
Vylepšovanie dopytov
Vylepšovanie dopytov je iteratívny proces optimalizácie vyhľadávacích dopytov pre lepšie výsledky v AI vyhľadávačoch. Zistite, ako funguje v ChatGPT, Perplexity...
10 min čítania
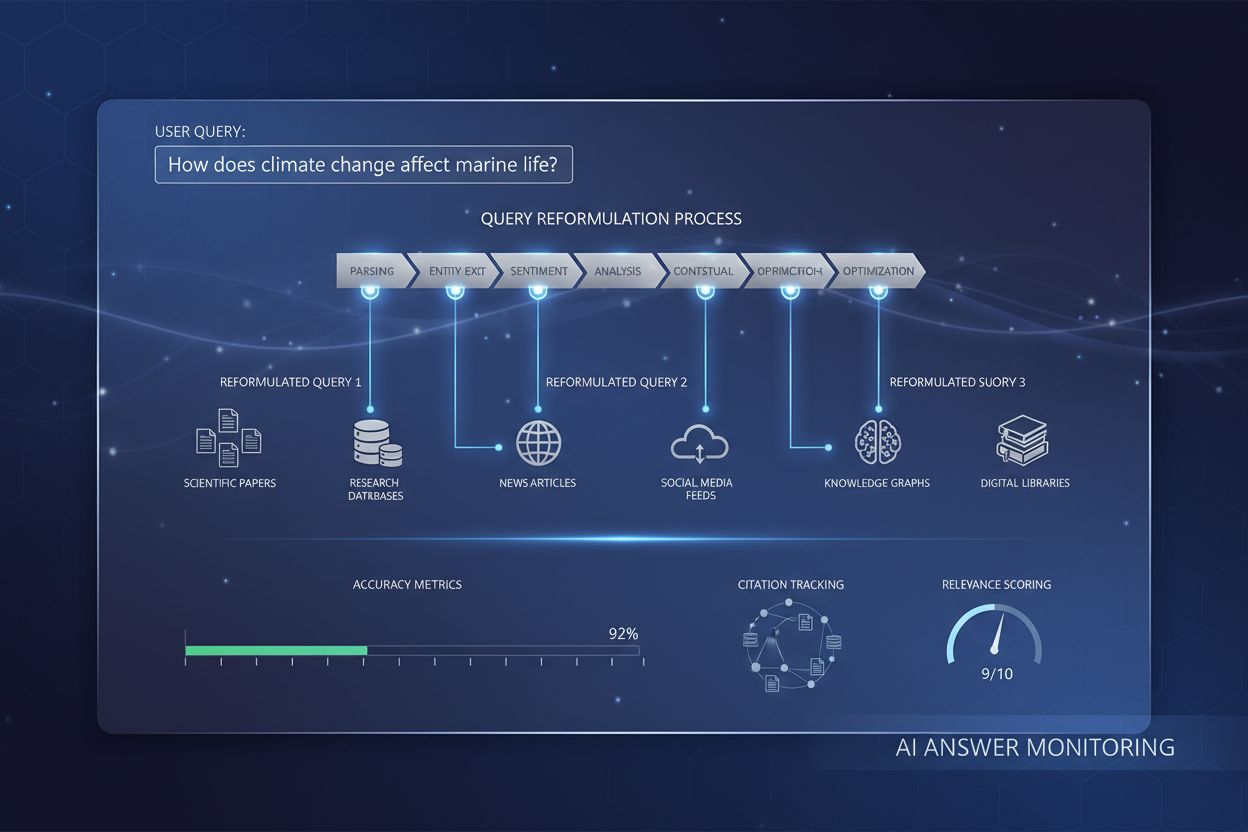
Reformulácia dopytu je proces, pri ktorom AI systémy interpretujú, preštruktúrovávajú a vylepšujú používateľské dopyty s cieľom zlepšiť presnosť a relevantnosť vyhľadávania informácií. Premieňa jednoduché alebo nejednoznačné vstupy používateľa na podrobnejšie a kontextuálne obohatené verzie, ktoré sú v súlade s chápaním AI systému, čím umožňuje presnejšie a komplexnejšie odpovede.
Reformulácia dopytu je proces, pri ktorom AI systémy interpretujú, preštruktúrovávajú a vylepšujú používateľské dopyty s cieľom zlepšiť presnosť a relevantnosť vyhľadávania informácií. Premieňa jednoduché alebo nejednoznačné vstupy používateľa na podrobnejšie a kontextuálne obohatené verzie, ktoré sú v súlade s chápaním AI systému, čím umožňuje presnejšie a komplexnejšie odpovede.
Reformulácia dopytu je proces transformácie, rozšírenia alebo prepisovania pôvodného vyhľadávacieho dopytu používateľa tak, aby bol lepšie prispôsobený možnostiam podkladového systému na vyhľadávanie informácií a skutočnému zámeru používateľa. V kontexte umelej inteligencie a spracovania prirodzeného jazyka (NLP) reformulácia dopytu preklenuje kritickú priepasť medzi tým, ako používatelia prirodzene formulujú svoje informačné potreby, a tým, ako ich AI systémy interpretujú a spracovávajú. Táto technika je nevyhnutná v moderných AI systémoch, pretože používatelia často formulujú dopyty nepresne, používajú doménovú terminológiu nekonzistentne alebo vynechávajú kontextové informácie, ktoré by zlepšili presnosť vyhľadávania. Reformulácia dopytu funguje na prieniku vyhľadávania informácií, sémantického porozumenia a strojového učenia, čo umožňuje systémom generovať relevantnejšie výsledky reinterpretáciou dopytov z viacerých uhlov pohľadu – či už prostredníctvom rozšírenia o synonymá, kontextového obohatenia alebo štrukturálnej reorganizácie. Inteligentnou reformuláciou dopytov môžu AI systémy dramaticky zlepšiť kvalitu odpovedí, znížiť nejednoznačnosť a zabezpečiť, že získané informácie lepšie zodpovedajú zámeru používateľa.
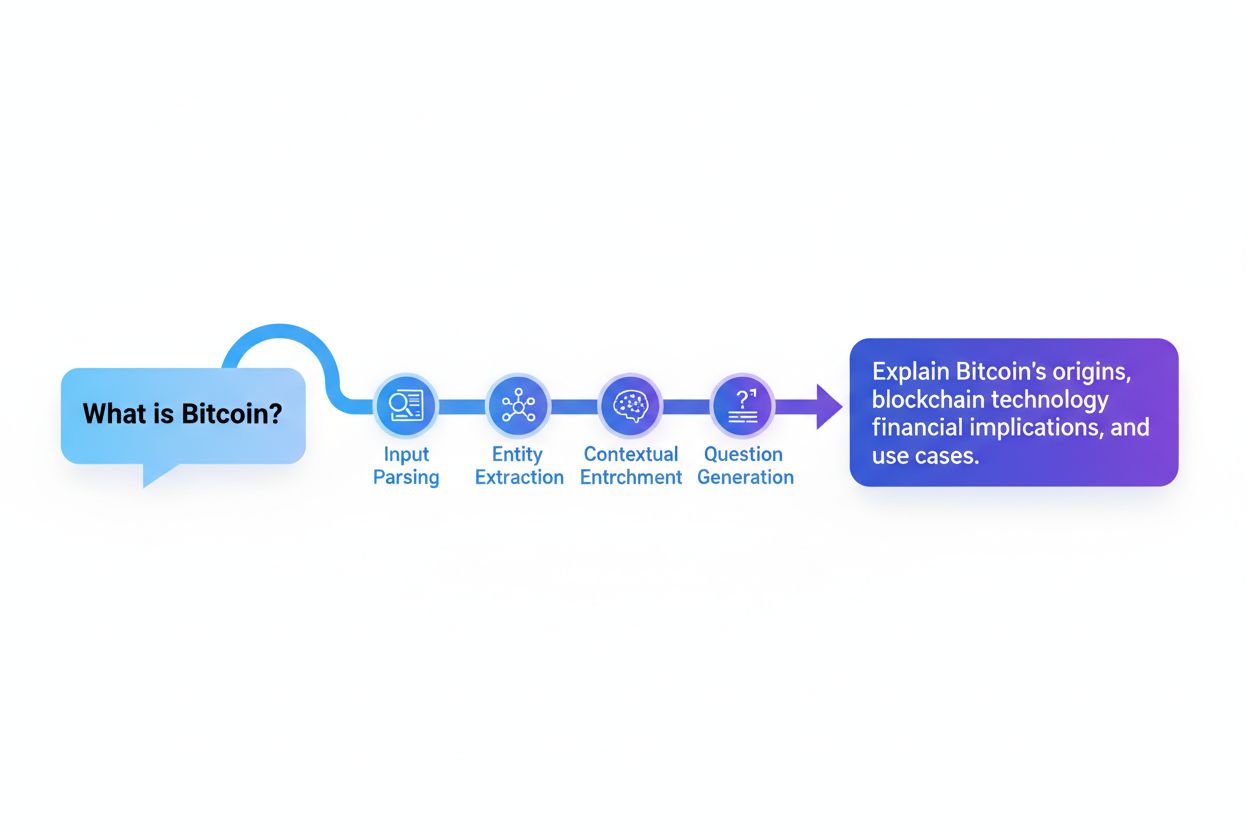
Systémy na reformuláciu dopytu zvyčajne fungujú prostredníctvom piatich prepojených komponentov, ktoré spolupracujú na transformácii surového vstupu používateľa na optimalizované vyhľadávacie dopyty. Parsovanie vstupu rozdeľuje pôvodný dopyt na jeho jednotlivé časti, identifikuje kľúčové slová, frázy a štrukturálne prvky. Extrakcia entít identifikuje pomenované entity (osoby, miesta, organizácie, produkty) a doménovo špecifické koncepty s významnou sémantickou hodnotou. Analýza sentimentu zachováva emocionálny tón alebo hodnotiaci postoj pôvodného dopytu, aby reformulované verzie udržiavali pôvodnú perspektívu používateľa. Kontextová analýza zahŕňa históriu relácie, informácie o profile používateľa a doménové znalosti na obohatenie dopytu o implicitný význam. Generovanie otázok premieňa deklaratívne vety alebo fragmenty na dobre štruktúrované otázky, ktoré vyhľadávacie systémy dokážu efektívnejšie spracovať.
| Komponent | Účel | Príklad |
|---|---|---|
| Parsovanie vstupu | Tokenizuje a segmentuje dopyt na zmysluplné jednotky | “najlepšie Python knižnice” → [“najlepšie”, “Python”, “knižnice”] |
| Extrakcia entít | Identifikuje pomenované entity a doménové koncepty | “Apple’s latest iPhone” → Entita: Apple (firma), iPhone (produkt) |
| Analýza sentimentu | Zachováva hodnotiaci tón a pohľad používateľa | “hrozný zákaznícky servis” → Zachováva negatívny sentiment v reformulácii |
| Kontextová analýza | Zahŕňa históriu relácie a doménové znalosti | Predchádzajúci dopyt o “strojovom učení” informuje aktuálny dopyt “neurónové siete” |
| Generovanie otázok | Premieňa fragmenty na štruktúrované otázky | “Python debugging” → “Ako môžem debugovať Python kód?” |
Proces reformulácie dopytu nasleduje systematickú šesťkrokovú metodológiu zameranú na postupné zvyšovanie kvality a relevantnosti dopytu:
Parsovanie a normalizácia vstupu
Extrakcia entít a konceptov
Zachovanie sentimentu a zámeru
Kontextové obohatenie
Rozšírenie dopytu a generovanie synoným
Optimalizácia a vyhodnotenie
Reformulácia dopytu využíva rôzne techniky od tradičných lexikálnych prístupov až po najmodernejšie neurónové metódy. Rozšírenie na základe synoným využíva etablované zdroje ako WordNet, embeddingy slov ako Word2Vec a GloVe a kontextové modely ako BERT na identifikáciu sémanticky podobných výrazov. Relaxácia dopytu postupne uvoľňuje obmedzenia dopytu na zvýšenie pokrytia v prípade nedostatočných pôvodných výsledkov – napríklad odstránením zriedkavých slov alebo rozšírením časových rozsahov. Integrácia spätnej väzby používateľa a kontextu relácie umožňuje systémom učiť sa z interakcií používateľov a vylepšovať reformulácie podľa toho, ktoré výsledky používateľ považuje za relevantné. Transformátorové prepisovače ako T5 (Text-to-Text Transfer Transformer) a GPT modely generujú úplne nové formulácie dopytu učením vzorcov z veľkých trénovacích datasetov párov dopytov. Hybridné prístupy kombinujú viacero techník – napríklad použitie pravidlami riadeného rozširovania synoným pre vysoko dôveryhodné výrazy a neurónových modelov pre nejednoznačné frázy. Skutočné implementácie často využívajú ansámblové metódy, ktoré generujú viacero reformulácií a zoraďujú ich pomocou naučených modelov relevantnosti. Napríklad e-commerce platformy môžu kombinovať doménovo špecifické slovníky synoným s BERT embeddingmi na spracovanie štandardizovanej produktovej terminológie aj hovorového jazyka používateľov, zatiaľ čo medicínske vyhľadávacie systémy využívajú špecializované ontológie spolu s transformer modelmi na zabezpečenie klinickej presnosti.
Reformulácia dopytu prináša významné zlepšenia v rôznych oblastiach výkonu AI systémov a používateľského zážitku:
Zlepšená presnosť vyhľadávania: Reformulované dopyty presnejšie vystihujú zámer používateľa, čo vedie k získaniu kvalitnejších dokumentov a relevantnejších AI-generovaných odpovedí. Rozšírením dopytu o synonymá a súvisiace koncepty systémy získajú dokumenty, ktoré môžu používať inú terminológiu ako pôvodný dopyt, čo výrazne zvyšuje šancu nájsť skutočne relevantné informácie.
Zvýšený recall a pokrytie: Rozšírenie dopytu zvyšuje počet relevantných získaných dokumentov skúmaním sémantických variácií a súvisiacich konceptov. Je to obzvlášť užitočné v špecializovaných doménach s rôznorodou terminológiou, vďaka čomu používatelia nepremeškajú relevantné informácie kvôli slovnej zásobe.
Zníženie nejednoznačnosti a objasnenie: Reformulačné procesy odstraňujú nejednoznačnosť vágnych dopytov začlenením kontextu a generovaním viacerých interpretácií. Tým systémy zvládnu dopyty ako “apple” (ovocie vs. firma) generovaním kontextovo špecifických reformulácií, ktoré získajú vhodné výsledky.
Lepší používateľský zážitok a spokojnosť: Používatelia dostávajú relevantnejšie výsledky rýchlejšie, čo znižuje potrebu opakovane meniť dopyt. Menej neúspešných vyhľadávaní a presnejšie prvé výsledky vedú k vyššej spokojnosti a menšej záťaži na používateľa.
Škálovateľnosť a efektívnosť: Reformulácia umožňuje systémom zvládať rôznorodé skupiny používateľov s rôznou slovnou zásobou, úrovňou odbornosti a jazykovým pozadím. Jeden reformulačný engine môže obsluhovať používateľov naprieč doménami a jazykmi, čím zlepšuje škálovateľnosť systému bez proporcionálneho nárastu infraštruktúry.
Neustále zlepšovanie a učenie: Systémy reformulácie dopytu je možné trénovať na dátach z interakcií používateľov, čím sa ich reformulačné stratégie neustále zlepšujú na základe úspešných reformulácií. Vzniká tak pozitívna spätná väzba, kde sa výkon systému časom zlepšuje s pribúdajúcimi dátami.
Doménová adaptácia a špecializácia: Reformulačné techniky je možné doladiť pre konkrétne domény (medicína, právo, technika) trénovaním na doménovo špecifických pároch dopytov a zapojením doménových ontológií. To umožňuje špecializovaným systémom zvládať doménovú terminológiu presnejšie ako všeobecné prístupy.
Odolnosť voči variáciám dopytu: Systémy sa stávajú robustnými voči preklepom, gramatickým chybám a hovorovému jazyku reformulovaním dopytov do štandardizovaných foriem. Táto odolnosť je zvlášť cenná pre hlasové rozhrania a mobilné vyhľadávanie s kolísavou kvalitou vstupu.
Reformulácia dopytu hrá kľúčovú úlohu v presnosti a spoľahlivosti AI-generovaných odpovedí, čo je zásadné pre platformy na monitorovanie AI odpovedí ako AmICited.com. Keď AI systémy reformulujú dopyty pred generovaním odpovedí, kvalita týchto reformulácií priamo ovplyvňuje, či AI získa vhodné zdrojové materiály a vygeneruje presné odpovede so správnymi citáciami. Zle reformulované dopyty môžu viesť k získaniu irelevantných dokumentov, čo spôsobí, že AI generuje odpovede bez správneho základu alebo s nevhodnými citáciami. V kontexte monitorovania AI a sledovania citácií je pochopenie spôsobu, akým sú dopyty reformulované, kľúčové na overenie, že AI systémy skutočne odpovedajú na pôvodnú otázku používateľa a nie na jej skreslenú interpretáciu. AmICited.com sleduje, ako AI systémy reformulujú dopyty, aby zabezpečil, že zdroje citované v AI-generovaných odpovediach sú skutočne relevantné k pôvodnej otázke používateľa, nie len k nesprávne interpretovanej reformulácii. Táto monitorovacia schopnosť je obzvlášť dôležitá, pretože reformulácia dopytu prebieha pre používateľa neviditeľne – vidí len konečnú odpoveď a citácie, bez vedomia o transformácii pôvodného dopytu. Analýzou vzorcov reformulácie dopytov môžu monitorovacie AI platformy identifikovať situácie, keď AI systémy generujú odpovede na základe reformulovaných dopytov, ktoré sa výrazne odchyľujú od úmyslu používateľa, a včas označiť možné problémy s presnosťou. Navyše pochopenie reformulácie pomáha platformám posúdiť, či AI systémy správne zvládajú nejednoznačné dopyty generovaním viacerých reformulácií a syntézou informácií naprieč nimi, alebo či robia neopodstatnené predpoklady o zámere používateľa.
Reformulácia dopytu sa stala nepostrádateľnou naprieč mnohými AI-riadenými aplikáciami a odvetviami. V zdravotníctve a medicínskom výskume reformulácia zvláda zložitosť medicínskej terminológie, kde pacienti môžu hľadať “infarkt”, zatiaľ čo odborná literatúra používa “myokardiálny infarkt” – reformulácia preklenuje túto slovnú medzeru pre získanie klinicky presných informácií. Systémy na analýzu právnych dokumentov využívajú reformuláciu na zvládanie presného, archaického jazyka právnych dokumentov a zároveň moderných vyhľadávacích výrazov, čím zabezpečujú, že právnici nájdu relevantné precedensy bez ohľadu na formuláciu dopytu. Technická podpora reformuluje používateľské dopyty tak, aby zodpovedali článkom v znalostnej databáze, pričom hovorové opisy problémov (“môj počítač je pomalý”) premieňa na technické výrazy (“degradácia výkonu systému”) pre správne návody na riešenie. Optimalizácia vyhľadávania v e-commerce využíva reformuláciu dopytov na zvládanie produktových vyhľadávaní, kde používateľ hľadá “bežecké tenisky”, ale katalóg používa “športová obuv” alebo konkrétne značky, čím zabezpečí, že zákazník nájde hľadaný produkt bez ohľadu na terminológiu. Konverzačné AI a chatboty používajú reformuláciu dopytov na udržiavanie kontextu v multiobratových konverzáciách, reformulovaním následných otázok so začlenením implicitného kontextu z predošlých výmen. Retrieval-Augmented Generation (RAG) systémy silne závisia od reformulácie dopytu na zabezpečenie, že získané kontextové dokumenty sú skutočne relevantné pre otázku používateľa, čo priamo ovplyvňuje kvalitu generovaných odpovedí. Napríklad RAG systém odpovedajúci na “Ako optimalizovať databázové dopyty?” môže reformulovať túto otázku do viacerých variantov ako “ladenie výkonu databázových dopytov”, “techniky optimalizácie SQL” a “plány vykonávania dopytov” na získanie komplexného kontextu pred vygenerovaním detailnej odpovede.
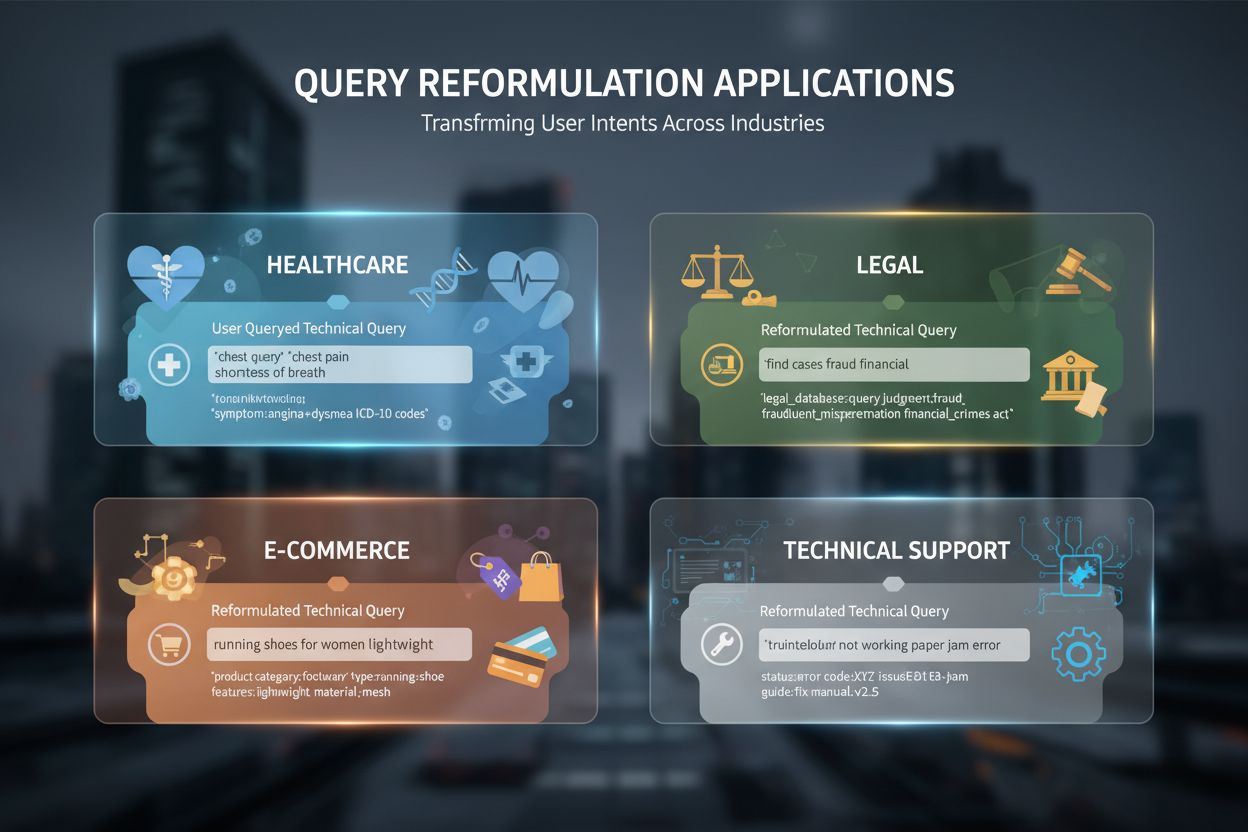
Napriek výhodám prináša reformulácia dopytu niekoľko významných výziev, ktoré musia odborníci starostlivo riešiť. Výpočtová zložitosť výrazne rastie pri generovaní viacerých reformulácií a ich zoraďovaní podľa relevantnosti – každá reformulácia vyžaduje spracovanie a systémy musia vyvážiť zisk na kvalite s požiadavkami na odozvu, najmä v reálnom čase. Kvalita trénovacích dát priamo určuje efektivitu reformulácie; systémy trénované na nekvalitných pároch dopytov alebo zaujatých datasetoch tieto zaujatosti prenášajú aj do reformulácií, čím môžu problémy skôr znásobiť ako vyriešiť. Riziko nadmernej reformulácie vzniká, ak systémy generujú príliš veľa variantov dopytu, čím strácajú zameranie na pôvodný zámer a získavajú čoraz vzdialenejšie výsledky, ktoré skôr mätú než objasňujú. Doménovo špecifická adaptácia vyžaduje značné úsilie – modely trénované na všeobecných webových dopytoch často podávajú slabý výkon v špecializovaných oblastiach ako medicína či právo bez rozsiahleho preškolenia a ladenia. Vyváženie presnosti a recall predstavuje základný kompromis: agresívne rozšírenie dopytu zvyšuje recall, ale môže znížiť presnosť získaním irelevantných výsledkov, zatiaľ čo konzervatívna reformulácia zachováva presnosť za cenu neúplnosti. Možnosť zavedenia zaujatia nastáva, ak reformulačné systémy prijímajú spoločenské predsudky prítomné v trénovacích dátach, čo môže viesť k diskriminácii vo výsledkoch vyhľadávania alebo AI odpovediach – napríklad reformulácia dopytov o “sestre” môže prevažovať ženské výsledky, ak trénovacie dáta odzrkadľujú historické rodové stereotypy.
Reformulácia dopytu sa rýchlo vyvíja spolu s pokrokom AI a vznikom nových techník. Pokrok v reformulácii založenej na LLM umožňuje sofistikovanejšie, kontextovo uvedomelé transformácie dopytov, keďže veľké jazykové modely čoraz lepšie chápu nuansy zámeru používateľa a generujú prirodzené, sémanticky bohaté reformulácie. Integrácia multimodálnych AI rozšíri reformuláciu dopytu za text na spracovanie obrázkov, audia a videa, kde sa vizuálne dopyty reformulujú do textových popisov pre vyhľadávacie systémy. Personalizácia a učenie umožní reformulačným systémom prispôsobiť sa preferenciám, slovnej zásobe a vzorom vyhľadávania každého používateľa, čím vzniknú stále personalizovanejšie reformulácie zodpovedajúce individuálnemu štýlu komunikácie. Adaptívna reformulácia v reálnom čase umožní systémom dynamicky reformulovať dopyty na základe priebežných výsledkov vyhľadávania, čím sa vytvoria spätné väzby a ďalšie vylepšenia. Integrácia znalostných grafov umožní reformulačným systémom využiť štruktúrované znalosti o entitách a vzťahoch, čo povedie k sémanticky presnejším reformuláciám ukotveným v explicitných reprezentáciách vedomostí. Vznikajúce štandardy na hodnotenie a benchmarking reformulácie dopytu uľahčia porovnávanie systémov a podporia celoodvetvové zlepšenie kvality a konzistencie reformulácie.
Reformulácia dopytu je širší proces transformácie dopytu na zlepšenie vyhľadávania, zatiaľ čo rozšírenie dopytu je konkrétna technika v rámci reformulácie, ktorá pridáva synonymá a súvisiace výrazy. Rozšírenie dopytu sa zameriava na rozšírenie rozsahu vyhľadávania, zatiaľ čo reformulácia zahŕňa viacero techník vrátane parsovania, extrakcie entít, analýzy sentimentu a kontextuálneho obohacovania na zásadné zlepšenie kvality dopytu.
Reformulácia dopytu pomáha AI systémom lepšie pochopiť zámer používateľa tým, že objasňuje nejednoznačné výrazy, pridáva kontext a generuje viacero interpretácií pôvodného dopytu. To vedie k vyhľadaniu relevantnejších zdrojových dokumentov, čo umožňuje AI generovať presnejšie, kvalitnejšie odpovede so správnymi citáciami.
Áno, reformulácia dopytu môže slúžiť ako bezpečnostná vrstva štandardizovaním a čistením vstupov používateľa predtým, než sa dostanú do hlavného AI systému. Špecializovaný reformulačný agent môže detegovať a neutralizovať potenciálne škodlivé vstupy, filtrovať podozrivé vzory a transformovať dopyty do bezpečných, štandardizovaných formátov, ktoré znižujú zraniteľnosť voči prompt injection útokom.
V Retrieval-Augmented Generation (RAG) systémoch je reformulácia dopytu kľúčová pre zabezpečenie, že získané kontextové dokumenty sú skutočne relevantné k otázke používateľa. Reformulovaním dopytov do viacerých variantov môžu RAG systémy získať komplexnejší a rozmanitejší kontext, čo priamo zlepšuje kvalitu a presnosť generovaných odpovedí.
Implementácia zvyčajne zahŕňa výber vhodných techník pre váš prípad použitia: použite rozšírenie na základe synoným s BERT alebo Word2Vec pre sémantickú podobnosť, aplikujte transformer modely ako T5 alebo GPT na neurónovú reformuláciu, zakomponujte doménovo špecifické ontológie pre špecializované oblasti a implementujte spätné väzby na neustále zlepšovanie reformulácií na základe interakcií používateľov a metrík úspešnosti vyhľadávania.
Výpočtové náklady sa líšia podľa techniky: jednoduché rozšírenie synoným je nenáročné, zatiaľ čo transformerová reformulácia vyžaduje značné GPU zdroje. Použitie menších špecializovaných modelov na reformuláciu a väčších modelov len na generovanie finálnej odpovede môže optimalizovať náklady. Mnohé systémy využívajú cacheovanie a dávkové spracovanie na rozloženie výpočtových nákladov na viacero dopytov.
Reformulácia dopytu priamo ovplyvňuje presnosť citácií, pretože reformulovaný dopyt určuje, ktoré dokumenty sú získané a citované. Ak sa reformulácia výrazne odkloní od pôvodného zámeru používateľa, AI môže citovať zdroje relevantné k reformulovanému dopytu, nie k pôvodnej otázke. AI monitorovacie platformy ako AmICited sledujú tieto transformácie, aby zabezpečili, že citácie sú naozaj relevantné k tomu, na čo sa používateľ skutočne pýtal.
Áno, reformulácia dopytu môže zosilniť existujúce zaujatosti, ak trénovacie dáta odrážajú spoločenské predsudky. Napríklad reformulovanie určitých dopytov môže neprimerane získavať výsledky spojené s určitými demografickými skupinami. Prevencia si vyžaduje starostlivý výber dát, mechanizmy na detekciu zaujatosti, rozmanité trénovacie príklady a neustále monitorovanie výstupov reformulácie z hľadiska férovosti a reprezentatívnosti.
Reformulácia dopytu ovplyvňuje, ako AI systémy rozumejú a citujú váš obsah. AmICited sleduje tieto transformácie, aby vaša značka dostala správne pripísanie v AI-generovaných odpovediach.
Vylepšovanie dopytov je iteratívny proces optimalizácie vyhľadávacích dopytov pre lepšie výsledky v AI vyhľadávačoch. Zistite, ako funguje v ChatGPT, Perplexity...

Konverzačné dopyty sú otázky v prirodzenom jazyku kladené AI systémom ako ChatGPT a Perplexity. Zistite, ako sa líšia od vyhľadávania pomocou kľúčových slov a o...
Zistite viac o klasifikácii zámeru dopytu – ako AI systémy kategorizujú dopyty používateľov podľa zámeru (informačné, navigačné, transakčné, porovnávacie). Poch...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.