
AI citácia
Zistite, čo sú AI citácie, ako fungujú naprieč ChatGPT, Perplexity a Google AI, a prečo sú dôležité pre viditeľnosť vašej značky v generatívnych vyhľadávačoch....
12 min čítania

Zistite, ako modely umelej inteligencie ako ChatGPT, Perplexity a Gemini vyberajú zdroje na citovanie. Pochopte mechanizmy citovania, hodnotiace faktory a optimalizačné stratégie pre viditeľnosť v AI.
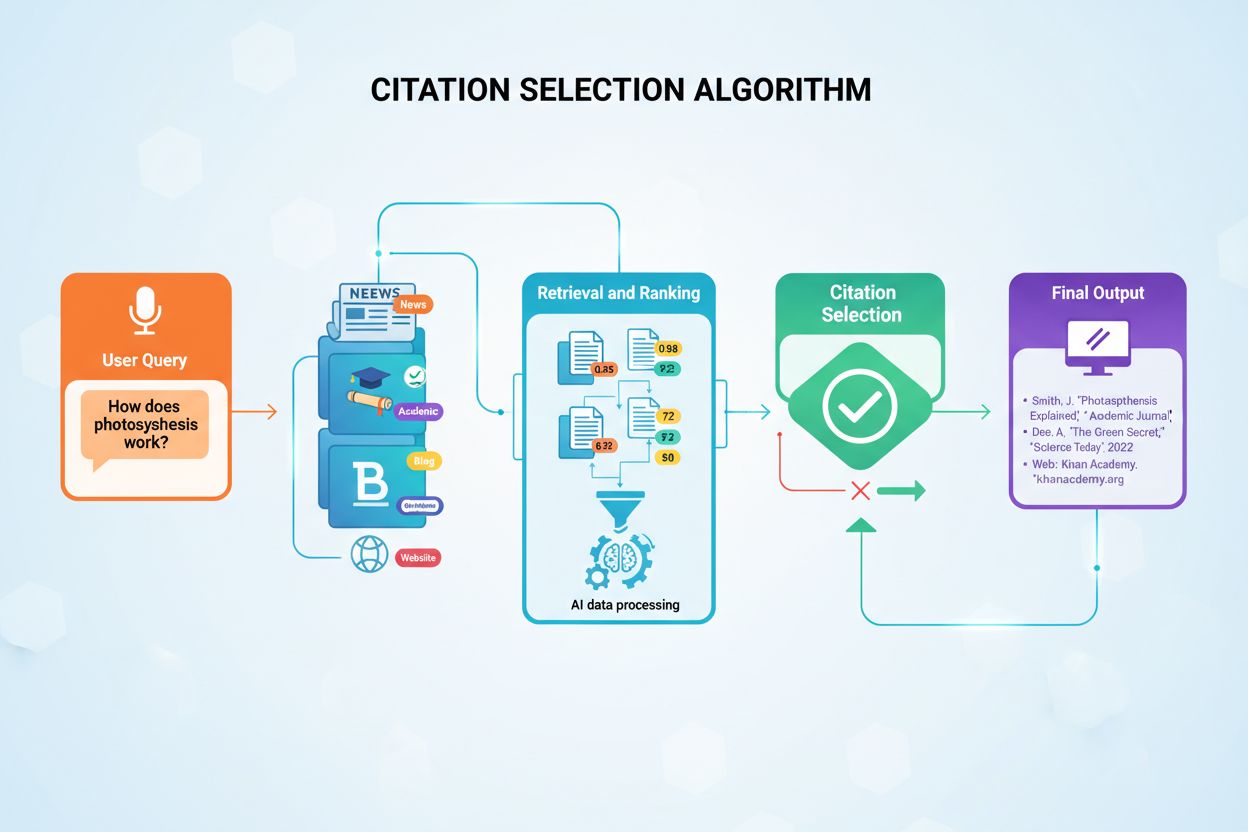
Modely umelej inteligencie rozhodujú, čo citovať, pomocou Retrieval-Augmented Generation (RAG), pričom hodnotia zdroje na základe autority domény, aktuálnosti obsahu, sémantickej relevantnosti, štruktúry informácií a faktickej hustoty. Rozhodovací proces prebieha v milisekundách pomocou algoritmov na párovanie vektorovej podobnosti a viacfaktorového skórovania, ktoré posudzujú dôveryhodnosť, signály odbornosti a kvalitu obsahu.
Modely umelej inteligencie si nevyberajú zdroje na citovanie náhodne. Namiesto toho využívajú sofistikované algoritmy, ktoré v priebehu milisekúnd vyhodnocujú stovky signálov, aby určili, ktoré zdroje si zaslúžia atribúciu. Tento proces, známy ako Retrieval-Augmented Generation (RAG), sa zásadne líši od toho, ako tradičné vyhľadávače radia obsah. Zatiaľ čo Google sa zameriava na radenie stránok pre viditeľnosť vo výsledkoch vyhľadávania, AI algoritmy pre citácie uprednostňujú zdroje, ktoré poskytujú najautoritatívnejšie, najrelevantnejšie a najdôveryhodnejšie informácie na zodpovedanie konkrétnych otázok používateľov. Tento rozdiel znamená, že dosiahnutie viditeľnosti v AI-generovaných odpovediach si vyžaduje porozumenie úplne iným optimalizačným princípom ako tradičné SEO.
Rozhodovanie o citácii prebieha viacstupňovým procesom, ktorý začína okamžite po odoslaní dopytu používateľom. AI systém prevedie otázku používateľa do numerických vektorov nazývaných embeddingy, ktoré predstavujú sémantický význam dopytu. Tieto embeddingy potom prehľadávajú indexované databázy obsahu s miliónmi dokumentov a hľadajú sémanticky podobné časti obsahu. Systém nevyhľadáva len najpodobnejší obsah; namiesto toho aplikuje viaceré hodnotiace kritériá súčasne a zoraďuje potenciálne zdroje podľa ich vhodnosti na citovanie. Tento paralelný hodnotiaci proces zabezpečuje, že najdôveryhodnejšie, najrelevantnejšie a najlepšie štruktúrované zdroje sa dostávajú na vrchol rebríčka.
Retrieval-Augmented Generation (RAG) predstavuje základnú architektúru, ktorá umožňuje modelom umelej inteligencie vôbec citovať externé zdroje. Na rozdiel od tradičných veľkých jazykových modelov, ktoré sa spoliehajú len na tréningové dáta zakódované počas ich vývoja, RAG systémy aktívne vyhľadávajú v indexovaných dokumentoch v čase dopytu, získavajú relevantné informácie ešte pred generovaním odpovedí. Tento architektonický rozdiel vysvetľuje, prečo niektoré platformy ako Perplexity a Google AI Overviews dôsledne poskytujú citácie, zatiaľ čo iné ako základný ChatGPT často generujú odpovede bez explicitnej atribúcie zdroja. Pochopenie RAG vysvetľuje, prečo sa niektorý obsah cituje, zatiaľ čo rovnako kvalitný obsah zostáva pre AI systémy neviditeľný.
Proces RAG funguje cez štyri odlišné fázy, ktoré určujú, ktoré zdroje napokon získajú citácie. Najprv sa dokumenty rozdelia na zvládnuteľné časti s rozsahom 200-500 slov, čo zabezpečuje, že AI systémy dokážu extrahovať konkrétne, relevantné informácie bez nutnosti spracovať celé články. Po druhé, tieto časti sa prevedú na numerické vektory nazývané embeddingy pomocou modelov strojového učenia vyškolených na pochopenie sémantického významu. Po tretie, keď používateľ položí otázku, systém hľadá sémanticky podobné vektory pomocou párovania vektorovej podobnosti a identifikuje obsah, ktorý sa zaoberá hlavnými konceptmi dopytu. Po štvrté, AI vygeneruje odpoveď pomocou získaného obsahu ako kontextu a zdroje, ktoré najvýraznejšie prispeli k odpovedi, získajú citácie. Táto architektúra vysvetľuje, prečo štruktúra obsahu, jasnosť a sémantická zhoda s bežnými dopytmi priamo ovplyvňujú pravdepodobnosť citácie.
Algoritmy na citovanie v AI hodnotia zdroje podľa piatich základných rozmerov, ktoré spoločne určujú vhodnosť na citovanie. Tieto faktory spolu vytvárajú komplexné hodnotenie kvality zdroja, pričom každý rozmer prispieva k celkovému skóre citácie.
| Faktor citácie | Úroveň vplyvu | Kľúčové indikátory |
|---|---|---|
| Autorita domény | Veľmi vysoká (25-30%) | Profil spätných odkazov, vek domény, prítomnosť v knowledge graph, zmienky na Wikipédii |
| Aktuálnosť obsahu | Vysoká (20-25%) | Dátum publikácie, frekvencia aktualizácií, čerstvosť štatistík a údajov |
| Sémantická relevantnosť | Vysoká (20-25%) | Zhoda dopytu s obsahom, špecifickosť témy, prítomnosť priamej odpovede |
| Štruktúra informácií | Stredne vysoká (15-20%) | Hierarchia nadpisov, skenovateľný formát, implementácia schémy |
| Faktická hustota | Stredná (10-15%) | Konkrétne údaje, štatistiky, citácie odborníkov, reťazce citácií |
Autorita predstavuje najväčšiu váhu v rozhodnutiach AI o citáciách. Výskum analyzujúci 150 000 AI citácií ukazuje, že Reddit a Wikipedia predstavujú 40,1 % a 26,3 % všetkých LLM citácií, čo demonštruje, ako výrazne etablovaná autorita ovplyvňuje výber. AI systémy posudzujú autoritu cez viaceré signály dôvery vrátane veku domény, kvality profilu spätných odkazov, prítomnosti v knowledge graph a overenia tretími stranami. Webstránky s hodnotením autority domény nad 60 majú konzistentne vyššiu mieru citácií v ChatGPT, Perplexity a Gemini. Autorita však nie je len o metrikách na úrovni domény; zahŕňa aj dôveryhodnosť autora, pričom obsah podpísaný menovanými odborníkmi s overiteľnými referenciami získava prednosť pred anonymnými príspevkami.
Aktuálnosť funguje ako kritický časový filter, ktorý určuje, či obsah zostáva vhodný na citovanie. Obsah publikovaný alebo aktualizovaný v priebehu 48-72 hodín získava preferenčné hodnotenie, zatiaľ čo zastarávanie obsahu začína okamžite a viditeľnosť merateľne klesá už po 2-3 dňoch bez aktualizácie. Táto zaujatosť na aktuálnosť odráža záväzok AI platforiem poskytovať aktuálne informácie, najmä pri rýchlo sa vyvíjajúcich témach, kde by zastarané informácie mohli používateľov zavádzať. Nadčasový obsah s nedávnymi aktualizáciami však môže prekonať novší, ale povrchný obsah, čo naznačuje, že kombinácia základnej kvality a čerstvosti má väčšiu váhu než každý faktor zvlášť. Organizácie, ktoré obsah obnovujú kvartálne alebo ročne, dosahujú vyššie miery citácií než tie, ktoré publikujú jednorazovo a obsah zanedbajú.
Relevantnosť meria sémantickú zhodu medzi dopytom používateľa a obsahom dokumentu. Zdroje, ktoré priamo odpovedajú na hlavnú otázku s minimom odbočenia, získavajú vyššie skóre ako komplexné, ale neostré zdroje. AI systémy hodnotia relevantnosť pomocou podobnosti embeddingov, kde porovnávajú numerické reprezentácie dopytu s numerickou reprezentáciou častí dokumentov. To znamená, že obsah napísaný konverzačným jazykom zodpovedajúcim prirodzeným dopytom funguje lepšie než obsah optimalizovaný na kľúčové slová pre tradičné vyhľadávače. FAQ štýl a páry otázka-odpoveď prirodzene zodpovedajú spôsobu, akým AI systémy spracúvajú dopyty, vďaka čomu je tento formát obsahu obzvlášť vhodný na citácie.
Štruktúra zahŕňa informačnú architektúru aj technickú implementáciu. Jasná hierarchická organizácia s popisnými nadpismi, logickým tokom a skenovateľným formátovaním pomáha AI systémom pochopiť hranice obsahu a extrahovať relevantné informácie. Štruktúrované dáta pomocou schém ako FAQ, Article alebo Organization môžu zvýšiť pravdepodobnosť citácie až o 10 %. Obsah organizovaný ako stručné zhrnutia, odrážkové zoznamy, porovnávacie tabuľky a páry otázka-odpoveď získava prednosť pred hutnými odstavcami s ukrytými poznatkami. Táto preferencia štruktúry odráža spôsob, akým AI rozpoznáva dobre organizované informácie poskytujúce úplné, kontextové odpovede.
Faktická hustota označuje koncentráciu konkrétnych, overiteľných informácií v obsahu. Zdroje obsahujúce konkrétne údaje, štatistiky, dátumy a príklady prekonávajú čisto koncepčný obsah. Ešte dôležitejšie je, že zdroje citujúce autoritatívne referencie vytvárajú reťazce dôvery, kde AI systémy preberajú dôveru od citovaných zdrojov. Obsah, ktorý zahŕňa podporné dôkazy a odkazuje na primárne zdroje, má vyššiu mieru citácií než nepodložené tvrdenia. Táto požiadavka na faktickú hustotu znamená, že každé významné tvrdenie by malo obsahovať atribúciu na autoritatívne zdroje s dátumom publikácie a odbornými referenciami.
Rôzne AI platformy implementujú odlišné stratégie citovania, ktoré odrážajú ich architektúru a filozofiu dizajnu. Pochopenie týchto špecifických preferencií pomáha tvorcom obsahu optimalizovať pre viaceré AI systémy naraz.
Vzorce citovania v ChatGPT odhaľujú silnú preferenciu encyklopedických a autoritatívnych zdrojov. Wikipedia sa objavuje približne v 35 % citácií ChatGPT, čo demonštruje závislosť modelu na etablovaných, komunitne overených informáciách. Platforma sa vyhýba obsahu z fór generovaného používateľmi, pokiaľ dopyty výslovne nevyžadujú komunitné názory, a uprednostňuje zdroje s jasnou atribučnou reťazou a overiteľnými faktami pred obsahom založeným na názoroch. Tento konzervatívny prístup odráža tréning ChatGPT na vysokokvalitných zdrojoch a filozofiu dizajnu uprednostňujúcu presnosť pred komplexnosťou. Organizácie, ktoré chcú byť citované v ChatGPT, by mali budovať prítomnosť v knowledge graph, vytvárať záznamy na Wikipédii a tvoriť obsah podobný encyklopedickej hĺbke a neutralite.
Google AI systémy vrátane Gemini a AI Overviews zahŕňajú rozmanitejšie typy zdrojov, čo odráža širšiu filozofiu indexácie Googlu. Reddit príspevky tvoria približne 5 % citácií v AI Overviews, pričom platforma uprednostňuje obsah, ktorý sa objavuje v top organických výsledkoch vyhľadávania, čím vytvára synergiu medzi tradičným SEO a mierou AI citácií. Google AI systémy preukazujú väčšiu ochotu citovať novšie zdroje a obsah generovaný používateľmi v porovnaní s ChatGPT, pokiaľ tieto zdroje vykazujú relevantnosť a autoritu. Táto preferencia znamená, že silná výkonnosť v tradičnom SEO koreluje s úspechom v AI citáciách na platformách Googlu, hoci korelácia nie je dokonalá.
Preferencie Perplexity AI zdôrazňujú transparentnosť a priamu atribúciu zdrojov. Platforma zvyčajne poskytuje 3-5 zdrojov na odpoveď s priamymi odkazmi, pričom uprednostňuje odvetvové recenzné stránky, odborné publikácie a dátovo orientovaný obsah. Autorita domény zohráva veľkú váhu, pričom etablované publikácie sú preferované, zatiaľ čo komunitný obsah tvorí približne 1 % citácií, najmä pri odporúčaniach produktov. Filozofia dizajnu Perplexity dáva dôraz na to, aby používatelia mohli overiť informácie prostredníctvom jasnej atribúcie zdrojov, vďaka čomu je obzvlášť vhodná na sledovanie viditeľnosti značky. Organizácie optimalizujúce pre Perplexity by mali vytvárať dátovo bohatý obsah, odvetvové zdroje a články od odborníkov, ktoré jasne demonštrujú autoritu.
Autorita domény funguje ako ukazovateľ spoľahlivosti v AI algoritmoch, čo signalizuje, že zdroj si v priebehu času vybudoval dôveryhodnosť. Systémy hodnotia autoritu prostredníctvom viacerých signálov dôvery, ktoré predstavujú približne 5 % celkovej pravdepodobnosti citácie, hoci toto percento výrazne rastie pri témach YMYL (Your Money, Your Life) ovplyvňujúcich zdravie, financie alebo bezpečnosť. Kľúčové indikátory autority zahŕňajú vek domény, SSL certifikáty, zásady ochrany osobných údajov a značky súladu ako SOC 2 alebo GDPR certifikácia. Tieto technické signály sa násobia v kombinácii s metrikami kvality obsahu, čím vzniká multiplikatívny efekt, pri ktorom technicky kvalitné weby s výborným obsahom prekonávajú technicky slabé stránky bez ohľadu na kvalitu obsahu.
Profily spätných odkazov významne ovplyvňujú vnímanie zdroja v AI algoritmoch. AI modely hodnotia autoritu odkazujúcich domén, relevantnosť kontextu odkazu a diverzitu portfólia odkazov. Výskumy ukazujú, že desať spätných odkazov z významných publikácií prekoná sto odkazov z nízkoautoritatívnych stránok, čo dokazuje, že kvalita odkazov je omnoho dôležitejšia než ich kvantita. Odborná atribúcia výrazne zvyšuje pravdepodobnosť citácie, pričom obsah podpísaný menovanými autormi s overiteľnými referenciami má omnoho lepšiu výkonnosť než anonymný obsah. Schema markup autora a podrobné bio pomáhajú AI systémom overiť odbornosť, zatiaľ čo overenie tretími stranami prostredníctvom zmienok v odvetvových publikáciách posilňuje dôveryhodnosť. Organizácie budujúce autoritu by sa mali sústrediť na získavanie spätných odkazov z vysokoautoritatívnych zdrojov, budovanie referencií autorov a zabezpečenie zmienok v odvetvových publikáciách.
Prítomnosť na Wikipédii a v knowledge graph výrazne zvyšuje mieru citácií bez ohľadu na iné faktory. Zdroje zmienené na Wikipédii majú výraznú výhodu, pretože knowledge graph slúžia ako autoritatívne zdroje, na ktoré sa AI modely opakovane odvolávajú pri rôznych dopytoch. Informácie z Google Knowledge Panel priamo ovplyvňujú, ako AI modely chápu vzťahy entít a autoritu. Organizácie bez prítomnosti na Wikipédii majú problém dosiahnuť konzistentné citácie aj pri vysokokvalitnom obsahu, čo naznačuje, že rozvoj knowledge graph by mal byť prioritou pre vážne stratégie AI viditeľnosti. Tým vzniká základná vrstva dôvery, ktorú jazykové modely využívajú počas vyhľadávania, pričom záznamy v knowledge graph slúžia ako autoritatívne zdroje, na ktoré sa modely opakovane obracajú.
Súlad s konverzačnými dopytmi predstavuje zásadný posun od tradičnej SEO optimalizácie. Obsah štruktúrovaný ako páry otázka-odpoveď dosahuje lepšie výsledky v retrieval algoritmoch ako obsah optimalizovaný na kľúčové slová. FAQ stránky a obsah napodobňujúci prirodzené jazykové dopyty majú preferenčné zaobchádzanie, pretože AI systémy sú trénované na konverzačných dátach a lepšie rozumejú prirodzeným jazykovým vzorom než reťazcom kľúčových slov. To znamená, že obsah napísaný ako odpoveď priateľovi prekonáva obsah písaný pre algoritmy vyhľadávača. Organizácie by mali revidovať svoj obsah z hľadiska konverzačného tónu, priamych odpovedí na bežné otázky a prirodzeného jazyka v súlade s tým, ako používatelia skutočne kladú otázky.
Kvalita citácie v obsahu vytvára reťazce dôvery, ktoré presahujú jednotlivé zdroje. AI systémy hodnotia, či tvrdenia obsahujú podporné údaje a dôkazy. Obsah citujúci autoritatívne referencie preberá dôveru od týchto zdrojov, čím vzniká multiplikatívny efekt dôveryhodnosti. Zdroje, ktoré obsahujú podporné dôkazy a odkazujú na primárne zdroje, majú vyššiu mieru citácií než nepodložené tvrdenia. To znamená, že každé významné tvrdenie by malo obsahovať atribúciu na autoritatívne zdroje s dátumom publikácie a odbornými referenciami. Organizácie tvoriace obsah hodný citácií by mali citovať minimálne 5-8 autoritatívnych zdrojov, zahrnúť 2-3 citácie odborníkov s úplnými referenciami a pridať 3-5 aktuálnych štatistík s dátumami publikácie.
Konzistentnosť naprieč platformami ovplyvňuje, ako AI systémy hodnotia dôveryhodnosť zdroja. Keď AI nájde konzistentné informácie naprieč viacerými zdrojmi, zvyšuje sa dôvera v citovanie ktoréhokoľvek jednotlivého zdroja z tohto klastru. Zdroje, ktoré odporujú širšiemu konsenzu, získavajú nižšiu prioritu, pokiaľ neposkytujú presvedčivé protidôkazy. Táto zaujatosť na konzistentnosť znamená, že vytváranie koherentných naratívov naprieč vlastnenými, získanými a zdieľanými mediálnymi kanálmi posilňuje citovateľnosť jednotlivých zdrojov. Organizácie vyvíjajúce stratégie pre reputáciu v AI musia zabezpečiť konzistentné správy naprieč všetkými digitálnymi vlastnosťami, aby informácie prezentované na firemných weboch, sociálnych sieťach, odvetvových publikáciách a platformách tretích strán boli v súlade a posilňovali hlavné posolstvá.
Stratégia frekvencie aktualizácií je v ére AI dôležitejšia než v tradičnom SEO. Frekvencia publikovania priamo ovplyvňuje mieru citácií, pričom AI platformy jasne preferujú nedávno aktualizovaný obsah. Organizácie by mali aktualizovať existujúci obsah každých 48-72 hodín, aby si udržali signály aktuálnosti, hoci to nevyžaduje kompletné prepísanie. Pridanie nových údajov, aktualizovanie štatistík alebo rozšírenie sekcií o najnovší vývoj udržiava vhodnosť obsahu na citovanie. Systémy na správu obsahu, ktoré sledujú frekvenciu aktualizácií a čerstvosť obsahu, pomáhajú udržať konkurenčnú mieru citácií, keďže AI platformy stále viac kladú dôraz na signály aktuálnosti. Tento prístup kontinuálnych aktualizácií sa zásadne líši od tradičného SEO, kde obsah mohol byť hodnotený neobmedzene dlho bez úprav.
Stratégická prítomnosť na agregátoroch vytvára pre AI systémy viacero ciest k objaveniu obsahu. Získanie miesta v odvetvových zostavách, zoznamoch odborníkov či recenzných stránkach generuje príležitosti, ktoré pôvodné zdroje nedosiahnu samy. Jedna zmienka vo frekventovane citovanej publikácii vytvára viacero ciest na objavenie a umožňuje AI systémom naraziť na váš obsah z viacerých smerov. Media relations a obsahové partnerstvá rastú na hodnote pre AI viditeľnosť, rovnako ako strategická prítomnosť v odvetvových databázach a adresároch. Organizácie by mali cielene usilovať o zmienky v odvetvových zostavách, zoznamoch odborníkov a recenzných stránkach ako súčasť svojej stratégie AI viditeľnosti.
Implementácia štruktúrovaných dát zvyšuje pravdepodobnosť citácie tým, že robí obsah strojovo čitateľným. Schema markup v AI-čitateľných formátoch pomáha AI platformám pochopiť a extrahovať konkrétne fakty bez potreby analyzovať neštruktúrovaný text. FAQ schéma, Article schéma s informáciami o autorovi a Organization schéma vytvárajú strojovo čitateľné signály, ktoré retrieval algoritmy uprednostňujú. JSON-LD štruktúrované dáta umožňujú AI efektívne extrahovať konkrétne fakty, čím sa zlepšuje pravdepodobnosť citácie aj presnosť citovaných informácií. Organizácie, ktoré implementujú komplexný schema markup, pozorujú merateľné zlepšenia v miere citácií naprieč viacerými AI platformami.
Budovanie Wikipédie a knowledge graph prináša kumulatívne výnosy aj napriek potrebe dlhodobej práce. Vybudovanie prítomnosti na Wikipédii si vyžaduje neutrálne, dobre zdrojované príspevky spĺňajúce redakčné štandardy Wikipédie. Súbežná optimalizácia profilov na Wikidata, Google Knowledge Panel a v odvetvových databázach vytvára základnú vrstvu dôvery, na ktorú sa AI systémy opakovane odvolávajú. Tieto záznamy v knowledge graph slúžia ako autoritatívne zdroje, na ktoré sa modely obracajú pri rôznych dopytoch, vďaka čomu je rozvoj knowledge graph strategickou prioritou pre organizácie usilujúce sa o trvalú AI viditeľnosť.
Organizácie by mali sledovať frekvenciu citácií manuálnym testovaním relevantných dopytov naprieč ChatGPT, Google AI Overviews, Perplexity a ďalšími platformami. Pravidelné testovanie promptov odhalí, ktorý obsah úspešne získava citácie a kde existujú medzery v AI reprezentácii. Táto testovacia metodológia poskytuje priamy prehľad o výkonnosti citácií a pomáha identifikovať príležitosti na optimalizáciu. Algoritmy AI citácií sa neustále menia, ako sa rozširujú tréningové dáta a vyvíjajú retrieval stratégie, čo si vyžaduje, aby sa obsahové stratégie prispôsobovali na základe výkonnostných dát. Ak obsah prestane získavať citácie napriek historickému úspechu, je potrebné ho obnoviť aktuálnymi informáciami alebo preštruktúrovať pre lepšiu sémantickú zhodu.
Viacero zdrojov môže získať citácie pre jediný dopyt, čím sa vytvárajú príležitosti na ko-citácie namiesto nulového súčtu konkurencie. Organizácie profitujú z tvorby komplexného obsahu, ktorý dopĺňa, nie duplikuje, existujúce vysoko citované zdroje. Analýza konkurenčného prostredia odhalí, ktoré značky dominujú vo viditeľnosti v AI v konkrétnych kategóriách, čím organizácie identifikujú medzery a príležitosti. Sledovanie výkonu citácií v čase odhaľuje trendy a ktoré URL adresy poháňajú úspech, čo umožňuje organizáciám replikovať víťazné stratégie a škálovať úspešné prístupy.
Sledujte, kde sa váš obsah objavuje v AI-generovaných odpovediach naprieč ChatGPT, Perplexity, Google AI Overviews a ďalšími AI platformami. Získajte prehľad v reálnom čase o viditeľnosti a výkonnosti vašich citácií v AI.
Zistite, čo sú AI citácie, ako fungujú naprieč ChatGPT, Perplexity a Google AI, a prečo sú dôležité pre viditeľnosť vašej značky v generatívnych vyhľadávačoch....
Zistite, ako si AI systémy vyberajú, ktoré zdroje budú citovať a ktoré parafrázovať. Pochopte algoritmy výberu citácií, vzory zaujatosti a stratégie na zlepšeni...

Zistite, čo je optimalizácia citácií pre AI a ako optimalizovať svoj obsah, aby bol citovaný ChatGPT, Perplexity, Google Gemini a ďalšími AI vyhľadávačmi....