
Vstavané vektory (Embedding)
Zistite, čo sú embeddingy, ako fungujú a prečo sú nevyhnutné pre AI systémy. Objavte, ako sa text premieňa na číselné vektory, ktoré zachytávajú sémantický význ...
11 min čítania

Zistite, ako vektorové embeddingy umožňujú AI systémom chápať sémantický význam a priraďovať obsah k dopytom. Preskúmajte technológiu za sémantickým vyhľadávaním a priraďovaním obsahu v AI.

Vektorové embeddingy sú číselným základom, ktorý poháňa moderné systémy umelej inteligencie a premieňa surové dáta na matematické reprezentácie, ktorým stroje rozumejú a dokážu ich spracovať. V jadre embeddingy prevádzajú text, obrázky, zvuk a iné typy obsahu na polia čísel—zvyčajne s desiatkami až tisíckami rozmerov—ktoré zachytávajú sémantický význam a kontextové vzťahy v týchto dátach. Táto číselná reprezentácia je základom toho, ako AI systémy vykonávajú priraďovanie obsahu, sémantické vyhľadávanie a odporúčacie úlohy, vďaka čomu stroje chápu nielen to, aké slová alebo obrázky sú prítomné, ale aj čo vlastne znamenajú. Bez embeddingov by AI systémy ťažko pochopili nuansované vzťahy medzi konceptmi, preto sú kľúčovou infraštruktúrou pre každú modernú AI aplikáciu.
Premenu zo surových dát na vektorové embeddingy realizujú sofistikované neurónové siete trénované na obrovských datasetoch, aby sa naučili zmysluplné vzory a vzťahy. Keď vložíte text do embeddingového modelu, prechádza viacerými vrstvami neurónových sietí, ktoré postupne extrahujú sémantické informácie a nakoniec vytvoria vektor s pevnou veľkosťou, ktorý reprezentuje podstatu obsahu. Populárne embeddingové modely ako Word2Vec, GloVE a BERT používajú rôzne prístupy—Word2Vec využíva plytké neurónové siete optimalizované na rýchlosť, GloVE kombinuje globálnu maticovú faktorizáciu s lokálnymi kontextovými oknami, zatiaľ čo BERT využíva transformerovú architektúru na pochopenie obojsmerného kontextu.
| Model | Typ dát | Rozmery | Primárny účel | Hlavná výhoda |
|---|---|---|---|---|
| Word2Vec | Text (slová) | 100-300 | Vzťahy medzi slovami | Rýchly, efektívny |
| GloVE | Text (slová) | 100-300 | Sémantické vzťahy | Kombinuje globálny a lokálny kontext |
| BERT | Text (vety/dokumenty) | 768-1024 | Kontextové porozumenie | Obojsmerná znalosť kontextu |
| Sentence-BERT | Text (vety) | 384-768 | Podobnosť viet | Optimalizované pre sémantické vyhľadávanie |
| Universal Sentence Encoder | Text (vety) | 512 | Viacjazyčné úlohy | Jazykovo nezávislé |
Tieto modely vytvárajú vysokodimenzionálne vektory (často 300 až 1 536 rozmerov), pričom každý rozmer zachytáva iný aspekt významu—od gramatických vlastností až po konceptuálne vzťahy. Krása tejto číselnej reprezentácie spočíva v tom, že umožňuje matematické operácie—vektory môžete sčítať, odčítať a porovnávať, čím objavujete vzťahy, ktoré by v surovom texte zostali skryté. Tento matematický základ umožňuje sémantické vyhľadávanie a inteligentné priraďovanie obsahu vo veľkom rozsahu.
Skutočná sila embeddingov sa ukazuje vďaka sémantickej podobnosti, teda schopnosti rozpoznať, že rôzne slová či frázy môžu vektorovo znamenať v podstate to isté. Ak sú embeddingy vytvorené správne, sémanticky podobné koncepty sa prirodzene zhlukujú vo vysoko-dimenzionálnom priestore—“kráľ” a “kráľovná” sú si blízko, rovnako ako “auto” a “vozidlo”, aj keď ide o rôzne slová. Na meranie tejto podobnosti používajú AI systémy metriky vzdialenosti ako kosínovú podobnosť (uhol medzi vektormi) alebo skalárny súčin (veľkosť a smer), ktoré kvantifikujú, ako blízko sú si dva embeddingy. Napríklad dopyt na “automobilovú dopravu” bude mať vysokú kosínovú podobnosť s dokumentmi o “cestovaní autom”, čo umožňuje systému priraďovať obsah podľa významu a nie len podľa kľúčových slov. Toto sémantické porozumenie odlišuje moderné AI vyhľadávanie od jednoduchého porovnávania kľúčových slov a umožňuje systémom pochopiť zámer používateľa a dodať skutočne relevantné výsledky.
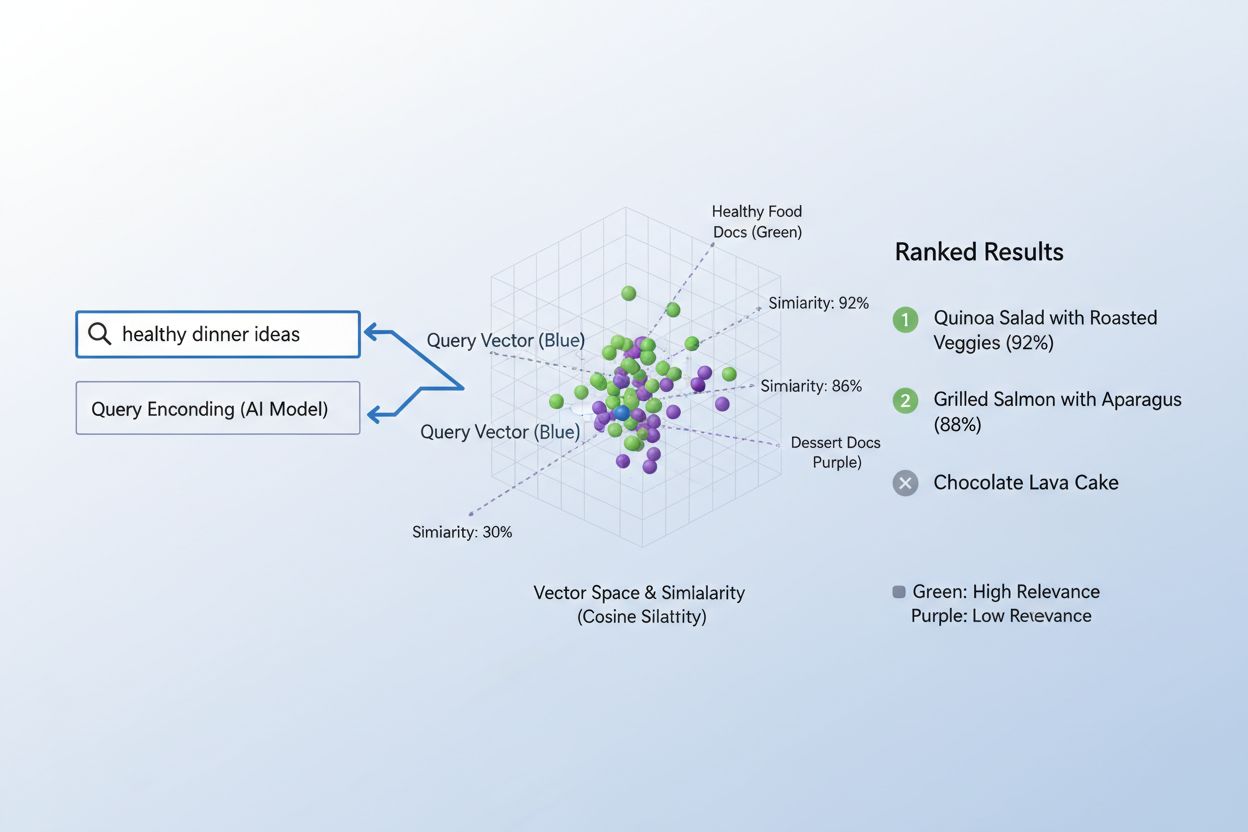
Proces priraďovania obsahu k dopytom pomocou embeddingov prebieha v elegantnom dvojkrokovom pracovnom postupe, ktorý poháňa všetko od vyhľadávačov až po odporúčacie systémy. Najprv sa dopyt používateľa aj dostupný obsah nezávisle prevedú na embeddingy pomocou rovnakého modelu—dopyt ako “najlepšie postupy pre strojové učenie” sa stane vektorom, rovnako ako každý článok, dokument či produkt v databáze systému. Následne systém vypočíta podobnosť medzi embeddingom dopytu a embeddingami obsahu, obvykle pomocou kosínovej podobnosti, ktorá vráti skóre relevancie každého obsahu k dopytu. Tieto skóre sa zoradia a najrelevantnejší obsah sa zobrazí používateľovi na vrchu výsledkov. V reálnom vyhľadávači, keď zadáte “ako trénovať neurónové siete”, systém zakóduje váš dopyt, porovná ho s miliónmi embeddingov dokumentov a vráti články o deep learningu, optimalizácii modelov či tréningových technikách—všetko bez nutnosti presnej zhodnosti kľúčových slov. Tento proces priraďovania prebieha v milisekundách, takže je praktický pre aplikácie v reálnom čase pre milióny používateľov zároveň.
Rôzne typy embeddingov slúžia rôznym účelom v závislosti od toho, čo chcete priraďovať alebo pochopiť. Slovné embeddingy zachytávajú význam jednotlivých slov a sú vhodné pre úlohy, kde je potrebné jemné sémantické rozlíšenie, zatiaľ čo vetné embeddingy a dokumentové embeddingy agregujú význam cez dlhšie texty, takže sú ideálne na priraďovanie celkových dopytov k celým článkom alebo dokumentom. Obrázkové embeddingy číselne reprezentujú vizuálny obsah, vďaka čomu systémy nájdu vizuálne podobné obrázky alebo priradia obrázky k textovým popisom, zatiaľ čo používateľské a produktové embeddingy zachytávajú správanie a vlastnosti, čím poháňajú odporúčacie systémy, ktoré navrhujú položky podľa preferencií používateľa. Výber medzi týmito typmi embeddingov si vyžaduje kompromisy: slovné embeddingy sú výpočtovo nenáročné, ale strácajú kontext, zatiaľ čo dokumentové embeddingy zachovávajú plný význam, no vyžadujú viac výkonu. Doménovo špecifické embeddingy, doladené na špecializovaných datasetoch, ako je medicína či právo, často prekonávajú univerzálne modely v odvetvových aplikáciách, hoci si vyžadujú viac tréningových dát a výpočtových zdrojov.
V praxi embeddingy poháňajú najvplyvnejšie AI aplikácie, ktoré denne používame—od výsledkov vyhľadávania cez odporúčané produkty na internete. Sémantické vyhľadávače využívajú embeddingy na pochopenie zámeru dopytu a zobrazujú relevantný obsah bez ohľadu na presné kľúčové slová, zatiaľ čo odporúčacie systémy Netflixu, Amazonu či Spotify využívajú embeddingy používateľov a položiek na predpovedanie, čo si budete chcieť pozrieť, kúpiť alebo vypočuť. Systémy na moderáciu obsahu používajú embeddingy na detekciu škodlivého obsahu porovnávaním príspevkov s embeddingmi známych porušení pravidiel, zatiaľ čo systémy otázka-odpoveď priraďujú otázky používateľov k relevantným článkom v znalostnej báze na základe sémantickej podobnosti. Personalizačné motory využívajú embeddingy na pochopenie preferencií používateľov a prispôsobenie zážitku a systémy detekcie anomálií rozpoznávajú nezvyčajné vzory, keď nové dáta spadajú ďaleko od očakávaných embeddingových zhlukov. V AmICited využívame embeddingy na monitoring využitia AI systémov na internete, priraďovanie dopytov a obsahu na sledovanie výskytu AI-generovaného či AI-asistovaného obsahu, čo pomáha značkám pochopiť ich AI stopu a zabezpečiť správne pripisovanie.
Efektívna implementácia embeddingov si vyžaduje dôkladnú pozornosť viacerým technickým aspektom, ktoré ovplyvňujú výkon aj náklady. Výber modelu je kľúčový—musíte vyvážiť sémantickú kvalitu embeddingov s výpočtovými požiadavkami, pričom väčšie modely ako BERT vytvárajú bohatšie reprezentácie, ale vyžadujú viac výkonu než ľahšie alternatívy. Dimenzionalita predstavuje zásadný kompromis: vyššie rozmerné embeddingy zachytia viac nuans, ale spotrebujú viac pamäte a spomaľujú výpočty podobnosti, zatiaľ čo nižšie rozmerné embeddingy sú rýchlejšie, ale môžu stratiť dôležité sémantické informácie. Na efektívne vyhľadávanie vo veľkých objemoch sa používajú špeciálne indexačné stratégie ako FAISS (Facebook AI Similarity Search) alebo Annoy (Approximate Nearest Neighbors Oh Yeah), ktoré umožňujú nájsť podobné embeddingy v milisekundách namiesto sekúnd, vďaka organizácii vektorov v stromových štruktúrach alebo schémach lokálne citlivého hashovania. Dolaďovanie embeddingových modelov na doménovo špecifických dátach dokáže dramaticky zvýšiť relevantnosť pre špecializované aplikácie, no vyžaduje si označené tréningové dáta a ďalšiu výpočtovú záťaž. Organizácie musia neustále vyvažovať rýchlosť verzus presnosť, výpočtové náklady verzus sémantickú kvalitu a univerzálne modely verzus špecializované alternatívy podľa konkrétnych potrieb a obmedzení.
Budúcnosť embeddingov smeruje k väčšej sofistikovanosti, efektivite a integrácii so širšími AI systémami, čo sľubuje ešte výkonnejšie možnosti priraďovania a porozumenia obsahu. Objavujú sa multimodálne embeddingy, ktoré naraz spracúvajú text, obrázky a zvuk, vďaka čomu systémy vedia priraďovať medzi rôznymi typmi obsahu—nájsť obrázky relevantné k textovým dopytom a naopak—čo otvára úplne nové možnosti objavovania a chápania obsahu. Vedci vyvíjajú čoraz efektívnejšie embeddingové modely, ktoré poskytujú porovnateľnú sémantickú kvalitu s oveľa menším počtom parametrov, čím robia pokročilé AI schopnosti dostupné aj pre menšie organizácie a edge zariadenia. Integrácia embeddingov s veľkými jazykovými modelmi vytvára systémy, ktoré dokážu nielen sémanticky priraďovať obsah, ale aj chápať kontext, nuansy a zámer na nebývalej úrovni. Ako sa AI systémy rozširujú na internete, schopnosť sledovať, monitorovať a pochopiť, ako sa obsah priraďuje a používa, je čoraz dôležitejšia—a práve tu platformy ako AmICited využívajú embeddingy na pomoc organizáciám pri monitorovaní prítomnosti značky, sledovaní vzorcov využívania AI a zabezpečení správneho pripisovania a vhodného použitia obsahu. Splynutie lepších embeddingov, efektívnejších modelov a sofistikovaných monitoringových nástrojov vytvára budúcnosť, v ktorej budú AI systémy transparentnejšie, zodpovednejšie a viac v súlade s ľudskými hodnotami.
Vektorový embedding je číselná reprezentácia dát (text, obrázky, audio) vo vysoko-dimenzionálnom priestore, ktorá zachytáva sémantický význam a vzťahy. Prevod abstraktných dát na pole čísel umožňuje ich matematické spracovanie a analýzu strojom.
Embeddingy prevádzajú abstraktné dáta na čísla, ktoré stroje dokážu spracovať, čím umožňujú AI rozpoznať vzory, podobnosti a vzťahy medzi rôznymi časťami obsahu. Táto matematická reprezentácia umožňuje AI systémom chápať význam, nielen porovnávať kľúčové slová.
Zhoda kľúčových slov hľadá presné zhody slov, zatiaľ čo sémantická podobnosť chápe význam. To umožňuje nájsť súvisiaci obsah aj bez rovnakých slov—napríklad priradiť 'automobil' k 'auto' na základe sémantického vzťahu, nie presnej textovej zhody.
Áno, embeddingy môžu reprezentovať text, obrázky, zvuk, používateľské profily, produkty a ďalšie. Rôzne embeddingové modely sú optimalizované pre rôzne typy dát, od Word2Vec pre text po CNN pre obrázky či spektrogramy pre audio.
AmICited používa embeddingy na pochopenie, ako AI systémy sémanticky priraďujú a odkazujú na vašu značku naprieč rôznymi AI platformami a odpoveďami. To pomáha sledovať prítomnosť vášho obsahu v AI-generovaných odpovediach a zabezpečiť správne pripisovanie.
Kľúčové výzvy zahŕňajú výber správneho modelu, zvládanie výpočtových nárokov, prácu s vysoko-dimenzionálnymi dátami, dolaďovanie pre konkrétne domény a vyváženie rýchlosti verzus presnosť pri výpočtoch podobnosti.
Embeddingy umožňujú sémantické vyhľadávanie, ktoré chápe zámer používateľa a vracia relevantné výsledky na základe významu, nie len zhody kľúčových slov. Tak vyhľadávače nachádzajú konceptuálne súvisiaci obsah aj bez presných výrazov z dopytu.
Veľké jazykové modely používajú embeddingy interne na pochopenie a generovanie textu. Embeddingy sú základom toho, ako tieto modely spracúvajú informácie, priraďujú obsah a vytvárajú kontextovo vhodné odpovede.
Vektorové embeddingy poháňajú AI systémy ako ChatGPT, Perplexity a Google AI Overviews. AmICited sleduje, ako tieto systémy citujú a spomínajú váš obsah, aby ste lepšie chápali prítomnosť vašej značky v AI-generovaných odpovediach.
Zistite, čo sú embeddingy, ako fungujú a prečo sú nevyhnutné pre AI systémy. Objavte, ako sa text premieňa na číselné vektory, ktoré zachytávajú sémantický význ...

Zistite, ako embeddingy fungujú vo vyhľadávačoch s umelou inteligenciou a jazykových modeloch. Pochopte vektorové reprezentácie, sémantické vyhľadávanie a ich ú...
Zistite, ako vektorové vyhľadávanie využíva embeddingy strojového učenia na vyhľadávanie podobných položiek na základe významu, nie len presných kľúčových slov....