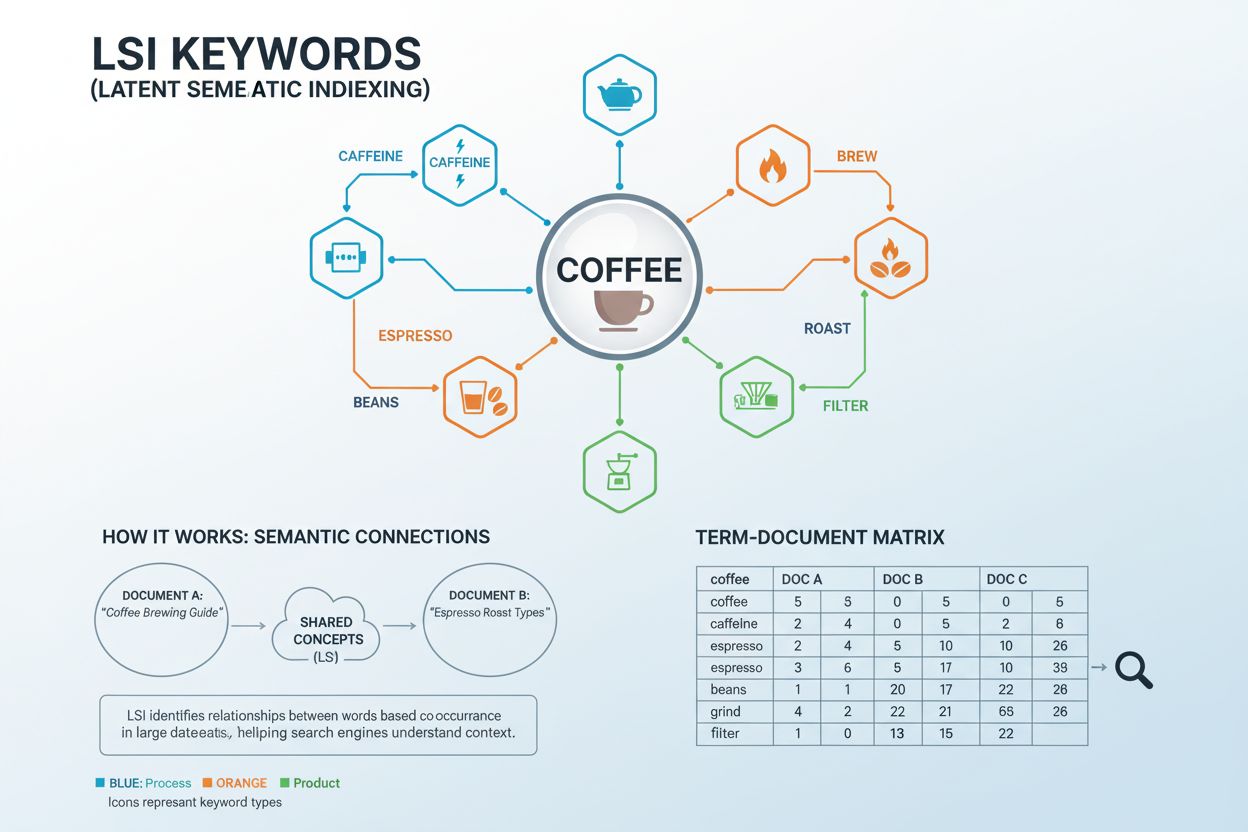
Definícia LSI kľúčových slov
LSI kľúčové slová (Latent Semantic Indexing Keywords) sú slová a frázy, ktoré sú konceptuálne príbuzné vášmu cieľovému kľúčovému slovu a často sa spolu vyskytujú v podobných kontextoch. Tento pojem pochádza z matematickej techniky vyvinutej v 80. rokoch 20. storočia, ktorá analyzuje skryté sémantické vzťahy medzi slovami vo veľkých kolekciách dokumentov. V praxi SEO sú LSI kľúčové slová vyhľadávacie výrazy, ktoré pomáhajú vyhľadávačom a AI systémom pochopiť širší kontext a tému vášho obsahu nad rámec presného párovania kľúčových slov. Napríklad, ak je vaším hlavným kľúčovým slovom „káva“, príbuzné LSI kľúčové slová môžu byť „kofeín“, „praženie“, „espresso“, „zrná“, „pražiť“ a „mletie“. Tieto výrazy spolu signalizujú vyhľadávačom, že váš obsah tému kávy komplexne pokrýva, a nie len opakovane spomína dané slovo.
Historický kontext a vývoj LSI kľúčových slov
Latentné sémantické indexovanie bolo predstavené v prelomovom výskumnom článku v roku 1988 ako „nový prístup k riešeniu problému slovníka v interakcii človeka s počítačom“. Technológia mala vyriešiť zásadný problém: vyhľadávače boli príliš závislé od presného párovania kľúčových slov, čo často zlyhávalo pri vyhľadávaní relevantných dokumentov, ak používatelia použili odlišnú terminológiu alebo synonymá. V roku 2004 Google implementoval LSI koncepcie do svojho vyhľadávacieho algoritmu, čo znamenalo zásadný posun vo vnímaní obsahu vyhľadávačmi. Táto aktualizácia Googlu umožnila posunúť sa za hranice analýzy frekvencie kľúčových slov a začať rozumieť kontextu, významu a konceptuálnym vzťahom medzi pojmami. Podľa výskumu Googlu je dnes viac ako 15 % denných vyhľadávaní nových a nikdy predtým nezadaných, čo robí kontextové pochopenie cez príbuzné výrazy ešte dôležitejším. Evolúcia od LSI k modernej sémantickej analýze predstavuje jeden z najdôležitejších posunov v technológiách vyhľadávačov a zásadne mení prístup tvorcov obsahu k optimalizácii.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
LSI kľúčové slová vs. príbuzná terminológia: Porovnávacia tabuľka
| Pojem | Definícia | Zameranie | Vzťah k hlavnému kľúčovému slovu | Dopad na moderné SEO |
|---|
| LSI kľúčové slová | Slová vyskytujúce sa spolu s hlavným kľúčovým slovom na základe matematickej analýzy | Vzory vo frekvencii slov a spoločnom výskyte | Priamy kontextový vzťah | Obmedzený (Google LSI algoritmus nepoužíva) |
| Sémantické kľúčové slová | Konceptuálne príbuzné pojmy riešiace zámer používateľa a hĺbku témy | Význam a zámer používateľa | Širší vzťah k téme | Vysoký (jadro moderného SEO) |
| Synonymá | Slová s rovnakým alebo veľmi podobným významom | Priama zámennosť slov | Rovnaký význam, iné slovo | Stredný (užitočné, nie prioritné) |
| Long-tail kľúčové slová | Dlhšie a špecifickejšie frázy | Hľadanosť a špecifičnosť | Konkrétnejšia verzia hlavného kľúčového slova | Vysoký (nižšia konkurencia, vyšší zámer) |
| Príbuzné kľúčové slová | Výrazy často vyhľadávané spolu s hlavným kľúčovým slovom | Vzory v správaní používateľov | Vzory vyhľadávania používateľov | Vysoký (indikuje zámer používateľa) |
| Entity kľúčové slová | Pomenované entity a pojmy súvisiace s témou | Vzťahy medzi entitami a znalostné grafy | Konceptuálny a kategorizovaný vzťah | Veľmi vysoký (AI systémy preferujú entity) |
Matematický základ: Ako LSI kľúčové slová fungujú
Latentné sémantické indexovanie funguje cez sofistikovaný matematický proces nazývaný Singular Value Decomposition (SVD), ktorý analyzuje vzťahy medzi slovami v rámci veľkých kolekcií dokumentov. Systém najprv vytvorí Term Document Matrix (TDM)—dvojrozmernú maticu, ktorá sleduje, ako často sa jednotlivé slová vyskytujú v rôznych dokumentoch. Bežné slová (napr. „a“, „alebo“, „je“) sú odstránené, aby sa izolovali obsahovo významné výrazy. Algoritmus následne aplikuje váhovacie funkcie na zistenie vzorcov spoločného výskytu—prípadov, keď sa konkrétne slová v rozličných dokumentoch vyskytujú spolu s podobnou frekvenciou. Ak sa slová opakovane vyskytujú v podobných kontextoch, systém ich rozpozná ako sémanticky príbuzné. Napríklad slová „káva“, „praženie“, „espresso“ a „kofeín“ sa často spoločne vyskytujú v dokumentoch o nápojoch, čo signalizuje ich sémantický vzťah. Tento matematický prístup umožňuje počítačom pochopiť, že „espresso“ a „káva“ sú príbuzné pojmy, aj bez explicitných pravidiel. Vektory SVD získané touto analýzou predpovedajú význam presnejšie než analýza samostatných výrazov, čo umožňuje vyhľadávačom chápať obsah na hlbšej úrovni, než len pri jednoduchom párovaní kľúčových slov.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Prečo Google nepoužíva LSI (ale stále oceňuje sémantiku)
Napriek teoretickej elegancii latentného sémantického indexovania Google výslovne oznámil, že LSI vo svojom hodnotiacom algoritme nepoužíva. John Mueller, zástupca Googlu, potvrdil v roku 2019: „LSI kľúčové slová neexistujú—každý, kto tvrdí opak, sa mýli, prepáčte.“ Existuje viacero dôvodov, prečo Google LSI opustil v prospech modernejších prístupov. Po prvé, LSI bol navrhnutý pre menšie, statické kolekcie dokumentov, nie pre dynamický a neustále rastúci internet. Pôvodný LSI patent, udelený Bell Communications Research v roku 1989, vypršal v roku 2008, no dovtedy už Google technológiu dávno opustil. Dôležitejšie však je, že Google vyvinul omnoho pokročilejšie systémy ako RankBrain (predstavený v roku 2015), ktorý používa strojové učenie na prevod textu do matematických vektorov, ktoré počítače rozumejú. Neskôr Google uviedol BERT (Bidirectional Encoder Representations from Transformers) v roku 2019, ktorý analyzuje slová obojsmerne—zvažuje všetky slová pred aj po konkrétnom výraze na pochopenie kontextu. Na rozdiel od LSI, ktoré stop slová odstraňuje, BERT rozpoznáva, že aj malé slová ako „nájsť“ vo vete „Kde môžem nájsť miestneho zubára?“ sú kľúčové pre pochopenie zámeru. Dnes Google využíva MUM (Multitask Unified Model) a AI Overviews na generovanie kontextových súhrnov priamo vo výsledkoch vyhľadávania, čo je evolúcia ďaleko za hranicami možností LSI.
Sémantické SEO: Moderná evolúcia LSI konceptov
Hoci LSI kľúčové slová ako konkrétna technológia sú zastarané, základný princíp—že vyhľadávače majú rozumieť kontextu a významu obsahu—zostáva základom moderného SEO. Sémantické SEO predstavuje vývoj tohto konceptu, pričom sa zameriava na zámer používateľa, tematickú autoritu a komplexné pokrytie témy namiesto frekvencie kľúčových slov. Podľa údajov z roku 2025 je približne 74 % všetkých vyhľadávaní tvorených long-tail frázami, čo robí sémantické porozumenie nevyhnutným pre oslovenie rôznych skupín používateľov. Sémantické SEO kladie dôraz na tvorbu obsahu, ktorý tému dôsledne pokrýva z viacerých uhlov pohľadu, prirodzene obsahuje súvisiace pojmy a odpovedá na príbuzné otázky. Tento prístup je v súlade s tým, ako moderné AI systémy ako ChatGPT, Perplexity, Google AI Overviews a Claude posudzujú zdrojový materiál. Tieto systémy uprednostňujú obsah, ktorý preukazuje odbornosť, komplexnosť a jasnú tematickú autoritu—vlastnosti, ktoré prirodzene vznikajú pri zahrnutí sémanticky príbuzných pojmov. Prechod od LSI k sémantickému SEO znamená dospievanie vyhľadávacích technológií od matematického rozpoznávania vzorcov k skutočnému pochopeniu kontextu za pomoci neurónových sietí a strojového učenia.
Praktická implementácia: Kde a ako používať príbuzné kľúčové slová
Zahrnutie LSI kľúčových slov a sémanticky príbuzných výrazov do obsahu si vyžaduje strategické umiestnenie a prirodzenú integráciu. Najefektívnejšie miesta pre tieto výrazy sú title tagy a H1 nadpisy, ktoré majú veľkú váhu pri hodnotení obsahu vyhľadávačmi. H2 a H3 podnadpisy ponúkajú výbornú príležitosť prirodzene predstaviť súvisiace pojmy a logicky štruktúrovať obsah. Alt text obrázkov je ďalšou cennou možnosťou, ktorá posilňuje tematickú relevantnosť a zároveň zlepšuje prístupnosť. V celom telesnom obsahu by mali byť príbuzné pojmy prirodzene vkladané do viet a odsekov ako podpora hlavného rozprávania, nie ako rušivý prvok. Meta popisy môžu obsahovať príbuzné kľúčové slová na zvýšenie preklikov z výsledkov vyhľadávania. Interné odkazy (anchor texty) poskytujú ďalšiu možnosť na posilnenie sémantických vzťahov medzi stránkami vášho webu. Kľúčovým princípom je prirodzená integrácia—ak príbuzný pojem do obsahu prirodzene nezapadá, netreba ho nasilu vkladať. Výskumy ukazujú, že obsah s jedným LSI kľúčovým slovom na každých 200-300 slov udržiava optimálnu rovnováhu medzi sémantickou bohatostou a čitateľnosťou. Tento pomer nie je striktným pravidlom, ale užitočným odporúčaním na zabezpečenie dostatočného tematického pokrytia bez preplnenia kľúčovými slovami.
LSI kľúčové slová a AI vyhľadávacia viditeľnosť
Pre značky a tvorcov obsahu, ktorí sa zameriavajú na viditeľnosť v AI vyhľadávaní a citácie naprieč platformami, ktoré monitoruje AmICited, je pochopenie LSI kľúčových slov a sémantických vzťahov čoraz dôležitejšie. AI systémy, ktoré generujú odpovede pre ChatGPT, Perplexity, Google AI Overviews a Claude, hodnotia zdrojový materiál podľa tematickej komplexnosti a signálov odbornosti. Ak váš obsah obsahuje sémanticky príbuzné pojmy a koncepty, signalizujete tým týmto AI systémom, že ste tému dôkladne pokryli. Táto komplexnosť zvyšuje pravdepodobnosť, že váš obsah bude vybraný ako zdroj pre AI-generované odpovede. Okrem toho sémantické kľúčové slová pomáhajú vytvárať vzťahy medzi entitami—prepojenia medzi konceptmi, ktoré AI systémy využívajú na pochopenie znalostných oblastí. Napríklad obsah o „káve“, ktorý zahŕňa súvisiace entity ako „kofeín“, „espresso stroje“, „kávové zrná“ a „metódy prípravy“, preukazuje širšiu odbornosť než obsah, ktorý spomína iba hlavné kľúčové slovo. Takýto entity-bohatý obsah je pravdepodobnejšie citovaný AI systémami generujúcimi komplexné odpovede. S pokračujúcim vývojom AI vyhľadávania sa schopnosť preukázať tematickú autoritu cez sémantickú bohatost stáva kľúčovou konkurenčnou výhodou pre viditeľnosť a citácie.
Kľúčové aspekty LSI kľúčových slov a sémantickej optimalizácie
- Kontextové vzťahy: Príbuzné pojmy, ktoré sa často vyskytujú spolu v podobných kontextoch a pomáhajú vyhľadávačom pochopiť význam obsahu nad rámec presných zhod kľúčových slov
- Vzorce spoločného výskytu: Slová, ktoré sa opakovane objavujú spolu vo viacerých dokumentoch, signalizujúce sémantické vzťahy pre vyhľadávacie algoritmy
- Tematická autorita: Komplexné pokrytie témy prostredníctvom príbuzných pojmov, čím sa buduje odbornosť a dôveryhodnosť voči vyhľadávačom aj AI systémom
- Prirodzená integrácia: Plynulé začlenenie príbuzných výrazov do obsahu, ktorý je prirodzený pre čitateľov a zároveň signalizuje relevanciu vyhľadávačom
- Zladenie so zámerom vyhľadávania: Použitie sémanticky príbuzných pojmov, ktoré zodpovedajú skutočným vyhľadávaniam používateľov, čím sa zvyšuje relevantnosť obsahu a počet preklikov
- Rozpoznávanie entít: Identifikácia a zahrnutie pomenovaných entít a pojmov súvisiacich s hlavnou témou, čo je kľúčové pre hodnotenie AI systémami
- Sémantická bohatost: Hĺbka a šírka konceptuálne príbuzného obsahu, indikujúca komplexné pokrytie témy
- Variácie long-tail kľúčových slov: Dlhšie, špecifickejšie frázy, ktoré zachytávajú príbuzný zámer vyhľadávania a znižujú konkurenciu
- Komplexnosť obsahu: Pokrytie viacerých uhlov pohľadu a subtemát súvisiacich s hlavným kľúčovým slovom, čím sa zlepšuje celková kvalita obsahu
- Potenciál AI citácií: Preukázanie odbornosti prostredníctvom sémantického pokrytia zvyšuje šancu, že vás AI systémy ako ChatGPT a Perplexity budú citovať
Budúcnosť sémantického porozumenia vo vyhľadávaní
Vývoj vyhľadávacích technológií jasne smeruje k čoraz sofistikovanejšiemu sémantickému porozumeniu poháňanému umelou inteligenciou a strojovým učením. LSI kľúčové slová ako konkrétna technológia predstavujú raný pokus o riešenie problému sémantického porozumenia, no moderné prístupy tieto možnosti ďaleko prekonali. Budúce vyhľadávacie systémy sa pravdepodobne budú ešte viac spoliehať na neurónové siete, transformer modely a veľké jazykové modely na pochopenie nielen toho, čo obsah hovorí, ale aj čo znamená v širšom kontexte. Vznik disciplíny Generative Engine Optimization (GEO) tento posun odráža—marketéri musia dnes optimalizovať nielen pre tradičné vyhľadávače, ale aj pre AI systémy, ktoré generujú odpovede. Tieto AI systémy hodnotia zdrojový materiál podľa komplexnosti, odbornosti a tematickej autority—vlastností, ktoré prirodzene vznikajú sémantickou optimalizáciou. Ako sa AI Overviews čoraz viac objavujú vo výsledkoch vyhľadávania, schopnosť preukázať tematickú odbornosť cez sémanticky bohatý obsah nadobúda na hodnote. Budúcnosť pravdepodobne prinesie ešte užšie prepojenie medzi tradičným SEO a AI optimalizáciou, pričom sémantické porozumenie bude mostom medzi týmito disciplínami. Tvorcovia obsahu, ktorí pochopia a aplikujú princípy sémantickej optimalizácie, si udržia výhodu vo viditeľnosti aj s ďalším rozvojom vyhľadávacích technológií.
Záver: Od LSI kľúčových slov k sémantickej autorite
Hoci LSI kľúčové slová ako konkrétny algoritmický prístup Google už nepoužíva, základný princíp—že vyhľadávače majú rozumieť kontextu a významu obsahu—je dnes relevantnejší než kedykoľvek predtým. Vývoj od LSI cez sémantické SEO až po modernú AI optimalizáciu predstavuje prirodzený progres v tom, ako vyhľadávacie technológie chápu a hodnotia obsah. Pre tvorcov obsahu a značky zamerané na viditeľnosť vo vyhľadávačoch aj AI platformách je praktický záver jasný: tvorte komplexný, tematicky bohatý obsah, ktorý prirodzene zahŕňa príbuzné pojmy a preukazuje odbornosť. Takýto prístup spĺňa požiadavky tradičných vyhľadávačov aj hodnotiace kritériá AI systémov ako ChatGPT, Perplexity, Google AI Overviews a Claude. Pochopením vzťahov medzi hlavným kľúčovým slovom a sémanticky príbuznými pojmami vytvoríte obsah, ktorý sa dobre umiestňuje v tradičných výsledkoch vyhľadávania a zároveň je citovaný ako autoritatívny zdroj AI systémami. Budúcnosť viditeľnosti vo vyhľadávaní patrí tým, ktorí zvládnu sémantickú optimalizáciu—nie preplňovaním kľúčových slov či umelým vkladaním výrazov, ale skutočnou odbornosťou a komplexným pokrytím témy, ktoré prirodzene zahŕňa príbuzné pojmy a ukazuje hlboké porozumenie danej oblasti.