
Pokrytie AI indexu
Zistite, čo je pokrytie AI indexu a prečo je dôležité pre viditeľnosť vašej značky v ChatGPT, Google AI Overviews a Perplexity. Objavte technické faktory, osved...
7 min čítania

Pokrytie indexu označuje percento a stav stránok webu, ktoré boli objavené, prehľadané a zahrnuté do indexu vyhľadávača. Meria, ktoré stránky sú oprávnené zobrazovať sa vo výsledkoch vyhľadávania, a identifikuje technické problémy brániace indexácii.
Pokrytie indexu označuje percento a stav stránok webu, ktoré boli objavené, prehľadané a zahrnuté do indexu vyhľadávača. Meria, ktoré stránky sú oprávnené zobrazovať sa vo výsledkoch vyhľadávania, a identifikuje technické problémy brániace indexácii.
Pokrytie indexu je mierou toho, koľko stránok z vášho webu bolo objavených, prehľadaných a zahrnutých do indexu vyhľadávača. Predstavuje percento stránok vášho webu, ktoré sa môžu zobrazovať vo výsledkoch vyhľadávania, a identifikuje stránky, ktoré majú technické problémy brániace indexácii. V podstate pokrytie indexu odpovedá na zásadnú otázku: „Koľko z môjho webu dokážu vyhľadávače skutočne nájsť a zaradiť?“ Tento ukazovateľ je základom pre pochopenie viditeľnosti vášho webu vo vyhľadávačoch a sleduje sa prostredníctvom nástrojov ako Google Search Console, ktorý poskytuje detailné správy o indexovaných stránkach, vylúčených stránkach a stránkach s chybami. Bez správneho pokrytia indexu zostáva aj najlepšie optimalizovaný obsah neviditeľný pre vyhľadávače aj používateľov hľadajúcich vaše informácie.
Pokrytie indexu nie je len o kvantite – ide o to, aby boli indexované správne stránky. Web môže mať tisíce stránok, no ak je mnoho z nich duplicitných, s nekvalitným obsahom alebo blokovaných cez robots.txt, skutočné pokrytie indexu môže byť výrazne nižšie, než sa očakáva. Tento rozdiel medzi celkovým počtom stránok a počtom indexovaných stránok je kľúčový pre tvorbu efektívnej SEO stratégie. Organizácie, ktoré pravidelne sledujú pokrytie indexu, dokážu identifikovať a opraviť technické problémy ešte predtým, ako ovplyvnia organickú návštevnosť, čo robí z pokrytia indexu jeden z najakčnejších ukazovateľov v technickom SEO.
Koncept pokrytia indexu vznikol, keď sa vyhľadávače vyvinuli z jednoduchých crawlerov na sofistikované systémy schopné denne spracovať milióny stránok. V začiatkoch SEO mali správcovia webov len obmedzený prehľad o tom, ako vyhľadávače interagujú s ich stránkami. Google Search Console, pôvodne spustený ako Google Webmaster Tools v roku 2006, spôsobil revolúciu v tejto transparentnosti tým, že poskytol priamu spätnú väzbu o prehľadávaní a indexovaní. Správa o pokrytí indexu (predtým „Správa o indexovaní stránok“) sa stala hlavným nástrojom na pochopenie, ktoré stránky Google indexoval a prečo boli iné vylúčené.
Ako sa weby stávali komplexnejšími s dynamickým obsahom, parametrami a duplicitnými stránkami, problémy s pokrytím indexu boli čoraz bežnejšie. Výskumy ukazujú, že približne 40–60 % webov má významné problémy s pokrytím indexu a mnohé stránky zostávajú neobjavené alebo zámerne vylúčené z indexu. Nárast JavaScriptových webov a single-page aplikácií proces indexácie ešte viac komplikoval, keďže vyhľadávače musia najprv zobraziť obsah, aby určili indexovateľnosť. Dnes je monitorovanie pokrytia indexu považované za nevyhnutné pre každý projekt závislý od organickej návštevnosti, pričom odborníci odporúčajú minimálne mesačný audit.
Vzťah medzi pokrytím indexu a crawl budgetom je čoraz dôležitejší s rastúcim rozsahom webov. Crawl budget je počet stránok, ktoré Googlebot prehľadá na vašom webe v danom časovom úseku. Veľké weby so zlou architektúrou alebo nadmerným množstvom duplicitného obsahu môžu premrhať crawl budget na bezcenné stránky, pričom dôležitý obsah zostáva neobjavený. Štúdie ukazujú, že viac ako 78 % veľkých firiem používa nejaký nástroj na monitorovanie obsahu, aby sledovali svoju viditeľnosť vo vyhľadávačoch a AI platformách, pričom pokrytie indexu je základom každej stratégie viditeľnosti.
| Pojem | Definícia | Hlavné ovládanie | Používané nástroje | Vplyv na pozície |
|---|---|---|---|---|
| Pokrytie indexu | Percento stránok indexovaných vyhľadávačom | Meta tagy, robots.txt, kvalita obsahu | Google Search Console, Bing Webmaster Tools | Priamy – len indexované stránky môžu byť hodnotené |
| Prehľadateľnosť | Schopnosť botov pristupovať a navigovať stránky | robots.txt, štruktúra webu, interné odkazy | Screaming Frog, ZentroAudit, serverové logy | Nepriamy – stránky musia byť prehľadateľné, aby boli indexované |
| Indexovateľnosť | Schopnosť prehľadaných stránok byť pridané do indexu | Noindex direktívy, kanonické tagy, obsah | Google Search Console, URL Inspection Tool | Priamy – určuje, či sa stránky zobrazia vo výsledkoch |
| Crawl budget | Počet stránok, ktoré Googlebot prehľadá v časovom úseku | Autorita webu, kvalita stránok, chyby v prehľadávaní | Google Search Console, serverové logy | Nepriamy – ovplyvňuje, ktoré stránky sa prehľadajú |
| Duplicitný obsah | Viacero stránok s rovnakým alebo podobným obsahom | Kanonické tagy, 301 presmerovania, noindex | SEO audit nástroje, manuálna kontrola | Negatívny – rozrieďuje potenciál hodnotenia |
Pokrytie indexu prebieha v troch fázach: objavenie, prehľadanie a indexovanie. Vo fáze objavenia vyhľadávače nachádzajú URL rôznymi spôsobmi, vrátane XML sitemap, interných odkazov, externých spätných odkazov a priameho odoslania cez Google Search Console. Po objavení sú URL zaradené do frontu na prehľadanie, kde Googlebot načíta stránku a analyzuje jej obsah. Nakoniec, počas indexovania, Google spracuje obsah stránky, posúdi jej relevantnosť a kvalitu a rozhodne, či ju zahrnie do vyhľadávateľného indexu.
Správa o pokrytí indexu v Google Search Console kategorizuje stránky do štyroch hlavných stavov: Platné (indexované stránky), Platné s upozorneniami (indexované, ale s problémami), Vylúčené (zámerne neindexované) a Chyba (stránky, ktoré nebolo možné indexovať). Každý stav obsahuje konkrétne typy problémov, ktoré dávajú detailný prehľad o tom, prečo sú stránky (ne)indexované. Napríklad stránky môžu byť vylúčené kvôli noindex meta tagu, blokovaniu cez robots.txt, duplicite bez správneho kanonického tagu alebo chybám 4xx či 5xx HTTP kódov.
Pochopenie technických mechanizmov pokrytia indexu si vyžaduje znalosť niekoľkých kľúčových prvkov. robots.txt je textový súbor v koreňovom adresári webu, ktorý inštruuje vyhľadávacie crawleri, ktoré adresáre a súbory môžu alebo nemôžu prehľadávať. Nesprávna konfigurácia robots.txt je jednou z najčastejších príčin problémov s pokrytím indexu – omylom zablokované dôležité adresáre zabránia Google objaviť tieto stránky. Meta robots tag umiestený v hlavičke HTML stránky poskytuje stránkovú úroveň inštrukcií pomocou direktív ako index, noindex, follow a nofollow. Kanonický tag (rel=“canonical”) informuje vyhľadávače, ktorá verzia stránky je preferovaná pri duplicite, čím zabraňuje indexačnému balastu a konsoliduje hodnotiace signály.
Pre firmy závislé na organickej návštevnosti pokrytie indexu priamo ovplyvňuje príjmy aj viditeľnosť. Ak dôležité stránky nie sú indexované, nemôžu sa objaviť vo výsledkoch vyhľadávania a potenciálni zákazníci ich nenájdu cez Google. E-shopy s nízkym pokrytím indexu môžu mať produktové stránky v stave „Objavené – aktuálne neindexované“, čo znamená stratené predaje. Content marketingové platformy s tisíckami článkov potrebujú silné pokrytie indexu, aby sa ich obsah dostal k publiku. SaaS firmy závisia od indexovaných dokumentácií a blogov na generovanie organických leadov.
Praktický význam presahuje tradičné vyhľadávanie. S nástupom generatívnych AI platforiem ako ChatGPT, Perplexity a Google AI Overviews je pokrytie indexu relevantné aj pre AI viditeľnosť. Tieto systémy často používajú indexovaný webový obsah ako tréningové dáta a zdroje citácií. Ak vaše stránky nie sú správne indexované Googlom, je menej pravdepodobné, že budú zahrnuté do tréningových datasetov alebo citované v AI-generovaných odpovediach. Vzniká tak kumulatívny problém s viditeľnosťou: slabé pokrytie indexu negatívne ovplyvňuje klasické pozície aj AI viditeľnosť.
Organizácie, ktoré aktívne monitorujú pokrytie indexu, zaznamenávajú merateľné zlepšenie organickej návštevnosti. Typickým scenárom je zistenie, že 30–40 % odoslaných URL je vylúčených kvôli noindex tagom, duplicitnému obsahu alebo chybám v prehľadávaní. Po náprave – odstránení nepotrebných noindex tagov, implementácii správnej kanonikalizácie a oprave chýb – počet indexovaných stránok často stúpne o 20–50 %, čo priamo koreluje so zlepšením organickej viditeľnosti. Cena nečinnosti je značná: každý mesiac, čo stránka zostáva neindexovaná, je mesiacom strateného potenciálu návštevnosti a konverzií.
Google Search Console zostáva hlavným nástrojom na monitorovanie pokrytia indexu, poskytujúc najautoritatívnejšie dáta o rozhodnutiach Googlu ohľadom indexácie. Správa o pokrytí indexu zobrazuje indexované stránky, stránky s upozorneniami, vylúčené stránky a stránky s chybami, vrátane detailného rozpisu konkrétnych problémov. Google poskytuje aj URL Inspection Tool, ktorý umožňuje overiť indexačný stav jednotlivých stránok a požiadať o indexáciu nového či aktualizovaného obsahu. Tento nástroj je nenahraditeľný pri diagnostike konkrétnych stránok a pochopení, prečo neboli indexované.
Bing Webmaster Tools ponúka podobnú funkcionalitu cez Index Explorer a URL Submission. Hoci podiel Bing je menší ako Google, stále je dôležitý na oslovenie používateľov preferujúcich Bing vyhľadávanie. Dáta Bing o pokrytí indexu sa niekedy líšia od Google, čo odhaľuje problémy špecifické pre Bing. Organizácie spravujúce veľké weby by mali monitorovať obe platformy pre komplexné pokrytie.
Pre AI monitoring a viditeľnosť značky platformy ako AmICited sledujú, ako sa vaša značka a doména objavuje v ChatGPT, Perplexity, Google AI Overviews a Claude. Tieto platformy prepájajú klasické pokrytie indexu s AI viditeľnosťou a pomáhajú organizáciám pochopiť, ako sa ich indexovaný obsah premieta do zmienok v AI-generovaných odpovediach. Táto integrácia je zásadná pre modernú SEO stratégiu, keďže viditeľnosť v AI systémoch čoraz viac ovplyvňuje povedomie o značke a návštevnosť.
Tretie strany, SEO audit nástroje ako Ahrefs, SEMrush a Screaming Frog, poskytujú ďalšie poznatky o pokrytí indexu tým, že web prehľadávajú nezávisle a porovnávajú svoje zistenia s údajmi Google. Rozdiely medzi vlastným prehľadom a Google môžu odhaliť problémy ako JavaScript rendering, serverové chyby alebo obmedzenia crawl budgetu. Tieto nástroje tiež identifikujú „osirelé stránky“ (bez interných odkazov), ktoré často trpia slabým pokrytím indexu.
Zlepšovanie pokrytia indexu si vyžaduje systematický prístup, ktorý rieši technické aj strategické aspekty. Najprv si urobte audit aktuálneho stavu pomocou správy o pokrytí indexu v Google Search Console. Identifikujte hlavné typy problémov ovplyvňujúce váš web – či už ide o noindex tagy, blokovanie cez robots.txt, duplicitný obsah alebo chyby v prehľadávaní. Prioritizujte podľa vplyvu: stránky, ktoré by mali byť indexované, ale nie sú, majú prednosť pred tými, ktoré sú správne vylúčené.
Po druhé, opravte nesprávne nastavenia robots.txt kontrolou súboru a uistite sa, že omylom neblokujete dôležité adresáre. Častou chybou je blokovať /admin/, /staging/ či /temp/, čo je správne, ale zároveň omylom blokovať /blog/, /products/ či iný verejný obsah. Využite robots.txt tester v Google Search Console na overenie, že dôležité stránky nie sú blokované.
Po tretie, implementujte správnu kanonikalizáciu pre duplicitný obsah. Ak máte viacero URL so zhodným obsahom (napr. produktové stránky prístupné cez rôzne kategórie), implementujte self-referencing canonical tagy na každej stránke alebo použite 301 presmerovania na konsolidáciu na jednu verziu. Zabránite tým indexačnému balastu a konsolidujete hodnotiace signály.
Po štvrté, odstráňte zbytočné noindex tagy zo stránok, ktoré chcete indexovať. Auditujte web na výskyt noindex direktív, najmä na testovacích prostrediach, ktoré mohli byť omylom nasadené do produkcie. Pomocou URL Inspection Tool overte, že dôležité stránky nemajú noindex značky.
Po piate, odošlite XML sitemap do Google Search Console, ktorá bude obsahovať len indexovateľné URL. Udržujte sitemap čistú – vylúčte stránky s noindex, presmerovaniami alebo 404 chybami. Pri veľkých weboch zvážte rozdelenie sitemap podľa typu obsahu alebo sekcie na lepšiu organizáciu a detailnejšie hlásenia o chybách.
Po šieste, opravte chyby v prehľadávaní vrátane nefunkčných odkazov (404), serverových chýb (5xx) a reťazení presmerovaní. V Google Search Console identifikujte dotknuté stránky a systematicky ich riešte. Pri 404 chybách na dôležitých stránkach buď obnovte obsah alebo nastavte 301 presmerovanie na relevantnú alternatívu.
Budúcnosť pokrytia indexu sa vyvíja spolu so zmenami vo vyhľadávacích technológiách a nástupom generatívnych AI systémov. Ako Google ďalej zdokonaľuje požiadavky Core Web Vitals a štandardy E-E-A-T (Skúsenosť, Odbornosť, Autoritatívnosť, Dôveryhodnosť), pokrytie indexu bude čoraz viac závisieť od kvality obsahu a užívateľských metrík. Stránky so zlými Core Web Vitals alebo tenkým obsahom môžu čeliť problémom s indexáciou aj keď sú technicky prehľadateľné.
Vzostup AI-generovaných výsledkov vyhľadávania a odpovedacích enginov mení význam pokrytia indexu. Tradičné pozície závisia od indexovaných stránok, no AI systémy môžu citovať indexovaný obsah inak alebo uprednostniť niektoré zdroje pred inými. Organizácie budú musieť monitorovať nielen to, či sú stránky indexované Googlom, ale aj či sú citované a referencované AI platformami. Táto požiadavka na dvojitú viditeľnosť znamená, že monitorovanie pokrytia indexu sa musí rozšíriť aj na AI monitoringové platformy sledujúce zmienky značky v ChatGPT, Perplexity a ďalších generatívnych AI systémoch.
JavaScript rendering a dynamický obsah budú naďalej komplikovať pokrytie indexu. S rastúcim využívaním JavaScript frameworkov a single-page aplikácií musia vyhľadávače najprv zobraziť JavaScript, aby pochopili obsah stránky. Google síce zlepšil schopnosti JavaScript renderingu, no problémy pretrvávajú. Budúce osvedčené postupy budú pravdepodobne klásť dôraz na server-side rendering alebo dynamický rendering, aby bol obsah okamžite dostupný crawlerom bez potreby JavaScriptu.
Integrácia štruktúrovaných dát a schema markup bude čoraz dôležitejšia pre pokrytie indexu. Vyhľadávače používajú štruktúrované dáta na lepšie pochopenie obsahu a kontextu stránky, čo môže zlepšiť rozhodovanie o indexácii. Organizácie, ktoré implementujú komplexný schema markup pre svoje typy obsahu – články, produkty, udalosti, FAQ – môžu zaznamenať lepšie pokrytie indexu a vyššiu viditeľnosť v rozšírených výsledkoch.
Napokon sa koncept pokrytia indexu rozšíri aj za stránky na entity a témy. Namiesto sledovania len toho, či sú stránky indexované, sa bude monitorovať, či sú vaša značka, produkty a témy správne zastúpené v znalostných grafoch vyhľadávačov a tréningových dátach AI. Ide o zásadnú zmenu od indexovania na úrovni stránok k viditeľnosti na úrovni entít, čo si vyžiada nové prístupy a stratégie monitorovania.
+++
Prehľadateľnosť znamená, či môžu boti vyhľadávača pristupovať a navigovať vaše stránky, čo je riadené napríklad robots.txt a štruktúrou webu. Indexovateľnosť určuje, či sú prehľadané stránky skutočne pridané do indexu vyhľadávača, ovplyvňovaná meta robots značkami, kanonickými značkami a kvalitou obsahu. Stránka musí byť prehľadateľná, aby mohla byť indexovaná, ale prehľadateľnosť nezaručuje indexáciu.
Pre väčšinu webov postačuje mesačná kontrola pokrytia indexu na zachytenie hlavných problémov. Ak však výrazne meníte štruktúru stránky, pravidelne publikujete nový obsah alebo migrujete web, sledujte správu týždenne či každé dva týždne. Google síce posiela emailové notifikácie o urgentných problémoch, no tie často meškajú, preto je proaktívne monitorovanie nevyhnutné pre zachovanie optimálnej viditeľnosti.
Tento stav znamená, že Google našiel URL (zvyčajne cez sitemapu alebo interné odkazy), ale zatiaľ ju neprehľadal. Môže to byť spôsobené limitom crawl budgetu, kedy Google uprednostňuje iné stránky vášho webu. Ak dôležité stránky zostávajú v tomto stave dlhodobo, môže to signalizovať problém s crawl budgetom alebo nízkou autoritou webu, ktorý je potrebné riešiť.
Áno, odoslanie XML sitemap do Google Search Console pomáha vyhľadávačom objaviť a uprednostniť vaše stránky na prehľadávanie a indexáciu. Dobre udržiavaná mapa webu obsahujúca len indexovateľné URL môže výrazne zlepšiť pokrytie indexu tým, že usmerní crawl budget Google na najdôležitejší obsah a skracuje čas objavenia stránok.
Medzi časté problémy patrí blokovanie stránok cez robots.txt, noindex meta značka na dôležitých stránkach, duplicitný obsah bez správnej kanonikalizácie, serverové chyby (5xx), reťazenia presmerovaní a nekvalitný (tenký) obsah. Okrem toho sa často v správach o pokrytí indexu objavujú chyby 404, soft 404 a stránky s požiadavkou autorizácie (chyby 401/403), ktoré je potrebné odstrániť pre zlepšenie viditeľnosti.
Pokrytie indexu priamo ovplyvňuje, či sa váš obsah zobrazuje v AI-generovaných odpovediach z platforiem ako ChatGPT, Perplexity a Google AI Overviews. Ak vaše stránky nie sú správne indexované Googlom, je menej pravdepodobné, že budú zahrnuté do tréningových dát alebo citované AI systémami. Monitorovanie pokrytia indexu zaručuje, že obsah vašej značky je objaviteľný a citovateľný naprieč klasickým vyhľadávaním aj generatívnymi AI platformami.
Crawl budget je počet stránok, ktoré Googlebot prehľadá na vašom webe za daný čas. Stránky s neefektívne využitým crawl budgetom môžu mať veľa stránok v stave 'Objavené – aktuálne neindexované'. Optimalizáciou crawl budgetu opravou chýb, odstránením duplicitných URL a strategickým využitím robots.txt zabezpečíte, že Google sa sústreďuje na indexáciu najhodnotnejšieho obsahu.
Nie, nie všetky stránky by mali byť indexované. Stránky ako testovacie prostredia, duplicitné varianty produktov, interné výsledky vyhľadávania či archívy zásad ochrany osobných údajov je zvyčajne lepšie vylúčiť z indexu pomocou noindex tagov alebo robots.txt. Cieľom je indexovať len hodnotný, jedinečný obsah, ktorý slúži zámeru používateľa a prispieva k celkovému výkonu SEO vášho webu.
Začnite sledovať, ako AI chatboty spomínajú vašu značku na ChatGPT, Perplexity a ďalších platformách. Získajte použiteľné poznatky na zlepšenie vašej prítomnosti v AI.
Zistite, čo je pokrytie AI indexu a prečo je dôležité pre viditeľnosť vašej značky v ChatGPT, Google AI Overviews a Perplexity. Objavte technické faktory, osved...

Indexovateľnosť je schopnosť vyhľadávačov zahrnúť stránky do svojho indexu. Zistite, ako prelezateľnosť, technické faktory a kvalita obsahu ovplyvňujú, či sa va...
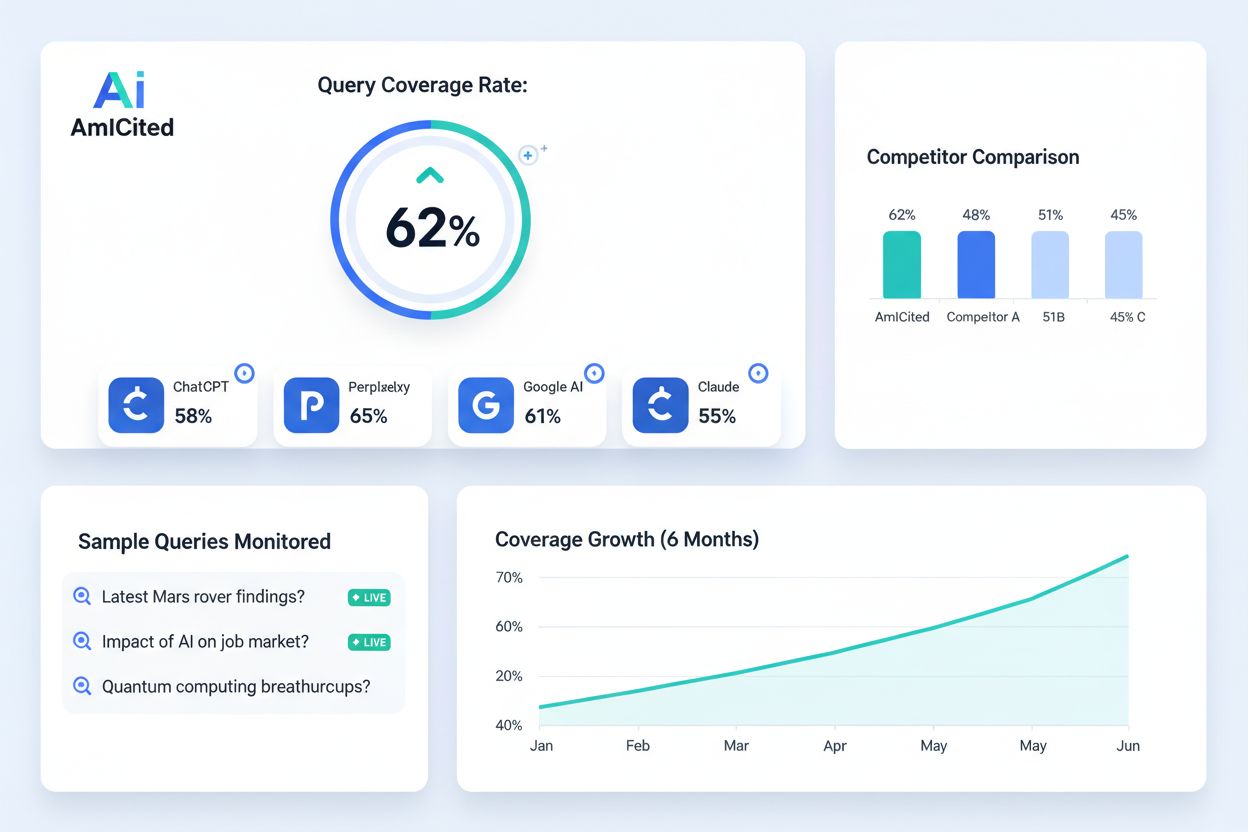
Zistite, čo je miera pokrytia dopytov, ako ju merať a prečo je kľúčová pre viditeľnosť značky v AI vyhľadávaní. Objavte benchmarky, stratégie optimalizácie a ná...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.