Strategická prax selektívneho povoľovania alebo blokovania AI crawlerov s cieľom kontrolovať, ako je obsah využívaný na trénovanie verzus na vyhľadávanie v reálnom čase. Zahŕňa používanie súborov robots.txt, serverových nastavení a monitorovacích nástrojov na riadenie toho, ktoré AI systémy môžu pristupovať k vášmu obsahu a na aké účely.
Správa AI crawlerov
Strategická prax selektívneho povoľovania alebo blokovania AI crawlerov s cieľom kontrolovať, ako je obsah využívaný na trénovanie verzus na vyhľadávanie v reálnom čase. Zahŕňa používanie súborov robots.txt, serverových nastavení a monitorovacích nástrojov na riadenie toho, ktoré AI systémy môžu pristupovať k vášmu obsahu a na aké účely.
Čo je správa AI crawlerov?
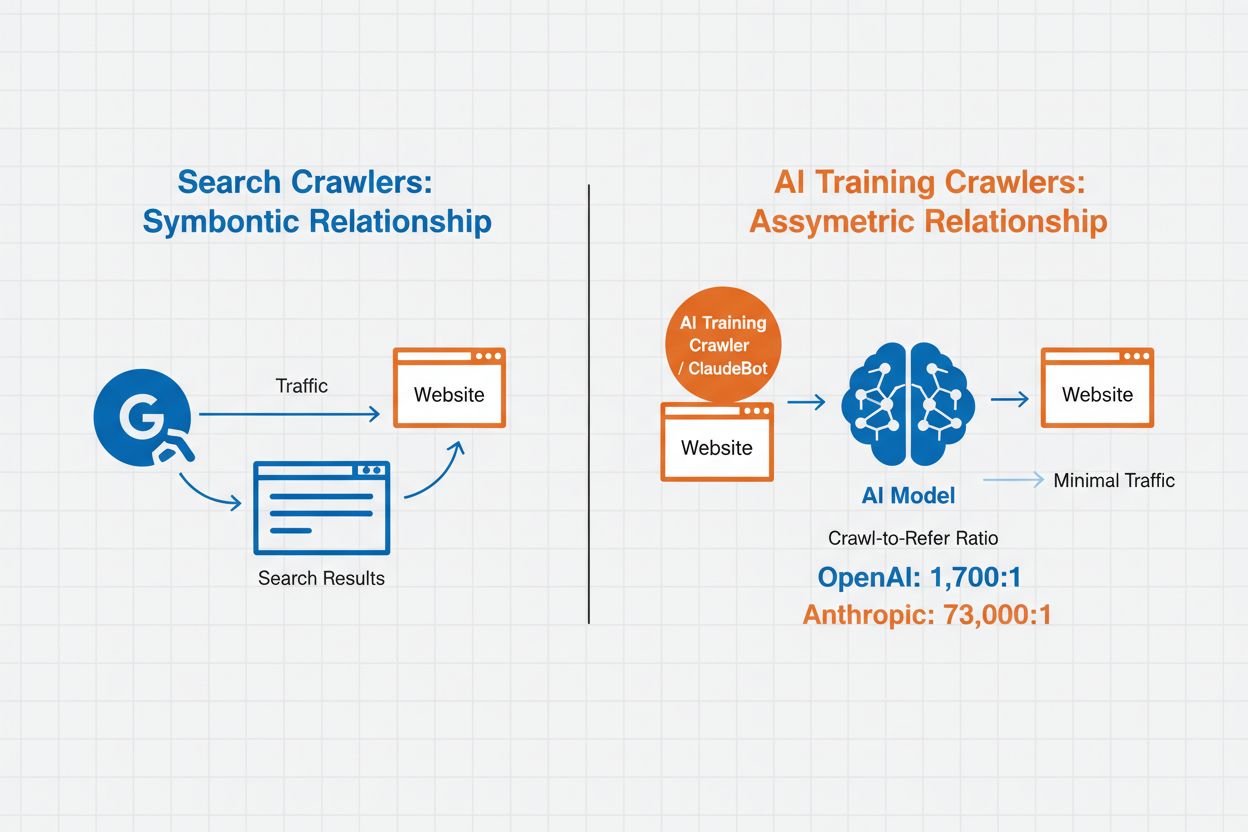
Správa AI crawlerov označuje prax riadenia a monitorovania toho, ako systémy umelej inteligencie pristupujú a využívajú obsah webových stránok na trénovanie a vyhľadávanie. Na rozdiel od tradičných vyhľadávacích crawlerov, ktoré indexujú obsah pre výsledky webového vyhľadávania, AI crawlery sú špeciálne navrhnuté na zber dát na trénovanie veľkých jazykových modelov alebo poháňanie AI vyhľadávacích funkcií. Rozsah tejto aktivity sa medzi organizáciami výrazne líši—crawlery OpenAI pracujú s pomerom crawl-to-refer 1 700:1, čo znamená, že pristupujú k obsahu 1 700-krát na každý odkaz, ktorý poskytnú, zatiaľ čo u Anthropicu je tento pomer až 73 000:1, čo poukazuje na obrovskú dátovú spotrebu potrebnú na trénovanie moderných AI systémov. Efektívna správa crawlerov umožňuje správcovi webu rozhodnúť, či jeho obsah prispeje k trénovaniu AI, zobrazí sa vo vyhľadávaní AI alebo zostane chránený pred automatizovaným prístupom.
Typy AI crawlerov
AI crawlery spadajú do troch odlišných kategórií podľa účelu a spôsobu využitia dát. Trénovacie crawlery sú určené na zber dát pre vývoj strojového učenia a spotrebúvajú veľké množstvá obsahu na zlepšovanie AI. Vyhľadávacie a citačné crawlery indexujú obsah na poháňanie AI vyhľadávacích funkcií a poskytovanie atribúcie v AI odpovediach, čo umožňuje používateľom objaviť váš obsah prostredníctvom AI rozhraní. Používateľom spúšťané crawlery fungujú na požiadanie, keď používateľ interaguje s AI nástrojmi, napríklad ak používateľ ChatGPT nahrá dokument alebo žiada analýzu konkrétnej webstránky. Pochopenie týchto kategórií vám pomôže rozhodnúť, ktoré crawlery povolíte alebo zablokujete, na základe vašej obsahovej stratégie a cieľov.
Typ crawlera
Účel
Príklady
Použité trénovacie dáta
Trénovací
Vývoj a zlepšovanie modelov
GPTBot, ClaudeBot
Áno
Vyhľadávací/Citačný
AI vyhľadávanie a atribúcia
Google-Extended, OAI-SearchBot, PerplexityBot
Rôzne
Spúšťaný používateľom
Analýza obsahu na požiadanie
ChatGPT-User, Meta-ExternalAgent, Amazonbot
Špecifické podľa kontextu
Prečo záleží na správe AI crawlerov
Správa AI crawlerov priamo ovplyvňuje návštevnosť, príjmy a hodnotu vášho obsahu. Keď crawlery spotrebúvajú váš obsah bez odmeny, strácate príležitosť profitovať z tejto návštevnosti prostredníctvom referralov, zobrazení reklám alebo zapojenia používateľov. Weby hlásia výrazné zníženie návštevnosti, keď používatelia nachádzajú odpovede priamo v AI generovaných odpovediach namiesto prekliku na pôvodný zdroj, čo v praxi znamená stratu referral návštevnosti a súvisiacich príjmov z reklám. Okrem finančných aspektov sú tu aj právne a etické otázky—váš obsah predstavuje duševné vlastníctvo a máte právo kontrolovať jeho využitie a či získate atribúciu alebo odmenu. Navyše, neobmedzený prístup crawlerov môže zvyšovať záťaž servera a náklady na prenos dát, najmä pri crawlery s agresívnymi rýchlosťami, ktoré nerešpektujú obmedzenia.
Robots.txt a technické kontroly
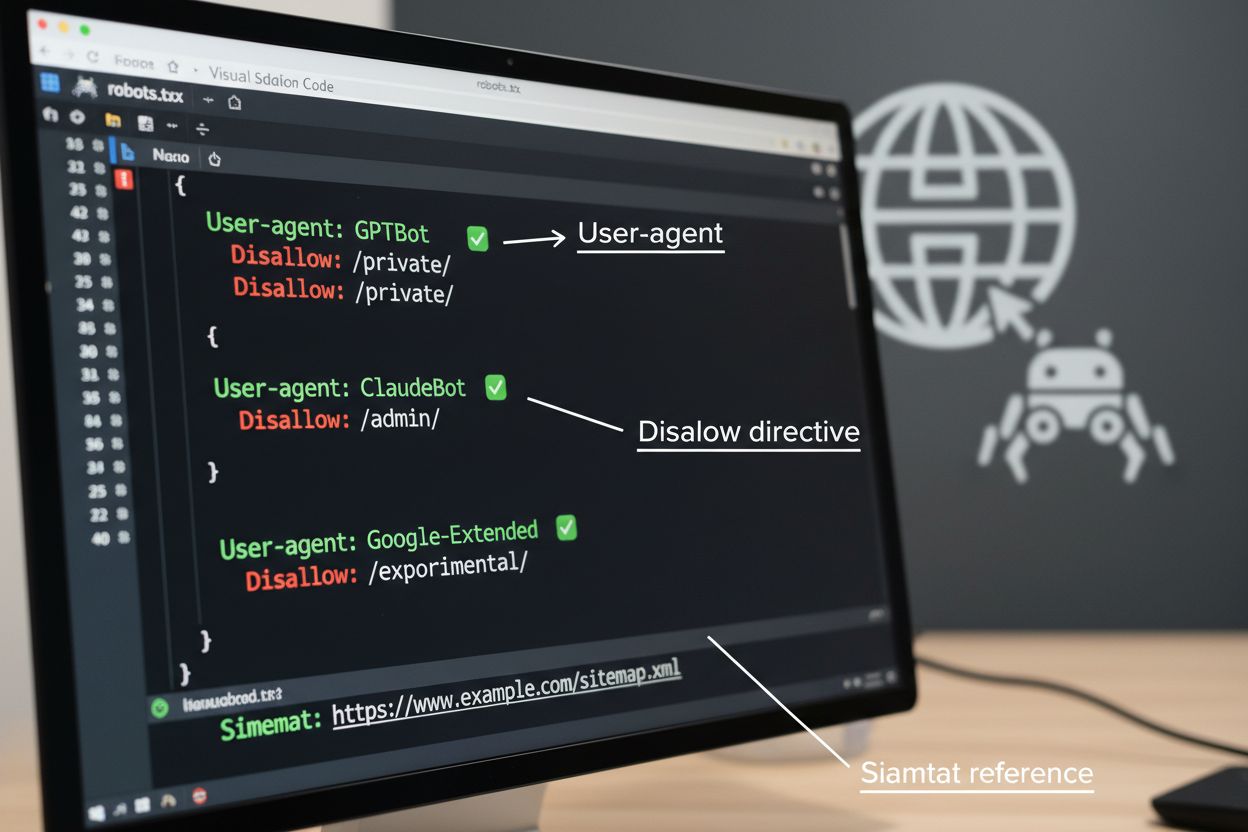
Súbor robots.txt je základným nástrojom na správu prístupu crawlerov, umiestnený v koreňovom adresári webu na komunikáciu preferencií pre automatizovaných agentov. Tento súbor používa direktívy User-agent na zacílenie konkrétnych crawlerov a pravidlá Disallow alebo Allow na povolenie či obmedzenie prístupu k určitým cestám a zdrojom. Robots.txt má však podstatné obmedzenia—je to dobrovoľný štandard závislý od ochoty crawlerov ho rešpektovať, a škodlivé či zle navrhnuté boty ho môžu úplne ignorovať. Robots.txt navyše nebráni crawlerom v prístupe k verejne dostupnému obsahu; len žiada, aby rešpektovali vaše preferencie. Preto by robots.txt mal byť súčasťou vrstveného prístupu k správe crawlerov, nie jedinou ochranou.
Okrem robots.txt existuje viacero pokročilých techník, ktoré poskytujú silnejšie vynútenie a detailnejšiu kontrolu prístupu crawlerov. Tieto metódy fungujú na rôznych vrstvách vašej infraštruktúry a je možné ich kombinovať pre komplexnú ochranu:
.htaccess pravidlá: Serverové direktívy, ktoré môžu blokovať konkrétnych user agentov alebo IP rozsahy ešte pred podaním obsahu
IP allowlisting/blocklisting: Obmedzenie prístupu na základe IP adries známych AI crawlerov—vyžaduje však udržiavanie aktuálnych zoznamov IP
Cloudflare WAF riešenia: Použitie pravidiel Web Application Firewall na identifikáciu a blokovanie crawlerov podľa správania a podpisov
HTTP hlavičky (X-Robots-Tag): Zasielanie crawler direktív priamo v odpovediach servera, čo umožňuje kontrolu na úrovni stránky alebo zdroja, ktorú je ťažšie ignorovať ako robots.txt
Rate limiting: Zavedenie prísnych limitov na rýchlosť crawlerov, aby sa zber veľkých dát stal ekonomicky nevýhodným
Fingerprinting botov: Analýza vzorcov požiadaviek, hlavičiek a správania na identifikáciu sofistikovaných crawlerov, ktoré sa vydávajú za niečo iné
Rovnováha medzi ochranou a viditeľnosťou
Rozhodnutie o blokovaní AI crawlerov so sebou prináša dôležité kompromisy medzi ochranou obsahu a jeho objaviteľnosťou. Blokovanie všetkých AI crawlerov vylučuje možnosť, aby sa váš obsah objavil vo výsledkoch AI vyhľadávania, AI sumarizáciách či bol citovaný AI nástrojmi—čo môže znížiť vašu viditeľnosť medzi používateľmi, ktorí objavujú obsah cez tieto nové kanály. Naopak, neobmedzený prístup znamená, že váš obsah slúži na trénovanie AI bez kompenzácie a môže znížiť referral návštevnosť, keďže používatelia dostanú odpovede priamo od AI. Strategický prístup znamená selektívne blokovanie: povoliť citačné crawlery ako OAI-SearchBot a PerplexityBot, ktoré prinášajú návštevnosť, a blokovať trénovacie crawlery ako GPTBot a ClaudeBot, ktoré spotrebúvajú dáta bez atribúcie. Zvážte tiež povolenie Google-Extended, aby ste udržali viditeľnosť v Google AI Overviews, ktoré môžu priniesť významnú návštevnosť, a zároveň blokujte trénovacie crawlery konkurencie. Optimálna stratégia závisí od typu obsahu, obchodného modelu a publika—spravodajské weby a vydavatelia môžu dávať prednosť blokovaniu, zatiaľ čo tvorcovia vzdelávacieho obsahu môžu profitovať zo širšej AI viditeľnosti.
Monitorovanie a vynucovanie
Implementácia kontrol crawlerov je účinná len vtedy, ak overíte, že crawlery skutočne rešpektujú vaše pravidlá. Analýza serverových logov je základnou metódou monitorovania aktivity crawlerov—skúmajte prístupové logy kvôli User-Agent reťazcom a vzorom požiadaviek, aby ste zistili, ktoré crawlery pristupujú na váš web a či rešpektujú pravidlá robots.txt. Mnohé crawlery tvrdia, že sú v súlade s pravidlami, no stále pristupujú k blokovaným cestám, preto je dôležité priebežné monitorovanie. Nástroje ako Cloudflare Radar poskytujú prehľad o vzoroch návštevnosti v reálnom čase a pomáhajú identifikovať podozrivé alebo nevyhovujúce správanie crawlerov. Nastavte si automatické upozornenia na pokusy o prístup k blokovaným zdrojom a pravidelne kontrolujte logy, aby ste zachytili nové crawlery alebo zmeny vzorcov, ktoré môžu signalizovať snahu o obchádzanie pravidiel.
Najlepšie postupy a implementácia
Efektívna správa AI crawlerov vyžaduje systematický prístup, ktorý vyvažuje ochranu a strategickú viditeľnosť. Postupujte podľa týchto ôsmich krokov na vytvorenie komplexnej stratégie správy crawlerov:
Audit aktuálneho prístupu: Analyzujte serverové logy a zistite, ktoré AI crawlery aktuálne pristupujú na váš web, ako často a k akým zdrojom
Stanovte svoju politiku: Rozhodnite, ktoré crawlery sú v súlade s vašimi obchodnými cieľmi—zvážte trénovacie vs. vyhľadávacie crawlery, vplyv na návštevnosť a hodnotu obsahu
Zaznamenajte rozhodnutia: Vytvorte jasnú dokumentáciu svojej politiky a dôvodov za každým rozhodnutím pre budúcu orientáciu a zladenie tímu
Implementujte kontroly: Nasadzujte pravidlá robots.txt, HTTP hlavičky a pokročilé kontroly ako rate limiting či IP blokovanie podľa vašej politiky
Monitorujte dodržiavanie: Pravidelne kontrolujte serverové logy a využívajte monitorovacie nástroje na overenie, či crawlery rešpektujú vaše pravidlá
Nastavte upozornenia: Nakonfigurujte automatické upozornenia na nevyhovujúci prístup crawlerov alebo pokusy o obídenie vašich kontrol
Štvrťročne revidujte: Prehodnocujte stratégiu správy crawlerov každé štvrťroky podľa nových crawlerov a vývoja vašich potrieb
Aktualizujte pri vzniku nových crawlerov: Sledujte nové AI crawlery a aktualizujte opatrenia proaktívne, nie reaktívne
AmICited.com: Sledujte svoje AI odkazy
AmICited.com je špecializovaná platforma na monitorovanie toho, ako AI systémy odkazujú a používajú váš obsah naprieč rôznymi modelmi a aplikáciami. Služba ponúka sledovanie vašich citácií v AI generovaných odpovediach v reálnom čase, čo vám umožní pochopiť, ktoré crawlery najviac používajú váš obsah a ako často sa vaša práca objavuje vo výstupoch AI. Analýzou vzorcov crawlerov a citácií vám AmICited.com umožní robiť rozhodnutia o stratégii správy crawlerov na základe dát—môžete presne vidieť, ktoré crawlery prinášajú hodnotu prostredníctvom citácií a referralov a ktoré len spotrebúvajú obsah bez atribúcie. Tieto informácie menia správu crawlerov z defenzívnej činnosti na strategický nástroj na optimalizáciu viditeľnosti a vplyvu vášho obsahu vo svete poháňanom umelou inteligenciou.
Najčastejšie kladené otázky
Trénovacie crawlery ako GPTBot a ClaudeBot zbierajú obsah na vytváranie datasetov pre vývoj veľkých jazykových modelov, pričom spotrebúvajú váš obsah bez toho, aby vám prinášali návštevnosť. Vyhľadávacie crawlery ako OAI-SearchBot a PerplexityBot indexujú obsah pre AI vyhľadávacie výsledky a môžu priniesť návštevníkov späť na váš web prostredníctvom citácií. Blokovanie trénovacích crawlerov chráni váš obsah pred zahrnutím do AI modelov, zatiaľ čo blokovanie vyhľadávacích crawlerov môže znížiť vašu viditeľnosť na AI vyhľadávacích platformách.
Nie. Blokovanie AI trénovacích crawlerov ako GPTBot, ClaudeBot a CCBot nemá vplyv na vaše pozície vo vyhľadávačoch Google alebo Bing. Tradičné vyhľadávače používajú iné crawlery (Googlebot, Bingbot), ktoré fungujú nezávisle od AI trénovacích botov. Tradičné vyhľadávacie crawlery blokujte len v prípade, ak chcete úplne zmiznúť z výsledkov vyhľadávania, čo by poškodilo vaše SEO.
Preskúmajte prístupové logy vášho servera a identifikujte User-Agent reťazce crawlerov. Hľadajte záznamy obsahujúce 'bot', 'crawler' alebo 'spider' v poli User-Agent. Nástroje ako Cloudflare Radar poskytujú prehľad v reálnom čase o tom, ktoré AI crawlery pristupujú na vašu stránku a ich vzory návštevnosti. Môžete tiež použiť analytické platformy, ktoré rozlišujú medzi botmi a ľudskými návštevníkmi.
Áno. robots.txt je odporúčací štandard, ktorý závisí od ochoty crawlerov ho dodržiavať—nie je vynútiteľný. Dobre správané crawlery od veľkých spoločností ako OpenAI, Anthropic a Google vo všeobecnosti rešpektujú pravidlá robots.txt, ale niektoré crawlery ich úplne ignorujú. Pre silnejšiu ochranu implementujte blokovanie na úrovni servera cez .htaccess, firewall pravidlá alebo IP obmedzenia.
Závisí to od vašich obchodných priorít. Blokovanie všetkých trénovacích crawlerov chráni váš obsah pred zahrnutím do AI modelov, zatiaľ čo môžete povoliť vyhľadávacie crawlery, ktoré môžu priniesť návštevnosť. Mnohí vydavatelia používajú selektívne blokovanie, ktoré cieli na trénovacie crawlery a povoľuje vyhľadávacie a citačné crawlery. Zvážte typ obsahu, zdroje návštevnosti a model monetizácie pri rozhodovaní o stratégii.
Prekontrolujte a aktualizujte svoju politiku správy crawlerov minimálne štvrťročne. Nové AI crawlery sa objavujú pravidelne a existujúce crawlery menia svoje user agenty bez oznámenia. Sledujte zdroje ako projekt ai.robots.txt na GitHube pre komunitou udržiavané zoznamy a mesačne kontrolujte svoje serverové logy, aby ste identifikovali nové crawlery na vašom webe.
AI crawlery môžu výrazne ovplyvniť vašu návštevnosť a príjmy. Ak používatelia získavajú odpovede priamo z AI systémov namiesto návštevy vašej stránky, stratíte referral návštevnosť a súvisiace zobrazenia reklám. Výskumy ukazujú pomer crawl-to-refer až 73 000:1 pri niektorých AI platformách, čo znamená, že pristupujú k vášmu obsahu tisíce krát na každého návštevníka, ktorého pošlú späť. Blokovanie trénovacích crawlerov môže ochrániť vašu návštevnosť, zatiaľ čo povolenie vyhľadávacích crawlerov môže priniesť určité referral výhody.
Skontrolujte svoje serverové logy, či sa blokované crawlery stále objavujú v prístupových logoch. Použite testovacie nástroje ako robots.txt tester v Google Search Console alebo Merkle's Robots.txt Tester na validáciu konfigurácie. Prístupom na svoj robots.txt súbor na vašomsite.com/robots.txt si overte, že obsah je správny. Pravidelne sledujte svoje logy, aby ste zachytili crawlery, ktoré by mali byť blokované, ale stále sa objavujú.
Sledujte, ako AI systémy odkazujú na váš obsah
AmICited.com sleduje v reálnom čase AI odkazy na vašu značku v ChatGPT, Perplexity, Google AI Overviews a iných AI systémoch. Robte rozhodnutia o stratégii správy crawlerov založené na dátach.
Ktorým AI crawlerom by ste mali povoliť prístup? Kompletný sprievodca pre rok 2025
Zistite, ktorým AI crawlerom povoliť alebo zablokovať prístup vo vašom robots.txt. Komplexný sprievodca pokrývajúci GPTBot, ClaudeBot, PerplexityBot a ďalších 2...
Ako identifikovať AI crawlerov v serverových logoch: Kompletný sprievodca detekciou
Zistite, ako identifikovať a monitorovať AI crawlery ako GPTBot, PerplexityBot a ClaudeBot vo vašich serverových logoch. Objavte user-agent reťazce, metódy over...
Vplyv AI crawlerov na serverové zdroje: Čo očakávať
Zistite, ako AI crawlery ovplyvňujú serverové zdroje, šírku pásma a výkon. Objavte reálne štatistiky, stratégie zmiernenia a infraštruktúrne riešenia na efektív...
9 min čítania
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.