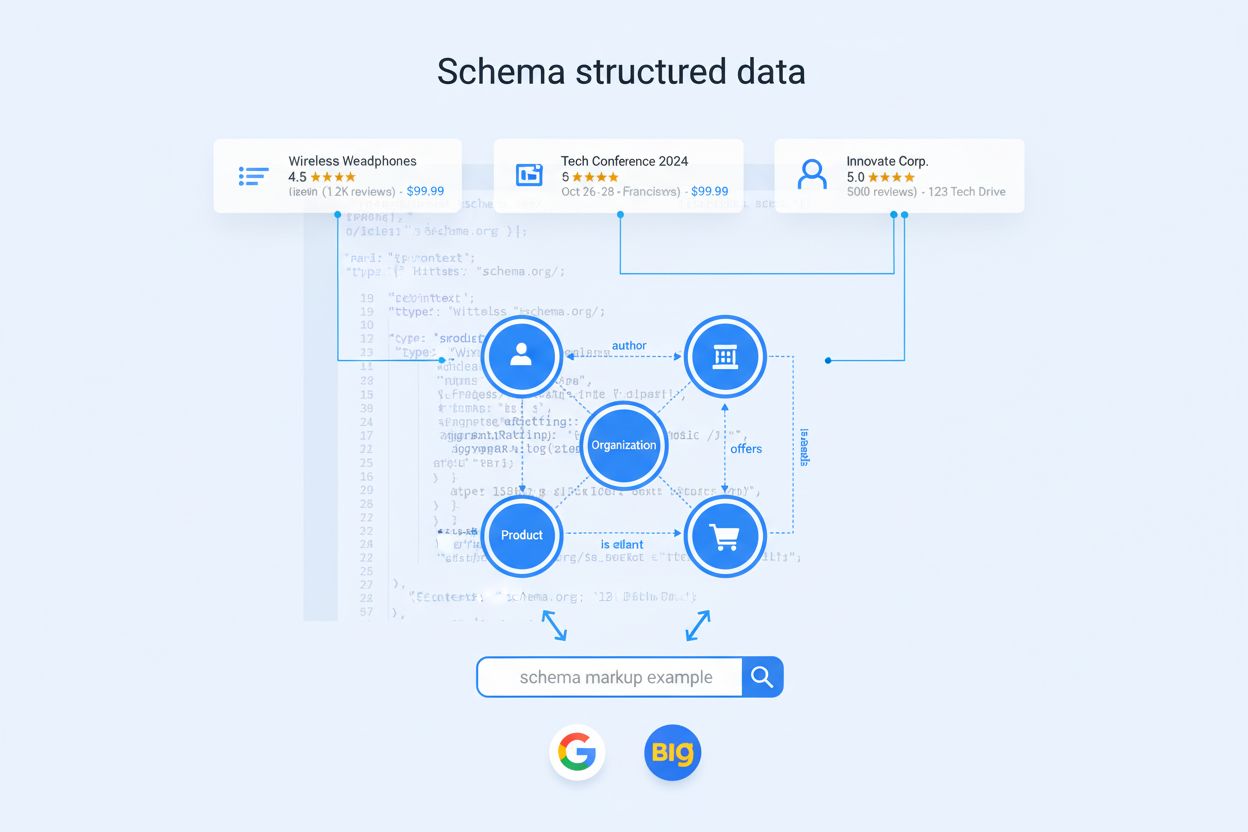
Schema Markup
Schema markup je štandardizovaný kód, ktorý pomáha vyhľadávačom pochopiť obsah. Zistite, ako štruktúrované dáta zlepšujú SEO, umožňujú rozšírené výsledky a podp...
8 min čítania

Zistite, na ktorých typoch schém najviac záleží pre AI viditeľnosť. Objavte, ako LLM interpretujú štruktúrované dáta a implementujte schema stratégie, ktoré zabezpečia, že vaša značka bude citovaná v AI odpovediach.
Roky bol schema markup primárne o získavaní rich výsledkov — tých výrazných hodnotení hviezdičkami, produktových kariet a FAQ rozbalovačiek, ktoré sa zobrazovali v tradičných výsledkoch vyhľadávania. Dnes sa tento prístup stáva zastaraným. Veľké jazykové modely a AI answer enginy interpretujú schema markup zásadne inak, využívajúc ho nie na kozmetické vylepšenia, ale na budovanie znalostných grafov a porozumenie vzťahom medzi entitami vo veľkom rozsahu. Približne 45 miliónov webov (12,4% všetkých registrovaných domén) už implementuje nejakú formu schema.org markup, takže AI systémy majú prístup k bezprecedentnému množstvu štruktúrovaných dát na učenie a analýzu. Zmena je zásadná: schema markup teraz ovplyvňuje, či bude vaša značka citovaná v AI-generovaných odpovediach, ako presne modely reprezentujú vaše produkty a služby a či sa váš obsah stane dôveryhodným zdrojom v AI-first prostredí vyhľadávania.
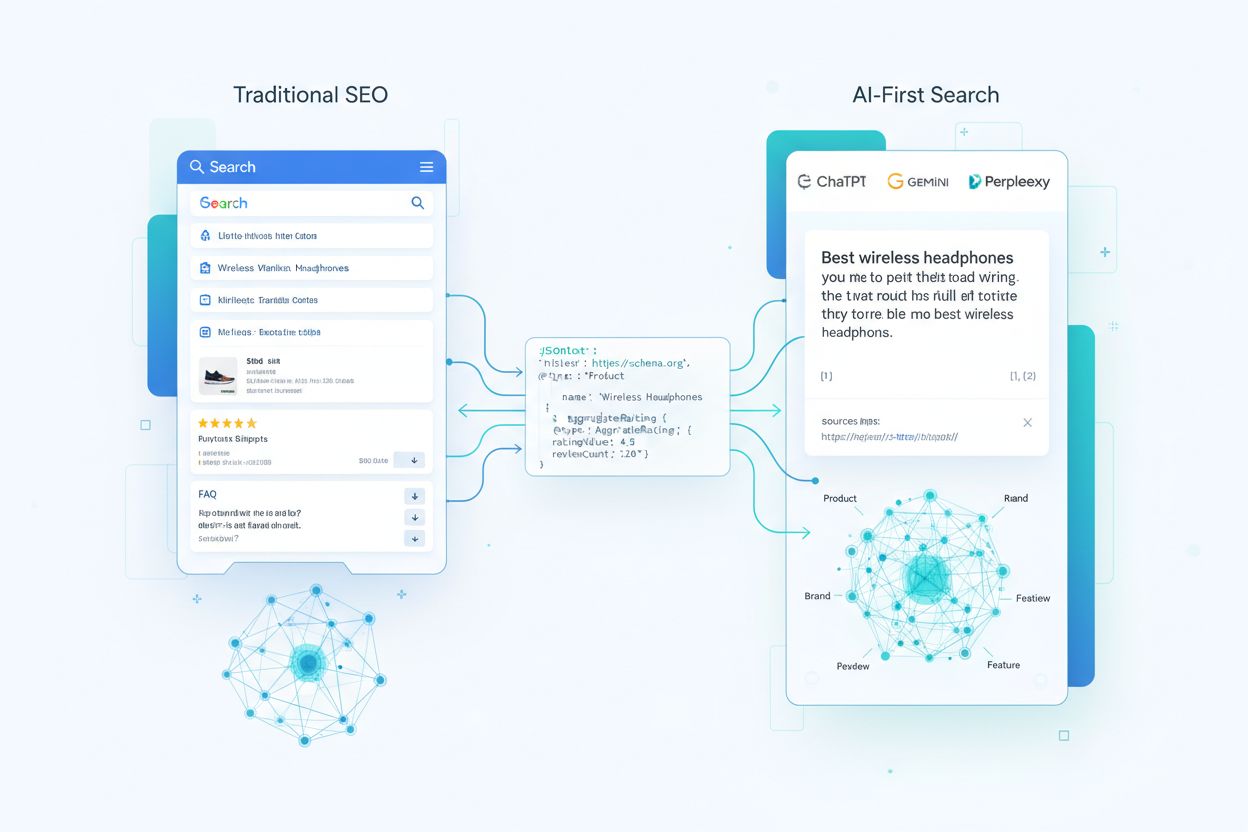
Pochopenie, ako AI systémy spotrebúvajú schema markup, si vyžaduje sledovať cestu vašich štruktúrovaných dát od prvého prehľadania až po odpovede generované LLM. Keď crawler navštívi vašu stránku, extrahuje JSON-LD, microdata alebo RDFa bloky a normalizuje ich do indexu spolu s neštruktúrovaným textom a médiami. Tieto štruktúrované dáta sa stávajú súčasťou webového znalostného grafu, kde sú entity prepojené vzťahmi a priraďujú sa im embeddingy pre sémantické vyhľadávanie. V systémoch retrieval-augmented generation (RAG) sa schéma môže priamo vložiť do blokov, ktoré tvoria vektorové indexy — jeden blok môže obsahovať popis produktu aj jeho JSON-LD markup, čím modelom poskytuje naratívny kontext aj štruktúrované kľúčové hodnoty. Rôzne LLM architektúry spotrebúvajú schému rôzne: niektoré vrstvia modely na existujúce indexy vyhľadávania a znalostné grafy, iné používajú multi-zdrojové retrieval pipeline, ktoré ťažia zo štruktúrovaného aj neštruktúrovaného obsahu. Kľúčovým poznatkom je, že dobre implementovaná schéma funguje ako kontrakt s modelom, ktorý v silne štruktúrovanej forme deklaruje, ktoré fakty na vašej stránke považujete za kanonické a dôveryhodné.
| Typ architektúry | Použitie schémy | Vplyv na citáciu | Kľúčové vlastnosti |
|---|---|---|---|
| Tradičné vyhľadávanie + LLM vrstva | Posilňuje existujúci znalostný graf | Vysoký – modely citujú dobre štruktúrované zdroje | Organization, Product, Article |
| Retrieval-Augmented Generation | Vložené do vektorových blokov | Stredne-vysoký – schéma pomáha s presnosťou | Všetky typy s detailnými vlastnosťami |
| Multi-zdrojové answer-enginy | Používa sa na rozlíšenie entít | Stredný – súťaží s inými signálmi | Person, LocalBusiness, Service |
| Konverzačné AI | Podporuje pochopenie kontextu | Rôzne – závisí od tréningových dát | FAQPage, HowTo, BlogPosting |
Nie všetky typy schém majú v AI ére rovnakú váhu. Organization markup slúži ako kotva celého entitného grafu, pomáha modelom pochopiť identitu značky, autoritu a vzťahy. Product schéma je nevyhnutná pre e-commerce a retail, umožňuje AI systémom porovnávať vlastnosti, ceny a hodnotenia naprieč zdrojmi. Article a BlogPosting markup pomáhajú modelom identifikovať dlhší obsah vhodný pre vysvetľujúce dopyty a odborné líderstvo. Person schéma je kľúčová pre budovanie dôveryhodnosti autora a priradenie odborníka v AI-generovaných odpovediach. FAQPage markup priamo mapuje na konverzačné dopyty, na ktoré sú AI asistenti navrhnutí odpovedať. Pre SaaS a B2B firmy sú rovnako dôležité typy SoftwareApplication a Service, ktoré sa často objavujú v porovnaniach “najlepšie nástroje na X” a hodnoteniach funkcií. Pre lokálne podniky a zdravotnícke zariadenia poskytujú LocalBusiness a MedicalOrganization typy geografickú presnosť a regulačnú jasnosť. Skutočné odlíšenie však neprichádza z používania základných typov, ale z pokročilých vlastností, ktoré na ne navrstvíte — konzistencia naprieč stránkami, jasné identifikátory entít a explicitné mapovanie vzťahov.
Základné vlastnosti schémy ako name, description a URL sú dnes štandardom; 72,6% stránok na prvej strane Google už používa nejakú formu schema markup. Vlastnosti, ktoré naozaj vytvárajú rozdiel pre AI viditeľnosť, sú spojivovým tkanivom, ktoré pomáha modelom rozlišovať entity, chápať vzťahy a odstrániť nejasnosti významu. Tu sú najdôležitejšie pokročilé vlastnosti:
Tieto vlastnosti menia schému z obyčajného dátového kontajnera na sémantickú mapu, ktorou sa modely môžu pohybovať s dôverou. Keď použijete sameAs na prepojenie vašej organizácie s jej stránkou na Wikipédii, nepridávate len metadáta — hovoríte modelu “toto je autoritatívny zdroj faktov o nás”. Keď použijete additionalProperty na zakódovanie špecifikácií produktov alebo vlastností služieb, poskytujete presne tie atribúty, ktoré AI systémy hľadajú pri zostavovaní porovnaní alebo odporúčaní.
Väčšina organizácií vníma schema markup ako jednorazovú úlohu, no konkurenčná výhoda v AI-vyhľadávaní si vyžaduje vnímať ju ako disciplínu riadenia dát. Užitočný rámec predstavuje štvornásobný model zrelosti, ktorý tímom pomáha pochopiť svoju pozíciu a ďalšie kroky:
Level 1 – Základná schéma pre rich výsledky sa zameriava na minimálny markup na vybraných šablónach, hlavne na získanie hviezdičiek, produktových kariet alebo FAQ úryvkov. Správa je voľná, konzistentnosť nízka a cieľom je skôr kozmetické vylepšenie než sémantická jasnosť.
Level 2 – Pokrytie zamerané na entity štandardizuje Organization, Product, Article a Person markup na kľúčových šablónach, zavádza konzistentné používanie @id hodnôt a pridáva základné sameAs odkazy na predchádzanie zámenám entít.
Level 3 – Schéma integrovaná v znalostnom grafe zosúlaďuje schéma ID s internými dátovými modelmi (CMS, PIM, CRM), rozsiahlo využíva vlastnosti about/mentions/additionalType a kóduje medzi-stranové vzťahy, aby modely pochopili, ako obsahové uzly súvisia medzi sebou aj vonkajšími entitami.
Level 4 – Schéma optimalizovaná pre LLM & RAG cielene štruktúruje markup pre konverzačné dopyty a AI úryvky, zosúlaďuje schému s internými RAG pipeline a zahŕňa meranie a iteráciu ako jadro praxe.
Väčšina značiek momentálne stagnuje na úrovni 1–2, čo znamená, že základná adopcia je už len hygienickým faktorom, nie odlíšením. Posun na úroveň 3–4 je miestom, kde sa optimalizácia schémy pre LLM stáva trvalou konkurenčnou výhodou, pretože modely dokážu spoľahlivo interpretovať vaše entity naprieč mnohými formátmi dopytov a zobrazeniami.
Rôzne odvetvia majú rôzne entity, rizikové profily a úmysly používateľov, preto pokročilé využitie schémy nemôže byť univerzálne. Základné princípy — jasnosť entít, modelovanie vzťahov a súlad s obsahom na stránke — ostávajú rovnaké, ale typy a vlastnosti schém, ktoré uprednostníte, by mali odrážať skutočné vyhľadávacie správanie vo vašom segmente.
Pre e-commerce a retail sú hlavné entity Produkty, Ponuky, Recenzie a vaša Organizácia. Každá produktová stránka s vysokým zámerom by mala obsahovať podrobný Product markup s identifikátormi (SKU, GTIN), značkou, modelom, rozmermi, materiálmi a rozlišovacími atribútmi cez additionalProperty. Doplnte to Ponukami s cenami a dostupnosťou a AggregateRating štruktúrami, ktoré modelom pomáhajú pochopiť sociálny dôkaz. Okrem základov myslite na to, ako zákazníci kladú otázky: “Je to vodotesné?”, “Je v balení záruka?”, “Aká je politika vrátenia?” Zakódovanie týchto odpovedí ako FAQPage markup na tej istej URL a zabezpečenie súladu medzi Product atribútmi a FAQ obsahom uľahčí answer enginom správne citovať vašu stránku.
Pre SaaS a B2B služby sú entity abstraktnejšie, no dobre mapovateľné na SoftwareApplication, Service a Organization schému. Pre každý produkt alebo službu definujte SoftwareApplication alebo Service entitu s jasným popisom kategórie, podporovaných platforiem, integrácií a cenových modelov, pričom additionalProperty polia využite na vymenovanie funkcií, ktoré sa často objavujú v porovnaniach “najlepšie nástroje na X”. Prepojte ich s vašou organizáciou cez provider alebo offers vzťahy a s tímom odborníkov cez Person markup. Na obsahovej strane Article, BlogPosting, FAQPage a HowTo štruktúry pomáhajú LLM identifikovať vaše najlepšie aktíva pre hodnotiace a vzdelávacie dopyty.
Pre lokálne, zdravotnícke a regulované segmenty môžu LocalBusiness, MedicalOrganization a príbuzné MedicalEntity typy zakódovať adresy, oblasti pôsobenia, špecializácie, akceptované poistenie a otváracie hodiny oveľa jednoznačnejšie než voľný text. To je dôležité, keď sa AI asistent opýta “nájdi detského kardiológa v mojom okolí, ktorý berie moje poistenie” alebo “odporuč pohotovosť, ktorá je teraz otvorená”. V týchto segmentoch buďte obzvlášť opatrní, aby schéma neuvádzala nadsadené ani citlivé detaily — označujte len fakty, s ktorými súhlasíte, že budú použité v rôznych kontextoch, a zabezpečte kontrolu compliance a právneho oddelenia pri všetkých medicínsky či regulačne orientovaných atribútoch.
Správanie LLM je zo svojej podstaty stochastické, preto nedosiahnete úplne presnú atribúciu len zmenami v schéme. Môžete však vybudovať ľahký monitorovací systém, ktorý pravidelne vzorkuje AI odpovede na vopred určenom súbore dopytov. Sledujte, ktoré entity sú zmieňované, ktoré URL sú citované, ako je vaša značka opísaná a či sú kľúčové fakty (ceny, možnosti, compliance detaily) presné naprieč platformami ako ChatGPT, Gemini, Perplexity či Bing Copilot. Ak sa niečo pokazí — vymyslené vlastnosti, chýbajúce zmienky či citácie uprednostňujúce agregátory pred vašimi hlavnými stránkami — začnite kontrolou rozporuplných alebo neúplných signálov. Protirečí on-page text schéme? Chýbajú sameAs odkazy alebo smerujú na neaktuálne profily? Tvrdí viacero stránok, že sú kanonickým zdrojom tej istej entity? Strategicky plánujte kontrolu schémy aspoň raz za štvrťrok podľa nových ponúk, obsahových klastrov a zmien v tom, ako AI answer enginy zobrazujú vašu značku.
Niekoľko vzorov opakovane znižuje účinnosť schémy pre AI systémy. Označenie obsahu, ktorý nie je skutočne viditeľný na stránke, vytvára deficit dôvery — modely sa naučia zdroje, kde sa schéma a obsah rozchádzajú, diskreditovať. Používanie príliš všeobecných typov bez špecifikácie (napr. všetko označiť ako “Thing” alebo “CreativeWork”) neposkytuje žiadny sémantický signál; modely potrebujú presné typy na pochopenie kontextu. Kopírovanie šablónovej schémy naprieč stránkami bez úpravy detailov entít je asi najčastejšou chybou — keď má každá produktová stránka rovnaký Organization markup alebo každý článok uvádza rovnakého autora, modely majú problém rozlíšiť entity a môžu váš obsah označiť ako málo hodnotný. Nekonzistentné entity ID naprieč stránkami (použitie rôznych @id pre tú istú organizáciu alebo produkt) rozbíja rozpoznávanie entít a núti modely považovať príbuzný obsah za samostatné entity. Chýbajúce sameAs odkazy na autoritatívne profily zvyšujú riziko zámien vašej značky. Napokon, rozpory medzi schémou a obsahom signalizujú nespoľahlivosť; ak schéma tvrdí, že produkt je na sklade, ale stránka hovorí “vypredané”, modely nebudú veriť ani jednému zdroju.
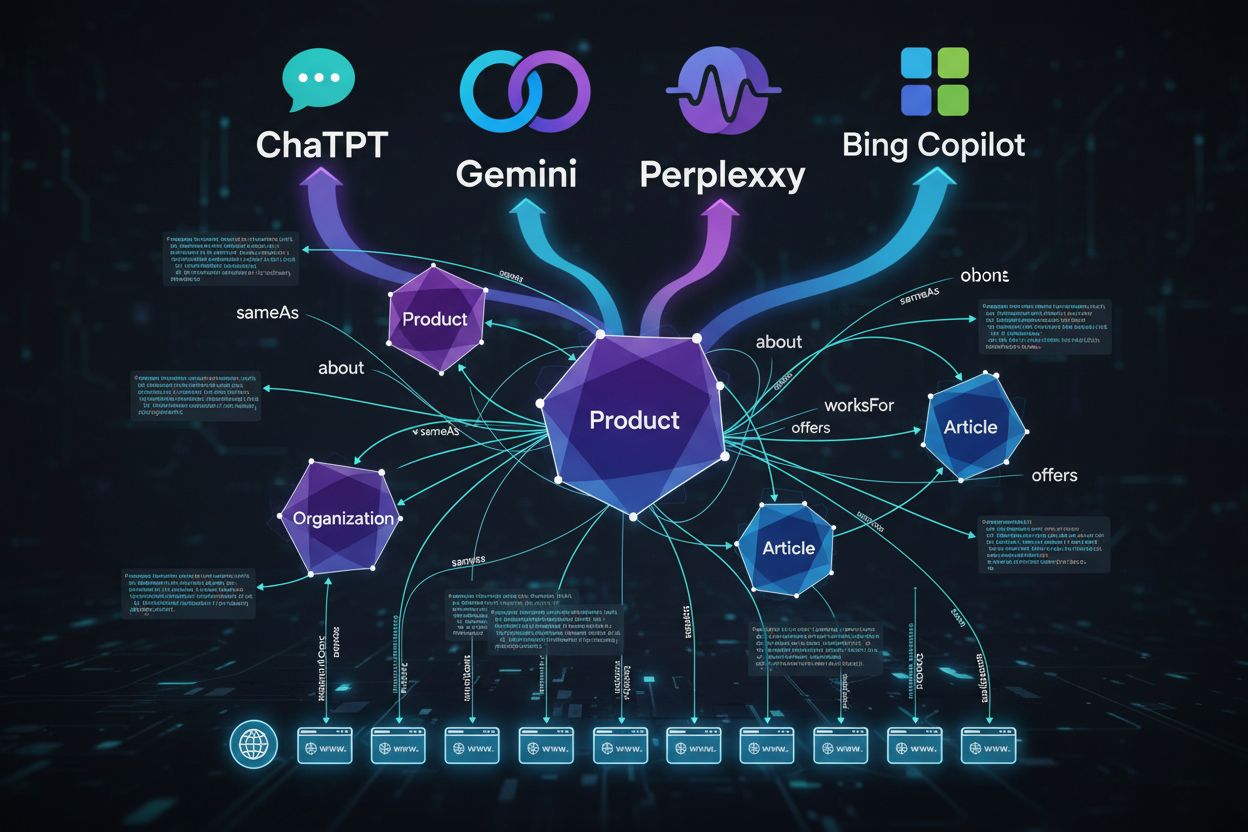
Schema markup sa mení z kozmetickej SEO taktiky na základnú technológiu pre AI-first vyhľadávanie. Prepojená schéma — kde explicitne definujete vzťahy medzi entitami pomocou vlastností ako sameAs, about a mentions — buduje znalostné grafy, v ktorých sa AI systémy môžu pohybovať s istotou. Konkurenčná výhoda už nespočíva v otázke “Aké minimálne schéma potrebujeme pre rich výsledok?”, ale v otázke “Aká štruktúra by urobila náš obsah jednoznačným pre stroj, aj mimo SERP?” Tento posun tlačí organizácie smerom k úplnejším, prepojeným a na entity zameraným schémam. Keď sa AI-vyhľadávanie stane hlavným kanálom objavovania, optimalizácia schémy pre LLM sa zmení z technickej zaujímavosti na základnú SEO disciplínu. Organizácie, ktoré postúpia v úrovniach zrelosti — od základnej schémy pre rich výsledky cez znalostno-grafové až po LLM optimalizované vzory — si vybudujú trvalé bariéry v AI vyhľadávaní, zabezpečia citácie svojej značky ako autority a zviditeľnia svoj obsah ako dôveryhodný zdroj.
Tradičný schema sa zameriaval na rozšírené výsledky (hviezdičky, úryvky). Pre AI je schema o jasnosti entít, vzťahoch a znalostných grafoch. AI systémy používajú schému na pochopenie obsahu na sémantickej úrovni, nielen na vizuálne vylepšenia.
Organization, Product, Article, Person a FAQPage sú základné. Pre SaaS pridajte SoftwareApplication a Service. Pre lokálne/zdravotnícke segmenty pridajte LocalBusiness a MedicalOrganization. Dôležitosť sa líši podľa odvetvia a zámeru používateľa.
Nie. Začnite s Organization a najhodnotnejšími stránkami (produkty, služby, kľúčové články). Postupne rozširujte podľa vášho podnikateľského modelu a tam, kde sú AI odpovede najcennejšie.
Zmeny schémy môžu ovplyvniť AI citácie v priebehu niekoľkých týždňov, ale vzťah je pravdepodobnostný. Plánujte kvartálne kontroly a nepretržité monitorovanie naprieč viacerými AI platformami na sledovanie vplyvu.
sameAs prepojí vašu entitu s kanonickými profilmi (Wikipedia, LinkedIn), aby sa predišlo zámene s menovcami. about/mentions objasňuje, na čo je vaša stránka skutočne zameraná, čo pomáha modelom pochopiť nuansy a kontext.
Nie. Schéma najlepšie funguje v súlade s kvalitným, dobre štruktúrovaným obsahom na stránke. Modely potrebujú štruktúrované dáta aj naratívny kontext, aby mohli sebavedome citovať vaše stránky.
Sledujte AI odpovede na platformách (ChatGPT, Gemini, Perplexity, Bing) pre vaše cieľové dopyty. Sledujte zmienky entít, citácie URL, presnosť faktov a popisy značky. Hľadajte trendy počas týždňov/mesiacov.
JSON-LD je odporúčaný formát pre väčšinu prípadov. Ľahšie sa implementuje, udržiava a nezasahuje do HTML. Microdata a RDFa sú v moderných implementáciách menej bežné.
Sledujte, ako AI systémy citujú vašu značku naprieč ChatGPT, Gemini, Perplexity a Google AI Overviews. Získajte prehľad o tom, ktoré typy schém zvyšujú vašu viditeľnosť.
Schema markup je štandardizovaný kód, ktorý pomáha vyhľadávačom pochopiť obsah. Zistite, ako štruktúrované dáta zlepšujú SEO, umožňujú rozšírené výsledky a podp...

Diskusia komunity o tom, či Article Schema a štruktúrované dáta skutočne ovplyvňujú AI citácie v ChatGPT, Perplexity a Google AI Overviews.
Diskusia komunity o schema markup pre AI viditeľnosť. Skutočné skúsenosti vývojárov a SEO odborníkov s tým, ktoré typy štruktúrovaných dát zlepšujú AI citácie....
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.