na zlepšenie viditeľnosti vo ...
Testovanie formátov obsahu pre AI citácie: Návrh experimentu
Zistite, ako testovať formáty obsahu pre AI citácie pomocou A/B testovania. Objavte, ktoré formáty zabezpečujú najvyššiu viditeľnosť a mieru citácií v ChatGPT, ...
10 min čítania
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.