
NoAI Meta Tag
Zistite, čo sú NoAI meta tagy, ako fungujú pri prevencii AI scrapovania, metódy implementácie a ich účinnosť pri ochrane vášho obsahu pred neoprávneným trénovan...
6 min čítania

Zistite, ako implementovať noai a noimageai meta tagy na kontrolu prístupu AI robotov k obsahu vašej webstránky. Kompletný sprievodca hlavičkami na kontrolu AI prístupu a metódam implementácie.
Webové roboty sú automatizované programy, ktoré systematicky prechádzajú internet a zbierajú informácie z webových stránok. Historicky ich prevádzkovali hlavne vyhľadávače ako Google, ktorého Googlebot prechádzal stránky, indexoval obsah a späť cez výsledky vyhľadávania posielal užívateľov na weby – vytvárali tak obojstranne výhodný vzťah. S príchodom AI robotov sa však táto dynamika zásadne zmenila. Na rozdiel od tradičných vyhľadávacích robotov, ktoré za prístup k obsahu prinášajú návštevnosť, trénovacie AI roboty zbierajú obrovské množstvá webového obsahu na vytváranie datasetov pre veľké jazykové modely, často bez toho, aby prinášali späť akúkoľvek návštevnosť vydavateľom. Tento posun robí meta tagy – malé HTML smernice, ktoré komunikujú pokyny robotom – čoraz dôležitejšími pre tvorcov obsahu, ktorí chcú mať kontrolu nad tým, ako ich dielo využívajú systémy umelej inteligencie.
noai a noimageai meta tagy sú smernice vytvorené komunitou DeviantArt v roku 2022 na pomoc tvorcom obsahu, ktorí chcú zabrániť použitiu svojich diel na trénovanie AI generátorov obrázkov. Tieto tagy fungujú podobne ako dlhodobo zaužívaný noindex tag, ktorý hovorí vyhľadávačom, aby stránku neindexovali. noai signalizuje, že žiadny obsah na stránke nemá byť použitý na trénovanie AI, kým noimageai špecificky zabraňuje použitiu obrázkov na trénovanie AI modelov. Tieto tagy môžete vložiť do sekcie head vášho HTML v tomto tvare:
<!-- Zablokujte všetok obsah pred trénovaním AI -->
<meta name="robots" content="noai">
<!-- Zablokujte len obrázky pred trénovaním AI -->
<meta name="robots" content="noimageai">
<!-- Zablokujte obsah aj obrázky -->
<meta name="robots" content="noai, noimageai">
Tu je porovnávacia tabuľka rôznych meta tag smerníc a ich účelu:
| Smernica | Účel | Syntax | Rozsah |
|---|---|---|---|
| noai | Zabráni použitiu všetkého obsahu na trénovanie AI | content="noai" | Celý obsah stránky |
| noimageai | Zabráni použitiu obrázkov na trénovanie AI | content="noimageai" | Len obrázky |
| noindex | Zabraňuje indexovaniu vo vyhľadávačoch | content="noindex" | Výsledky vyhľadávania |
| nofollow | Zabraňuje sledovaniu odkazov | content="nofollow" | Odchádzajúce odkazy |
Zatiaľ čo meta tagy sa vkladajú priamo do vášho HTML, HTTP hlavičky poskytujú alternatívny spôsob komunikácie s robotmi na úrovni servera. X-Robots-Tag hlavička môže obsahovať tie isté smernice ako meta tagy, ale funguje inak – odosiela sa v HTTP odpovedi ešte predtým, než sa stránka načíta. Tento prístup je obzvlášť užitočný na kontrolu prístupu k ne-HTML súborom ako PDF, obrázky či videá, kde nie je možné vložiť HTML meta tagy.
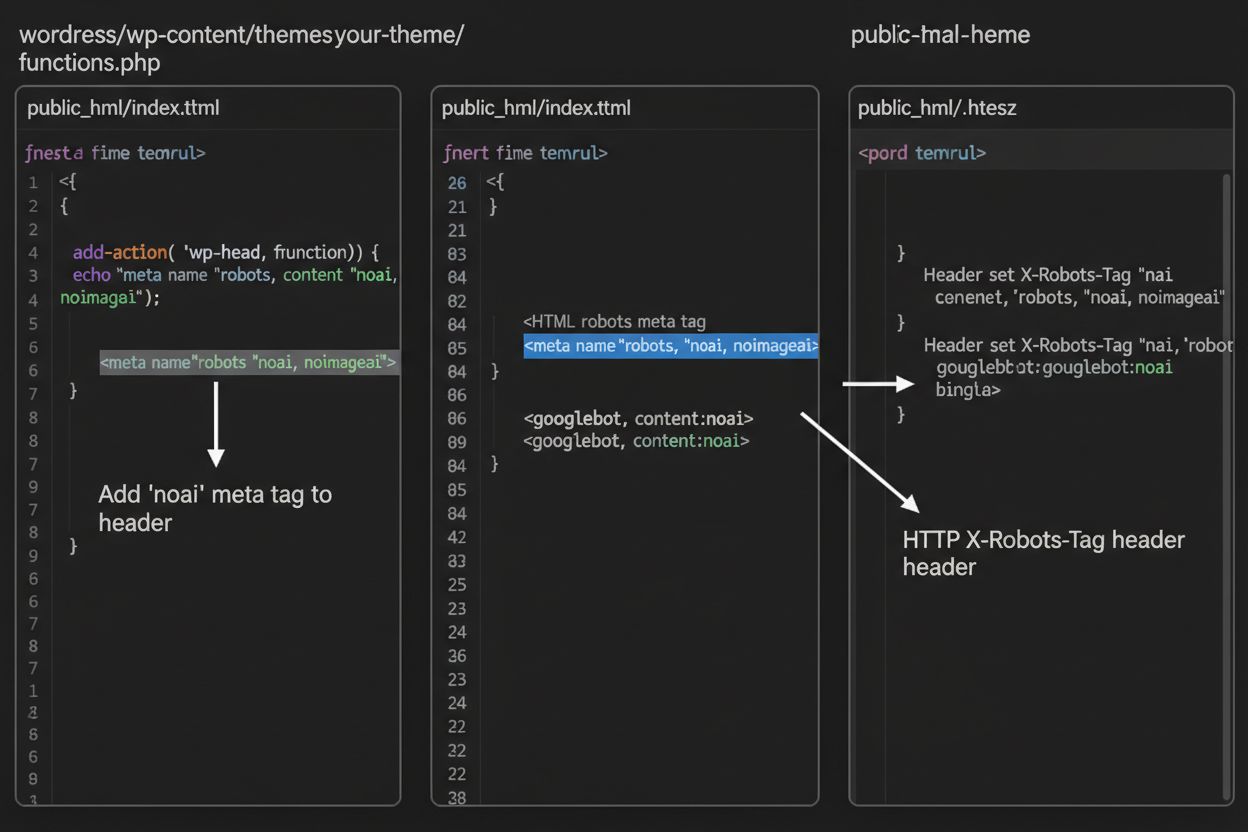
Pre Apache servery môžete nastaviť X-Robots-Tag hlavičky v súbore .htaccess:
<IfModule mod_headers.c>
Header set X-Robots-Tag "noai, noimageai"
</IfModule>
Pre NGINX servery pridajte hlavičku do konfigurácie servera:
location / {
add_header X-Robots-Tag "noai, noimageai";
}
Hlavičky poskytujú globálnu ochranu naprieč celou stránkou či konkrétnymi adresármi, vďaka čomu sú ideálne pre komplexné stratégie kontroly prístupu AI.
Účinnosť noai a noimageai tagov závisí výlučne od toho, či ich roboty rešpektujú. Dobre sa správajúce roboty od veľkých AI spoločností tieto smernice zvyčajne rešpektujú:
Naopak, zle nastavené alebo škodlivé roboty môžu tieto smernice cielene ignorovať, pretože neexistuje mechanizmus na ich vynútenie. Na rozdiel od robots.txt, ktorý vyhľadávače uznávajú ako priemyselný štandard, noai nie je oficiálnym webovým štandardom a roboty nemajú povinnosť ho dodržiavať. Preto bezpečnostní experti odporúčajú viacvrstvový prístup kombinujúci viacero ochranných metód namiesto spoliehania sa len na meta tagy.
Implementácia noai a noimageai tagov sa líši v závislosti od platformy. Tu je postup pre najbežnejšie platformy:
1. WordPress (cez functions.php) Pridajte tento kód do súboru functions.php vašej detskej témy:
function add_noai_meta_tag() {
echo '<meta name="robots" content="noai, noimageai">' . "\n";
}
add_action('wp_head', 'add_noai_meta_tag');
2. Statické HTML stránky
Vložte priamo do sekcie <head> vášho HTML:
<head>
<meta name="robots" content="noai, noimageai">
</head>
3. Squarespace Prejdite do Nastavenia > Pokročilé > Code Injection a vložte do sekcie Header:
<meta name="robots" content="noai, noimageai">
4. Wix Choďte do Nastavenia > Vlastný kód, kliknite na “Pridať vlastný kód”, vložte meta tag, vyberte “Head” a použite na všetky stránky.
Každá platforma ponúka inú úroveň kontroly – WordPress umožňuje stránkovú implementáciu cez pluginy, zatiaľ čo Squarespace a Wix poskytujú globálne možnosti pre celý web. Vyberte si spôsob, ktorý najlepšie vyhovuje vašim technickým zručnostiam a potrebám.
Noai a noimageai tagy sú dôležitým krokom v ochrane tvorcov obsahu, no majú významné obmedzenia. Po prvé, nejde o oficiálne webové štandardy – vytvorila ich komunita DeviantArt, takže neexistuje žiadna formálna špecifikácia ani mechanizmus na vynútenie. Po druhé, dodržiavanie je úplne dobrovoľné. Dobre sa správajúce roboty veľkých spoločností smernice rešpektujú, no zle nastavené roboty a scrapery ich môžu ignorovať bez následkov. Po tretie, nedostatok štandardizácie znamená rôznu úroveň adopcie. Niektoré menšie AI firmy a výskumníci o týchto smerniciach ani nemusia vedieť, nieto ich ešte podporovať. Napokon, samy meta tagy nemôžu zabrániť odhodlaným útočníkom v scrapovaní vášho obsahu. Škodlivý robot môže vaše smernice úplne ignorovať, preto sú ďalšie vrstvy ochrany nevyhnutné pre komplexnú bezpečnosť obsahu.
Najefektívnejšia stratégia kontroly prístupu AI využíva viacero vrstiev ochrany namiesto spoliehania sa na jedinú metódu. Tu je porovnanie rôznych prístupov:
| Metóda | Rozsah | Účinnosť | Náročnosť |
|---|---|---|---|
| Meta tagy (noai) | Úroveň stránky | Stredná (dobrovoľná) | Ľahká |
| robots.txt | Celý web | Stredná (len odporúčanie) | Ľahká |
| X-Robots-Tag hlavičky | Úroveň servera | Stredne vysoká (pre všetky typy súborov) | Stredná |
| Pravidlá firewallu | Sieťová úroveň | Vysoká (blokuje na infraštruktúre) | Ťažká |
| IP allowlisting | Sieťová úroveň | Veľmi vysoká (len overené zdroje) | Ťažká |
Komplexná stratégia môže zahŕňať: (1) implementáciu noai meta tagov na všetky stránky, (2) pridanie pravidiel do robots.txt na blokovanie známych AI trénovacích robotov, (3) nastavenie X-Robots-Tag hlavičiek na serveri pre ne-HTML súbory a (4) monitoring serverových logov na odhalenie robotov ignorujúcich vaše smernice. Tento viacvrstvový prístup významne sťažuje prácu zlomyseľným robotom a zároveň zostáva kompatibilný s tými, ktorí vaše preferencie rešpektujú.
Po implementácii noai tagov a ďalších smerníc by ste si mali overiť, či roboty naozaj rešpektujú vaše pravidlá. Najpriamejšou metódou je kontrola serverových access logov na aktivitu robotov. Na Apache serveroch môžete vyhľadať konkrétnych robotov takto:
grep "GPTBot\|ClaudeBot\|PerplexityBot" /var/log/apache2/access.log
Ak vidíte požiadavky od robotov, ktorých ste blokovali, znamená to, že vaše smernice ignorujú. Na NGINX serveroch kontrolujte /var/log/nginx/access.log rovnakým grep príkazom. Navyše nástroje ako Cloudflare Radar poskytujú prehľad o AI robotickej návštevnosti vašej stránky, ukazujú najaktívnejšie boty a vývoj ich správania v čase. Pravidelný monitoring logov – aspoň raz mesačne – vám pomôže identifikovať nové roboty a overiť, že vaše opatrenia fungujú správne.
Aktuálne existujú noai a noimageai v šedej zóne: sú široko uznávané a rešpektované hlavnými AI spoločnosťami, no stále nie sú oficiálne a štandardizované. Rýchlo však rastie tlak na formálnu štandardizáciu. W3C (World Wide Web Consortium) a rôzne priemyselné skupiny diskutujú o vytvorení oficiálnych štandardov na kontrolu prístupu AI, ktoré by týmto smerniciach dali rovnakú váhu ako zavedené štandardy typu robots.txt. Ak sa noai stane oficiálnym webovým štandardom, očakávaním bude dodržiavanie, nie len dobrovoľnosť, čo výrazne zvýši jeho účinnosť. Tento štandardizačný proces odráža celkový posun v pohľade technologického sektora na práva tvorcov obsahu a rovnováhu medzi rozvojom AI a ochranou vydavateľov. Ako bude rásť počet vydavateľov využívajúcich tieto tagy a požadujúcich silnejšiu ochranu, zvýši sa aj pravdepodobnosť ich oficiálnej štandardizácie – čím sa kontrola AI prístupu stane rovnako dôležitou pre správu webu, ako sú pravidlá indexovania pre vyhľadávače.
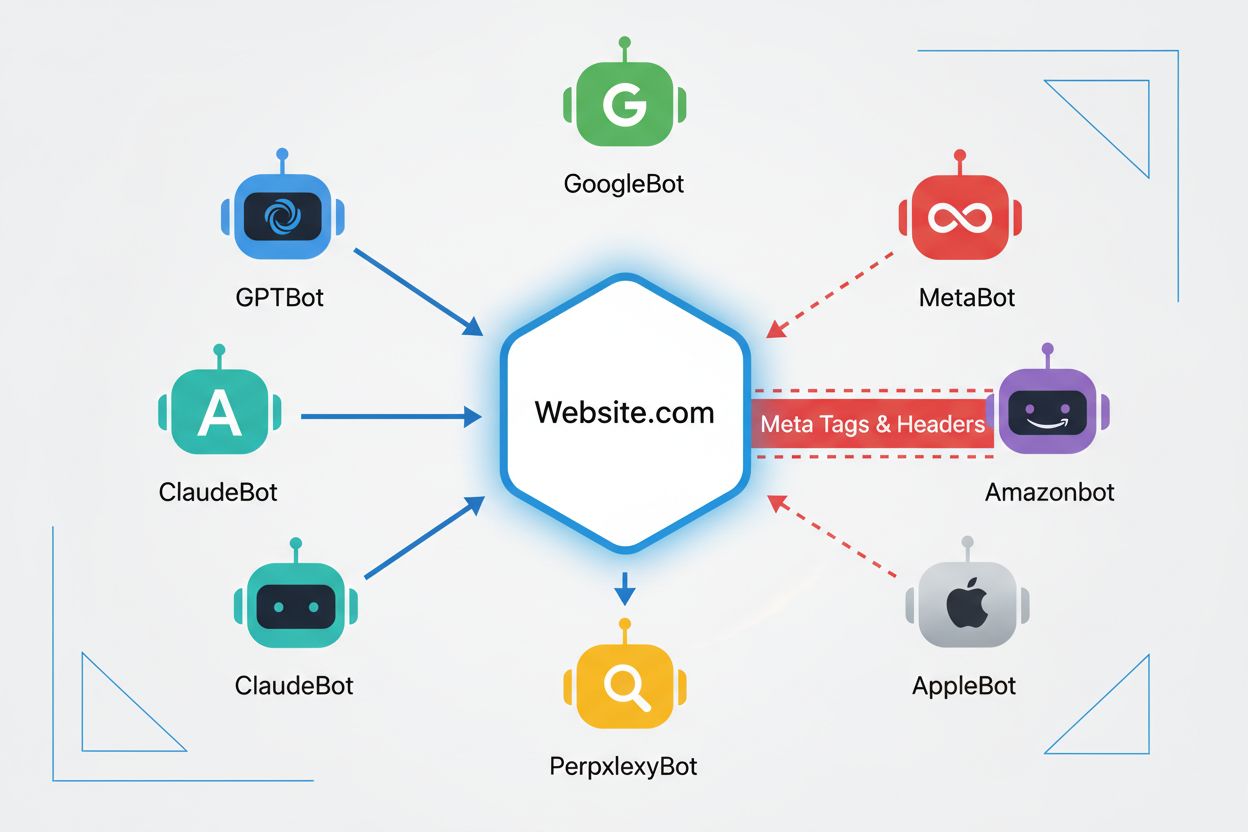
Noai meta tag je smernica umiestnená v sekcii head vášho webu, ktorá signalizuje AI robotom, že váš obsah by nemal byť použitý na trénovanie modelov umelej inteligencie. Funguje tak, že komunikuje vaše preferencie dobre sa správajúcim AI botom, hoci nejde o oficiálny webový štandard a niektoré roboty ju môžu ignorovať.
Nie, noai a noimageai nie sú oficiálnymi webovými štandardmi. Vytvorila ich komunita DeviantArt ako iniciatívu na ochranu tvorcov pred využívaním ich diela na trénovanie AI. Avšak veľké AI spoločnosti, ako OpenAI, Anthropic a ďalšie, už začali tieto smernice rešpektovať vo svojich robotoch.
Hlavné AI roboty vrátane GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) a ďalšie rešpektujú noai smernicu. Niektoré menšie alebo nevhodne nastavené roboty ju však môžu ignorovať, preto sa odporúča viacvrstvová ochrana.
Meta tagy sú umiestnené v sekcii head vášho HTML a platia pre jednotlivé stránky, zatiaľ čo HTTP hlavičky (X-Robots-Tag) sa nastavujú na úrovni servera a môžu platiť globálne alebo pre konkrétne typy súborov. Hlavičky fungujú aj pre ne-HTML súbory ako PDF a obrázky, vďaka čomu sú univerzálnejšie pre komplexnú ochranu.
Áno, noai tagy môžete implementovať na WordPresse viacerými spôsobmi: pridaním kódu do súboru functions.php vašej témy, použitím pluginu ako WPCode alebo cez nástroje na tvorbu stránok ako Divi a Elementor. Najbežnejšia je metóda functions.php, kde jednoduchým hookom vložíte meta tag do hlavičky stránky.
To záleží na vašich obchodných cieľoch. Blokovanie trénovacích robotov chráni váš obsah pred využitím pri vývoji AI modelov. Naopak, blokovanie vyhľadávacích robotov ako OAI-SearchBot môže znížiť vašu viditeľnosť vo vyhľadávaní a AI platformách. Mnohí vydavatelia preto volia selektívny prístup – blokujú trénovacie roboty, ale ponechávajú prístup vyhľadávacím.
Môžete skontrolovať serverové logy na aktivitu robotov napríklad príkazom grep, kde vyhľadáte konkrétne užívateľské agenty botov. Nástroje ako Cloudflare Radar poskytujú prehľad o AI robotickej návštevnosti. Pravidelne sledujte logy a zistíte, či blokované roboty stále pristupujú k vášmu obsahu – v tom prípade ignorujú vaše smernice.
Ak roboty ignorujú vaše meta tagy, implementujte ďalšie úrovne ochrany vrátane pravidiel v robots.txt, X-Robots-Tag HTTP hlavičiek a blokovania na úrovni servera cez .htaccess alebo firewall. Pre silnejšie overenie použite IP allowlisting a povoľte prístup len z overených IP adries robotov zverejnených veľkými AI spoločnosťami.
Použite AmICited na sledovanie, ako AI systémy ako ChatGPT, Perplexity a Google AI Overviews citujú a odkazujú na váš obsah na rôznych AI platformách.
Zistite, čo sú NoAI meta tagy, ako fungujú pri prevencii AI scrapovania, metódy implementácie a ich účinnosť pri ochrane vášho obsahu pred neoprávneným trénovan...

Zistite, čo je meta tag noai, ako zabraňuje zbieraniu dát pre AI tréning, aké má obmedzenia a ako ho implementovať na svoj web na ochranu obsahu pred generatívn...
Objavte, ako sa meta tagy vyvíjali pre vyhľadávanie poháňané AI. Zistite, ktoré meta tagy sú najdôležitejšie pre AI optimalizáciu, viditeľnosť v AI Prehľadoch a...