Ukotvenie obsahu
Zistite, čo je ukotvenie obsahu, ako predchádza halucináciám AI a prečo je nevyhnutné pre dôveryhodné AI systémy. Objavte techniky, nástroje a najlepšie postupy...
8 min čítania

Zistite, čo je content pruning pre AI, ako funguje, aké existujú metódy pruningu a prečo je nevyhnutný pre nasadzovanie efektívnych AI modelov na edge zariadeniach a v prostrediach s obmedzenými zdrojmi.
Content pruning pre AI je technika, ktorá selektívne odstraňuje redundantné alebo menej dôležité parametre, váhy alebo tokeny z AI modelov s cieľom zmenšiť ich veľkosť, zlepšiť rýchlosť inferencie a znížiť pamäťové nároky pri zachovaní kvality výkonu.
Content pruning pre AI je základná optimalizačná technika používaná na zníženie výpočtovej náročnosti a pamäťovej stopy modelov umelej inteligencie bez výrazného zníženia ich výkonu. Tento proces zahŕňa systematickú identifikáciu a odstránenie redundantných alebo menej dôležitých komponentov z neurónových sietí, vrátane jednotlivých váh, celých neurónov, filtrov alebo aj tokenov v jazykových modeloch. Hlavným cieľom je vytvárať štíhlejšie, rýchlejšie a efektívnejšie modely, ktoré je možné efektívne nasadiť na zariadeniach s obmedzenými zdrojmi, ako sú smartfóny, edge počítače a IoT zariadenia.
Koncept pruningu čerpá inšpiráciu z biologických systémov, konkrétne zo synaptického pruningu v ľudskom mozgu, kde sa počas vývoja eliminujú nepotrebné neurónové spojenia. Podobne aj AI pruning rozpoznáva, že vytrénované neurónové siete často obsahujú množstvo parametrov, ktoré majú minimálny vplyv na konečný výstup. Odstránením týchto redundantných komponentov môžu vývojári dosiahnuť výrazné zmenšenie modelu pri zachovaní alebo dokonca zlepšení presnosti pomocou starostlivého doladenia.
Content pruning funguje na princípe, že nie všetky parametre v neurónovej sieti sú rovnako dôležité pre predikcie. Počas tréningu vytvárajú neurónové siete zložité prepojenia, z ktorých mnohé sú redundantné alebo majú zanedbateľný vplyv na rozhodovanie modelu. Pruning identifikuje tieto menej dôležité komponenty a odstraňuje ich, čím vzniká riedka architektúra siete, ktorá vyžaduje menej výpočtových zdrojov na prevádzku.
Účinnosť pruningu závisí od viacerých faktorov, vrátane použitej metódy pruningu, agresivity stratégie a následného procesu doladenia. Rôzne prístup k pruningu sa zameriavajú na rôzne aspekty neurónových sietí. Niektoré metódy sa sústreďujú na jednotlivé váhy (nestruktúrovaný pruning), iné odstraňujú celé neuróny, filtre alebo kanály (štruktúrovaný pruning). Výber metódy výrazne ovplyvňuje efektivitu výsledného modelu aj kompatibilitu s modernými hardvérovými akcelerátormi.
| Typ pruningu | Cieľ | Výhody | Výzvy |
|---|---|---|---|
| Pruning váh | Jednotlivé spojenia/váhy | Maximálna kompresia, riedke siete | Nemusí zrýchliť hardvérové vykonávanie |
| Štruktúrovaný pruning | Neuróny, filtre, kanály | Vhodné pre hardvér, rýchlejšia inferencia | Nižšia kompresia než nestruktúrovaný |
| Dynamický pruning | Kontextovo závislé parametre | Adaptívna efektivita, úprava v reálnom čase | Zložitá implementácia, vyššia režijnosť |
| Pruning vrstiev | Celé vrstvy alebo bloky | Výrazné zmenšenie veľkosti | Riziko straty presnosti, vyžaduje opatrnú validáciu |
Nestruktúrovaný pruning, známy aj ako pruning váh, funguje na najjemnejšej úrovni odstránením jednotlivých váh z váhových matíc siete. Tento prístup obvykle používa kritériá založené na veľkosti, kde váhy s hodnotami blízkymi nule sú považované za menej dôležité a eliminované. Výsledná sieť je riedka, čo znamená, že počas inferencie zostáva aktívna len časť pôvodných spojení. Hoci nestruktúrovaný pruning môže dosiahnuť pôsobivé pomery kompresie – niekedy znížiť počet parametrov o 90 % alebo viac – výsledné riedke siete nemusia vždy priniesť úmerné zrýchlenie na bežnom hardvéri bez špeciálnej podpory pre riedke výpočty.
Štruktúrovaný pruning pristupuje inak, keď odstráni celé skupiny parametrov naraz, napríklad kompletné filtre v konvolučných vrstvách, celé neuróny vo fully connected vrstvách či celé kanály. Táto metóda je obzvlášť cenná pre praktické nasadenie, pretože výsledné modely sú prirodzene kompatibilné s modernými hardvérovými akcelerátormi ako GPU a TPU. Ak sa z konvolučných vrstiev odstránia celé filtre, úspory vo výpočtoch sa prejavia okamžite, bez potreby špeciálnych riedkych maticových operácií. Výskum ukázal, že štruktúrovaný pruning dokáže zmenšiť model o 50–90 % pri zachovaní porovnateľnej presnosti ako pôvodné modely.
Dynamický pruning predstavuje sofistikovanejší prístup, pri ktorom sa proces pruningu prispôsobuje počas inferencie modelu na základe konkrétneho spracovávaného vstupu. Táto technika využíva externý kontext, ako sú embeddingy rečníka, udalostné signály alebo jazykovo špecifické informácie, na dynamické prispôsobenie toho, ktoré parametre sú aktívne. V systémoch retrieval-augmented generation dokáže dynamický pruning zredukovať veľkosť kontextu približne o 80 % a zároveň zlepšiť presnosť odpovedí filtrovaním irelevantných informácií. Tento adaptívny prístup je obzvlášť cenný pre multimodálne AI systémy, ktoré musia efektívne spracovávať rôznorodé typy vstupov.
Iteratívny pruning a doladenie predstavuje najčastejšie používaný prístup v praxi. Táto metóda zahŕňa cyklický proces: odstrániť časť siete, doladiť zostávajúce parametre na obnovenie presnosti, vyhodnotiť výkon a opakovať. Iteratívnosť tohto postupu umožňuje vývojárom starostlivo vyvažovať kompresiu modelu a zachovanie výkonu. Namiesto odstránenia všetkých zbytočných parametrov naraz – čo by mohlo katastrofálne poškodiť výkon modelu – iteratívny pruning postupne znižuje zložitosť siete a umožňuje modelu adaptovať sa a naučiť, ktoré zostávajúce parametre sú najdôležitejšie.
Jednorazový pruning ponúka rýchlejšiu alternatívu, kde celý proces pruningu prebehne v jednom kroku po trénovaní, nasledovaný fázou doladenia. Tento prístup je výpočtovo efektívnejší ako iteratívne metódy, no nesie vyššie riziko degradácie presnosti, ak sa odstráni priveľa parametrov naraz. Jednorazový pruning je užitočný najmä v prípade obmedzených výpočtových zdrojov pre iteratívne procesy, hoci obvykle vyžaduje rozsiahlejšie doladenie na obnovenie výkonu.
Pruning založený na analýze citlivosti využíva sofistikovanejší mechanizmus radenia, keď meria, o koľko sa zvyšuje hodnota loss funkcie modelu po odstránení konkrétnych váh alebo neurónov. Parametre, ktoré majú minimálny vplyv na loss funkciu, sú identifikované ako bezpečné kandidáty na pruning. Tento prístup založený na dátach umožňuje nuansovanejšie rozhodnutia v porovnaní s jednoduchými metódami podľa veľkosti, často tak dochádza k lepšiemu zachovaniu presnosti pri rovnakých úrovniach kompresie.
Hypotéza o výhernom losu (Lottery Ticket Hypothesis) predstavuje zaujímavý teoretický rámec, ktorý naznačuje, že vo veľkých neurónových sieťach existuje menšia, riedka podsieť – „výherný los“ – schopná dosiahnuť porovnateľnú presnosť ako pôvodná sieť, ak je trénovaná od rovnakého inicializačného stavu. Táto hypotéza má zásadný význam pre pochopenie redundancie sietí a inšpirovala nové metodiky pruningu, ktoré sa snažia tieto efektívne podsiete identifikovať a izolovať.
Content pruning sa stal nepostrádateľným v mnohých AI aplikáciách, kde je kľúčová výpočtová efektivita. Nasadenie na mobilných a embedded zariadeniach patrí medzi najvýznamnejšie prípady použitia, kde pruned modely umožňujú pokročilé AI funkcie na smartfónoch a IoT zariadeniach s obmedzeným výkonom a kapacitou batérie. Rozpoznávanie obrazu, hlasoví asistenti a aplikácie na preklad v reálnom čase všetky profitujú z pruned modelov, ktoré si zachovávajú presnosť pri minimálnej spotrebe zdrojov.
Autonómne systémy, vrátane samojazdiacich vozidiel a dronov, vyžadujú rozhodovanie v reálnom čase s minimálnou latenciou. Pruned neurónové siete umožňujú týmto systémom spracovávať senzorické dáta a robiť kritické rozhodnutia v prísnych časových rámcoch. Znížený výpočtový režijný čas sa premieta priamo do rýchlejšieho reagovania, čo je zásadné pre aplikácie kritické na bezpečnosť.
V cloudových a edge computing prostrediach pruning znižuje výpočtové náklady aj požiadavky na úložisko pri nasadzovaní veľkých modelov. Organizácie dokážu obslúžiť viac používateľov s rovnakou infraštruktúrou, resp. výrazne znížiť svoje výpočtové výdavky. Edge computing obzvlášť profituje z pruned modelov, keďže umožňuje pokročilé AI spracovanie na zariadeniach vzdialených od dátových centier.
Hodnotenie efektívnosti pruningu si vyžaduje starostlivé posúdenie viacerých metrík nad rámec jednoduchého zníženia počtu parametrov. Latencia inferencie – čas potrebný na vygenerovanie výstupu z modelu – je kľúčová metrika, ktorá priamo ovplyvňuje používateľský zážitok v reálnom čase. Efektívny pruning by mal výrazne znížiť latenciu inferencie, čo umožňuje rýchlejšie odozvy pre koncových používateľov.
Presnosť modelu a F1 skóre musia byť počas procesu pruningu zachované. Základnou výzvou je dosiahnuť výraznú kompresiu bez obetovania prediktívneho výkonu. Dobre navrhnuté stratégie pruningu udržia presnosť v rozmedzí 1–5 % od pôvodného modelu pri 50–90 % znížení parametrov. Redukcia pamäťovej stopy je rovnako dôležitá, keďže určuje, či modely možno nasadiť na zariadeniach s obmedzenými zdrojmi.
Výskum porovnávajúci veľké-riedke modely (veľké siete s odstránenými parametrami) a malé-husté modely (menšie siete trénované od začiatku) s rovnakou pamäťovou stopou opakovane ukazuje, že veľké-riedke modely prekonávajú svoje malé-husté náprotivky. Tento poznatok zdôrazňuje hodnotu začať s väčšími, dobre natrénovanými sieťami a následne ich strategicky prunovať namiesto pokusov trénovať malé siete od začiatku.
Degradácia presnosti zostáva hlavnou výzvou content pruningu. Agresívny pruning môže výrazne znížiť výkon modelu, preto je potrebné starostlivo kalibrovať intenzitu pruningu. Vývojári musia nájsť optimálny bod, kde sú zisky z kompresie maximalizované bez neprijateľnej straty presnosti. Tento bod sa líši v závislosti od konkrétnej aplikácie, architektúry modelu a akceptovateľných prahov výkonu.
Problémy s hardvérovou kompatibilitou môžu obmedziť praktické prínosy pruningu. Kým nestruktúrovaný pruning vytvára riedke siete s menším počtom parametrov, moderný hardvér je optimalizovaný pre husté maticové operácie. Riedke siete nemusia byť na štandardných GPU výpočtovo výrazne rýchlejšie bez špeciálnych knižníc a hardvérovej podpory pre riedke výpočty. Štruktúrovaný pruning túto nevýhodu zmierňuje zachovaním hustých výpočtových vzorov, hoci za cenu menej agresívnej kompresie.
Výpočtová náročnosť samotných metód pruningu môže byť značná. Iteratívny pruning aj prístupy založené na citlivostnej analýze vyžadujú viacnásobné tréningové cykly a starostlivé vyhodnocovanie, čo zvyšuje spotrebu výpočtových zdrojov. Vývojári musia zvážiť jednorazové náklady na pruning oproti dlhodobým úsporám pri nasadzovaní efektívnejších modelov.
Obavy z generalizácie sa objavujú pri príliš agresívnom pruningu. Prepruned modely môžu dosahovať dobré výsledky na trénovacích a validačných dátach, no zle generalizovať na nové, nevidené dáta. Pre zaistenie robustného výkonu v produkčnom prostredí sú nevyhnutné správne validačné stratégie a dôkladné testovanie na rozmanitých datasetoch.
Úspešný content pruning si vyžaduje systematický prístup založený na najlepších postupoch overených výskumom aj praxou. Začnite s väčšími, dobre natrénovanými sieťami namiesto pokusov trénovať malé siete od začiatku. Väčšie siete poskytujú viac redundancie a flexibility pre pruning, pričom výskum opakovane dokazuje, že pruned veľké siete prekonávajú malé siete trénované od nuly.
Používajte iteratívny pruning s dôkladným doladením, aby ste postupne znižovali zložitosť modelu pri zachovaní výkonu. Tento prístup poskytuje lepšiu kontrolu nad kompromisom medzi presnosťou a efektivitou a umožňuje modelu adaptovať sa na odstraňovanie parametrov. Pri praktickom nasadení využívajte štruktúrovaný pruning, ak je dôležitá hardvérová akcelerácia, pretože takto vytvorené modely bežia efektívne na štandardnom hardvéri bez nutnosti špeciálnych riedkych výpočtových knižníc.
Dôkladne validujte na rôznorodých datasetoch, aby ste zaistili, že pruned modely dobre generalizujú mimo trénovacích dát. Monitorujte viacero výkonnostných metrík, vrátane presnosti, latencie inferencie, využitia pamäte a spotreby energie, aby ste komplexne vyhodnotili efektívnosť pruningu. Zohľadnite cieľové nasadzovacie prostredie pri výbere stratégií pruningu, keďže rôzne zariadenia a platformy majú odlišné optimalizačné charakteristiky.
Oblasť content pruningu sa neustále vyvíja s novými technikami a metodikami. Kontektovo adaptívny pruning tokenov (CATP) predstavuje špičkový prístup, ktorý využíva sémantickú zhodu a diverzitu príznakov na selektívne ponechanie len najrelevantnejších tokenov v jazykových modeloch. Táto technika je obzvlášť cenná pre veľké jazykové modely a multimodálne systémy, kde je manažment kontextu kľúčový.
Integrácia s vektorovými databázami ako Pinecone a Weaviate umožňuje sofistikovanejšie stratégie pruningu kontextu efektívnym ukladaním a vyhľadávaním relevantných informácií. Tieto integrácie podporujú dynamické rozhodovanie o pruningu na základe sémantickej podobnosti a skórovania relevancie, čo zvyšuje efektivitu aj presnosť.
Kombinácia s ďalšími kompresnými technikami ako kvantizácia a distilácia znalostí vytvára synergické efekty a umožňuje ešte agresívnejšiu kompresiu modelov. Modely, ktoré sú súčasne prunedované, kvantizované a distilované, môžu dosiahnuť 100-násobné a vyššie pomery kompresie pri zachovaní prijateľnej úrovne výkonu.
Ako AI modely ďalej rastú na zložitosti a scenáre ich nasadenia sa stávajú čoraz rozmanitejšími, content pruning zostane kľúčovou technikou pre sprístupnenie a praktické využitie pokročilej AI v celom spektre výpočtových prostredí – od výkonných dátových centier až po zariadenia s extrémne obmedzenými zdrojmi.
Objavte, ako AmICited pomáha sledovať, kedy sa váš obsah objavuje v AI-generovaných odpovediach v ChatGPT, Perplexity a ďalších AI vyhľadávačoch. Zaistite viditeľnosť vašej značky v AI budúcnosti.
Zistite, čo je ukotvenie obsahu, ako predchádza halucináciám AI a prečo je nevyhnutné pre dôveryhodné AI systémy. Objavte techniky, nástroje a najlepšie postupy...

Zistite, ako AI systémy znižujú skóre relevantnosti obsahu v priebehu času prostredníctvom algoritmov úbytku čerstvosti. Pochopte funkcie časového úbytku, strat...
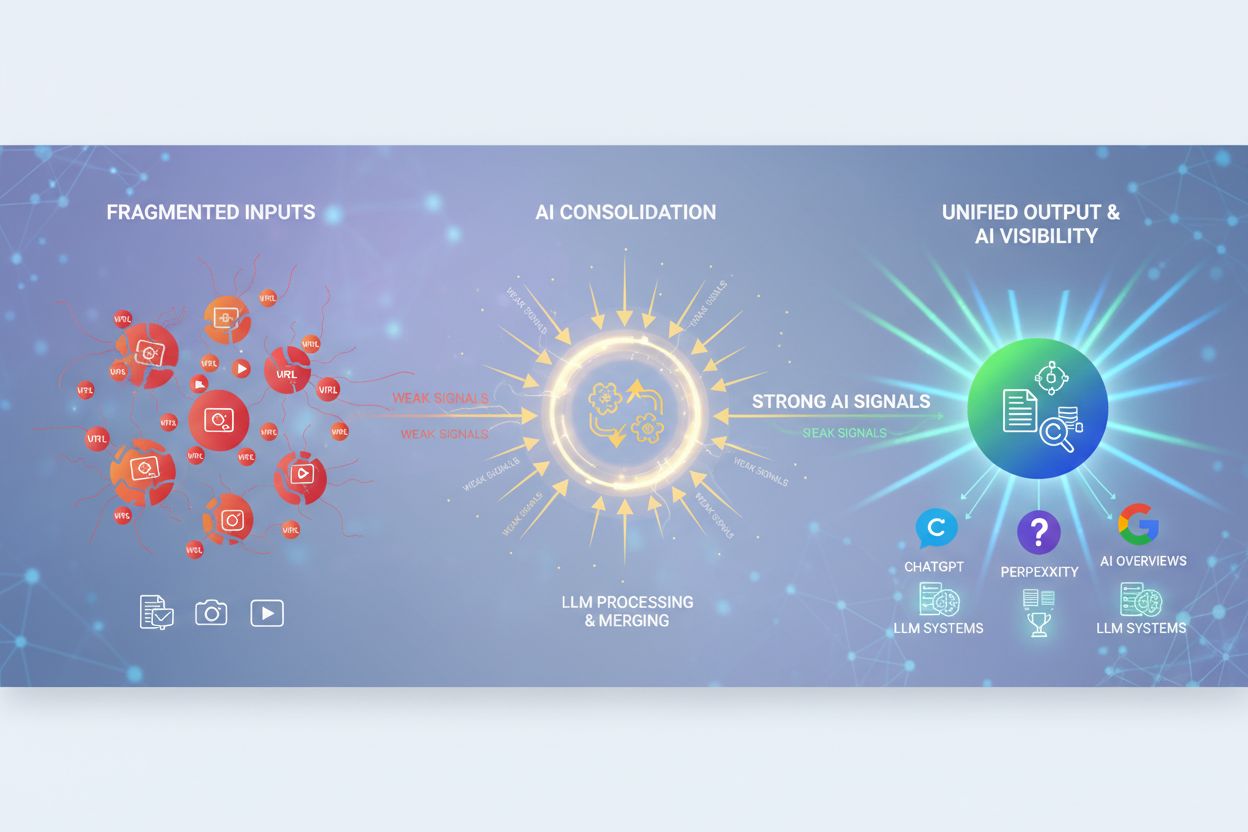
Zistite, čo je konsolidácia AI obsahu a ako spájanie podobného obsahu posilňuje signály viditeľnosti pre ChatGPT, Perplexity a Google AI Overviews. Objavte stra...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.