
Diferencovaný prístup prehliadačov (crawlerov)
Zistite, ako selektívne povoliť alebo blokovať AI crawlerov podľa obchodných cieľov. Implementujte diferencovaný prístup crawlerov na ochranu obsahu a zároveň u...
8 min čítania

Zistite, ako používať robots.txt na kontrolu, ktoré AI boty majú prístup k vášmu obsahu. Kompletný sprievodca blokovaním GPTBot, ClaudeBot a ďalších AI crawlerov s praktickými príkladmi a konfiguračnými stratégiami.
Krajina webového crawlingu sa za posledné dva roky zásadne zmenila – posunula sa od známeho územia indexácie vyhľadávačmi do zložitého sveta tréningu AI modelov. Zatiaľ čo Googlebot od Google bol dlhodobo predvídateľnou návštevou stránok vydavateľov, nová generácia crawlerov prichádza s dramaticky odlišnými zámermi a vzorcami spotreby obsahu. GPTBot od OpenAI má pomer crawl-to-refer približne 1 700 : 1, teda prejde 1 700 stránok, aby vygeneroval len jednu návštevu späť na váš web, pričom ClaudeBot od Anthropic pracuje s extrémnejším pomerom 73 000 : 1 – čo je v ostrom kontraste s pomerom Google 14 : 1, kde crawling znamená reálny prínos pre návštevnosť. Tento zásadný rozdiel vytvára pre tvorcov obsahu urgentné obchodné rozhodnutie: ak týmto botom povolíte neobmedzený prístup, váš obsah trénuje AI modely, ktoré konkurujú vašej návštevnosti a príjmom, pričom späť dostávate len minimálnu kompenzáciu alebo návštevnosť. Vydavatelia sa musia aktívne rozhodnúť, či je pre nich prínos AI botov v rámci ich obchodného modelu dostatočný – konfigurácia robots.txt sa tak stáva nielen technickou, ale najmä strategickou obchodnou otázkou.
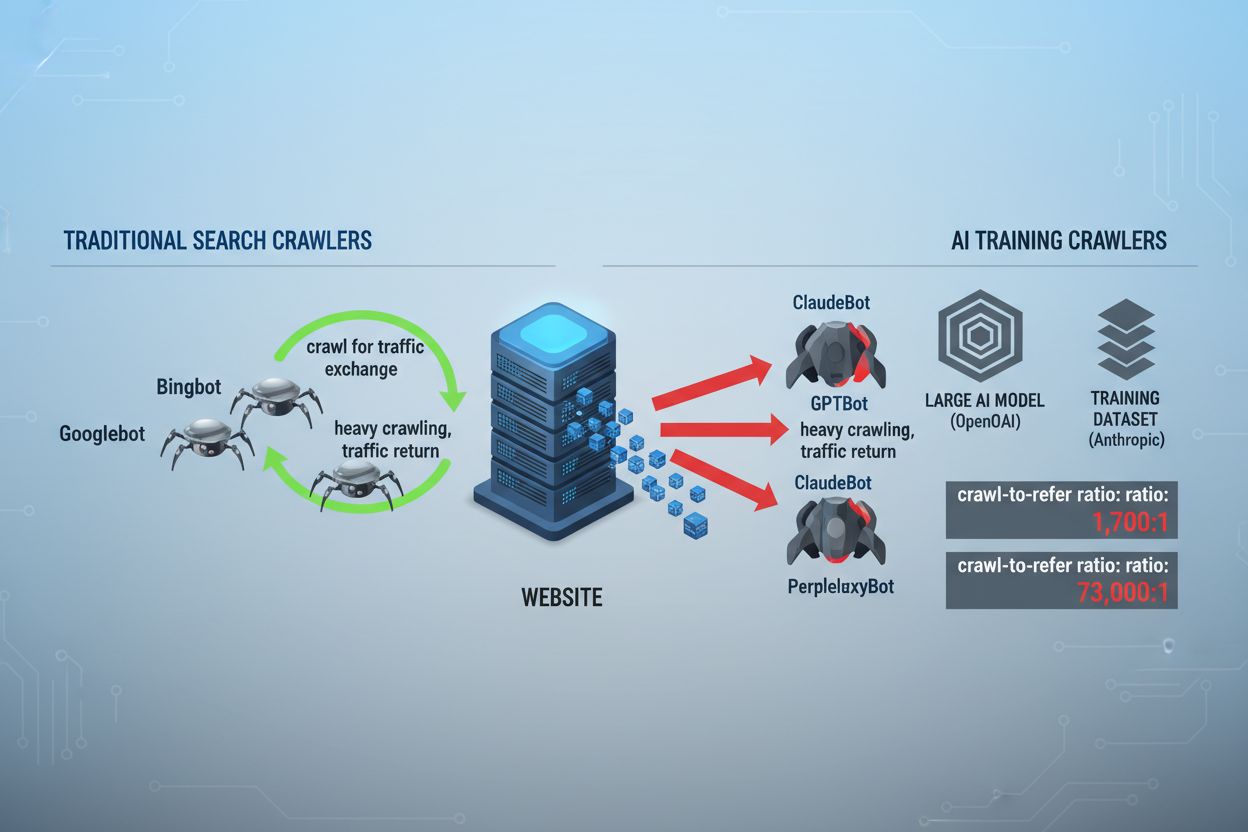
AI crawlery fungujú v troch odlišných kategóriách, z ktorých každá má iný účel a vyžaduje inú blokovaciu stratégiu. Tréningové crawlery sú určené na spracovanie veľkého objemu obsahu pre tréning základných AI modelov – patria sem GPTBot od OpenAI, ClaudeBot od Anthropic, Google-Extended od Google, PerplexityBot od Perplexity, Meta-ExternalAgent od Meta, Applebot-Extended od Apple a noví hráči ako Amazonbot, Bytespider či cohere-ai. Vyhľadávacie crawlery, naopak, poháňajú AI vyhľadávače a typicky vracajú návštevnosť vydavateľom; patria sem OAI-SearchBot od OpenAI, Claude-Web od Anthropic a vyhľadávacia funkcionalita Perplexity. Tretia kategória sú agenti spúšťaní používateľom, ktorí pristupujú k obsahu na požiadanie, napr. ChatGPT-User alebo Claude-Web priame interakcie spustené koncovým používateľom. Pochopenie tejto taxonómie je kľúčové, pretože vaša blokovacia stratégia by mala odrážať vaše obchodné priority – môžete privítať vyhľadávacie crawlery, ktoré prinášajú návštevnosť, no blokovať tréningové crawlery, ktoré spotrebúvajú obsah bez kompenzácie. Každá veľká AI spoločnosť má vlastnú flotilu špecializovaných crawlerov a rozdiel medzi nimi často spočíva práve v konkrétnom reťazci user agent, ktorý používajú – preto je presná identifikácia a cielené blokovanie nevyhnutné pre efektívnu konfiguráciu robots.txt.
| Spoločnosť | Tréningový crawler | Vyhľadávací crawler | Agent spustený používateľom |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (používa štandardný Googlebot) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Udržiavanie presného, aktuálneho zoznamu user agentov AI botov je základom efektívnej konfigurácie robots.txt, hoci toto prostredie sa rýchlo mení s príchodom nových modelov a úpravami stratégií crawlovania. Medzi hlavné tréningové crawlery, ktoré by ste mali poznať, patria GPTBot (hlavný tréningový crawler OpenAI), ClaudeBot (tréningový crawler Anthropic), anthropic-ai (alternatívny identifikátor Anthropic), Google-Extended (AI tréningový token Google), PerplexityBot (crawler Perplexity), Meta-ExternalAgent (tréningový crawler Meta), Applebot-Extended (AI variant Apple), CCBot (Common Crawl bot), Amazonbot (crawler Amazonu), Bytespider (crawler ByteDance), cohere-ai (tréningový bot Cohere), DuckAssistBot (AI asistent crawler DuckDuckGo) a YouBot (crawler You.com). Na vyhľadávanie zamerané crawlery, ktoré typicky prinášajú návštevnosť, zahŕňajú OAI-SearchBot, Claude-Web a PerplexityBot v režime vyhľadávania. Kľúčovým problémom je, že tento zoznam nie je statický – nové AI spoločnosti sa objavujú pravidelne, existujúce predstavujú nové crawlery pre nové produkty a user agent reťazce sa občas menia alebo rozširujú. Vydavatelia by mali na svoju robots.txt konfiguráciu pozerať ako na živý dokument, ktorý si vyžaduje minimálne štvrťročnú revíziu a aktualizáciu – ideálne je sledovať odvetvové monitorovacie zdroje alebo analyzovať serverové logy na výskyt neznámych user agentov, ktoré môžu signalizovať nové AI crawlery na vašom webe. Ak neudržiavate aktuálny zoznam user agentov, hrozí, že omylom povolíte nové tréningové crawlery, ktoré ste chceli blokovať, alebo naopak zablokujete legitímne vyhľadávacie crawlery, ktoré by vám mohli priniesť cennú návštevnosť.
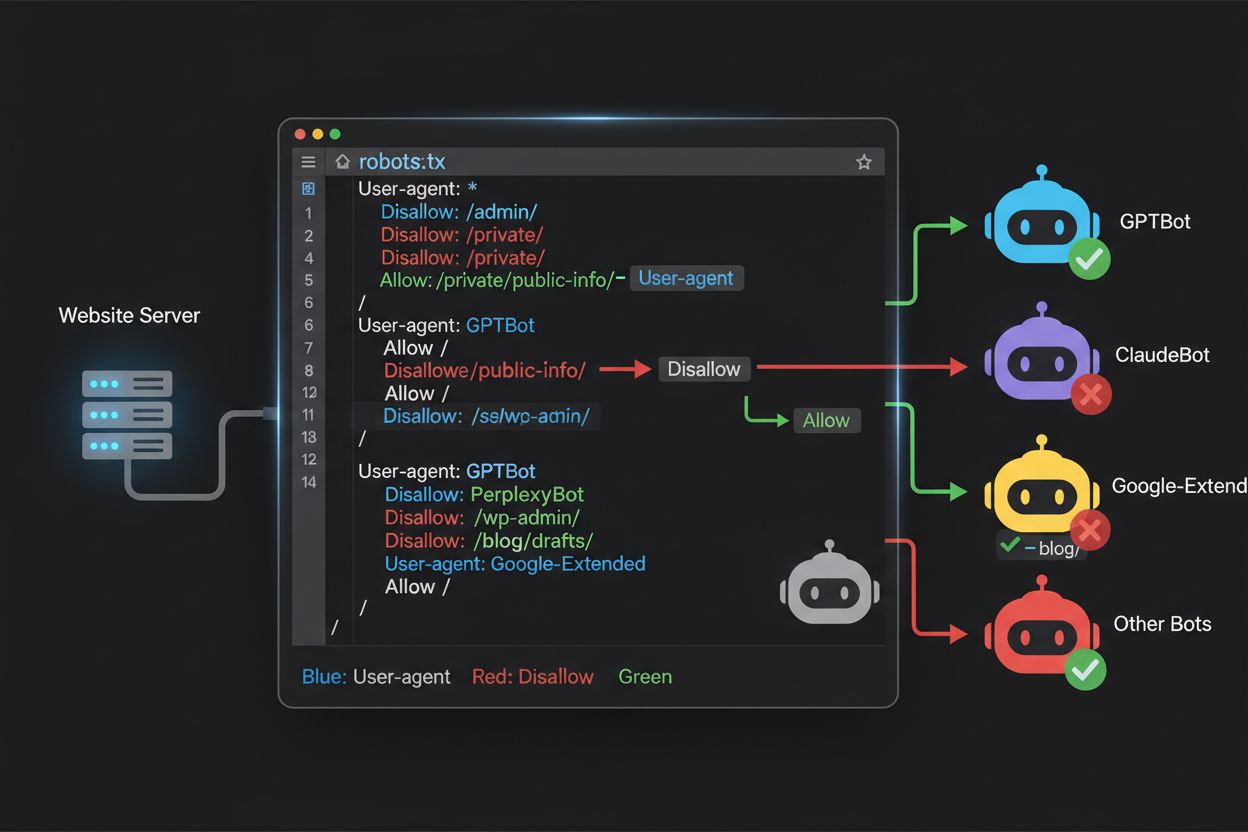
Súbor robots.txt, umiestnený v koreňovom adresári vašej domény (vasadomena.com/robots.txt), používa jednoduchú syntax na komunikáciu preferencií pre crawlery, ktoré protokol rešpektujú. Každé pravidlo sa začína direktívou User-Agent, ktorá určuje, na ktorý bot sa pravidlo vzťahuje, nasleduje jeden alebo viac príkazov Disallow označujúcich, ktoré cesty bot nesmie navštíviť. Na blokovanie všetkých hlavných AI tréningových crawlerov pri zachovaní prístupu pre tradičné vyhľadávače vytvoríte samostatné bloky User-Agent pre každý tréningový crawler, ktorého chcete vylúčiť: GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended a ďalšie, každý s direktívou “Disallow: /”, ktorá im zabráni crawlovať akýkoľvek obsah na vašom webe. Zároveň zabezpečíte, že legitímne vyhľadávacie crawlery ako Googlebot, Bingbot a vyhľadávacie varianty ako OAI-SearchBot zostanú neblokované, teda môžu ďalej indexovať váš obsah a prinášať návštevnosť. Správne nakonfigurovaný robots.txt by mal obsahovať aj odkaz na váš XML sitemap, čo pomáha vyhľadávačom efektívne objavovať a indexovať obsah. Dôležitosť správnej konfigurácie nemožno podceniť – jediná syntaktická chyba, nesprávny znak alebo nesprávny user agent môže znefunkčniť celú ochrannú stratégiu, umožniť prístup nechceným crawlerom alebo naopak zablokovať zdroje legitímnej návštevnosti. Testovanie konfigurácie pred nasadením je preto nevyhnutné na zabezpečenie správneho účinku robots.txt.
# Blokovanie AI tréningových crawlerov
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Povolenie tradičných vyhľadávačov
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Odkaz na sitemap
Sitemap: https://yoursite.com/sitemap.xml
Mnohí vydavatelia stoja pred jemným rozhodnutím: chcú zostať viditeľní vo výsledkoch AI vyhľadávania a získať návštevnosť z týchto platforiem, no zároveň nechcú, aby ich obsah bol použitý na tréning základných AI modelov, ktoré konkurujú ich podnikaniu. Táto selektívna stratégia vyžaduje rozlíšenie medzi vyhľadávacími a tréningovými crawlermi tej istej spoločnosti – napríklad povoliť OAI-SearchBot od OpenAI (poháňa vyhľadávanie v ChatGPT a vracia návštevnosť), ale blokovať GPTBot (tréning modelu). Podobne môžete povoliť vyhľadávací crawler PerplexityBot a blokovať jeho tréningové operácie, alebo povoliť Claude-Web pre vyhľadávanie na žiadosť používateľa a zablokovať tréningové aktivity ClaudeBot. Obchodné dôvody sú jasné: vyhľadávacie crawlery spravidla fungujú s oveľa nižším pomerom crawl-to-refer, keďže sú navrhnuté na priamy prínos návštevnosti, zatiaľ čo tréningové crawlery spotrebúvajú obsah vo veľkom s minimálnou návratnosťou. Tento prístup si vyžaduje starostlivú konfiguráciu a priebežné monitorovanie, keďže spoločnosti občas menia svoje stratégie alebo zavádzajú nové user agenty, ktoré stierajú hranicu medzi vyhľadávaním a tréningom. Vydavatelia realizujúci túto stratégiu by mali pravidelne analyzovať serverové logy, aby overili, že požadované crawlery majú prístup a blokované crawlery sú vylúčené, pričom svoju robots.txt konfiguráciu upravovať podľa vývoja AI prostredia a nových hráčov na trhu.
# Povolenie AI vyhľadávacích crawlerov
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Blokovanie tréningových crawlerov
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Aj skúsení webmasteri často robia chyby v konfigurácii, ktoré úplne znehodnotia ich stratégiu robots.txt a vystavia obsah botom, ktoré chceli blokovať. Prvou častou chybou je vytváranie samostatných riadkov User-Agent bez zodpovedajúcich Disallow direktív – napríklad napíšete “User-Agent: GPTBot” a hneď pokračujete ďalším pravidlom bez špecifikácie, čo má byť GPTBotovi zakázané, čím zostáva úplne neblokovaný. Druhou chybou je nesprávne umiestnenie, pomenovanie alebo veľké písmená v názve súboru; súbor sa musí volať presne “robots.txt” (malými písmenami), musí byť v koreňovom adresári domény a servovaný s HTTP statusom 200 – ak je v podadresári alebo sa volá “Robots.txt” či “robots.TXT”, crawlery ho vôbec nevidia. Treťou chybou je vkladanie prázdnych riadkov do pravidlového bloku, čo mnohé parsere interpretujú ako ukončenie pravidla a následné direktívy ignorujú alebo zle aplikujú. Štvrtou chybou je citlivosť na veľké a malé písmená v URL cestách; názvy user agentov nie sú citlivé na veľkosť písmen, ale cesty v Disallow sú, takže “Disallow: /Admin” neblokuje “/admin” ani “/ADMIN”. Piata chyba je nesprávne použitie zástupných znakov – hviezdička (*) nahradzuje akúkoľvek postupnosť znakov, no mnohí vydavatelia ju zle používajú, napr. “Disallow: .pdf” namiesto “Disallow: /.pdf” alebo “Disallow: /*pdf”, aby správne blokovali prípony súborov. Navyše, niektorí vydavatelia vytvárajú príliš komplikované pravidlá s viacerými Disallow, ktoré si navzájom odporujú, alebo neberú do úvahy parametre a query stringy v URL, čo môže spôsobiť blokovanie legitímneho obsahu alebo ponechanie prístupu tam, kde nechceli. Testovanie konfigurácie pomocou špecializovaných validatorov robots.txt pred nasadením vám umožní odhaliť tieto chyby včas.
Najčastejšie chyby, ktorým sa vyhnúť:
Google-Extended predstavuje osobitý prípad v konfigurácii robots.txt, pretože funguje ako riadiaci token, nie ako tradičný crawler, a pochopenie tohto rozdielu je zásadné pre správne rozhodnutie o blokovaní. Na rozdiel od Googlebotu, ktorý crawl-uje váš web na účely indexácie pre Google Vyhľadávanie, Google-Extended je signálom, či môže byť váš obsah použitý na tréning AI modelov Gemini od Google a pre funkciu Google AI Overviews vo výsledkoch vyhľadávania. Blokovanie Google-Extended zabráni použitiu vášho obsahu na tréning Gemini a v AI Overviews, no neovplyvní vašu viditeľnosť v klasickom Google Vyhľadávaní – Googlebot bude váš obsah indexovať naďalej. Rozhodnutie je významné: blokovaním Google-Extended váš obsah nebude figurovať v AI Overviews, ktoré majú čoraz väčší význam vo výsledkoch Google a môžu priniesť veľkú návštevnosť, no zároveň chránite svoj obsah pred tréningom konkurenčného AI modelu. Naopak, povolením Google-Extended môže byť váš obsah v AI Overviews (potenciálne získať návštevnosť), ale zároveň prispievate do tréningových dát Gemini, čo môže časom konkurovať vašim zdrojom. Vydavatelia by mali zvážiť svoju konkrétnu situáciu – organizácie závislé na priamom trafiku môžu profitovať z blokovania Google-Extended, iné môžu uprednostniť zvýšenú viditeľnosť. Toto rozhodnutie by ste mali spraviť vedome, nie automaticky, pretože má zásadný dopad na vašu dlhodobú návštevnosť a viditeľnosť v ekosystéme Google.
Testovanie konfigurácie robots.txt pred nasadením do produkcie je absolútne kľúčové, keďže chyby môžu mať ďalekosiahle dôsledky pre vašu viditeľnosť vo vyhľadávačoch aj pre ochranu obsahu. Google Search Console poskytuje zabudovaný tester robots.txt, kde si môžete overiť, či konkrétny user agent môže pristupovať ku konkrétnej URL – zadáte napríklad “GPTBot” a cestu, Google vám povie, či by bol povolený alebo zablokovaný podľa vašej konfigurácie. Merkle Robots.txt Tester ponúka podobnú funkcionalitu s prehľadným rozhraním a vysvetlením interpretácie pravidiel. TechnicalSEO.com poskytuje ďalší bezplatný nástroj, ktorý kontroluje syntax robots.txt a ukáže vám presne, ako budú jednotlivé boty spracované. Pre komplexnejšie monitorovanie Knowatoa AI Search Console ponúka špecializované nástroje na sledovanie aktivít AI crawlerov a validáciu konfigurácie podľa konkrétnych botov, ktoré sa snažíte blokovať. Vaše testovanie by malo zahŕňať nahratie robots.txt do staging prostredia, následnú kontrolu, či kritické stránky zostávajú prístupné a či sú AI boty naozaj blokované, ako aj monitorovanie serverových logov pre nečakané aktivity crawlerov. Súčasťou musí byť aj kontrola správnosti odkazu na sitemap a overenie, že vyhľadávače majú stále prístup k obsahu – cieľom je blokovať AI tréningové crawlery bez toho, aby ste nechtiac blokovali legitímnu návštevnosť z vyhľadávania. Až po dôkladnom otestovaní nasadzujte robots.txt do produkcie a aj potom minimálne prvý týždeň sledujte logy pre odhalenie prípadných problémov.
Nástroje na testovanie:
Robots.txt je síce užitočnou prvou líniou obrany, no treba chápať, že funguje na báze čestnosti – boty, ktoré protokol rešpektujú, ho dodržia, no zlé alebo zle navrhnuté crawlery ho môžu úplne ignorovať a k obsahu sa aj tak dostať. Odhady hovoria, že robots.txt úspešne zastaví približne 40–60 % nechcenej aktivity crawlerov, čo znamená, že zvyšných 40–60 % botov protokol ignoruje alebo ho úmyselne obchádza. Pre vydavateľov, ktorí potrebujú robustnejšiu ochranu, je nutné pridať ďalšie vrstvy obrany. Web Application Firewall (WAF) od Cloudflare umožňuje nastaviť pravidlá na blokovanie podľa user agentov, IP adries či správania, čím ochránite web pred botmi, ktoré robots.txt ignorujú. Serverové nástroje ako .htaccess (na Apache) alebo ekvivalentné nastavenia na Nginx vedia blokovať konkrétne user agenty či rozsahy IP ešte predtým, než sa požiadavka dostane k aplikácii. IP blokovanie je efektívne, ak poznáte IP rozsahy crawlerov, no vyžaduje priebežnú údržbu, keďže infraštruktúra crawlerov sa mení. Nástroje ako Fail2ban automaticky blokujú IP s podozrivým správaním, napríklad s neľudskou frekvenciou požiadaviek či pokusmi o prístup k citlivým cestám. Implementácia týchto doplnkových ochrán si však vyžaduje opatrnosť – príliš agresívne blokovanie môže omylom vylúčiť legitímnu návštevnosť, vrátane reálnych používateľov pristupujúcich cez VPN alebo firemné proxy, ktoré zdieľajú IP s crawlermi. Najefektívnejší prístup kombinuje robots.txt ako zdvorilú žiadosť, blokovanie user agentov na serveri pre boty ignorujúce robots.txt a monitorovanie správania na zachytenie crawlerov, ktoré spoofujú user agenta alebo využívajú distribuované IP. Vydavatelia by mali nasadzovať tieto vrstvy postupne a každú dôkladne otestovať, aby omylom neblokovali legitímnu návštevnosť, no zároveň dosiahli cieľ ochrany obsahu.
Pochopenie toho, čo na váš web v skutočnosti pristupuje, je zásadné pre overenie účinnosti konfigurácie robots.txt a identifikáciu nových crawlerov, ktoré bude treba blokovať. Analýza serverových logov je primárnou metódou tohto monitoringu – logy vášho webservera (prístupové logy Apache, logy Nginx a pod.) obsahujú podrobné záznamy o každej požiadavke, vrátane user agenta, IP adresy, času a požadovaného zdroja. Pomocou príkazu grep môžete v logoch vyhľadávať konkrétnych user agentov; napríklad “grep ‘GPTBot’ /var/log/apache2/access.log” zobrazí všetky požiadavky od GPTBot a umožní vám overiť, či blokovanie funguje. Sofistikovanejšia analýza zahŕňa parsovanie logov pre zistenie miery crawl-ovania jednotlivých botov, konkrétnych stránok, ktoré navštevujú a či rešpektujú vaše robots.txt pravidlá. Automatizované monitorovacie riešenia vedia logy priebežne analyzovať a upozorniť vás na nové alebo nečakané crawlery, čo je zvlášť dôležité, keďže AI crawlery sa rýchlo menia. Niektorí vydavatelia využívajú platformy na agregáciu logov ako ELK Stack, Splunk či cloudové riešenia, ktoré umožňujú centralizovane analyzovať aktivitu crawlerov naprieč viacerými servermi. Keďže AI crawlery sa rýchlo menia, monitoring nie je jednorazová úloha, ale priebežná zodpovednosť – nové boty vznikajú pravidelne, existujúce menia user agent, aj ich správanie sa vyvíja. Nastavenie pravidelnej rutiny (týždenné alebo mesačné kontroly logov) vám umožní držať krok so zmenami a upraviť robots.txt proaktívne, namiesto reaktívneho riešenia problémov po ich vzniku.
Vaša konfigurácia robots.txt pre AI crawlery je v konečnom dôsledku rozhodnutím ovplyvňujúcim príjmy a zaslúži si rovnakú strategickú pozornosť, akú venujete iným kľúčovým obchodným rozhodnutiam. Povolenie neobmedzeného prístupu tréningovým crawlerom znamená, že AI modely trénované na vašich dátach môžu časom konkurovať vašej návštevnosti a príjmom – ak je váš obchodný model závislý od priamej návštevnosti, vyhľadávateľnosti alebo reklamy, v podstate poskytujete bezplatné tréningové dáta spoločnostiam, ktoré budujú konkurenčné produkty. Naopak, blokovanie všetkých AI crawlerov znamená, že prídete o potenciálnu viditeľnosť vo výsledkoch vyhľadávania poháňaných AI a referral traffic z AI asistentov, čo je rastúci spôsob, ako používatelia objavujú obsah. Optimálna stratégia závisí od vášho obchodného modelu: vydavatelia financovaní reklamou môžu profitovať z povolenia vyhľadávacích crawlerov (prinašajú návštevnosť a zobrazenia reklamy) pri blokovaní tréningových crawlerov (neprinášajú návštevnosť). Vydavatelia so subscription modelom môžu zvoliť agresívnejší prístup a blokovať väčšinu AI crawlerov, aby ochránili obsah pred sumarizáciou alebo replikáciou AI systémami. Tí, ktorým ide o značku a líderské postavenie, môžu AI vyhľadávanie vítať ako distribučný kanál. Kľúčom je rozhodnúť sa vedome – mnohí vydavatelia robots.txt pre AI crawlerov nikdy nenakonfigurovali, čím v podstate povolili všetko a pasívne prispievajú svojím obsahom na tréning AI bez vedomého rozhodnutia. Zvážte tiež implementáciu schémy (schema markup), ktorá zabezpečí správnu atribúciu, ak váš obsah AI systémy použijú, čo môže pomôcť, aby návštevnosť a uznanie smerovali späť na váš web aj pri citovaní AI asistentmi. Vaša konfigurácia robots.txt by mala odrážať vašu zámernú obchodnú stratégiu, pravidelne revidovanú podľa vývoja AI prostredia aj vašich priorít.
Krajina AI crawlerov sa vyvíja bezprecedentným tempom – nové spoločnosti uvádzajú AI produkty, existujúce firmy predstavujú nové crawlery a user agent reťazce sa často menia či rozširujú. Vaša konfigurácia robots.txt by nemala byť nastavená a zabudnutá, ale živý dokument kontrolovaný aspoň raz za štvrťrok. Zaveďte proces sledovania odvetvových oznámení o nových AI crawlery, prihláste sa na odber relevantných newsletterov alebo blogov, ktoré tieto zmeny sledujú, a pravidelne kontrolujte serverové logy na výskyt neznámych user agentov signalizujúcich nové crawlery na vašom webe. Pri objavení nových crawlerov si zistite ich účel a obchodný model, rozhodnite sa, či zapadajú do vašej stratégie ochrany obsahu, a podľa toho aktualizujte robots.txt. Zároveň sledujte účinnosť konfigurácie prostredníctvom metrík ako objem crawler trafficu, pomer požiadaviek crawlerov k reálnej návštevnosti alebo zmeny v organickej návštevnosti či referral trafficu z AI vyhľadávačov. Niektorí vydavatelia zistia, že ich pôvodná blokovacia stratégia potrebuje po pár mesiacoch real data úpravu – možno blokovanie konkrétneho crawlera malo nečakané dôsledky, alebo povolenie niektorých crawlerov prinieslo viac cennej návštevnosti, než čakali. Buďte pripravení stratégiu priebežne upravovať podľa reálnych výsledkov, nie domnienok. Nakoniec, komunikujte stratégiu robots.txt relevantným ľuďom vo firme – SEO tímu, content tímu aj vedeniu, aby rozhodnutia zostali konzistentné a zámerné aj v čase organizačných zmien. Táto priebežná pozornosť manažmentu crawlerov zabezpečí, že vaša stratégia ochrany obsahu zostane účinná a v súlade s obchodnými cieľmi aj pri ďalšej transformácii AI prostredia.
Nie. Blokovanie crawlerov na tréning AI ako GPTBot, ClaudeBot a CCBot nemá vplyv na vaše pozície vo vyhľadávačoch Google alebo Bing. Tradičné vyhľadávače používajú iné crawlery (Googlebot, Bingbot), ktoré fungujú nezávisle. Tie blokujte len v prípade, že sa chcete úplne odstrániť z výsledkov vyhľadávania.
Hlavné crawlery od OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) a Perplexity (PerplexityBot) oficiálne uvádzajú, že rešpektujú pokyny robots.txt. Menšie alebo menej transparentné boty však môžu vašu konfiguráciu ignorovať, preto existujú vrstvené ochranné stratégie.
Záleží na vašej stratégii. Blokovaním len tréningových crawlerov (GPTBot, ClaudeBot, CCBot) chránite svoj obsah pred tréningom modelov, pričom vyhľadávacie crawlery vám môžu pomôcť objaviť sa vo výsledkoch AI vyhľadávania. Úplné blokovanie vás odstráni z AI ekosystémov.
Svoju konfiguráciu kontrolujte aspoň raz za štvrťrok. AI spoločnosti pravidelne predstavujú nové crawlery. Anthropic zlúčilo svoje boty 'anthropic-ai' a 'Claude-Web' do 'ClaudeBot', čím nový bot dočasne získal neobmedzený prístup na stránky, ktoré pravidlá neaktualizovali.
Robots.txt je súbor v koreňovom adresári domény, platí pre všetky stránky, zatiaľ čo meta tagy robots sú HTML pokyny na jednotlivých stránkach. Robots.txt sa kontroluje ako prvé a môže crawlerom úplne zabrániť v prístupe, meta tagy sa čítajú len pri načítaní stránky. Pre komplexnú kontrolu použite oboje.
Áno. Môžete použiť pravidlá Disallow pre konkrétne cesty v robots.txt (napr. 'Disallow: /premium/' pre blokovanie len prémiového obsahu) alebo meta tagy robots na jednotlivých stránkach. Takto ochránite citlivý obsah a zároveň povolíte prístup crawlerom inde.
Ak bot ignoruje robots.txt, potrebujete ďalšie ochranné metódy ako blokovanie na úrovni servera (.htaccess), blokovanie IP alebo WAF pravidlá. Robots.txt zastaví približne 40–60 % nežiaducich crawlerov, preto sú dôležité vrstvené ochrany pre komplexnú obranu.
Použite nástroje na testovanie, napríklad robots.txt tester v Google Search Console, Merkle Robots.txt Tester alebo TechnicalSEO.com na overenie konfigurácie. Sledujte serverové logy pre aktivitu crawlerov a overte, že blokované boty sú vylúčené a povolené boty majú prístup k obsahu.
Robots.txt je len prvý krok. Použite AmICited na sledovanie, ktoré AI systémy citujú váš obsah, ako často vás zmieňujú a zabezpečte správnu atribúciu naprieč GPTs, Perplexity, Google AI Overviews a ďalšími.
Zistite, ako selektívne povoliť alebo blokovať AI crawlerov podľa obchodných cieľov. Implementujte diferencovaný prístup crawlerov na ochranu obsahu a zároveň u...

Zistite, čo znamená crawl budget pre AI, ako sa líši od tradičných crawl budgetov vyhľadávačov a prečo je dôležitý pre viditeľnosť vašej značky v AI-generovanýc...

Kompletný referenčný sprievodca AI crawlermi a botmi. Identifikujte GPTBot, ClaudeBot, Google-Extended a viac ako 20 ďalších AI crawlerov s user agentmi, rýchlo...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.