Optimalizácia tréningových dát vs. vyhľadávanie v reálnom čase: Stratégie optimalizácie
Porovnajte optimalizáciu tréningových dát a stratégie vyhľadávania v reálnom čase pre AI. Zistite, kedy použiť fine-tuning a kedy RAG, aké sú náklady a hybridné prístupy pre optimálny výkon AI.
Publikované dňa Jan 3, 2026.Naposledy upravené dňa Jan 3, 2026 o 3:24 am
Optimalizácia tréningových dát a vyhľadávanie v reálnom čase predstavujú zásadne odlišné prístupy k vybaveniu AI modelov znalosťami. Optimalizácia tréningových dát znamená vloženie vedomostí priamo do parametrov modelu prostredníctvom fine-tuningu na doménovo špecifických datasetoch, čím vznikajú statické vedomosti, ktoré po ukončení tréningu zostávajú nemenné. Vyhľadávanie v reálnom čase naproti tomu ponecháva vedomosti externé voči modelu a získava relevantné informácie dynamicky počas inferencie, čo umožňuje prístup k dynamickým informáciám, ktoré sa môžu meniť medzi jednotlivými požiadavkami. Zásadný rozdiel spočíva v tom, kedy sú vedomosti integrované do modelu: optimalizácia tréningových dát prebieha pred nasadením, kým vyhľadávanie v reálnom čase počas každej inferencie. Tento základný rozdiel sa premieta do všetkých aspektov implementácie, od infraštruktúrnych požiadaviek cez charakteristiky presnosti až po otázky súladu. Pochopenie tohto rozdielu je kľúčové pre organizácie, ktoré sa rozhodujú, ktorá optimalizačná stratégia najlepšie zodpovedá ich konkrétnym potrebám a obmedzeniam.
Ako funguje optimalizácia tréningových dát
Optimalizácia tréningových dát funguje systematickým prispôsobovaním vnútorných parametrov modelu prostredníctvom vystavenia kurátorským, doménovo špecifickým datasetom počas procesu fine-tuningu. Keď model opakovane spracováva tréningové príklady, postupne si osvojuje vzorce, terminológiu a doménové znalosti prostredníctvom backpropagácie a aktualizácií gradientov, ktoré pretvárajú mechanizmy učenia modelu. Tento proces umožňuje organizáciám zakódovať špecializované znalosti—či už lekársku terminológiu, právne rámce alebo proprietárnu biznis logiku—priamo do váh a biasov modelu. Výsledný model je vysoko špecializovaný pre svoju cieľovú doménu a často dosahuje výkon porovnateľný s oveľa väčšími modelmi; výskum od Snorkel AI ukázal, že fine-tunované menšie modely môžu výkonovo dosiahnuť úroveň modelov 1 400-krát väčších. Kľúčové charakteristiky optimalizácie tréningových dát zahŕňajú:
Trvalá integrácia znalostí: Po tréningu sú znalosti súčasťou modelu, nie je potrebné externé vyhľadávanie
Znížená latencia inferencie: Žiadne režijné náklady na vyhľadávanie počas predikcie, rýchlejšie odpovede
Konzistentný štýl a formátovanie: Modely sa učia doménovo špecifické komunikačné vzorce a konvencie
Schopnosť offline prevádzky: Modely fungujú nezávisle bez externých zdrojov dát
Vysoké počiatočné náklady na výpočty: Vyžaduje značné GPU zdroje a prípravu označených tréningových dát
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
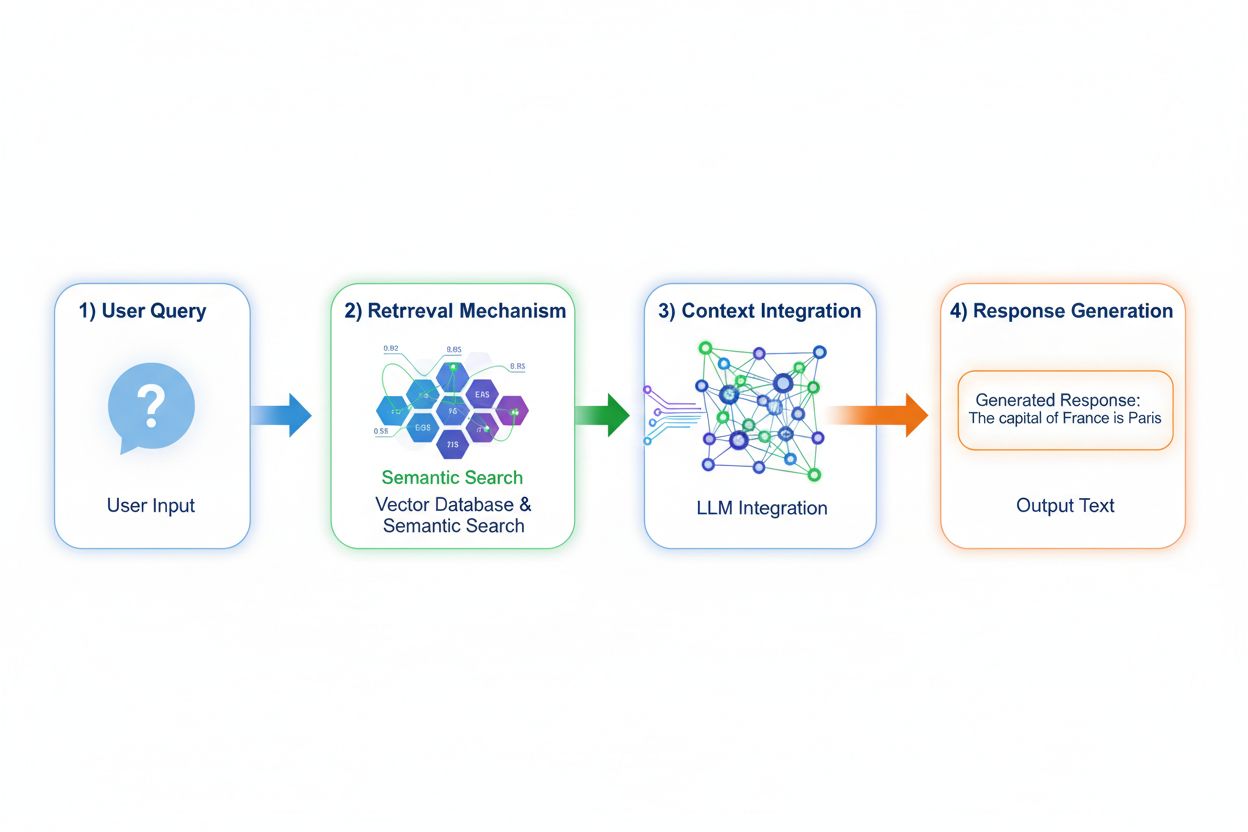
Retrieval Augmented Generation (RAG) zásadne mení spôsob, akým modely pristupujú k znalostiam, implementáciou štvorkrokového procesu: kódovanie dopytu, sémantické vyhľadávanie, hodnotenie kontextu a generovanie s ukotvením. Keď používateľ zadá dopyt, RAG ho najprv prevedie na hustú vektorovú reprezentáciu pomocou embedding modelov, následne prehľadáva vektorovú databázu obsahujúcu indexované dokumenty alebo zdroje znalostí. Fáza vyhľadávania využíva sémantické vyhľadávanie na nájdenie kontextuálne relevantných pasáží namiesto jednoduchého párovania kľúčových slov, pričom výsledky radí podľa skóre relevantnosti. Nakoniec model generuje odpovede s explicitnými odkazmi na získané zdroje, čím zakladá výstup na skutočných údajoch a nie naučených parametroch. Táto architektúra umožňuje modelom pristupovať k informáciám, ktoré počas tréningu neexistovali, a preto je RAG obzvlášť hodnotný pre aplikácie vyžadujúce aktuálne informácie, proprietárne dáta či často aktualizované znalostné bázy. Mechanizmus RAG v podstate premieňa model z pasívneho zdroja statických znalostí na dynamického syntetizátora informácií, ktorý vie inkorporovať nové dáta bez potreby pretrénovania.
Porovnanie výkonu a presnosti
Presnosť a profil halucinácií sa pri týchto prístupoch výrazne líšia, čo má zásadný vplyv na nasadenie v praxi. Optimalizácia tréningových dát vytvára modely s hlbokým pochopením domény, ale s obmedzenou schopnosťou priznať hranice svojich znalostí; ak fine-tunovaný model narazí na otázky mimo svojho tréningového rozdelenia, môže s istotou generovať zdanlivo správne, no chybné informácie. RAG výrazne znižuje halucinácie zakotvením odpovedí v získaných dokumentoch—model nemôže tvrdiť informácie, ktoré v zdrojovom materiáli neexistujú, čím vznikajú prirodzené obmedzenia vymýšľania. RAG však prináša iné riziká presnosti: ak vyhľadávacia fáza nenájde relevantné zdroje alebo vysoko hodnotí irelevantné dokumenty, model generuje odpovede na základe zlého kontextu. Aktuálnosť dát je pre systémy RAG kľúčová; optimalizácia tréningových dát zachytáva statický obraz znalostí v čase tréningu, zatiaľ čo RAG neustále odráža aktuálny stav zdrojových dokumentov. Pripisovanie zdrojov je ďalším rozdielom: RAG prirodzene umožňuje citovanie a overovanie tvrdení, zatiaľ čo fine-tunované modely nevedia ukázať konkrétny zdroj svojich znalostí, čo komplikuje fact-checking a overovanie súladu.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Náklady a infraštruktúrne dôsledky
Ekonomické profily týchto prístupov vytvárajú odlišné nákladové štruktúry, ktoré musia organizácie starostlivo posúdiť. Optimalizácia tréningových dát vyžaduje vysoké počiatočné výpočtové náklady: GPU clustre bežiace dni či týždne pre fine-tuning modelov, služby na anotáciu dát pri príprave označených datasetov a ML inžinierstvo na návrh efektívnych tréningových pipeline. Po natrénovaní sú prevádzkové náklady relatívne nízke, keďže inferencia si vyžaduje len štandardnú infraštruktúru bez externých požiadaviek. Systémy RAG majú opačnú štruktúru: nižšie počiatočné náklady bez potreby fine-tuningu, ale priebežné infraštruktúrne výdavky na údržbu vektorových databáz, embedding modelov, vyhľadávacích služieb a pipeline na indexáciu dokumentov. Kľúčové nákladové faktory zahŕňajú:
Fine-tuning: GPU hodiny (10 000 – 100 000+ USD za model), anotácia dát (0,50 – 5 USD za príklad), inžiniersky čas
Škálovateľnosť: Fine-tunované modely škálujú lineárne s objemom inferencie; RAG systémy škálujú aj s veľkosťou znalostnej bázy
Údržba: Fine-tuning vyžaduje periodické pretrénovanie; RAG kontinuálne aktualizáciu dokumentov a údržbu indexov
Bezpečnostné a compliance aspekty
Bezpečnostné a compliance dôsledky sa pri týchto prístupoch výrazne líšia, čo ovplyvňuje organizácie v regulovaných odvetviach. Fine-tunované modely vytvárajú výzvy v ochrane dát, pretože tréningové dáta sa zapíšu do váh modelu; zistiť alebo auditovať, aké znalosti model obsahuje, vyžaduje sofistikované postupy a vznikajú obavy o súkromie, ak správanie modelu ovplyvňujú citlivé tréningové dáta. Súlad s nariadeniami ako GDPR sa komplikuje, pretože model si „pamätá“ tréningové dáta spôsobmi, ktoré odolávajú vymazaniu či úprave. Systémy RAG ponúkajú odlišný bezpečnostný profil: znalosti zostávajú v externých, auditovateľných zdrojoch namiesto parametrov modelu, čo umožňuje jednoduché bezpečnostné opatrenia a obmedzenia prístupu. Organizácie môžu zaviesť detailné oprávnenia pre zdroje vyhľadávania, auditovať, ktoré dokumenty model použil na každú odpoveď, a rýchlo odstrániť citlivé informácie aktualizáciou zdrojových dokumentov bez pretrénovania. RAG však prináša riziká okolo ochrany vektorových databáz, bezpečnosti embedding modelov a zabezpečenia, že vyhľadané dokumenty neuniknú citlivé informácie. Zdravotnícke organizácie podliehajúce HIPAA a európske firmy podliehajúce GDPR často uprednostňujú transparentnosť a auditovateľnosť RAG, zatiaľ čo organizácie, ktoré vyžadujú prenositeľnosť modelu a offline fungovanie, preferujú sebestačný fine-tuning.
Praktický rozhodovací rámec
Výber medzi týmito prístupmi vyžaduje zhodnotenie špecifických organizačných obmedzení a charakteristík použitia. Organizácie by mali uprednostniť fine-tuning, ak sú znalosti stabilné a pravdepodobne sa nebudú často meniť, keď je zásadná nízka latencia inferencie, keď musia modely fungovať offline alebo v oddelených sieťach, alebo keď je dôležitý konzistentný štýl a doménové formátovanie. Vyhľadávanie v reálnom čase je vhodnejšie, keď sa znalosti pravidelne menia, keď je dôležité pripisovanie zdrojov a auditovateľnosť kvôli súladu, keď je znalostná báza príliš veľká na efektívne zakódovanie do parametrov modelu, alebo keď je potrebné aktualizovať informácie bez pretrénovania modelu. Konkrétne príklady použitia ilustrujú tieto rozdiely:
Fine-tuning: Chatboti zákazníckej podpory so stabilnými informáciami o produktoch, špecializovaní asistenti pre lekársku diagnostiku, analýza právnych dokumentov so stabilným judikatúrnym základom
RAG: Systémy sumarizácie správ vyžadujúce aktuálne udalosti, podpora zákazníkov s často aktualizovanými produktovými katalógmi, asistenti výskumu s prístupom k dynamickej vedeckej literatúre
Rozhodovací rámec: Zhodnoťte stabilitu znalostí, požiadavky na súlad, latenciu, frekvenciu aktualizácií a infraštruktúrne možnosti
Hybridné prístupy a kombinované stratégie
Hybridné prístupy kombinujú fine-tuning a RAG, aby využili výhody oboch stratégií a zároveň zmiernili ich individuálne obmedzenia. Organizácie môžu modely fine-tunovať na základné doménové znalosti a komunikačné vzorce a zároveň používať RAG na prístup k aktuálnym, detailným informáciám—model sa naučí ako premýšľať o doméne a zároveň vyhľadáva aké konkrétne fakty zaradiť. Táto kombinovaná stratégia sa osvedčila najmä pri aplikáciách vyžadujúcich špecializované know-how aj aktuálne informácie: napríklad finančný poradca fine-tunovaný na investičné princípy a terminológiu môže prostredníctvom RAG vyhľadávať aktuálne trhové údaje a firemné finančné výsledky. Reálne hybridné implementácie zahŕňajú zdravotnícke systémy, ktoré fine-tunujú na lekárske znalosti a protokoly a pacientsky špecifické údaje získavajú cez RAG, či právne výskumné platformy, ktoré fine-tunujú na právne uvažovanie a vyhľadávajú aktuálnu judikatúru. Synergické výhody zahŕňajú nižšiu mieru halucinácií (zakotvenie v získaných zdrojoch), lepšie porozumenie doméne (vďaka fine-tuningu), rýchlejšiu inferenciu pri bežných dotazoch (keďže znalosti sú v modeli) a flexibilitu aktualizovať špecializované informácie bez potreby pretrénovania. Organizácie čoraz častejšie využívajú tento optimalizačný prístup, ako sa výpočtové zdroje stávajú dostupnejšími a zložitosť reálnych aplikácií si vyžaduje hĺbku aj aktuálnosť poznatkov.
Monitoring AI odpovedí a sledovanie citácií
Schopnosť monitorovať AI odpovede v reálnom čase je čoraz dôležitejšia, keď organizácie zavádzajú tieto optimalizačné stratégie vo veľkom, najmä pre pochopenie, ktorý prístup prináša lepšie výsledky pre konkrétne prípady použitia. AI monitoring systémy sledujú výstupy modelu, kvalitu vyhľadávania a metriky spokojnosti užívateľov, čo umožňuje organizáciám merať, či ich aplikácie lepšie obsluhujú fine-tunované modely alebo systémy RAG. Sledovanie citácií odhaľuje zásadné rozdiely medzi prístupmi: RAG systémy prirodzene generujú citácie a odkazy na zdroje, vytvárajúc auditnú stopu, ktoré dokumenty ovplyvnili každú odpoveď, pričom fine-tunované modely neposkytujú inherentný mechanizmus na monitorovanie odpovedí alebo pripisovanie zdrojov. Tento rozdiel je dôležitý pre bezpečnosť značky a konkurenčnú inteligenciu—organizácie musia rozumieť, ako AI systémy citujú konkurenciu, referencujú ich produkty či pripisujú informácie zdrojom. Nástroje ako AmICited.com tento problém riešia monitorovaním, ako AI systémy citujú značky a firmy v rôznych optimalizačných stratégiách a poskytujú sledovanie citácií v reálnom čase. Zavedením komplexného monitoringu môžu organizácie merať, či ich zvolená optimalizačná stratégia (fine-tuning, RAG alebo hybrid) skutočne zlepšuje presnosť citácií, znižuje halucinácie o konkurencii a udržiava správne pripisovanie autoritatívnym zdrojom. Tento dátovo riadený prístup k monitoringu umožňuje neustále zdokonaľovanie optimalizačných stratégií na základe reálneho výkonu, nie len teoretických očakávaní.
Budúce trendy a nové vzory
Odvetvie smeruje k sofistikovanejším hybridným a adaptívnym prístupom, ktoré dynamicky vyberajú optimalizačné stratégie podľa charakteru dopytu a požiadaviek na znalosti. Objavujú sa nové best practices, ako je retrieval-augmented fine-tuning, kde sa modely fine-tunujú na efektívne využívanie získaných informácií namiesto memorovania faktov, a adaptívne routing systémy, ktoré smerujú dopyty na fine-tunované modely pre stabilné znalosti a na RAG pre dynamické informácie. Trendy ukazujú rastúce nasadenie špecializovaných embedding modelov a vektorových databáz optimalizovaných pre konkrétne domény, ktoré umožňujú presnejšie sémantické vyhľadávanie a znižujú šum pri vyhľadávaní. Organizácie si osvojujú vzory na kontinuálne zlepšovanie modelov, ktoré kombinujú periodické aktualizácie fine-tuningu s priebežnou RAG augmentáciou, čím vytvárajú systémy, ktoré sa časom zlepšujú a zároveň udržiavajú aktuálny prístup k informáciám. Evolúcia optimalizačných stratégií odráža širšie uznanie v odvetví, že žiadny jediný prístup nie je optimálny pre všetky prípady; budúce systémy pravdepodobne implementujú inteligentné selekčné mechanizmy, ktoré dynamicky volia medzi fine-tuningom, RAG a hybridným prístupom podľa kontextu dopytu, stability znalostí, latencie a compliance požiadaviek. Ako tieto technológie dozrievajú, konkurenčná výhoda sa bude presúvať od voľby jedného prístupu k expertnej implementácii adaptívnych systémov, ktoré využívajú silné stránky každej stratégie.
Najčastejšie kladené otázky
Aký je hlavný rozdiel medzi optimalizáciou tréningových dát a vyhľadávaním v reálnom čase?
Optimalizácia tréningových dát vkladá vedomosti priamo do parametrov modelu prostredníctvom fine-tuningu, čím vznikajú statické vedomosti, ktoré po tréningu zostávajú nemenné. Vyhľadávanie v reálnom čase ponecháva vedomosti externé a získava relevantné informácie dynamicky počas inferencie, čo umožňuje prístup k dynamickým informáciám, ktoré sa môžu medzi požiadavkami meniť. Základný rozdiel je v tom, kedy sú vedomosti integrované: optimalizácia tréningových dát prebieha pred nasadením, zatiaľ čo vyhľadávanie v reálnom čase pri každom volaní inferencie.
Kedy by som mal použiť fine-tuning namiesto RAG?
Fine-tuning využite vtedy, keď sú vedomosti stabilné a pravdepodobne sa nebudú často meniť, keď je zásadná nízka latencia inferencie, keď modely musia fungovať offline alebo keď je dôležitý konzistentný štýl a špecifické formátovanie pre danú doménu. Fine-tuning je ideálny pre špecializované úlohy ako lekárska diagnostika, analýza právnych dokumentov alebo zákaznícky servis so stabilnými produktovými informáciami. Fine-tuning však vyžaduje významné počiatočné výpočtové zdroje a stáva sa nepraktickým, ak sa informácie často menia.
Môžem kombinovať optimalizáciu tréningových dát s vyhľadávaním v reálnom čase?
Áno, hybridné prístupy kombinujú fine-tuning a RAG, aby využili výhody oboch stratégií. Organizácie môžu modely fine-tunovať na základné znalosti domény a súčasne využívať RAG na prístup k aktuálnym, detailným informáciám. Tento prístup je obzvlášť efektívny pre aplikácie vyžadujúce špecializované odborné znalosti aj aktuálne informácie, napríklad finančné poradenské boty alebo zdravotnícke systémy, ktoré potrebujú lekárske vedomosti aj údaje o konkrétnych pacientoch.
Ako RAG znižuje halucinácie v porovnaní s fine-tuningom?
RAG výrazne znižuje halucinácie tým, že odpovede zakladá na získaných dokumentoch—model nemôže tvrdiť informácie, ktoré sa v zdrojových materiáloch nenachádzajú, čím sa prirodzene obmedzuje vymýšľanie. Fine-tunované modely naopak môžu s istotou generovať zdanlivo správne, ale nesprávne informácie pri otázkach mimo ich tréningovej distribúcie. RAG tiež umožňuje overenie tvrdení vďaka zdrojom, zatiaľ čo fine-tunované modely nemôžu ukázať konkrétny zdroj svojich vedomostí.
Aké sú nákladové dôsledky jednotlivých prístupov?
Fine-tuning vyžaduje významné počiatočné náklady: GPU hodiny (10 000 - 100 000+ USD za model), anotáciu dát (0,50 - 5 USD za príklad) a inžiniersky čas. Po natrénovaní zostávajú náklady na prevádzku relatívne nízke. Systémy RAG majú nižšie počiatočné náklady, ale priebežné infraštruktúrne výdavky na vektorové databázy, embedding modely a vyhľadávacie služby. Fine-tunované modely škálujú lineárne s objemom inferencie, zatiaľ čo RAG škáluje aj s veľkosťou znalostnej bázy.
Ako pomáha vyhľadávanie v reálnom čase so sledovaním AI citácií?
Systémy RAG prirodzene generujú citácie a odkazy na zdroje, takže vytvárajú auditnú stopu, ktoré dokumenty ovplyvnili každú odpoveď. To je kľúčové pre bezpečnosť značky a konkurenčnú inteligenciu—organizácie môžu sledovať, ako AI systémy citujú ich konkurentov a referencujú ich produkty. Nástroje ako AmICited.com monitorujú, ako AI cituje značky v rôznych optimalizačných stratégiách a poskytujú sledovanie citácií v reálnom čase.
Ktorý prístup je lepší pre odvetvia s prísnymi požiadavkami na súlad?
RAG je vo všeobecnosti lepší pre odvetvia s vysokými požiadavkami na súlad, ako zdravotníctvo a financie. Vedomosti zostávajú v externých, auditovateľných zdrojoch dát namiesto parametrov modelu, čo umožňuje jednoduché bezpečnostné opatrenia a prístupové obmedzenia. Organizácie môžu zaviesť detailné oprávnenia, auditovať, ktoré dokumenty model použil, a rýchlo odstrániť citlivé informácie bez nutnosti pretrénovania. Zdravotnícke organizácie podliehajúce HIPAA a subjekty GDPR často uprednostňujú transparentnosť a auditovateľnosť RAG.
Ako môžem monitorovať efektivitu zvolenej optimalizačnej stratégie?
Implementujte AI monitorovacie systémy, ktoré sledujú výstupy modelu, kvalitu vyhľadávania a metriky spokojnosti používateľov. Pri RAG systémoch sledujte presnosť vyhľadávania a kvalitu citácií. Pri fine-tunovaných modeloch sledujte presnosť v doménovo špecifických úlohách a mieru halucinácií. Využite nástroje ako AmICited.com na monitorovanie, ako vaše AI systémy citujú informácie a porovnávajte výkon naprieč rôznymi optimalizačnými stratégiami podľa reálnych výsledkov.
Sledujte, ako AI systémy citujú vašu značku
Sledujte citácie v reálnom čase v GPTs, Perplexity a Google AI Overviews. Zistite, aké optimalizačné stratégie používajú vaši konkurenti a ako sú spomínaní v AI odpovediach.
Trénovacie dáta vs. živé vyhľadávanie: Ako AI systémy pristupujú k informáciám
Pochopte rozdiel medzi AI trénovacími dátami a živým vyhľadávaním. Zistite, ako ovplyvňujú znalostné ohraničenia, RAG a vyhľadávanie v reálnom čase viditeľnosť ...
Ako optimalizovať váš obsah pre tréningové dáta AI a AI vyhľadávače
Zistite, ako optimalizovať svoj obsah na zaradenie do tréningových dát AI. Objavte najlepšie praktiky, ako sprístupniť svoju webstránku ChatGPT, Gemini, Perplex...
Tréningové dáta vs. živé vyhľadávanie v AI – na čo by som mal vlastne optimalizovať?
Diskusia komunity o rozdiele medzi tréningovými dátami AI a živým vyhľadávaním (RAG). Praktické stratégie optimalizácie obsahu pre statické tréningové dáta aj p...
7 min čítania
Discussion
Training Data
+1
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.