
Token
Zistite, čo sú tokeny v jazykových modeloch. Tokeny sú základné jednotky spracovania textu v AI systémoch, ktoré predstavujú slová, podslová alebo znaky ako čís...
10 min čítania

Preskúmajte, ako limity tokenov ovplyvňujú výkon AI a naučte sa praktické stratégie optimalizácie obsahu vrátane RAG, delenia a techník sumarizácie.
Tokeny sú základnými stavebnými kameňmi, ktoré AI modely používajú na spracovanie a pochopenie informácií. Namiesto práce s celými slovami alebo vetami rozkladajú veľké jazykové modely text na menšie jednotky nazývané tokeny, ktoré môžu byť samostatné znaky, podslová alebo celé slová v závislosti od algoritmu tokenizácie. Každému tokenu je priradený jedinečný číselný identifikátor, ktorý model interne používa na výpočty. Tento proces tokenizácie je nevyhnutný, pretože umožňuje AI systémom efektívne spracúvať vstupy s rôznou dĺžkou a zachovať konzistentné spracovanie naprieč rôznymi typmi obsahu. Pochopenie tokenov je kľúčové pre každého, kto pracuje s AI systémami, pretože priamo ovplyvňujú výkon, náklady a kvalitu výsledkov, ktoré môžete dosiahnuť.
Rôzne AI modely majú výrazne odlišné limity tokenov, ktoré určujú maximálne množstvo informácií, ktoré môžu spracovať v jednej požiadavke. Tieto limity sa v posledných rokoch dramaticky vyvíjali a novšie modely podporujú výrazne väčšie kontextové okná. Limit tokenov zahŕňa vstupné tokeny (váš prompt a dáta) aj výstupné tokeny (odpoveď modelu), čím vzniká spoločný rozpočet, ktorý treba starostlivo riadiť. Pochopenie týchto limitov je nevyhnutné na výber správneho modelu pre váš prípad použitia a plánovanie architektúry aplikácie.
| Model | Limit tokenov | Hlavný prípad použitia | Úroveň nákladov |
|---|---|---|---|
| GPT-3.5 Turbo | 4 096 | Krátke konverzácie, rýchle úlohy | Nízka |
| GPT-4 | 8 192 | Štandardné aplikácie, stredná zložitosť | Stredná |
| GPT-4 Turbo | 128 000 | Dlhé dokumenty, komplexná analýza | Vysoká |
| Claude 3.5 Sonnet | 200 000 | Rozsiahle dokumenty, komplexná analýza | Vysoká |
| Gemini 1.5 Pro | 1 000 000 | Masívne dátové sady, celé knihy, analýza videa | Veľmi vysoká |
Kľúčové aspekty pri hodnotení limitov tokenov:
Limity tokenov predstavujú významné obmedzenia, ktoré priamo ovplyvňujú presnosť, spoľahlivosť a nákladovú efektívnosť AI aplikácií. Ak prekročíte limit tokenov modelu, aplikácia úplne zlyhá—neexistuje žiadna postupná degradácia alebo čiastočné spracovanie. Aj keď zostanete v rámci limitov, naivné prístupy ako jednoduché skracovanie môžu výrazne zhoršiť výkon odstránením dôležitého kontextu, ktorý model potrebuje na generovanie presných odpovedí. Toto je obzvlášť problém v oblastiach ako právna analýza, medicínsky výskum či softvérové inžinierstvo, kde môže vynechanie aj jediného dôležitého detailu viesť k nesprávnym záverom. Výzva je ešte zložitejšia, ak vezmete do úvahy, že rôzne typy obsahu spotrebúvajú tokeny rôznym tempom—štruktúrované dáta ako kód alebo JSON vyžadujú podstatne viac tokenov než obyčajný anglický text kvôli symbolom a formátovaniu.
Skracovanie je najjednoduchšia metóda na riešenie limitov tokenov—jednoducho odstránite prebytočný obsah, ak prekračuje kapacitu modelu. Tento prístup sa ľahko implementuje, no nesie so sebou značné riziká. Pri skracovaní textu nevyhnutne prídete o informácie a model nemá spôsob zistiť, čo bolo odstránené. To môže viesť k neúplnej analýze, chýbajúcemu kontextu a halucináciám, keď model generuje vierohodne znejúce, ale nesprávne informácie na vyplnenie medzier vo svojom chápaní.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
Sofistikovanejšia stratégia skracovania rozlišuje medzi podstatným a voliteľným obsahom. Môžete uprednostniť nevyhnutné prvky, ako je aktuálna požiadavka používateľa a hlavné inštrukcie, a až následne pridať voliteľný kontext, napríklad históriu konverzácie, ak to kapacita dovolí. Takto zachováte kľúčové informácie a zároveň rešpektujete limity tokenov.
Namiesto skracovania rozdeľuje chunking váš obsah na menšie, zvládnuteľné časti, ktoré sa dajú spracovať samostatne alebo selektívne. Chunking s pevnou veľkosťou delí text na rovnomerné segmenty, zatiaľ čo sémantické delenie používa embeddingy na identifikáciu prirodzených deliacich bodov na základe významu, nie arbitrárneho počtu tokenov. Posuvné okná s prekrývaním zachovávajú kontext medzi chunkmi, aby sa dôležité informácie na hraniciach chunkov nestratili.
Hierarchický chunking vytvára viacero úrovní abstrakcie—jednotlivé odstavce na najnižšej úrovni, sekcie na ďalšej úrovni a kapitoly na najvyššej úrovni. Tento prístup umožňuje sofistikované vyhľadávacie stratégie, kde môžete rýchlo identifikovať relevantné sekcie bez potreby spracovať celý dokument. V kombinácii s vektorovými databázami a sémantickým vyhľadávaním sa chunking stáva mocným nástrojom na správu veľkých znalostných báz pri zachovaní relevantnosti a presnosti.
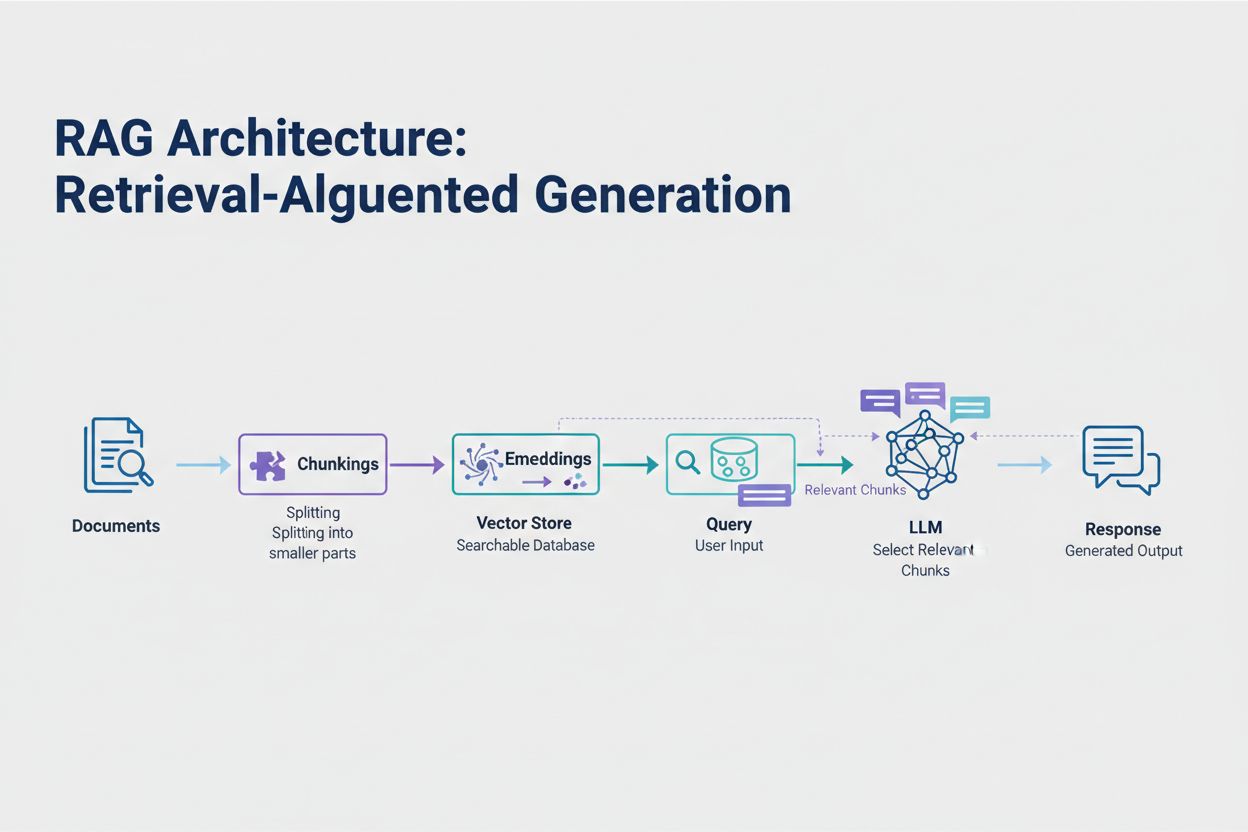
Retrieval-Augmented Generation (RAG) predstavuje najefektívnejší moderný prístup k zvládaniu limitov tokenov. Namiesto snahy zmestiť všetky dáta do kontextového okna modelu RAG získava len tie najrelevantnejšie informácie v čase dotazu. Proces začína konverziou vašich dokumentov na embeddingy—číselné reprezentácie, ktoré vystihujú sémantický význam. Tieto embeddingy sú uložené vo vektorovej databáze, čo umožňuje rýchle vyhľadávanie podobností.
Keď používateľ odošle dotaz, systém ho skonvertuje na embedding a načíta najrelevantnejšie časti dokumentu z vektorového úložiska. Do promptu sa vložia len tieto relevantné časti spolu s otázkou používateľa, čím sa dramaticky znižuje spotreba tokenov a zároveň zvyšuje presnosť. Napríklad analýza 100-stranovej právnej zmluvy pomocou RAG môže vyžadovať len 3-5 kľúčových klauzúl v promte, namiesto tisícov tokenov potrebných na zahrnutie celého dokumentu.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
Sumarizácia zhustí rozsiahly obsah pri zachovaní podstatných informácií, čím efektívne znižuje spotrebu tokenov. Extraktívna sumarizácia vyberá kľúčové vety z pôvodného textu, zatiaľ čo abstraktívna sumarizácia generuje nový, stručný text, ktorý vystihuje hlavné myšlienky. Hierarchická sumarizácia vytvára viacero úrovní súhrnov—najprv sumarizuje jednotlivé sekcie, potom tieto súhrny kombinuje do vyšších prehľadov. Tento prístup je obzvlášť vhodný pre štruktúrované dokumenty ako vedecké články či technické správy.
Komprimácia kontextu ide iným smerom—odstraňuje redundantný a zbytočný obsah, no zachováva pôvodné znenie. Prístupy založené na znalostných grafoch extrahujú entity a vzťahy z textu a následne rekonštruujú kontext len s najrelevantnejšími faktami. Tieto techniky môžu dosiahnuť 40-60 % zníženie tokenov pri zachovaní sémantickej presnosti, čo ich robí cennými pre optimalizáciu nákladov v produkčných systémoch.
Riadenie tokenov priamo ovplyvňuje náklady vašej AI aplikácie. Každý token spotrebovaný počas inferencie zvyšuje vaše náklady a tie rastú lineárne so spotrebou tokenov. Monitorovanie spotreby tokenov je nevyhnutné na pochopenie vašej nákladovej štruktúry a identifikovanie možností optimalizácie. Mnohé AI platformy dnes ponúkajú nástroje na počítanie tokenov a dashboardy na sledovanie spotreby v reálnom čase, ktoré vám pomôžu zistiť, ktoré dotazy alebo funkcie spotrebúvajú najviac tokenov.
Efektívny monitoring odhaľuje príležitosti na optimalizáciu—možno určitý typ dotazov pravidelne prekračuje limity tokenov alebo konkrétne funkcie spotrebúvajú neprimerane veľa zdrojov. Sledovaním týchto vzorcov môžete robiť informované rozhodnutia o tom, ktorú optimalizačnú stratégiu implementovať. Niektoré aplikácie profitujú z presmerovania veľkých požiadaviek na schopnejšie (ale drahšie) modely, iné viac z implementácie RAG alebo sumarizácie. Kľúčom je merať skutočný výkon a náklady na overenie efektívnosti vašich rozhodnutí.
Výber správnej stratégie riadenia tokenov závisí od vášho konkrétneho prípadu použitia, požiadaviek na výkon a rozpočtových obmedzení. Aplikácie, ktoré vyžadujú vysokú presnosť a zdrojované odpovede, najviac profitujú z RAG, ktorý zachováva vernosť informácií a zároveň riadi spotrebu tokenov. Dlhodobé konverzačné aplikácie profitujú z techník bufferovania pamäte, ktoré sumarizujú históriu konverzácie a zároveň uchovávajú kľúčové rozhodnutia a kontext. Aplikácie s množstvom dokumentov, ako právna analýza či výskumné nástroje, často profitujú z hierarchickej sumarizácie v kombinácii so sémantickým chunkingom.
Testovanie a validácia sú kritické pred nasadením akejkoľvek stratégie riadenia tokenov do produkcie. Vytvorte testovacie prípady, ktoré prekračujú limity tokenov vášho modelu, a vyhodnoťte, ako rôzne stratégie ovplyvňujú presnosť, latenciu a náklady. Merajte metriky ako relevantnosť odpovedí, faktická presnosť a efektivita tokenov, aby ste sa uistili, že zvolený prístup spĺňa vaše požiadavky. Bežné úskalia zahŕňajú príliš agresívnu sumarizáciu, ktorá stráca podstatné detaily, vyhľadávacie systémy, ktoré prehliadnu relevantné informácie, a chunkovacie stratégie, ktoré delia obsah na nesprávnych miestach z hľadiska významu.
Limity tokenov sa naďalej rozširujú, ako sa modely stávajú sofistikovanejšími a efektívnejšími. Nové techniky ako sparse attention mechanizmy a efektívne transformery sľubujú zníženie výpočtových nákladov pri spracovaní veľkých kontextových okien. Multimodálne modely, ktoré spracúvajú text, obrázky, zvuk aj video súčasne, prinášajú nové výzvy a príležitosti v tokenizácii. Reasoning tokeny—špeciálne tokeny používané modelmi na “premýšľanie” o zložitých problémoch—predstavujú novú kategóriu spotreby tokenov, ktorá umožňuje sofistikovanejšie riešenie problémov, no vyžaduje dôkladné riadenie.
Trend je jasný: ako sa kontextové okná rozširujú a spracovanie tokenov sa stáva efektívnejším, úzke miesto sa presúva z kapacity na inteligentný výber obsahu. Budúcnosť patrí systémom, ktoré dokážu efektívne identifikovať a vyhľadávať najrelevantnejšie informácie z masívnych databáz znalostí, nie systémom, ktoré len spracúvajú väčšie objemy dát. To robí techniky ako RAG a sémantické vyhľadávanie čoraz dôležitejšími pre budovanie škálovateľných a nákladovo efektívnych AI aplikácií.
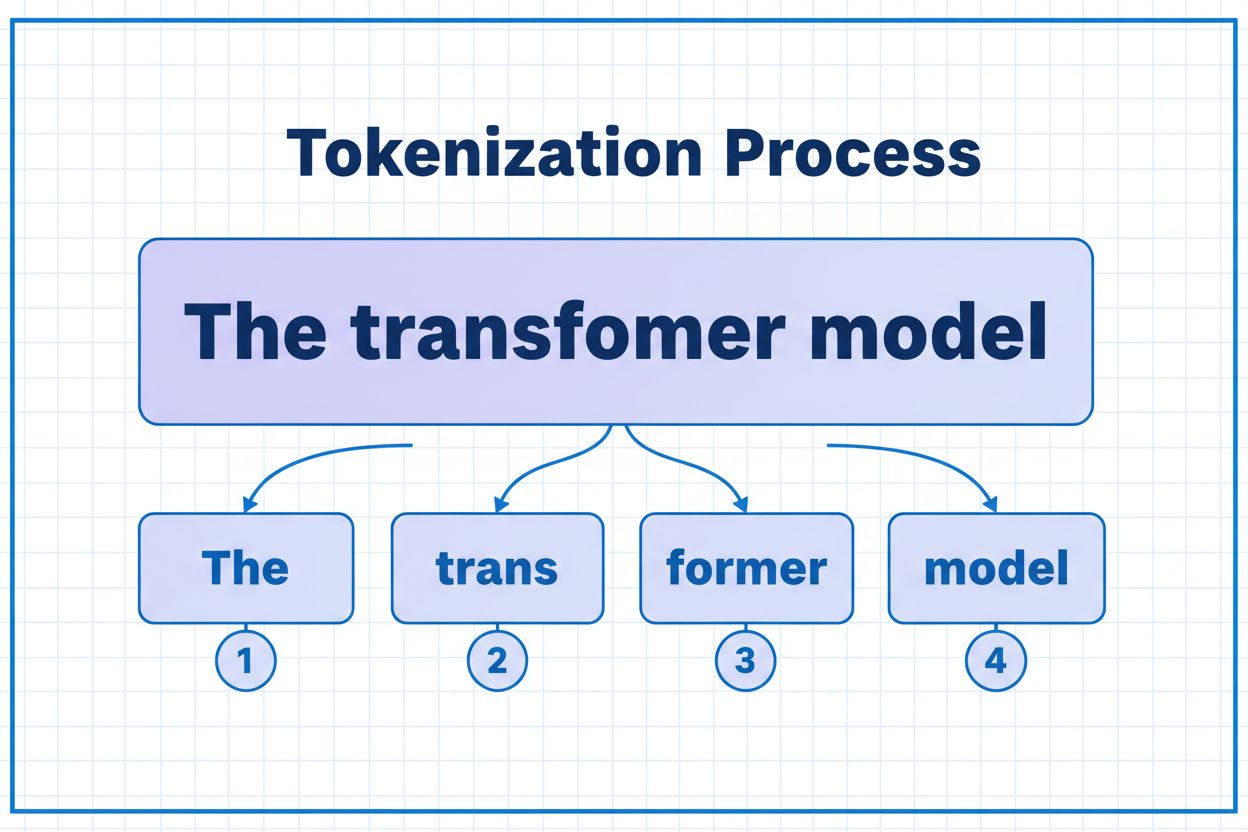
Token je najmenšia jednotka údajov, ktorú AI model spracúva. Tokeny môžu byť samostatné znaky, podslová alebo celé slová v závislosti od použitého algoritmu tokenizácie. Napríklad slovo 'transformer' môže byť rozdelené na 'trans' a 'former' ako dva samostatné tokeny. Každý token dostane jedinečný číselný identifikátor, ktorý model interne používa na výpočty.
Limity tokenov určujú maximálne množstvo informácií, ktoré váš AI model môže spracovať v jednej požiadavke. Ak tento limit prekročíte, aplikácia úplne zlyhá. Aj keď zostanete v rámci limitu, naivné prístupy ako skracovanie (truncation) môžu znížiť presnosť odstránením dôležitého kontextu. Limity tokenov tiež priamo ovplyvňujú náklady, keďže väčšinou platíte za každý spotrebovaný token.
Vstupné tokeny sú tokeny vo vašom zadaní a údajoch, ktoré posielate modelu, zatiaľ čo výstupné tokeny sú tie, ktoré model generuje vo svojej odpovedi. Tieto tokeny zdieľajú spoločný rozpočet určený veľkosťou kontextového okna modelu. Ak váš vstup využije 90 % z okna 128K tokenov, pre výstup modelu zostáva len 10 %.
Skracovanie je jednoduché na implementáciu, ale riskantné. Odstraňuje informácie bez toho, aby model vedel, čo bolo odstránené, čo vedie k neúplnej analýze a možným halucináciám. Hoci je užitočné v krajnom prípade, lepšie prístupy ako RAG, delenie obsahu (chunking) alebo sumarizácia zachovávajú vernosť informácií a zároveň efektívnejšie riadia spotrebu tokenov.
Retrieval-Augmented Generation (RAG) získava len najrelevantnejšie informácie v čase dotazu namiesto zahrnutia celých dokumentov. Vaše dokumenty sa konvertujú na embeddingy a ukladajú sa do vektorovej databázy. Pri dotaze používateľa systém načíta len relevantné časti a vloží ich do promptu, čím dramaticky znižuje spotrebu tokenov a zároveň zvyšuje presnosť.
Väčšina AI platforiem ponúka nástroje na počítanie tokenov a dashboardy na sledovanie spotreby v reálnom čase. Sledujte, ktoré dotazy alebo funkcie spotrebúvajú najviac tokenov, a potom implementujte optimalizačné stratégie ako RAG pre prácu s dokumentmi, sumarizáciu pre dlhé konverzácie alebo presmerovanie na väčšie modely pri zložitých úlohách. Merajte skutočný výkon a náklady na overenie vašich rozhodnutí.
AI služby zvyčajne účtujú poplatky za každý spotrebovaný token. Náklady rastú lineárne so spotrebou tokenov, takže optimalizácia tokenov má priamy vplyv na vaše výdavky. Zníženie spotreby tokenov o 20 % znamená zníženie nákladov o 20 %. Pochopenie efektivity tokenov vám pomáha zvoliť správnu optimalizačnú stratégiu v rámci vášho rozpočtu.
Limity tokenov sa naďalej rozširujú, ako sa modely stávajú sofistikovanejšími. Nové techniky ako sparse attention mechanizmy sľubujú zníženie výpočtových nákladov pri spracovaní veľkých kontextov. Budúcnosť sa zameriava na inteligentný výber a vyhľadávanie obsahu namiesto čistej výpočtovej kapacity, vďaka čomu sú techniky ako RAG čoraz dôležitejšie pre škálovateľné AI aplikácie.
Pochopte efektivitu tokenov a sledujte, ako AI modely citujú vašu značku s komplexnou platformou na monitoring AI citácií AmICited.
Zistite, čo sú tokeny v jazykových modeloch. Tokeny sú základné jednotky spracovania textu v AI systémoch, ktoré predstavujú slová, podslová alebo znaky ako čís...

Zistite, ako AI modely spracúvajú text prostredníctvom tokenizácie, embeddingov, transformačných blokov a neurónových sietí. Pochopte kompletný proces od vstupu...

Preskúmajte, ako AI systémy rozpoznávajú a spracúvajú entity v texte. Zistite viac o modeloch NER, architektúrach transformerov a reálnych aplikáciách porozumen...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.