
Čo je atribúcia AI viditeľnosti a ako ovplyvňuje vašu značku?
Zistite, čo je atribúcia AI viditeľnosti, ako sa líši od tradičného SEO a prečo je monitorovanie výskytu vašej značky v odpovediach generovaných AI kľúčové pre ...
11 min čítania
Mechanizmus pozornosti je komponent neurónovej siete, ktorý dynamicky váži dôležitosť rôznych vstupných prvkov, čo umožňuje modelom sústrediť sa na najrelevantnejšie časti dát pri predikciách. Počítaním váh pozornosti pomocou naučených transformácií dotazov, kľúčov a hodnôt umožňuje modelom hlbokého učenia zachytávať dlhodobé závislosti a vzťahy v sekvenčných dátach.
Mechanizmus pozornosti je komponent neurónovej siete, ktorý dynamicky váži dôležitosť rôznych vstupných prvkov, čo umožňuje modelom sústrediť sa na najrelevantnejšie časti dát pri predikciách. Počítaním váh pozornosti pomocou naučených transformácií dotazov, kľúčov a hodnôt umožňuje modelom hlbokého učenia zachytávať dlhodobé závislosti a vzťahy v sekvenčných dátach.
Mechanizmus pozornosti je technika strojového učenia, ktorá usmerňuje modely hlbokého učenia, aby uprednostňovali (alebo „venovali pozornosť“) najrelevantnejším častiam vstupných dát pri predikcii. Namiesto toho, aby všetky vstupné prvky boli považované za rovnocenné, mechanizmy pozornosti počítajú váhy pozornosti, ktoré odrážajú relatívnu dôležitosť každého prvku pre danú úlohu, a tieto váhy potom dynamicky zdôrazňujú alebo potláčajú konkrétne vstupy. Táto zásadná inovácia sa stala základným kameňom moderných transformerových architektúr a veľkých jazykových modelov (LLM) ako ChatGPT, Claude a Perplexity, ktoré im umožňujú spracovávať sekvenčné dáta s bezprecedentnou efektivitou a presnosťou. Mechanizmus je inšpirovaný ľudskou kognitívnou pozornosťou – schopnosťou selektívne sa sústrediť na dôležité detaily a súčasne filtrovať irelevantné informácie – pričom tento biologický princíp je matematicky rigorózne a naučiteľne prenesený do komponentu neurónovej siete.
Koncept mechanizmov pozornosti prvýkrát predstavil Bahdanau a kolegovia v roku 2014, aby vyriešili kritické obmedzenia rekurentných neurónových sietí (RNN) používaných na strojový preklad. Pred zavedením pozornosti sa Seq2Seq modely spoliehali na jediný kontextový vektor, ktorý kódoval celé zdrojové vety, čím vznikalo úzke hrdlo informácií, ktoré výrazne obmedzovalo výkon pri dlhších sekvenciách. Pôvodný mechanizmus pozornosti umožnil dekodéru pristupovať ku všetkým skrytým stavom enkodéra namiesto len k poslednému, pričom dynamicky vyberal tie časti vstupu, ktoré sú v každom dekódovacom kroku najrelevantnejšie. Tento prelom dramaticky zlepšil kvalitu prekladov, najmä pri dlhších vetách. V roku 2015 Luong a kolegovia predstavili skalárnu pozornosť, ktorá nahradila výpočtovo náročnú aditívnu pozornosť efektívnou maticovou násobou. Zlom nastal v roku 2017 s publikáciou “Attention is All You Need”, ktorá zaviedla transformerovú architektúru úplne bez rekurencie, postavenú výlučne na mechanizmoch pozornosti. Tento článok spôsobil revolúciu v hlbokom učení a umožnil vznik BERT-u, GPT modelov a celého moderného generatívneho AI ekosystému. Dnes sú mechanizmy pozornosti všadeprítomné v spracovaní prirodzeného jazyka, počítačovom videní aj multimodálnych AI systémoch, pričom viac ako 85 % najmodernejších modelov obsahuje nejakú formu architektúry založenej na pozornosti.
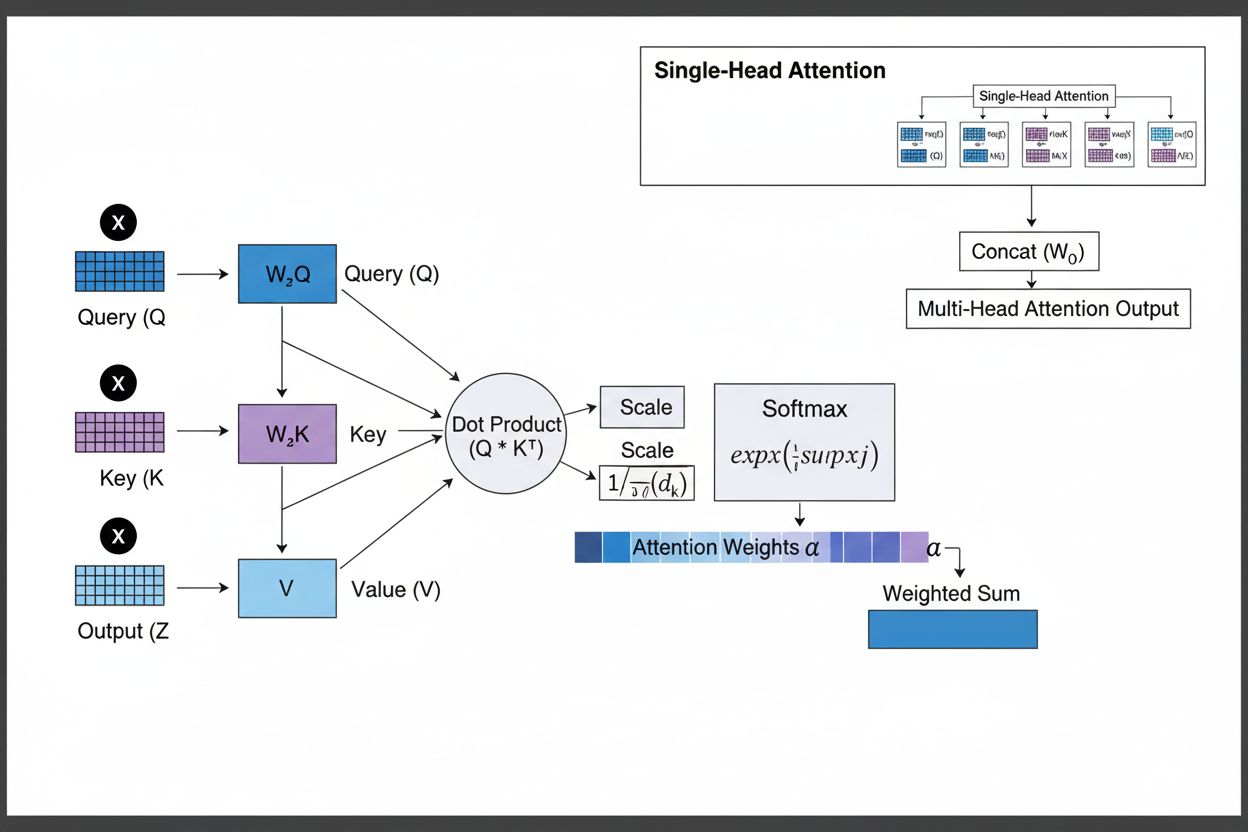
Mechanizmus pozornosti funguje prostredníctvom sofistikovanej interakcie troch hlavných matematických komponentov: dotazy (Q), kľúče (K) a hodnoty (V). Každý vstupný prvok je transformovaný do týchto troch reprezentácií prostredníctvom naučených lineárnych projekcií, čím vzniká štruktúra podobná relačnej databáze, kde kľúče slúžia ako identifikátory a hodnoty obsahujú skutočné informácie. Mechanizmus počíta zarovnávacie skóre meraním podobnosti medzi dotazom a všetkými kľúčmi, najčastejšie pomocou škálovanej skalárnej pozornosti, kde sa skóre počíta ako QK^T/√d_k. Tieto surové skóre sa následne normalizujú pomocou softmax funkcie, ktorá ich prevedie na pravdepodobnostné rozdelenie so súčtom váh 1, čím každý prvok dostane váhu medzi 0 a 1. Posledným krokom je výpočet váženého súčtu vektorov hodnôt podľa týchto váh pozornosti, čím vzniká kontextový vektor reprezentujúci najrelevantnejšie informácie z celej vstupnej sekvencie. Tento kontextový vektor sa potom kombinuje s pôvodným vstupom cez reziduálne spojenia a prechádza cez dopredné vrstvy, čo modelu umožňuje iteratívne spresňovať svoje chápanie vstupu. Matematická elegancia tohto dizajnu – spájajúca naučiteľné transformácie, výpočty podobnosti a pravdepodobnostné váženie – umožňuje mechanizmom pozornosti zachytávať komplexné závislosti a pritom zostať plne diferencovateľné pre optimalizáciu na základe gradientov.
| Typ pozornosti | Metóda výpočtu | Výpočtová zložitosť | Najlepšie použitie | Kľúčová výhoda |
|---|---|---|---|---|
| Aditívna pozornosť | Dopredná sieť + tanh aktivácia | O(n·d) na dotaz | Kratšie sekvencie, variabilné dimenzie | Zvláda rôzne dimenzie dotazu/kľúča |
| Skalárna pozornosť | Jednoduché maticové násobenie | O(n·d) na dotaz | Štandardné sekvencie | Výpočtovo efektívna |
| Škálovaná skalárna | QK^T/√d_k + softmax | O(n·d) na dotaz | Moderné transformery | Zabraňuje zániku gradientov |
| Multi-head attention | Viacero paralelných hláv pozornosti | O(h·n·d) kde h=hlavy | Komplexné vzťahy | Zachytáva rôznorodé sémantické aspekty |
| Self-attention | Dotazy, kľúče, hodnoty z rovnakej sekvencie | O(n²·d) | Vnútrosekvenčné vzťahy | Umožňuje paralelné spracovanie |
| Cross-attention | Dotazy z jednej sekvencie, kľúče/hodnoty z inej | O(n·m·d) | Encoder-decoder, multimodálne | Zlaďuje rôzne modality |
| Grouped query attention | Zdieľa kľúče/hodnoty medzi hlavami dotazov | O(n·d) | Efektívna inferencia | Znižuje pamäť a výpočty |
| Sparsna pozornosť | Limitovaná pozornosť na lokálne/striedané pozície | O(n·√n·d) | Veľmi dlhé sekvencie | Zvláda extrémne dĺžky sekvencií |
Mechanizmus pozornosti pracuje prostredníctvom presne organizovanej sekvencie matematických transformácií, ktoré umožňujú neurónovým sieťam dynamicky sa sústrediť na relevantné informácie. Pri spracovaní vstupnej sekvencie je každý prvok najprv zabudovaný do vektora s vysokou dimenziou, ktorý zachytáva sémantické a syntaktické informácie. Tieto embeddingy sú potom projektované do troch samostatných priestorov pomocou naučených váhových matíc: priestor dotazov (čo sa hľadá), priestor kľúčov (aké informácie každý prvok obsahuje) a priestor hodnôt (skutočné informácie na agregáciu). Pre každú pozíciu dotazu mechanizmus počíta skóre podobnosti so všetkými kľúčmi ako ich skalárny súčin, čím vznikne vektor surových skóre zarovnania. Tieto skóre sa škálujú delením odmocninou z dimenzie kľúča (√d_k), čo je kľúčové pre zabránenie ich prílišnému narastaniu pri vysokých dimenziách a tým zániku gradientov počas spätného šírenia. Škálované skóre prechádzajú cez softmax funkciu, ktorá ich exponuje a normalizuje na súčet 1, čím vznikne pravdepodobnostné rozdelenie cez všetky pozície vstupu. Napokon sa tieto váhy pozornosti použijú na výpočet váženého priemeru hodnôt, kde pozície s vyššími váhami viac ovplyvňujú výsledný kontextový vektor. Tento kontextový vektor sa následne kombinuje s pôvodným vstupom cez reziduálne spojenia a spracováva cez dopredné vrstvy, čo modelu umožňuje iteratívne spresňovať svoje reprezentácie. Celý proces je diferencovateľný, takže model sa môže učiť optimálne vzory pozornosti počas trénovania pomocou gradientného zostupu.
Mechanizmy pozornosti tvoria základný stavebný prvok transformerových architektúr, ktoré sa stali dominantným prístupom v hlbokom učení. Na rozdiel od RNN, ktoré spracovávajú sekvencie sekvenčne, a CNN, ktoré pracujú s fixnými lokálnymi oknami, transformery využívajú self-attention na to, aby sa každá pozícia mohla súčasne sústrediť na všetky ostatné, čo umožňuje masívnu paralelizáciu na GPU a TPU. Transformerová architektúra pozostáva zo striedajúcich sa vrstiev multi-head self-attention a dopredných sietí, pričom každá vrstva pozornosti umožňuje modelu selektívne sa sústrediť na rôzne aspekty vstupu. Multi-head attention spúšťa viacero mechanizmov pozornosti paralelne, pričom každá hlava sa špecializuje na iné typy vzťahov – jedna môže sledovať gramatickú závislosť, druhá sémantické vzťahy, tretia dlhodobé koreferencie. Výstupy zo všetkých hláv sa spoja a projektujú, čo modelu umožňuje udržať si vedomosť o viacerých jazykových javoch naraz. Táto architektúra sa ukázala mimoriadne účinná pre veľké jazykové modely ako GPT-4, Claude 3 či Gemini, ktoré využívajú decoder-only transformer architektúru, kde každý token môže venovať pozornosť len predchádzajúcim tokenom (kauzálne maskovanie), aby sa zachovala autoregresívna vlastnosť generovania. Schopnosť mechanizmu pozornosti zachytávať dlhodobé závislosti bez problémov so zánikom gradientov, ktoré trápili RNN, bola kľúčová pre to, aby tieto modely zvládali kontextové okná s veľkosťou 100 000+ tokenov a udržiavali koherenciu a konzistenciu na veľkých textoch. Výskumy ukazujú, že približne 92 % najmodernejších NLP modelov sa dnes spolieha na transformerové architektúry poháňané mechanizmami pozornosti, čo dokazuje ich zásadný význam pre moderné AI systémy.
V kontexte AI vyhľadávacích platforiem ako ChatGPT, Perplexity, Claude či Google AI Overviews zohrávajú mechanizmy pozornosti kľúčovú úlohu pri určovaní, ktoré časti vyhľadaných dokumentov a znalostných báz sú pre dotazy používateľov najrelevantnejšie. Pri generovaní odpovedí tieto systémy dynamicky vážia rôzne zdroje a pasáže podľa relevantnosti, čo im umožňuje syntetizovať koherentné odpovede z viacerých zdrojov a zároveň zachovať faktickú presnosť. Váhy pozornosti vypočítané počas generovania je možné analyzovať, aby sa pochopilo, ktorým informáciám model pridelil prioritu, čo poskytuje pohľad na to, ako AI systémy interpretujú a reagujú na dotazy. Pre monitoring značky a GEO (Generative Engine Optimization) je pochopenie mechanizmov pozornosti zásadné, pretože určujú, ktorý obsah a zdroje získajú dôraz v AI-generovaných odpovediach. Obsah štruktúrovaný tak, aby zodpovedal tomu, ako mechanizmy pozornosti vážia informácie – jasné definície entít, autoritatívne zdroje a kontextová relevantnosť – má väčšiu šancu byť citovaný a prominentne zobrazený v AI odpovediach. AmICited využíva poznatky o mechanizmoch pozornosti na sledovanie, ako sa značky a domény objavujú naprieč AI platformami, pričom rozpoznáva, že citácie vážené pozornosťou predstavujú najvplyvnejšie zmienky v AI-generovanom obsahu. Ako podniky čoraz viac monitorujú svoju prítomnosť v AI odpovediach, pochopenie, že mechanizmy pozornosti riadia vzory citácií, je kľúčové pre optimalizáciu obsahovej stratégie a zabezpečenie viditeľnosti značky v ére generatívnej AI.
Oblasť mechanizmov pozornosti sa naďalej rýchlo vyvíja, pričom výskumníci vyvíjajú čoraz sofistikovanejšie varianty na riešenie výpočtových obmedzení a zlepšovanie výkonu. Sparsne vzory pozornosti obmedzujú pozornosť na lokálne susedstvá alebo striedané pozície, čím znižujú zložitosť z O(n²) na O(n·√n) pri zachovaní výkonu na veľmi dlhých sekvenciách. Efektívne mechanizmy pozornosti ako FlashAttention optimalizujú pamäťové operácie výpočtu pozornosti a dosahujú 2–4-násobné zrýchlenie lepším využitím GPU. Grouped query attention a multi-query attention znižujú počet kľúčových-hodnotových hláv pri zachovaní výkonu, čím výrazne klesajú pamäťové nároky počas inferencie – čo je kľúčové pre nasadenie veľkých modelov do produkcie. Architektúry mixture of experts kombinujú pozornosť s riedkym smerovaním, čo modelom umožňuje škálovať sa do biliónov parametrov pri zachovaní výpočtovej efektivity. Nový výskum skúma naučené vzory pozornosti, ktoré sa dynamicky prispôsobujú charakteristikám vstupu, a hierarchickú pozornosť na viacerých úrovniach abstrakcie. Integrácia mechanizmov pozornosti s retrieval-augmented generation (RAG) umožňuje modelom dynamicky venovať pozornosť relevantným externým znalostiam, čím sa zlepšuje faktickosť a znižuje halucinovanie. Ako sa AI systémy nasadzujú v kritických aplikáciách, mechanizmy pozornosti sa rozširujú o vysvetliteľné prvky, ktoré poskytujú jasnejší pohľad na rozhodovanie modelu. Budúcnosť pravdepodobne prinesie hybridné architektúry kombinujúce pozornosť s alternatívnymi prístupmi ako state-space models (napr. Mamba), ktoré ponúkajú lineárnu zložitosť pri zachovaní konkurencieschopného výkonu. Pochopenie týchto vyvíjajúcich sa mechanizmov pozornosti je zásadné pre odborníkov budujúcich ďalšiu generáciu AI systémov aj pre organizácie sledujúce svoju prítomnosť v AI-generovanom obsahu, keďže mechanizmy rozhodujúce o vzoroch citácií a viditeľnosti obsahu sa neustále zdokonaľujú.
Pre organizácie používajúce AmICited na monitorovanie viditeľnosti značky v AI odpovediach poskytuje pochopenie mechanizmov pozornosti zásadný kontext na interpretáciu vzorov citácií. Keď ChatGPT, Claude alebo Perplexity citujú vašu doménu vo svojich odpovediach, váhy pozornosti vypočítané počas generovania rozhodli, že váš obsah bol najrelevantnejší pre dotaz používateľa. Kvalitný, dobre štruktúrovaný obsah, ktorý jasne definuje entity a poskytuje autoritatívne informácie, prirodzene získava vyššie váhy pozornosti, čo zvyšuje pravdepodobnosť, že bude vybraný na citáciu. Vizualizácie pozornosti v niektorých AI platformách ukazujú, ktoré zdroje získali najviac pozornosti pri generovaní odpovedí, a teda ktoré citácie boli najvplyvnejšie. Tento pohľad umožňuje organizáciám optimalizovať svoju obsahovú stratégiu na základe poznania, že mechanizmy pozornosti odmeňujú jasnosť, relevantnosť a autoritatívne zdroje. Ako AI vyhľadávanie rastie – viac ako 60 % podnikov už investuje do iniciatív generatívnej AI – schopnosť porozumieť a optimalizovať pre mechanizmy pozornosti je čoraz dôležitejšia pre udržanie viditeľnosti značky a presné zastúpenie v AI-generovanom obsahu. Prienik medzi mechanizmy pozornosti a monitoring značky predstavuje novú hranicu v oblasti GEO, kde pochopenie matematických základov, ako AI systémy vážia a citujú informácie, priamo vedie k lepšej viditeľnosti a vplyvu v ekosystéme generatívnej AI.
Tradičné RNN spracovávajú sekvencie sériovo, čo sťažuje zachytenie dlhodobých závislostí, zatiaľ čo CNN majú fixné lokálne recepčné polia, ktoré obmedzujú ich schopnosť modelovať vzdialené vzťahy. Mechanizmy pozornosti tieto obmedzenia prekonávajú výpočtom vzťahov medzi všetkými vstupnými pozíciami súčasne, čo umožňuje paralelné spracovanie a zachytenie závislostí bez ohľadu na vzdialenosť. Táto flexibilita v čase aj priestore robí mechanizmy pozornosti oveľa efektívnejšími a účinnejšími pre komplexné sekvenčné a priestorové dáta.
Dotazy predstavujú, aké informácie model aktuálne hľadá, kľúče predstavujú informačný obsah, ktorý každý vstupný prvok obsahuje, a hodnoty obsahujú skutočné dáta, ktoré sa majú agregovať. Model počíta skóre podobnosti medzi dotazmi a kľúčmi, aby určil, ktoré hodnoty by mali byť najviac vážené. Táto terminológia inšpirovaná databázami, popularizovaná článkom 'Attention is All You Need', poskytuje intuitívny rámec na pochopenie toho, ako mechanizmy pozornosti selektívne vyhľadávajú a kombinujú relevantné informácie zo vstupných sekvencií.
Self-attention počíta vzťahy v rámci jednej vstupnej sekvencie, kde dotazy, kľúče a hodnoty pochádzajú z rovnakého zdroja, čo umožňuje modelu pochopiť, ako spolu súvisia rôzne prvky. Cross-attention naproti tomu používa dotazy z jednej sekvencie a kľúče/hodnoty z inej sekvencie, čo modelu umožňuje zladiť a kombinovať informácie z viacerých zdrojov. Cross-attention je kľúčové v architektúrach encoder-decoder, ako je strojový preklad, a v multimodálnych modeloch ako Stable Diffusion, ktoré kombinujú textové a obrazové informácie.
Škálovaná skalárna pozornosť používa násobenie namiesto sčítania na výpočet skóre zarovnania, čo je výpočtovo efektívnejšie vďaka maticovým operáciám využívajúcim paralelizáciu na GPU. Škálovací faktor 1/√dk zabraňuje tomu, aby skalárne súčiny pri vysokej dimenzii kľúčov príliš narástli, čo by počas spätného šírenia spôsobilo zánik gradientov. Aj keď aditívna pozornosť niekedy prekonáva skalárnu pri veľmi veľkých dimenziách, výpočtová efektivita a praktický výkon škálovanej skalárnej pozornosti z nej robia štandard v moderných transformerových architektúrach.
Multi-head attention spúšťa viacero mechanizmov pozornosti paralelne, pričom každá hlava sa učí sústrediť na iné aspekty vstupu, napríklad gramatické vzťahy, sémantický význam alebo vzdialené závislosti. Každá hlava pracuje s inou lineárnou projekciou vstupu, čo modelu umožňuje zachytiť rozličné typy vzťahov súčasne. Výstupy zo všetkých hláv sa spoja a projektujú, čo modelu umožňuje udržať si komplexné povedomie o viacerých jazykových a kontextových prvkoch naraz, čím sa výrazne zlepšuje kvalita reprezentácie a výkon pri následných úlohách.
Softmax normalizuje surové skóre zarovnania vypočítané medzi dotazmi a kľúčmi do pravdepodobnostného rozdelenia, kde všetky váhy dávajú dokopy 1. Táto normalizácia zabezpečuje, že váhy pozornosti sú interpretovateľné ako skóre dôležitosti, pričom vyššie hodnoty znamenajú väčšiu relevantnosť. Softmax je diferencovateľný, čo umožňuje učenie mechanizmu pozornosti počas trénovania na základe gradientov, a jeho exponenciálny charakter zdôrazňuje rozdiely medzi skóre, vďaka čomu je zameranie modelu selektívnejšie a interpretovateľnejšie.
Mechanizmy pozornosti umožňujú týmto modelom dynamicky vážiť rôzne časti vstupného promptu podľa relevantnosti k aktuálnemu kroku generovania. Pri generovaní odpovede model využíva pozornosť na určenie, ktoré predchádzajúce tokeny a vstupné prvky by mali najviac ovplyvniť predikciu ďalšieho tokenu. Toto kontextovo citlivé váženie umožňuje modelom udržať koherenciu, sledovať entity v dlhých dokumentoch, rozriešiť nejednoznačnosti a generovať odpovede, ktoré primerane odkazujú na konkrétne časti vstupu, čím sa zvyšuje presnosť a kontextová vhodnosť ich výstupov.
Začnite sledovať, ako AI chatboty spomínajú vašu značku na ChatGPT, Perplexity a ďalších platformách. Získajte použiteľné poznatky na zlepšenie vašej prítomnosti v AI.
Zistite, čo je atribúcia AI viditeľnosti, ako sa líši od tradičného SEO a prečo je monitorovanie výskytu vašej značky v odpovediach generovaných AI kľúčové pre ...

Naučte sa, ako efektívne robiť výskum promptov pre AI viditeľnosť. Objavte metodológiu na pochopenie používateľských otázok v LLM a sledujte svoju značku v Chat...
Zistite viac o klasifikácii zámeru dopytu – ako AI systémy kategorizujú dopyty používateľov podľa zámeru (informačné, navigačné, transakčné, porovnávacie). Poch...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.