
Sémantická podobnosť
Sémantická podobnosť meria významovú príbuznosť medzi textami pomocou embeddingov a metrík vzdialenosti. Kľúčová pre AI monitoring, párovanie obsahu a sledovani...
11 min čítania
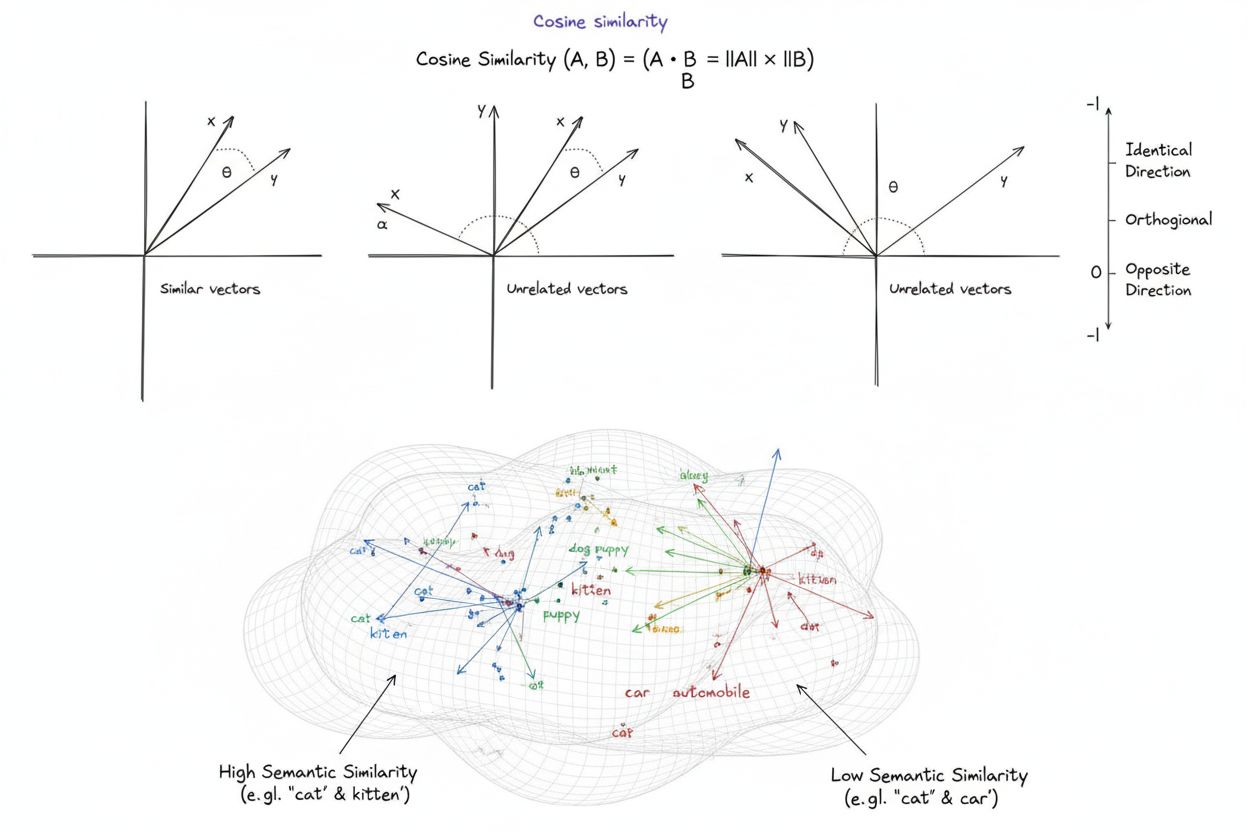
Kosínová podobnosť je matematická miera, ktorá vypočítava podobnosť medzi dvoma nenulovými vektormi určením kosínu uhla medzi nimi, čím vzniká skóre v rozsahu od -1 do 1. Široko sa používa v strojovom učení, spracovaní prirodzeného jazyka a AI systémoch na meranie sémantickej podobnosti medzi textovými embeddingami a vektorovými reprezentáciami, nezávisle od veľkosti vektora.
Kosínová podobnosť je matematická miera, ktorá vypočítava podobnosť medzi dvoma nenulovými vektormi určením kosínu uhla medzi nimi, čím vzniká skóre v rozsahu od -1 do 1. Široko sa používa v strojovom učení, spracovaní prirodzeného jazyka a AI systémoch na meranie sémantickej podobnosti medzi textovými embeddingami a vektorovými reprezentáciami, nezávisle od veľkosti vektora.
Kosínová podobnosť je matematická miera, ktorá vypočítava podobnosť medzi dvoma nenulovými vektormi určením kosínu uhla medzi nimi vo viacrozmernom priestore. Metrika vytvára skóre v rozsahu od -1 do 1, kde skóre 1 znamená, že vektory smerujú identickým smerom, 0 znamená ortogonálne (kolmé) vektory bez smerového vzťahu a -1 znamená, že vektory smerujú presne opačnými smermi. V praktických aplikáciách je kosínová podobnosť mimoriadne cenná, pretože meria smerovú zhodu namiesto absolútnej vzdialenosti, vďaka čomu je nezávislá od veľkosti vektora. Táto vlastnosť ju robí výnimočne užitočnou na porovnávanie textových embeddingov, vektorov dokumentov a sémantických reprezentácií, kde dĺžka alebo mierka dát by nemala ovplyvňovať hodnotenie podobnosti. Metrika sa stala základom moderných systémov umelé inteligencie, spracovania prirodzeného jazyka a strojového učenia, poháňajúc všetko od vyhľadávačov cez odporúčacie algoritmy až po aplikácie veľkých jazykových modelov.
Koncept kosínovej podobnosti pochádza zo základnej lineárnej algebry a trigonometrie, kde kosínus uhla medzi dvoma vektormi poskytuje normalizovanú mieru ich smerového zhodnutia. Matematický základ spočíva v skalárnom súčine (vnútornom súčine) vektorov a ich veľkostiach, čím vzniká normalizovaná metrika podobnosti, ktorá je výpočtovo efektívna a teoreticky podložená. Historicky sa kosínová podobnosť presadila v oblasti informačného vyhľadávania v 70. a 80. rokoch, keď výskumníci potrebovali efektívne metódy na porovnávanie vektorov dokumentov vo veľkých textových korpusoch. S nástupom strojového učenia a hlbokého učenia v 2010-tych rokoch sa jej využitie dramaticky zrýchlilo, najmä keď neurónové siete začali generovať vysoko dimenzionálne vektorové embeddingy na reprezentáciu textu, obrázkov a iných typov dát. Dnes výskumy ukazujú, že viac ako 78 % podnikov implementujúcich AI systémy využíva kosínovú podobnosť alebo príbuzné metriky porovnania vektorov vo svojich dátových tokoch. Elegantnosť tejto metriky – spájajúca jednoduchosť s výpočtovou efektivitou – z nej urobila de facto štandard na meranie sémantickej podobnosti v NLP aplikáciách; hlavné platformy ako OpenAI, Google a Anthropic ju zakomponovali do svojich jadrových systémov.
Výpočet kosínovej podobnosti sa riadi presným matematickým vzorcom: Kosínová podobnosť = (A · B) / (||A|| × ||B||), kde A · B predstavuje skalárny súčin vektorov A a B a ||A|| a ||B|| ich veľkosti alebo euklidovské normy. Na výpočet skalárneho súčinu sa vynásobia príslušné komponenty oboch vektorov a všetky výsledky sa sčítajú. Napríklad, ak vektor A obsahuje hodnoty [3, 2, 0, 5] a vektor B [1, 0, 0, 0], skalárny súčin je (3×1) + (2×0) + (0×0) + (5×0) = 3. Veľkosť vektora sa vypočíta ako druhá odmocnina zo súčtu druhých mocnín jeho komponentov; pre vektor A je to √(3² + 2² + 0² + 5²) = √38 ≈ 6,16. Finálne skóre kosínovej podobnosti vznikne vydelením skalárneho súčinu súčinom veľkostí vektorov, čím vznikne normalizovaná hodnota medzi -1 a 1. Táto normalizácia je zásadná, pretože robí metriku nezávislou od dĺžky vektora a umožňuje férové porovnanie vektorov s odlišnými mierkami. Vo vysoko dimenzionálnych priestoroch – napríklad s embeddingami o rozmere 1 536 od modelu OpenAI’s text-embedding-ada-002 – zostáva kosínová podobnosť výpočtovo zvládnuteľná, vyžaduje iba základné operácie (násobenie, sčítanie, odmocnina), ktoré moderné procesory zvládnu efektívne aj pri miliónoch vektorov.
V oblasti spracovania prirodzeného jazyka je kosínová podobnosť základom pre meranie sémantických vzťahov medzi textovými reprezentáciami. Keď sa text prevedie na vektorové embeddingy pomocou modelov ako BERT, Word2Vec, GloVe alebo embeddingy založené na GPT, každé slovo, fráza či dokument sa stáva bodom vo vysoko dimenzionálnom priestore, kde sémantický význam je zakódovaný polohou a smerom vektora. Kosínová podobnosť potom meria, ako úzko sú tieto sémantické reprezentácie zladené, čo umožňuje systémom chápať, že slová ako “lekár” a “zdravotná sestra” sú sémanticky príbuzné, hoci sú to odlišné termíny. Táto schopnosť je nevyhnutná pre sémantické vyhľadávanie, kde sa dotaz používateľa prevedie na vektor a porovnáva sa s vektormi dokumentov, aby sa našli najrelevantnejšie výsledky bez ohľadu na presnú zhodu kľúčových slov. Vo veľkých jazykových modeloch ako ChatGPT, Claude a Perplexity poháňa kosínová podobnosť retrieval mechanizmy, ktoré získavajú relevantný kontext z trénovacích dát alebo externých znalostných báz. Necitlivosť metriky na veľkosť je kľúčová v NLP, pretože dĺžka dokumentu by nemala určovať relevantnosť – krátky, výstižný článok môže byť sémanticky podobnejší dotazu ako dlhý dokument jednoducho vďaka obsahu. Výskumy ukazujú, že kosínová podobnosť prekonáva alternatívne metriky ako euklidovská vzdialenosť približne v 85 % NLP benchmarkov pri porovnaní textových embeddingov, vďaka čomu je preferovanou voľbou pre sémantické úlohy v oblasti AI.
| Metrika | Metóda výpočtu | Rozsah | Citlivosť na veľkosť | Najlepší prípad použitia | Výpočtová zložitosť |
|---|---|---|---|---|---|
| Kosínová podobnosť | (A·B) / ( | A | × | ||
| Euklidovská vzdialenosť | √(Σ(Aᵢ - Bᵢ)²) | 0 až ∞ | Áno (závislé na veľkosti) | Priestorové dáta, zhlukovanie, fyzické vzdialenosti | O(n) – efektívne |
| Skalárny súčin | Σ(Aᵢ × Bᵢ) | -∞ až ∞ | Áno (citlivé na mierku) | Surové meranie podobnosti, nenormalizované | O(n) – veľmi efektívne |
| Jaccardova podobnosť | |A ∩ B| / |A ∪ B| | 0 až 1 | Nie (na množinách) | Kategorické dáta, odporúčacie systémy | O(n) – efektívne |
| Manhattanská vzdialenosť | Σ|Aᵢ - Bᵢ| | 0 až ∞ | Áno (závislé na veľkosti) | Dáta na mriežke, porovnanie čŕt | O(n) – efektívne |
| Pearsonova korelácia | Cov(A,B) / (σₐ × σᵦ) | -1 až 1 | Nie (normalizované) | Štatistické vzťahy, časové rady | O(n) – efektívne |
Vektorové databázy ako Pinecone, Weaviate, Milvus a Qdrant sa stali špecializovanou infraštruktúrou na ukladanie a dopytovanie vysoko dimenzionálnych vektorov s využitím kosínovej podobnosti ako hlavnej metriky podobnosti. Tieto databázy sú optimalizované na spracovanie miliónov až miliárd vektorov, umožňujúc sémantické vyhľadávanie v reálnom čase vo veľkom rozsahu. Po zadaní dotazu do vektorovej databázy je dotaz prevedený na embedding a porovnaný so všetkými uloženými vektormi pomocou kosínovej podobnosti, pričom výsledky sú zoradené podľa skóre podobnosti. Na dosiahnutie praktického výkonu pri masívnych datasetoch používajú vektorové databázy algoritmy približného najbližšieho suseda (ANN), ako Hierarchical Navigable Small World (HNSW) a DiskANN, ktoré obetujú dokonalú presnosť výmenou za dramatické zrýchlenie. Napríklad rozšírenie Timescale’s pgvectorscale, ktoré implementuje StreamingDiskANN, dosahuje 28x nižšiu latenciu a 16x vyššiu priepustnosť dotazov v porovnaní so špecializovanými vektorovými databázami ako Pinecone, pričom si zachováva 99 % recall pri 75 % nižších nákladoch. V aplikáciách sémantického vyhľadávania umožňuje kosínová podobnosť systémom chápať úmysel používateľa aj za hranicou doslovného zhodnutia kľúčových slov – vyhľadávanie “zdravé stravovacie návyky” prinesie dokumenty o “nutričných tipoch” a “vyváženej strave”, pretože ich embeddingy smerujú podobným smerom napriek rozdielnej terminológii. Táto schopnosť revolučne zmenila informačné vyhľadávanie a umožnila vyhľadávačom, dokumentačným systémom a znalostným bázam poskytovať kontextovo relevantné výsledky podľa úmyslu používateľa, nie iba zhodou kľúčových slov.
Retrieval-Augmented Generation (RAG) predstavuje paradigmatickú zmenu v tom, ako veľké jazykové modely pristupujú k informáciám a využívajú ich, pričom kosínová podobnosť je ústredným prvkom tejto architektúry. V typickom RAG pipeline sa po zadaní dotazu používateľom najprv dotaz prevedie na vektorový embedding pomocou rovnakého embedding modelu, aký sa použil na vektorizáciu znalostnej bázy. Kosínová podobnosť potom porovnáva tento vektor dotazu so všetkými vektormi dokumentov v znalostnej báze a zoradí dokumenty podľa skóre relevantnosti. Najvyššie hodnotené dokumenty – tie s najvyšším skóre kosínovej podobnosti – sa získajú a posunú ako kontext LLM, ktorý vygeneruje odpoveď založenú na týchto informáciách. Tento prístup rieši zásadné obmedzenia samostatných LLM: pevné dátumy znalostných cutoffov, sklon k halucináciám či k vytváraniu vierohodne znejúcich, ale nesprávnych informácií a neschopnosť pristupovať k aktuálnym alebo vlastným dátam. Využitím kosínovej podobnosti na inteligentné vyhľadávanie zabezpečujú RAG systémy, že LLM generuje odpovede na základe overených, aktuálnych informácií. Hlavné implementácie RAG zahŕňajú OpenAI’s ChatGPT s pluginmi, Claude s retrievalom od Anthropic, Google AI Overviews a Perplexity’s answer generation engine. Výskumy ukazujú, že RAG systémy používajúce kosínovú podobnosť na vyhľadávanie zlepšujú presnosť odpovedí približne o 40–60 % v porovnaní so samostatnými LLM a zároveň znižujú mieru halucinácií až o 70 %. Efektivita výpočtov kosínovej podobnosti je v RAG systémoch obzvlášť dôležitá, pretože musia vykonávať porovnávania podobnosti cez potenciálne milióny dokumentov v reálnom čase a výpočtová jednoduchosť kosínovej podobnosti to umožňuje aj vo veľkom meradle.
Efektívna implementácia kosínovej podobnosti vyžaduje pozornosť k niekoľkým zásadným faktorom. Najprv je nevyhnutné predspracovanie dát – vektory musia byť pred výpočtom normalizované, aby bola zabezpečená konzistencia mierky a platné výsledky, najmä pri práci s vysoko dimenzionálnymi vstupmi z rôznych zdrojov. Organizácie by mali odstrániť alebo označiť nulové vektory (vektory so všetkými nulovými komponentmi), pretože kosínová podobnosť je pre ne matematicky nedefinovaná a spôsobila by chybu delenia nulou pri výpočte. Pri implementácii kosínovej podobnosti v produkčných systémoch je vhodné kombinovať ju s doplnkovými metrikami, ako Jaccardova podobnosť alebo euklidovská vzdialenosť, keď je potrebné zohľadniť viac dimenzií podobnosti, a nespoliehať sa výlučne na kosínovú podobnosť. Testovanie v prostrediach blízkych produkcii pred nasadením je kľúčové, najmä pri systémoch v reálnom čase, ako sú API a vyhľadávače, kde výkon a presnosť priamo ovplyvňujú používateľskú skúsenosť. Populárne knižnice implementáciu výrazne zjednodušujú: Scikit-learn ponúka sklearn.metrics.pairwise.cosine_similarity(), NumPy umožňuje priamu implementáciu vzorca pomocou np.dot() a np.linalg.norm(), TensorFlow a PyTorch ponúkajú GPU-akcelerované implementácie pre veľké výpočty a PostgreSQL s pgvector poskytuje natívne operátory kosínovej podobnosti pre databázové dotazy. Pre organizácie monitorujúce AI zmienky a prítomnosť značky na platformách ako ChatGPT, Perplexity a Google AI Overviews umožňuje kosínová podobnosť presné sledovanie, ako AI systémy odkazujú a citujú ich obsah porovnávaním embeddingov dotazov s uloženými vektormi značiek a domén.
Napriek širokému používaniu predstavuje kosínová podobnosť niekoľko výziev, ktorým sa musia praktici venovať. Metrika je nedefinovaná pre nulové vektory, preto je potrebné starostlivé predspracovanie a validácia dát, aby sa predišlo chybám počas behu. Kosínová podobnosť môže viesť k zavádzajúco vysokým skóre podobnosti pri vektoroch, ktoré sú smerovo zladené, ale sémanticky nesúvisiace, najmä ak sú embedding modely slabo natrénované alebo ak trénovacie dáta postrádajú diverzitu a kontextovú nuansu. Riziko falošnej podobnosti je obzvlášť problematické pri aplikáciách, ako je AI monitoring, kde nesprávne posúdenie podobnosti môže viesť k zmeškaným zmienkam o značke alebo falošným pozitívam. Symetria metriky – teda neschopnosť rozlíšiť poradie porovnávania – môže byť nevhodná v prípadoch, kde záleží na smerovaní. Navyše skóre kosínovej podobnosti 0 nemusí vždy znamenať úplnú odlišnosť v reálnych situáciách; v nuansovaných oblastiach, ako je jazyk, môžu ortogonálne vektory stále zdieľať jemné sémantické vzťahy, ktoré metrika nezachytí. Závislosť od správnej normalizácie znamená, že nesprávne škálované dáta môžu výsledky skresliť, a organizácie musia zabezpečiť konzistentné predspracovanie všetkých vektorov v systémoch. Napokon, samotná kosínová podobnosť môže byť nedostatočná pre zložité hodnotenia podobnosti; jej kombinácia s ďalšími metrikami a doménovo špecifickými validačnými pravidlami často prináša robustnejšie výsledky.
Úloha kosínovej podobnosti v AI systémoch sa vyvíja spolu so zlepšovaním embedding modelov a dominanciou vektorových architektúr v strojovom učení. Medzi nové trendy patrí integrácia kosínovej podobnosti s hybridným vyhľadávaním, ktoré kombinuje vektorovú podobnosť s tradičným fulltextovým vyhľadávaním, čo systémom umožňuje využívať sémantické pochopenie aj zhodu kľúčových slov. Multimodálne embeddingy – reprezentujúce text, obrázky, zvuk a video v spoločnom vektorovom priestore – sa čoraz viac spoliehajú na kosínovú podobnosť na meranie medzi-modálnych vzťahov, čo umožňuje aplikácie ako vyhľadávanie obrázok–text a porozumenie videa. Vývoj efektívnejších algoritmov približného najbližšieho suseda typu DiskANN a HNSW ďalej zlepšuje škálovateľnosť vyhľadávania podľa kosínovej podobnosti, vďaka čomu je sémantické vyhľadávanie v reálnom čase možné v nevídaných rozsahoch. Kvantizačné techniky, ktoré znižujú dimenzionalitu vektorov pri zachovaní vzťahov kosínovej podobnosti, umožňujú nasadenie veľkých vyhľadávaní podľa podobnosti aj na edge zariadeniach a v prostrediach s obmedzenými zdrojmi. V kontexte AI monitoringu a sledovania značky sa kosínová podobnosť stáva čoraz dôležitejšou, keďže organizácie chcú pochopiť, ako AI systémy ako ChatGPT, Perplexity, Claude a Google AI Overviews odkazujú a citujú ich obsah. Do budúcnosti možno očakávať adaptívne metriky kosínovej podobnosti, ktoré upravujú svoje správanie podľa špecifík domény, a integráciu s frameworkmi vysvetliteľnosti, ktoré používateľom pomôžu pochopiť, prečo boli určité vektory uznané za podobné. Ako vektorové databázy dozrievajú a stávajú sa štandardnou infraštruktúrou pre AI aplikácie, kosínová podobnosť pravdepodobne zostane dominantnou metrikou pre sémantické porovnávanie, hoci ju môžu dopĺňať doménovo špecifické metriky podobnosti prispôsobené konkrétnym aplikáciám a prípadom použitia.
Pre platformy ako AmICited, ktoré sledujú zmienky o značke a doméne naprieč AI systémami, je kosínová podobnosť kľúčovým technickým základom. Pri monitorovaní toho, ako ChatGPT, Perplexity, Google AI Overviews a Claude odkazujú na konkrétne domény alebo značky, umožňuje kosínová podobnosť presné meranie sémantickej relevantnosti medzi dotazmi používateľov a AI odpoveďami. Konvertovaním zmienok o značke, URL domény a obsahu dotazu na vektorové embeddingy môže kosínová podobnosť určiť, či AI odpoveď skutočne cituje alebo odkazuje na značku, alebo len spomína súvisiace pojmy. Táto schopnosť je nevyhnutná pre organizácie, ktoré chcú rozumieť svojej viditeľnosti v AI generovanom obsahu a sledovať, ako je ich duševné vlastníctvo AI systémami pripisované alebo citované. Efektivita metriky umožňuje monitorovanie v reálnom čase aj pri miliónoch AI interakcií, čím organizácie získavajú okamžité upozornenia pri zmienke o ich obsahu. Navyše kosínová podobnosť umožňuje porovnávaciu analýzu – organizácie môžu sledovať nielen to, či sú spomínané, ale aj ako často a relevantne v porovnaní s konkurenciou, čo poskytuje konkurenčnú inteligenciu o správaní AI systémov a vzoroch odkazovania na obsah
Skóre kosínovej podobnosti 1 znamená, že dva vektory smerujú presne rovnakým smerom, teda sú dokonale podobné. Skóre 0 znamená, že vektory sú ortogonálne (kolmé), čo naznačuje žiadny smerový vzťah alebo podobnosť. Skóre -1 znamená, že vektory smerujú presne opačným smerom, čo predstavuje úplnú rozdielnosť. V praktických NLP aplikáciách skóre bližšie k 1 znamenajú sémanticky podobné texty, zatiaľ čo skóre blízke 0 naznačujú nesúvisiaci obsah.
Kosínová podobnosť je pri textových embeddingoch preferovaná, pretože meria uhol medzi vektormi namiesto ich absolútnej vzdialenosti, vďaka čomu je necitlivá na veľkosť vektora. To je kľúčové pre NLP, pretože dĺžka dokumentu by nemala ovplyvňovať sémantickú podobnosť – krátky dotaz a dlhý článok môžu byť rovnako relevantné. Euklidovská vzdialenosť je naopak citlivá na veľkosť a má slabý výkon vo vysoko dimenzionálnych priestoroch, kde vektory majú tendenciu sa zbiehať. Kosínová podobnosť je tiež výpočtovo efektívnejšia a prirodzene obmedzená medzi -1 a 1, čím zabraňuje problémom s pretečením.
V RAG systémoch poháňa kosínová podobnosť fázu vyhľadávania porovnávaním embeddingov dotazu s embeddingami dokumentov v vektorovej databáze. Keď používateľ zadá dotaz, prevedie sa na vektor pomocou rovnakého embedding modelu ako uložené dokumenty. Kosínová podobnosť potom zoradí dokumenty podľa relevantnosti, pričom vyššie skóre znamená lepšiu zhodu. Najrelevantnejšie dokumenty sa získajú a posunú LLM ako kontext, čo umožňuje presnejšie a fakticky podložené odpovede. Tento proces umožňuje RAG systémom prekonať obmedzenia LLM, ako je zastarané znalostné zázemie a halucinácie.
Kosínová podobnosť má viacero obmedzení: je nedefinovaná, ak majú vektory nulovú veľkosť, preto je potrebné predspracovať údaje a odstrániť nulové vektory. Môže poskytnúť zavádzajúco vysoké skóre podobnosti pre smerovo zladené, ale sémanticky nesúvisiace vektory, najmä pri zle natrénovaných embeddingoch. Metrika je tiež symetrická, teda nerozlišuje poradie porovnávania, čo môže byť problém v niektorých aplikáciách. Navyše skóre podobnosti 0 nemusí vždy znamenať úplnú odlišnosť v reálnom svete, najmä v nuansovaných oblastiach, ako je jazyk, kde môžu ortogonálne vektory zdieľať sémantické vzťahy.
Kosínová podobnosť sa počíta podľa vzorca: (A · B) / (||A|| × ||B||), kde A · B je skalárny súčin vektorov A a B a ||A|| a ||B|| sú ich veľkosti (euklidovské normy). Skalárny súčin sa vypočíta vynásobením zodpovedajúcich komponentov vektorov a sčítaním výsledkov. Veľkosť vektora je druhá odmocnina zo súčtu druhých mocnín jeho komponentov. Tento vzorec vytvára normalizované skóre v rozsahu od -1 do 1, vďaka čomu je nezávislé od dĺžky vektora a vhodné na porovnanie vektorov rôznych veľkostí.
V monitorovacích AI platformách, ako je AmICited, je kosínová podobnosť nevyhnutná pre sledovanie zmienok o značke a doméne naprieč AI systémami ako ChatGPT, Perplexity a Google AI Overviews. Konvertovaním zmienok o značke a dotazov na vektorové embeddingy kosínová podobnosť meria, ako úzko sú AI odpovede zladené so sledovaným obsahom. To umožňuje organizáciám monitorovať, či sa ich domény objavujú v AI odpovediach, posúdiť sémantickú relevantnosť zmienok a sledovať, ako AI systémy odkazujú na ich obsah v porovnaní s konkurenciou. Efektivita tejto metriky umožňuje monitorovanie v reálnom čase aj pri miliónoch AI interakcií.
Hlavné AI platformy a nástroje využívajúce kosínovú podobnosť zahŕňajú embedding modely OpenAI, sémantické vyhľadávacie algoritmy Googlu, systém generovania odpovedí Perplexity a retrieval mechanizmy Claude. Vektorové databázy ako Pinecone, Weaviate a Milvus používajú kosínovú podobnosť ako hlavné metriky podobnosti. Open-source knižnice ako Scikit-learn, TensorFlow, PyTorch a NumPy poskytujú vstavané funkcie na výpočet kosínovej podobnosti. PostgreSQL s rozšírením pgvector umožňuje výpočty kosínovej podobnosti vo veľkom meradle. Tieto nástroje spoločne poháňajú odporúčacie systémy, chatboty, sémantické vyhľadávače a RAG aplikácie v rámci AI ekosystému.
Začnite sledovať, ako AI chatboty spomínajú vašu značku na ChatGPT, Perplexity a ďalších platformách. Získajte použiteľné poznatky na zlepšenie vašej prítomnosti v AI.
Sémantická podobnosť meria významovú príbuznosť medzi textami pomocou embeddingov a metrík vzdialenosti. Kľúčová pre AI monitoring, párovanie obsahu a sledovani...
Koincidencia nastáva, keď sa súvisiace pojmy objavujú spolu v obsahu, čo signalizuje sémantickú relevantnosť pre vyhľadávače a AI systémy. Zistite, ako tento ko...
Skóre viditeľnosti meria vyhľadateľnosť výpočtom odhadovaných kliknutí z organických pozícií. Zistite, ako táto metrika funguje, metódy jej výpočtu a prečo je d...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.