
Čo je MUM a ako ovplyvňuje AI vyhľadávanie?
Zistite viac o Google Multitask Unified Model (MUM) a jeho vplyve na AI vyhľadávacie výsledky. Pochopte, ako MUM spracúva zložité dopyty naprieč viacerými formá...
8 min čítania
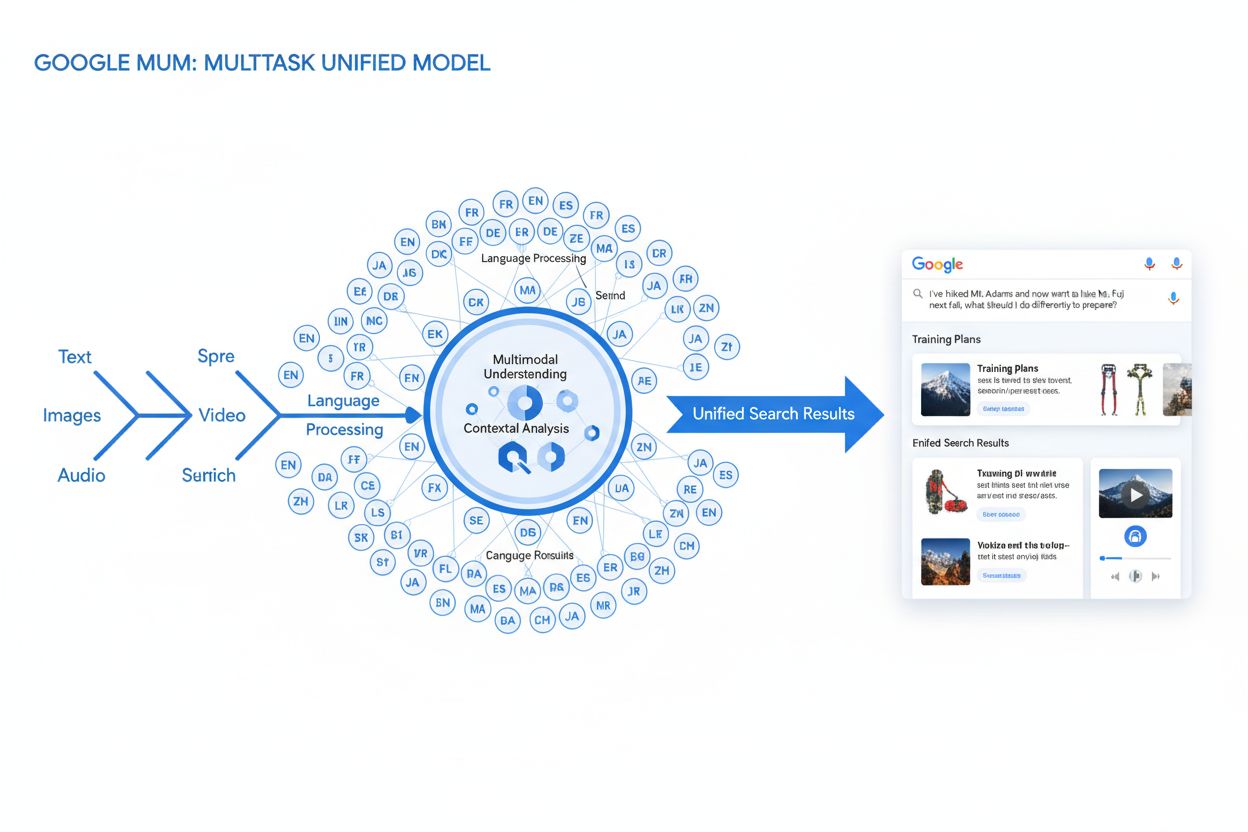
MUM (Multitask Unified Model) je pokročilý multimodálny AI model od spoločnosti Google, ktorý súčasne spracúva text, obrázky, video a zvuk vo viac než 75 jazykoch, aby poskytoval komplexnejšie a kontextuálne výsledky vyhľadávania. Uvedený v roku 2021, MUM je 1 000-krát výkonnejší ako BERT a predstavuje zásadnú zmenu v tom, ako vyhľadávače chápu a odpovedajú na zložité požiadavky používateľov.
MUM (Multitask Unified Model) je pokročilý multimodálny AI model od spoločnosti Google, ktorý súčasne spracúva text, obrázky, video a zvuk vo viac než 75 jazykoch, aby poskytoval komplexnejšie a kontextuálne výsledky vyhľadávania. Uvedený v roku 2021, MUM je 1 000-krát výkonnejší ako BERT a predstavuje zásadnú zmenu v tom, ako vyhľadávače chápu a odpovedajú na zložité požiadavky používateľov.
MUM (Multitask Unified Model) je pokročilý multimodálny model umelej inteligencie od Google, navrhnutý s cieľom revolučne zmeniť spôsob, akým vyhľadávače chápu a reagujú na zložité dopyty používateľov. Oznámený v máji 2021 Pandu Nayakom, Google Fellow a viceprezidentom pre vyhľadávanie, MUM predstavuje zásadný posun v technológiách vyhľadávania informácií. Postavený na text-to-text frameworku T5 a pozostávajúci z približne 110 miliárd parametrov je MUM 1 000-krát výkonnejší ako BERT, predchádzajúci prelomový model Google na spracovanie prirodzeného jazyka. Na rozdiel od tradičných algoritmov, ktoré spracúvajú text izolovane, MUM súčasne spracúva text, obrázky, video a zvuk a rozumie informáciám vo viac než 75 jazykoch natívne. Táto multimodálna a viacjazyčná schopnosť umožňuje MUM chápať zložité otázky, ktoré predtým vyžadovali viacero vyhľadávaní, a premieňa vyhľadávanie z jednoduchého porovnávania kľúčových slov na inteligentný, kontextovo uvedomelý systém získavania informácií. MUM nielen rozumie jazyku, ale ho aj generuje, vďaka čomu vie syntetizovať informácie z rôznych zdrojov a formátov a poskytovať komplexné, nuansované odpovede, ktoré adresujú celý rozsah zámeru používateľa.
Cesta Google k MUM predstavuje roky postupných inovácií v spracovaní prirodzeného jazyka a strojovom učení. Vývoj začal s Hummingbirdom (2013), ktorý zaviedol sémantické porozumenie, aby vyhľadávač interpretoval význam dopytov, nielen porovnával kľúčové slová. Nasledoval RankBrain (2015), ktorý použil strojové učenie na pochopenie long-tail kľúčových slov a nových vyhľadávacích vzorcov. Neural Matching (2018) posunul toto ďalej pomocou neurónových sietí na hlbšie sémantické párovanie dopytov s relevantným obsahom. BERT (Bidirectional Encoder Representations from Transformers), uvedený v roku 2019, predstavoval významný míľnik tým, že rozumel kontextu v rámci viet a odsekov, čo zlepšilo schopnosť Google interpretovať nuansovaný jazyk. BERT však mal významné obmedzenia—spracúval len text, obmedzene podporoval viac jazykov a nedokázal zvládnuť komplexné dopyty vyžadujúce syntézu informácií naprieč viacerými formátmi. Podľa výskumu Google používatelia zadávajú priemerne osem samostatných dopytov na zodpovedanie zložitých otázok, napríklad pri porovnávaní dvoch turistických destinácií alebo hodnotení produktov. Táto štatistika poukazovala na zásadnú medzeru vo vyhľadávacej technológii, ktorú mal MUM špecificky riešiť. Helpful Content Update (2022) a rámec E-E-A-T (2023) ďalej vylepšili, ako Google uprednostňuje autoritatívny a dôveryhodný obsah. MUM nadväzuje na všetky tieto inovácie a zároveň prináša schopnosti, ktoré prekonávajú predchádzajúce limity, čím predstavuje nie iba postupné vylepšenie, ale paradigmatickú zmenu v tom, ako vyhľadávače spracúvajú a poskytujú informácie.
Technický základ MUM stojí na architektúre Transformer, konkrétne na frameworku T5 (Text-to-Text Transfer Transformer), ktorý Google vyvinul skôr. T5 pristupuje ku všetkým úlohám spracovania prirodzeného jazyka ako k text-to-text problémom, pričom vstupy aj výstupy konvertuje do jednotnej textovej reprezentácie. MUM tento prístup rozširuje o multimodálne spracovanie, vďaka čomu dokáže zvládať text, obrázky, video a zvuk súčasne v rámci jedného modelu. Toto architektonické rozhodnutie je významné, pretože umožňuje MUM chápať vzťahy a kontext naprieč rôznymi typmi médií spôsobmi, ktoré predchádzajúce modely nedokázali. Napríklad pri spracovaní otázky o turistike na Mt. Fuji v kombinácii s obrázkom konkrétnych topánok MUM neanalyzuje text a obrázok oddelene—spracúva ich spoločne a chápe, ako vlastnosti topánok súvisia s kontextom otázky. Modelov 110 miliárd parametrov mu dáva kapacitu uchovávať a spracúvať obrovské množstvo vedomostí o jazyku, vizuálnych konceptoch a ich vzťahoch. MUM je trénovaný vo viac než 75 jazykoch a mnohých úlohách súčasne, čo mu umožňuje rozvinúť komplexnejšie chápanie informácií a svetového poznania, než aké majú modely trénované na jednom jazyku či úlohe. Tento multitaskový prístup znamená, že MUM rozpoznáva vzory a vzťahy prenosné naprieč jazykmi a doménami, vďaka čomu je robustnejší a univerzálnejší než predchádzajúce modely. Súčasné spracúvanie viacerých jazykov počas tréningu umožňuje MUM prenos vedomostí medzi jazykmi, teda rozumie informáciám v jednom jazyku a aplikuje toto porozumenie na dopyty v inom, čím efektívne prekonáva jazykové bariéry, ktoré predtým obmedzovali výsledky vyhľadávania.
| Atribút | MUM (2021) | BERT (2019) | RankBrain (2015) | T5 Framework |
|---|---|---|---|---|
| Primárna funkcia | Multimodálne porozumenie dopytom a syntéza odpovedí | Kontextové porozumenie textu | Interpretácia long-tail kľúčových slov | Text-to-text prenos učenia |
| Vstupné modality | Text, obrázky, video, zvuk | Iba text | Iba text | Iba text |
| Jazyková podpora | 75+ jazykov natívne | Obmedzená viacjazyčná podpora | Primárne angličtina | Primárne angličtina |
| Počet parametrov | ~110 miliárd | ~340 miliónov | Nezverejnené | ~220 miliónov |
| Porovnanie výkonu | 1 000× výkonnejší ako BERT | Základ | Predchodca BERT | Základ MUM |
| Schopnosti | Porozumenie + generovanie | Len porozumenie | Rozpoznávanie vzorov | Textová transformácia |
| Vplyv na SERP | Obohatené výsledky vo viacerých formátoch | Lepšie úryvky a kontext | Zlepšená relevantnosť | Základná technológia |
| Spracovanie zložitých dopytov | Zložité viacstupňové dopyty | Kontext jednej otázky | Variácie long-tail | Úlohy textovej transformácie |
| Prenos vedomostí | Naprieč jazykmi a modalitami | Len v rámci jazyka | Limitovaný prenos | Prenos medzi úlohami |
| Reálne využitie | Google Search, AI Overviews | Google Search ranking | Google Search ranking | Technický základ MUM |
Spracovanie dopytov v MUM zahŕňa viacero sofistikovaných krokov, ktoré spoločne poskytujú komplexné a kontextuálne odpovede. Keď používateľ zadá vyhľadávací dopyt, MUM najskôr vykoná jazykovo-agnostické predspracovanie, teda rozumie dopytu v ktoromkoľvek z podporovaných 75+ jazykov bez potreby prekladu. Táto natívna znalosť zachováva jazykové nuansy a regionálny kontext, ktorý by sa pri preklade mohol stratiť. Následne MUM aplikuje sequence-to-sequence matching, analyzuje celý dopyt ako sled významov, nie izolované kľúčové slová. Tento prístup umožňuje chápať vzťahy medzi konceptmi—napríklad rozpoznať, že otázka o “príprave na Mt. Fuji po výstupe na Mt. Adams” zahŕňa porovnanie, prípravu a kontextové prispôsobenie. Súčasne MUM vykonáva analýzu multimodálneho vstupu, teda spracúva akékoľvek obrázky, videá či iné médiá pripojené k dopytu. Model následne realizuje súbežné spracovanie dopytu, teda hodnotí viacero možných zámerov používateľa paralelne, nie len jednu interpretáciu. Znamená to, že MUM môže rozpoznať, že otázka o turistike na Mt. Fuji môže súvisieť s fyzickou prípravou, výberom výstroja, kultúrnymi zážitkami či cestovnými logistikami—a zobrazí relevantné informácie pre všetky tieto možnosti. Vektorové sémantické porozumenie konvertuje dopyt a indexovaný obsah do vysokodimenzionálnych vektorov reprezentujúcich význam, čím umožňuje vyhľadávanie na základe konceptuálnej podobnosti, nie len kľúčových slov. MUM potom aplikuje filtrovanie obsahu cez prenos vedomostí, využíva strojové učenie trénované na vyhľadávacích logoch, údajoch o prehliadaní a vzorcoch správania používateľov na uprednostnenie kvalitných, autoritatívnych zdrojov. Nakoniec MUM generuje multimediálne obohatenú kompozíciu SERP, ktorá kombinuje textové úryvky, obrázky, videá, súvisiace otázky a interaktívne prvky do jedného vizuálne vrstveného vyhľadávacieho zážitku. Celý tento proces prebieha v milisekundách, čo umožňuje MUM poskytovať výsledky, ktoré zohľadňujú nielen explicitný dopyt, ale aj očakávané doplňujúce otázky a súvisiace informačné potreby.
Multimodálne schopnosti MUM predstavujú zásadný odklon od systémov vyhľadávania založených len na texte. Model dokáže súčasne spracúvať a chápať informácie z textu, obrázkov, videa a zvuku, extrahovať význam z každej modality a syntetizovať ho do zrozumiteľných odpovedí. Táto schopnosť je mimoriadne silná pre otázky, kde je dôležitý vizuálny kontext. Napríklad ak sa používateľ opýta “Môžem tieto turistické topánky použiť na Mt. Fuji?” a priloží obrázok svojich topánok, MUM porozumie vlastnostiam topánok z obrázka—materiál, vzor podrážky, výšku, farbu—a spojí toto vizuálne porozumenie s poznatkami o teréne, klíme a požiadavkách na turistiku na Mt. Fuji, aby poskytol kontextuálnu odpoveď. Viacjazyčný rozmer MUM je rovnako transformačný. S natívnou podporou viac než 75 jazykov dokáže MUM realizovať prenos vedomostí medzi jazykmi, teda učí sa zo zdrojov v jednom jazyku a aplikuje tieto poznatky na dopyty v inom. Týmto spôsobom sa prelamuje významná bariéra, ktorá predtým obmedzovala výsledky len na obsah v jazyku používateľa. Ak sú najpodrobnejšie informácie o Mt. Fuji dostupné najmä v japončine—vrátane miestnych turistických sprievodcov, sezónnych podmienok a kultúrnych poznatkov—MUM rozumie tomuto obsahu v japončine a vie relevantné informácie ponúknuť aj anglicky hovoriacim používateľom. Podľa testov Google MUM dokázal v priebehu niekoľkých sekúnd uviesť 800 variácií vakcín proti COVID-19 vo viac než 50 jazykoch, čo demonštruje rozsah a rýchlosť jeho viacjazyčných schopností. Táto viacjazyčná znalosť je obzvlášť cenná pre používateľov z neanglicky hovoriacich trhov a pre dopyty na témy s bohatými informáciami vo viacerých jazykoch. Kombinácia multimodálneho a viacjazyčného spracovania znamená, že MUM vie zobrazovať najrelevantnejšie informácie bez ohľadu na formát či pôvodný jazyk ich publikovania, čím vytvára skutočne globálny vyhľadávací zážitok.
MUM zásadne mení spôsob zobrazovania a prežívania výsledkov vyhľadávania používateľmi. Namiesto tradičného zoznamu modrých odkazov, ktorý dominoval desaťročia, vytvára MUM obohatené, interaktívne SERPy, ktoré kombinujú viaceré formáty obsahu na jednej stránke. Používatelia teraz môžu vidieť textové úryvky, vysokokvalitné obrázky, video karusely, súvisiace otázky a interaktívne prvky bez opustenia stránky s výsledkami. Tento posun má zásadné dôsledky na spôsob, akým používatelia vyhľadávajú. Namiesto série viacerých vyhľadávaní na získanie informácií o zložitej téme môžu používatelia skúmať rôzne pohľady a podtémy priamo v SERPe. Napríklad dopyt o “príprave na Mt. Fuji na jeseň” môže zobraziť porovnania nadmorských výšok, predpovede počasia, odporúčania výstroja, videonávody a recenzie používateľov—všetko kontextuálne usporiadané na jednej stránke. Integrácia Google Lens poháňaná MUM umožňuje vyhľadávať pomocou obrázkov namiesto kľúčových slov, čím sa vizuálne prvky vo fotografiách premieňajú na interaktívne nástroje objavovania. Panely “Things to Know” rozdeľujú zložité otázky na stráviteľné podtémy a vedú používateľov rôznymi aspektmi témy s relevantnými úryvkami pre každú z nich. Zväčšiteľné, vysokokvalitné obrázky sa zobrazujú priamo vo výsledkoch, čo umožňuje vizuálne porovnávanie a znižuje trenie v raných fázach rozhodovania. Funkcia “Refine and Broaden” navrhuje súvisiace koncepty, ktoré pomáhajú používateľom buď ísť viac do hĺbky, alebo preskúmať príbuzné témy. Tieto zmeny znamenajú posun od vyhľadávania ako jednoduchého vyhľadávacieho nástroja k interaktívnemu, objaviteľskému zážitku, ktorý predvída potreby používateľov a poskytuje komplexné informácie priamo v rozhraní vyhľadávania. Výskumy ukazujú, že tento bohatší SERP zážitok znižuje priemerný počet vyhľadávaní potrebných na zodpovedanie zložitých otázok, hoci zároveň znamená, že používatelia môžu informácie spotrebovať priamo vo výsledkoch bez kliknutia na webstránky.
Pre organizácie sledujúce svoju prítomnosť v AI systémoch znamená MUM kľúčový posun v tom, ako sú informácie objavované a zobrazované. Ako sa MUM čoraz viac integruje do Google Search a ovplyvňuje ďalšie AI systémy, porozumenie tomu, ako sa značky a domény zobrazujú vo výsledkoch poháňaných MUM, je nevyhnutné pre udržanie viditeľnosti. Multimodálne spracovanie MUM znamená, že značky musia optimalizovať naprieč viacerými formátmi obsahu, nielen pre text. Značka, ktorá sa doteraz spoliehala na umiestnenie vďaka kľúčovým slovám, musí teraz zabezpečiť, že jej obsah je objaviteľný cez obrázky, videá a štruktúrované dáta. Schopnosť modelu syntetizovať informácie z rôznych zdrojov znamená, že viditeľnosť značky závisí nielen od jej vlastnej stránky, ale aj od toho, ako sú jej informácie zobrazené v širšom webovom ekosystéme. Viacjazyčné schopnosti MUM prinášajú nové príležitosti aj výzvy pre globálne značky. Obsah publikovaný v jednom jazyku je teraz objaviteľný používateľmi vyhľadávajúcimi v iných jazykoch, čím sa rozširuje potenciálny dosah. To však znamená aj potrebu zabezpečiť presnosť a konzistentnosť informácií naprieč jazykmi, keďže MUM môže pre jednu otázku zobrazovať informácie z viacerých jazykových zdrojov. Pre AI monitorovacie platformy ako AmICited je sledovanie vplyvu MUM kľúčové, pretože reprezentuje spôsob, akým moderné AI systémy získavajú a prezentujú informácie. Pri monitorovaní výskytu značky v AI odpovediach—či už v Google AI Overviews, Perplexity, ChatGPT alebo Claude—porozumenie technológii MUM pomáha vysvetliť, prečo je určitý obsah zobrazovaný a ako optimalizovať viditeľnosť. Posun k multimodálnemu, viacjazyčnému vyhľadávaniu znamená, že značky potrebujú komplexný monitoring naprieč formátmi a jazykmi, nielen tradičné sledovanie kľúčových slov. Organizácie, ktoré pochopia schopnosti MUM, môžu lepšie optimalizovať svoju obsahovú stratégiu, aby ostali viditeľné v tomto novom vyhľadávacom prostredí.
Aj keď MUM predstavuje významný pokrok, prináša aj nové výzvy a obmedzenia, s ktorými sa organizácie musia vysporiadať. Nižšia miera preklikov je veľkým problémom pre vydavateľov a tvorcov obsahu, keďže používatelia môžu spotrebovať komplexné informácie priamo vo výsledkoch vyhľadávania bez kliknutia na stránky. Znamená to, že tradičné metriky návštevnosti už nemusia byť spoľahlivým ukazovateľom úspechu obsahu. Vyššie technické SEO nároky znamenajú, že na to, aby bol obsah správne pochopený MUM, musí byť dobre štruktúrovaný, so správnym schéma označením, sémantickým HTML a zreteľnými vzťahmi entít. Obsah bez tejto technickej základne nemusí byť správne indexovaný alebo pochopený multimodálnym spracovaním MUM. Saturácia SERP vytvára výzvy pre viditeľnosť, keďže viacero formátov obsahu súťaží o pozornosť na jednej stránke. Aj silný obsah môže získať menej alebo žiadne kliknutia, ak používatelia nájdu dostatok informácií priamo v SERPe. Riziko zavádzajúcich výsledkov hrozí, ak MUM zobrazí informácie z viacerých zdrojov, ktoré si odporujú, alebo ak sa pri syntéze stratí kontext. Závislosť od štruktúrovaných dát znamená, že neštruktúrovaný či zle formátovaný obsah nemusí byť MUM správne pochopený alebo zobrazený. Výzvy v jazykových a kultúrnych nuansách sa môžu objaviť pri prenose vedomostí medzi jazykmi, keď MUM nezachytí kultúrny kontext či regionálne odlišnosti významu. Požiadavky na výpočtové zdroje pre prevádzku MUM vo veľkom sú značné, hoci Google investoval do zvýšenia efektivity a znižovania uhlíkovej stopy. Otázky zaujatosti a férovosti si vyžadujú neustálu pozornosť, aby MUM nereprodukoval zaujatosti z trénovacích dát alebo neuprednostňoval určité pohľady či komunity.
**Vznik MUM si vyžaduje zásadné zmeny
Kým BERT (2019) sa zameriaval na porozumenie prirodzeného jazyka v textových dopytoch, MUM predstavuje významný posun. MUM je postavený na text-to-text frameworku T5 a je 1 000-krát výkonnejší ako BERT. Na rozdiel od BERT, ktorý spracúva iba text, MUM je multimodálny—súčasne spracúva text, obrázky, video a zvuk. Navyše MUM natívne podporuje viac než 75 jazykov, zatiaľ čo BERT mal pri uvedení obmedzenú viacjazyčnú podporu. MUM dokáže jazyk nielen chápať, ale aj generovať, vďaka čomu zvládne aj zložité, viacstupňové dopyty, ktoré BERT efektívne riešiť nedokázal.
Multimodálny znamená, že MUM dokáže spracovávať a chápať informácie z viacerých typov vstupov súčasne. Namiesto samostatnej analýzy textu, obrázkov alebo videa spracúva MUM všetky tieto formáty naraz v jednotnom systéme. To znamená, že keď hľadáte niečo ako 'turistické topánky na Mt. Fuji', MUM rozumie vašej textovej otázke, analyzuje obrázky topánok, pozrie si videorecenzie a extrahuje zvukové popisy—všetko súčasne. Tento integrovaný prístup umožňuje MUM poskytovať bohatšie a kontextuálnejšie odpovede, ktoré zohľadňujú informácie naprieč rôznymi typmi médií.
MUM je trénovaný vo viac než 75 jazykoch, čo je významný pokrok v globálnej dostupnosti vyhľadávania. Táto viacjazyčná schopnosť znamená, že MUM dokáže prenášať vedomosti medzi jazykmi—ak existujú užitočné informácie o téme v japončine, MUM im rozumie a vie ich ponúknuť aj anglicky hovoriacim používateľom. Týmto spôsobom sa prelamujú jazykové bariéry, ktoré predtým obmedzovali výsledky vyhľadávania len na obsah v rodnom jazyku používateľa. Pre značky a tvorcov obsahu to znamená potenciálnu viditeľnosť naprieč viacerými jazykovými trhmi a používatelia na celom svete môžu získať informácie bez ohľadu na pôvodný jazyk publikácie.
T5 (Text-to-Text Transfer Transformer) je skorší model spoločnosti Google založený na transformeroch, na ktorom je MUM postavený. Framework T5 považuje všetky NLP úlohy za text-to-text problémy, teda vstupy aj výstupy konvertuje do textového formátu pre jednotné spracovanie. MUM rozširuje možnosti T5 o multimodálne spracovanie (zvládanie obrázkov, videa a zvuku) a škáluje ho na približne 110 miliárd parametrov. Tento základ umožňuje MUM rozumieť aj generovať jazyk, pričom zachováva efektivitu a flexibilitu, ktoré T5 preslávili.
MUM zásadne mení spôsob, akým je obsah objavovaný a zobrazovaný vo vyhľadávaní. Namiesto tradičných modrých odkazov vytvára MUM obohatené výsledky s viacerými formátmi obsahu—obrázky, videá, textové úryvky a interaktívne prvky—všetko na jednej stránke. To znamená, že značky musia optimalizovať naprieč viacerými formátmi, nielen pre text. Obsah, ktorý predtým vyžadoval viacero kliknutí, sa teraz môže zobrazovať priamo vo výsledkoch vyhľadávania. Znamená to však aj nižšiu mieru preklikov pre niektorý obsah, keďže používatelia môžu informácie získať priamo v SERPe. Značky sa preto musia sústrediť na viditeľnosť v samotných výsledkoch vyhľadávania a zabezpečiť, aby bol ich obsah správne štruktúrovaný a označený schémou, aby ho MUM pochopil.
MUM je kľúčový pre AI monitorovacie platformy, pretože predstavuje spôsob, akým moderné AI systémy chápu a vyhľadávajú informácie. Ako sa MUM stáva bežnejším v Google Search a ovplyvňuje ďalšie AI systémy, monitorovanie výskytu značiek a domén vo výsledkoch poháňaných MUM je nevyhnutné. AmICited sleduje, ako sú značky citované a zobrazované v AI systémoch vrátane vyhľadávania vylepšeného o Google MUM. Porozumenie multimodálnym a viacjazyčným schopnostiam MUM pomáha organizáciám optimalizovať svoju prítomnosť naprieč rôznymi formátmi obsahu a jazykmi, aby boli viditeľné vtedy, keď systémy ako MUM prezentujú ich informácie používateľom.
Áno, MUM dokáže spracovávať obrázky a video s vysokou úrovňou porozumenia. Keď nahráte obrázok alebo zahrniete video do dopytu, MUM nerozoznáva iba objekty—extrahuje kontext, význam a vzťahy. Napríklad, ak ukážete MUM fotografiu turistických topánok a opýtate sa 'môžem tieto použiť na Mt. Fuji?', MUM z obrázka pochopí vlastnosti topánok a spojí toto porozumenie s vašou otázkou, aby poskytol kontextuálnu odpoveď. Táto multimodálna schopnosť je jednou z najsilnejších vlastností MUM a umožňuje odpovedať na otázky, ktoré vyžadujú vizuálne aj textové vedomosti.
Začnite sledovať, ako AI chatboty spomínajú vašu značku na ChatGPT, Perplexity a ďalších platformách. Získajte použiteľné poznatky na zlepšenie vašej prítomnosti v AI.
Zistite viac o Google Multitask Unified Model (MUM) a jeho vplyve na AI vyhľadávacie výsledky. Pochopte, ako MUM spracúva zložité dopyty naprieč viacerými formá...
Diskusia komunity vysvetľuje Google MUM a jeho dopad na AI vyhľadávanie. Odborníci zdieľajú, ako tento multimodálny AI model ovplyvňuje optimalizáciu obsahu a v...

Ovládnite optimalizáciu multimodálneho AI vyhľadávania. Zistite, ako optimalizovať obrázky a hlasové dopyty pre AI-poháňané výsledky vyhľadávania, vrátane strat...