
Vyhľadávací zámer
Vyhľadávací zámer je účel za používateľovým vyhľadávacím dopytom. Zistite štyri typy vyhľadávacieho zámeru, ako ich identifikovať a optimalizovať obsah pre lepš...
11 min čítania
Zistite, ako veľké jazykové modely interpretujú používateľský zámer nad rámec kľúčových slov. Objavte rozširovanie dopytov, sémantické porozumenie a spôsob, akým AI systémy určujú, ktorý obsah citovať vo svojich odpovediach.
Používateľský zámer vo vyhľadávaní pomocou AI označuje základný cieľ alebo účel za dopytom, nie len kľúčové slová, ktoré niekto zadá. Keď vyhľadávate napríklad “najlepšie nástroje na správu projektov”, môžete hľadať rýchle porovnanie, informácie o cenách alebo možnosti integrácie—a veľké jazykové modely (LLM) ako ChatGPT, Perplexity a Gemini od Google sa snažia pochopiť, ktorý z týchto cieľov vlastne sledujete. Na rozdiel od tradičných vyhľadávačov, ktoré párujú kľúčové slová so stránkami, LLM interpretujú sémantický význam vášho dopytu analýzou kontextu, formulácie a súvisiacich signálov, aby predpovedali, čo naozaj chcete dosiahnuť. Tento posun od párovania kľúčových slov k pochopeniu zámeru je zásadný pre fungovanie moderných AI vyhľadávacích systémov a priamo určuje, ktoré zdroje budú citované v AI-generovaných odpovediach. Pochopenie používateľského zámeru je kľúčové pre značky, ktoré chcú byť viditeľné vo výsledkoch AI vyhľadávania, keďže nástroje ako AmICited už monitorujú, ako AI systémy odkazujú na váš obsah na základe zosúladenia zámerov.
Keď zadáte jeden dopyt do AI vyhľadávacieho systému, v pozadí sa deje niečo pozoruhodné: model neodpovedá len priamo na vašu otázku. Namiesto toho rozšíri váš dopyt na desiatky súvisiacich mikro-otázok, čo výskumníci nazývajú “fan-out dopytu”. Napríklad jednoduché vyhľadávanie ako “Notion vs Trello” môže vyvolať poddotazy typu “Ktorý nástroj je lepší na tímovú spoluprácu?”, “Aké sú rozdiely v cene?”, “Ktorý sa lepšie integruje so Slackom?” a “Čo je jednoduchšie pre začiatočníkov?” Toto rozšírenie umožňuje LLM preskúmať rôzne uhly vášho zámeru a zhromaždiť komplexnejšie informácie pred vygenerovaním odpovede. Systém potom hodnotí pasáže z rôznych zdrojov na detailnej úrovni, nie celé stránky naraz, takže môže byť vybratý iba jeden odsek z vášho obsahu, zatiaľ čo zvyšok stránky je ignorovaný. Táto analýza na úrovni pasáží je dôvodom, prečo je jasnosť a konkrétnosť v každej sekcii dôležitejšia než kedykoľvek predtým—dobre štruktúrovaná odpoveď na konkrétny podzámer môže byť dôvodom, prečo sa váš obsah dostane do AI-generovanej odpovede.
| Pôvodný dopyt | Podzámer 1 | Podzámer 2 | Podzámer 3 | Podzámer 4 |
|---|---|---|---|---|
| “Najlepšie nástroje na správu projektov” | “Ktorý je najlepší pre vzdialené tímy?” | “Aká je cena?” | “Ktorý sa integruje so Slackom?” | “Čo je najjednoduchšie pre začiatočníkov?” |
| “Ako zlepšiť produktivitu” | “Aké nástroje pomáhajú s time managementom?” | “Aké sú overené metódy produktivity?” | “Ako znížiť rozptýlenie?” | “Aké návyky podporujú sústredenie?” |
| “Vysvetlenie AI vyhľadávačov” | “Ako sa líšia od Google?” | “Ktorý AI vyhľadávač je najpresnejší?” | “Ako riešia súkromie?” | “Aká je budúcnosť AI vyhľadávania?” |
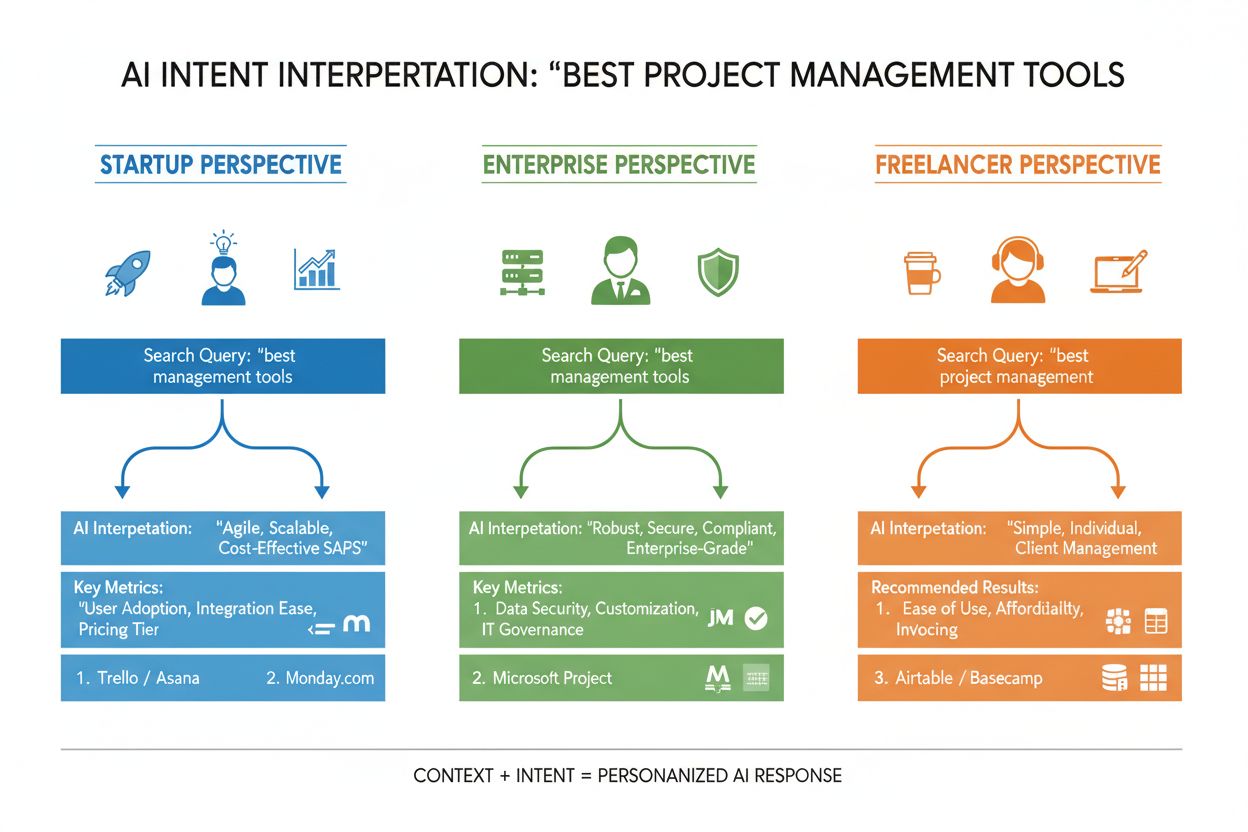
LLM neposudzujú váš dopyt izolovane—vytvárajú to, čo výskumníci nazývajú “embedding používateľa”, vektorový profil, ktorý zachytáva váš vyvíjajúci sa zámer na základe histórie vyhľadávania, polohy, typu zariadenia, času a dokonca aj predchádzajúcich konverzácií. Toto kontextové porozumenie umožňuje systému dramaticky personalizovať výsledky: dvaja používatelia vyhľadávajúci “najlepšie CRM nástroje” môžu dostať úplne odlišné odporúčania, ak je jeden zakladateľ startupu a druhý manažér veľkej firmy. Reálny čas preusporiadania výsledkov ďalej zužuje výber podľa toho, ako s nimi interagujete—ak klikáte na niektoré výsledky, venujete čas čítaniu konkrétnych sekcií alebo kladiete doplňujúce otázky, systém upravuje svoje chápanie vášho zámeru a aktualizuje ďalšie odporúčania. Táto spätná väzba správania znamená, že AI systémy sa neustále učia, čo používatelia skutočne chcú, nie len čo pôvodne napísali. Pre tvorcov a marketérov obsahu to zdôrazňuje dôležitosť vytvárania obsahu, ktorý napĺňa zámer v rôznych používateľských kontextoch a fázach rozhodovania.
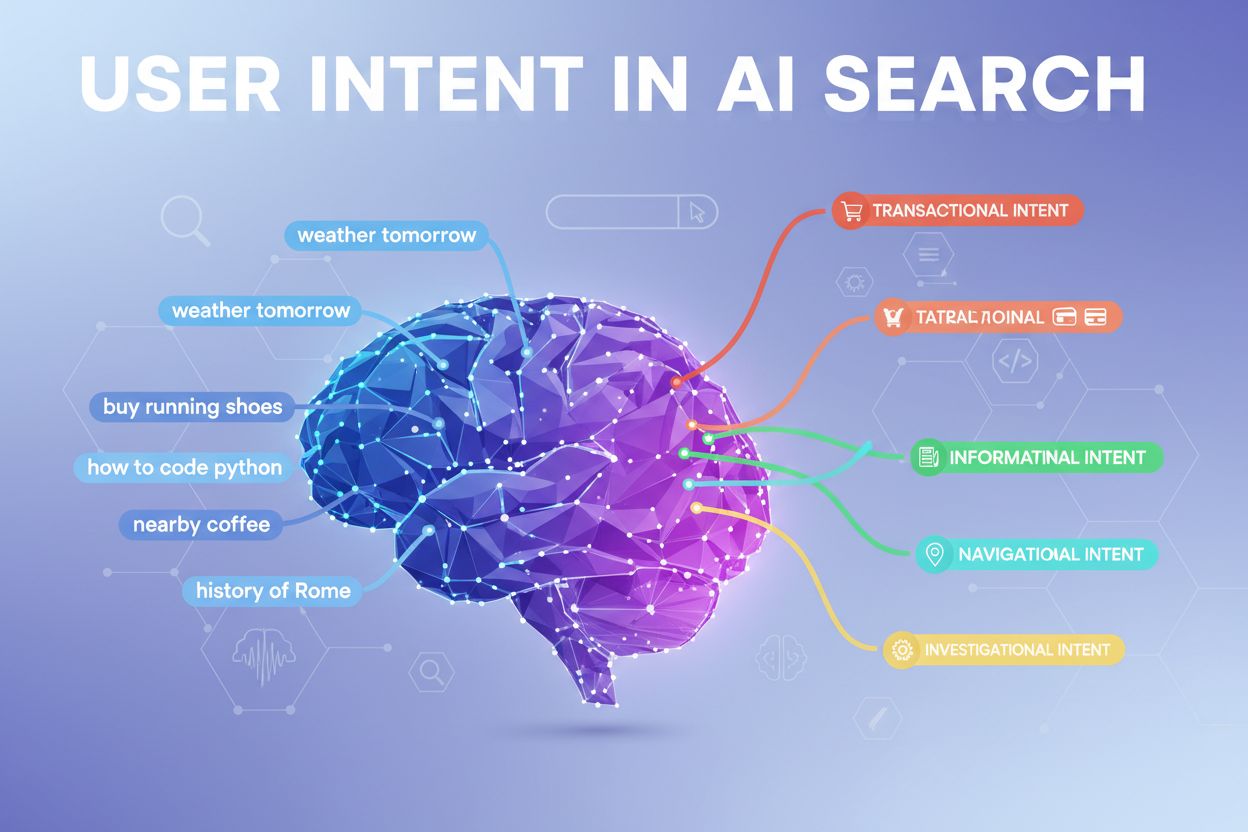
Moderné AI systémy klasifikujú zámer používateľa do niekoľkých odlišných kategórií, pričom každá vyžaduje iný typ obsahu a odpovedí:
LLM tieto zámery automaticky klasifikujú analýzou štruktúry dopytu, kľúčových slov a kontextových signálov a potom vyberajú obsah, ktorý najlepšie zodpovedá detekovanému typu zámeru. Poznanie týchto kategórií pomáha tvorcom obsahu štruktúrovať stránky tak, aby adresovali konkrétny zámer, ktorý si používateľ prináša do vyhľadávania.
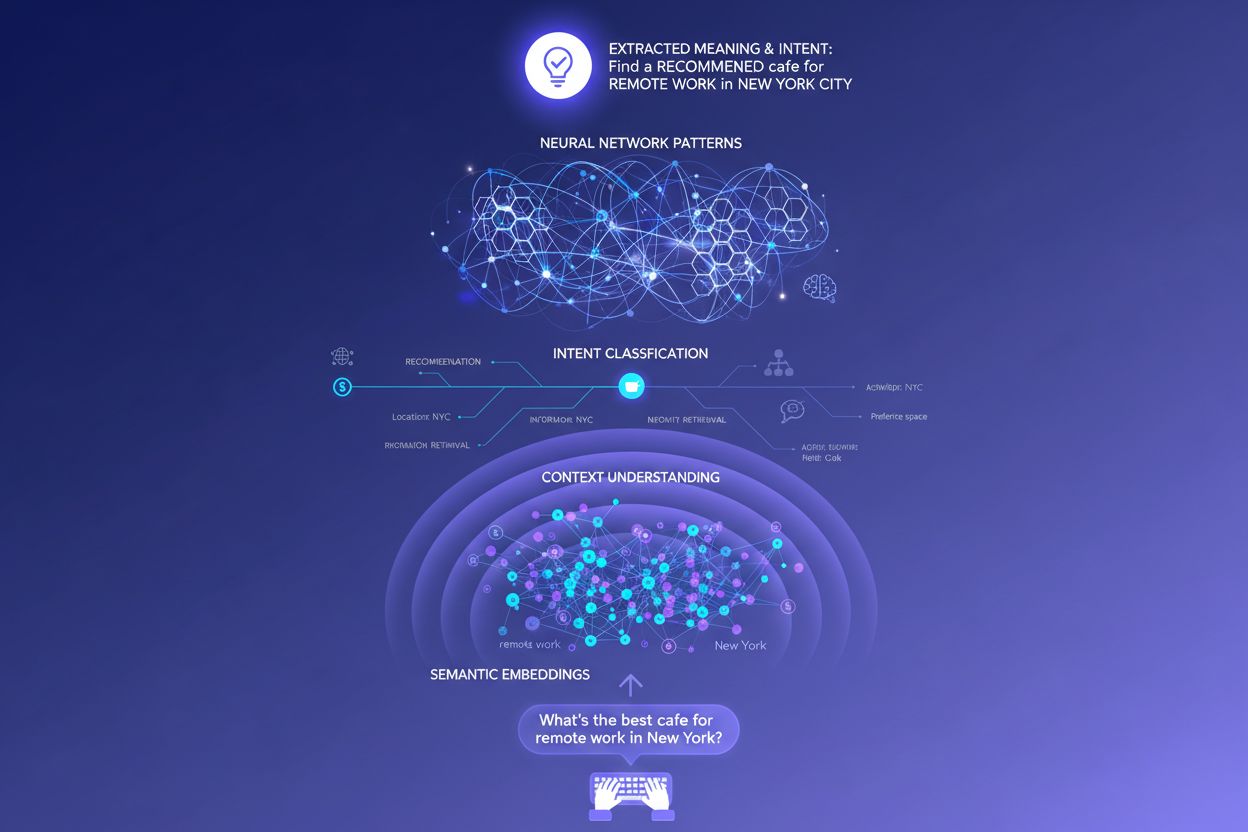
Tradičné vyhľadávače založené na kľúčových slovách fungujú na jednoduchom porovnávaní reťazcov—ak vaša stránka obsahuje presne tie slová, ktoré niekto hľadá, môže sa umiestniť vo výsledkoch. Tento prístup však zlyháva pri synonymách, parafrázovaní a kontexte. Ak niekto hľadá “cenovo dostupný software na správu projektov” a vaša stránka používa frázu “platforma na koordináciu úloh priateľská k rozpočtu”, tradičné vyhľadávanie si túto súvislosť nemusí vôbec všimnúť. Sémantické embeddingy tento problém riešia konverziou slov a fráz na matematické vektory, ktoré zachytávajú význam, nie len povrchový text. Tieto vektory existujú vo vysoko dimenzionálnom priestore, kde sa sémanticky podobné koncepty zhlukujú, čo LLM umožňuje rozpoznať, že “cenovo dostupný”, “priateľský k rozpočtu”, “lacný” a “nízkonákladový” vyjadrujú ten istý zámer. Tento sémantický prístup tiež oveľa lepšie zvláda dlhé a konverzačné dopyty než párovanie kľúčových slov—dopyt ako “Som freelancer a potrebujem niečo jednoduché, ale výkonné” môže byť spárovaný s relevantným obsahom, hoci neobsahuje tradičné kľúčové slová. Praktickým výsledkom je, že AI systémy dokážu ponúknuť relevantné odpovede aj na vágne, zložité či nekonvenčné dopyty, vďaka čomu sú podstatne užitočnejšie ako ich predchodcovia založení na kľúčových slovách.
Technickým jadrom interpretácie zámeru je transformer architektúra, neurónová sieť, ktorá spracováva jazyk analýzou vzťahov medzi slovami prostredníctvom mechanizmu nazývaného “pozornosť” (attention). Namiesto sekvenčného čítania textu ako človek, transformery skúmajú, ako sa každé slovo vzťahuje k ostatným v dopyte, čo im umožňuje zachytiť nuansy významu a kontextu. Sémantické embeddingy sú číselné reprezentácie, ktoré z tohto procesu vznikajú—každé slovo, fráza alebo koncept sa prevedie na vektor čísel, ktorý kóduje jeho význam. Modely ako BERT (Bidirectional Encoder Representations from Transformers) a RankBrain používajú tieto embeddingy na pochopenie, že “najlepšie CRM pre startupy” a “top platforma na riadenie vzťahov so zákazníkmi pre nové firmy” vyjadrujú podobný zámer, hoci používajú úplne iné slová. Mechanizmus pozornosti je mimoriadne silný, pretože umožňuje modelu sústrediť sa na najdôležitejšie časti dopytu—v dopyte “najlepšie nástroje na správu projektov pre vzdialené tímy s obmedzeným rozpočtom” sa systém naučí považovať “vzdialené tímy” a “obmedzený rozpočet” za kľúčové signály zámeru. Táto technická sofistikovanosť je dôvodom, prečo je moderné AI vyhľadávanie podstatne inteligentnejšie než tradičné systémy založené na kľúčových slovách.
Pochopenie, ako LLM interpretujú zámer, zásadne mení obsahovú stratégiu. Namiesto písania jedného komplexného návodu, ktorý sa snaží umiestniť na jedno kľúčové slovo, úspešný obsah dnes rieši viacero podzámerov v samostatných modulárnych sekciách, ktoré môžu stáť samostatne. Ak píšete o nástrojoch na správu projektov, namiesto jednej obrovskej porovnávacej tabuľky vytvorte jasné sekcie odpovedajúce na otázky “Ktorý je najlepší pre vzdialené tímy?”, “Ktorý je najdostupnejší?” a “Ktorý sa integruje so Slackom?"—každá sekcia sa môže stať potenciálnou odpoveďou, ktorú LLM vyberie a cituje. Formátovanie pripravené na citácie je nesmierne dôležité: používajte fakty namiesto všeobecných tvrdení, uvádzajte konkrétne čísla a dátumy a štruktúrujte informácie tak, aby ich AI systémy mohli ľahko citovať alebo zhrnúť. Odrážky, jasné nadpisy a krátke odseky pomáhajú LLM lepšie spracovať váš obsah než hustý text. Nástroje ako AmICited dnes umožňujú marketérom monitorovať, ako AI systémy citujú ich obsah v ChatGPT, Perplexity a Google AI, čím odhaľujú, ktoré zosúladenia zámerov fungujú a kde sú obsahové medzery. Tento dátovo riadený prístup k obsahovej stratégii—optimalizácia pre spôsob, akým AI systémy v skutočnosti interpretujú a citujú vašu prácu—predstavuje zásadný posun oproti tradičnému SEO.
Uveďme si e-commerce príklad: keď niekto hľadá “nepremokavá bunda do 200 €”, vyjadruje súčasne viacero zámerov—chce informácie o odolnosti, potvrdenie ceny a odporúčania produktov. AI systém môže tento dopyt rozšíriť na poddotazy o technológii nepremokavosti, cenových porovnaniach, recenziách značiek a informáciách o záruke. Značka, ktorá rieši všetky tieto uhly v modulárnom, dobre štruktúrovanom obsahu, má oveľa väčšiu šancu byť citovaná v AI-generovanej odpovedi ako konkurent s generickou produktovou stránkou. V SaaS oblasti sa rovnaký dopyt “Ako pozvať tím do tohto pracovného priestoru?” môže vyskytovať stovkykrát v zákazníckych požiadavkách, čo signalizuje kritickú obsahovú medzeru. AI asistent trénovaný na vašej dokumentácii nemusí vedieť na túto otázku jasne odpovedať, čo vedie k zlej používateľskej skúsenosti a nižšej viditeľnosti v AI-generovaných odpovediach na podporu. V spravodajských a informačných kontextoch bude dopyt ako “Čo sa deje s reguláciou AI?” interpretovaný rôzne podľa používateľa—tvorca politík môže potrebovať legislatívne detaily, biznis líder konkurenčné dôsledky a technológ technické štandardy. Úspešný obsah tieto odlišné kontexty zámeru adresuje explicitne.
Napriek svojej sofistikovanosti LLM čelia reálnym výzvam pri interpretácii zámeru. Nejednoznačné dopyty ako “Java” môžu znamenať programovací jazyk, ostrov alebo kávu—a ani kontext nemusí vždy stačiť na správnu klasifikáciu zámeru. Zmiešané alebo vrstvené zámery veci ešte komplikujú: “Je toto CRM lepšie ako Salesforce a kde si ho môžem vyskúšať zadarmo?” kombinuje porovnanie, hodnotenie i transakčný zámer v jednom dopyte. Obmedzenia kontextového okna znamenajú, že LLM môžu spracovať len konečné množstvo histórie konverzácie, takže pri dlhších rozhovoroch sa môžu skoršie signály zámeru vytratiť. Halucinácie a faktické chyby ostávajú problémom najmä v oblastiach, kde je potrebná vysoká presnosť ako zdravotníctvo, financie či právne poradenstvo. Otázky ochrany súkromia sú tiež dôležité—ako systémy zhromažďujú viac behaviorálnych dát na zlepšenie personalizácie, musia vyvažovať presnosť zámeru s ochranou súkromia používateľov. Pochopenie týchto obmedzení pomáha tvorcom a marketérom nastaviť realistické očakávania ohľadom viditeľnosti vo vyhľadávaní AI a uvedomiť si, že nie každý dopyt bude interpretovaný dokonale.
Vyhľadávanie na základe zámeru sa rýchlo vyvíja smerom k sofistikovanejšiemu porozumeniu a interakcii. Konverzačné AI budú čoraz prirodzenejšie, pričom systémy udržia kontext aj v dlhších, komplexných dialógoch, kde sa zámer môže meniť a vyvíjať. Multimodálne rozpoznávanie zámeru skombinuje text, obrázky, hlas či video na komplexnejšiu interpretáciu cieľov používateľa—predstavte si, že AI asistentovi poviete “nájdi mi niečo ako toto” a ukážete fotku. Zero-query vyhľadávanie predstavuje nový horizont, kde AI systémy predvídajú potreby používateľa skôr, než ich sám explicitne zadá, na základe behaviorálnych signálov a kontextu. Zlepšená personalizácia prinesie čoraz viac individuálne prispôsobené výsledky podľa profilu používateľa, fázy rozhodovania a situácie. Integrácia s odporúčacími systémami rozmaže hranicu medzi vyhľadávaním a objavovaním—AI začne aktívne navrhovať obsah, o ktorom používateľ ani nevedel, že ho môže hľadať. Ako tieto schopnosti dozrievajú, konkurenčnú výhodu získajú značky a tvorcovia, ktorí hlboko rozumejú zámerom a štruktúrujú svoj obsah tak, aby ich komplexne napĺňali v rôznych kontextoch a pre rôzne typy používateľov.
Používateľský zámer označuje základný cieľ alebo účel za dopytom, nie len kľúčové slová. LLM interpretujú sémantický význam analýzou kontextu, formulácie a súvisiacich signálov, aby predpovedali, čo používateľ skutočne chce dosiahnuť. Preto rovnaký dopyt môže priniesť rôzne výsledky v závislosti od kontextu používateľa a fázy rozhodovania.
LLM používajú proces nazývaný 'fan-out dopytov', pri ktorom rozdelia jeden dopyt na desiatky súvisiacich mikro-otázok. Napríklad 'Notion vs Trello' sa môže rozšíriť na poddotazy o tímovej spolupráci, cenách, integráciách a jednoduchosti používania. To umožňuje AI skúmať rôzne uhly zámeru a zhromaždiť komplexné informácie.
Pochopenie zámeru pomáha tvorcom obsahu optimalizovať spôsob, akým AI systémy skutočne interpretujú a citujú ich prácu. Obsah, ktorý rieši viacero podzámerov v modulárnych sekciách, má väčšiu šancu byť vybraný LLM. To priamo ovplyvňuje viditeľnosť v AI-generovaných odpovediach v ChatGPT, Perplexity a Google AI.
Sémantické embeddingy prevádzajú slová a frázy na matematické vektory, ktoré zachytávajú význam, nie len povrchový text. To umožňuje LLM rozpoznať, že 'cenovo dostupný', 'priateľský k rozpočtu' a 'lacný' vyjadrujú ten istý zámer, hoci používajú rôzne slová. Tento sémantický prístup oveľa lepšie zvláda synonymá, parafrázovanie a kontext ako tradičné párovanie kľúčových slov.
Áno, LLM čelia výzvam pri nejednoznačných dopytoch, zmiešaných zámeroch a obmedzeniach kontextu. Dopyty ako 'Java' môžu označovať programovací jazyk, geografiu alebo kávu. Dlhé konverzácie môžu presiahnuť kontextové okno, čo spôsobí zabudnutie skorších signálov zámeru. Porozumenie týmto obmedzeniam pomáha nastaviť realistické očakávania ohľadom viditeľnosti vo vyhľadávaní pomocou AI.
Značky by mali vytvárať modulárny obsah, ktorý rieši viacero podzámerov v oddelených sekciách. Používajte formátovanie pripravené na citácie s faktami, konkrétnymi číslami a jasnou štruktúrou. Monitorujte, ako AI systémy citujú váš obsah pomocou nástrojov ako AmICited, aby ste identifikovali medzery v zosúladení zámerov a optimalizovali podľa toho.
Zámer je zameraný na úlohu – čo chce používateľ momentálne dosiahnuť. Záujem je širšia všeobecná zvedavosť. AI systémy uprednostňujú zámer, pretože priamo určuje, ktorý obsah bude vybraný do odpovedí. Používateľ sa môže zaujímať o produktivitu celkovo, ale jeho zámerom môže byť nájsť niečo konkrétne pre tímovú spoluprácu na diaľku.
AI systémy citujú zdroje, ktoré najlepšie zodpovedajú detekovanému zámeru. Ak váš obsah jasne rieši konkrétny podzámer so štruktúrovanými, faktickými informáciami, je pravdepodobnejšie, že bude vybraný. Nástroje ako AmICited sledujú tieto vzory citácií a ukazujú, ktoré zosúladenia zámerov ovplyvňujú viditeľnosť v AI-generovaných odpovediach.
Zistite, ako LLM citujú váš obsah v ChatGPT, Perplexity a Google AI. Sledujte zosúladenie zámerov a optimalizujte viditeľnosť v AI pomocou AmICited.
Vyhľadávací zámer je účel za používateľovým vyhľadávacím dopytom. Zistite štyri typy vyhľadávacieho zámeru, ako ich identifikovať a optimalizovať obsah pre lepš...

Naučte sa identifikovať a optimalizovať obsah pre zámer vyhľadávania v AI vyhľadávačoch. Objavte metódy klasifikácie dopytov, analýzu AI SERP a štruktúrovanie o...
Zistite, čo znamená informačný vyhľadávací zámer pre AI systémy, ako AI rozpoznáva tieto dopyty a prečo je pochopenie tohto zámeru dôležité pre viditeľnosť obsa...