Definícia Sonar Algoritmu
Sonar Algoritmus je proprietárny systém hodnotenia na báze retrieval-augmented generation (RAG) od spoločnosti Perplexity, ktorý poháňa jej answer engine kombináciou hybridného sémantického a kľúčového vyhľadávania, neurónového prehodnocovania a generovania citácií v reálnom čase. Na rozdiel od tradičných vyhľadávačov, ktoré hodnotia stránky na zobrazenie v zozname výsledkov, Sonar hodnotí úryvky obsahu pre syntézu do jednej, zjednotenej odpovede s vnútornými citáciami na zdrojové dokumenty. Algoritmus uprednostňuje aktuálnosť obsahu, sémantickú relevantnosť a citovateľnosť, aby poskytoval ukotvené odpovede podložené zdrojmi a minimalizoval halucinácie. Sonar predstavuje zásadný posun v tom, ako AI systémy získavajú a hodnotia informácie—od autoritatívnych signálov založených na odkazoch k metrike užitočnosti zameranej na odpovede, ktorá zdôrazňuje, či obsah priamo spĺňa úmysel používateľa a môže byť čisto citovaný v syntetizovaných odpovediach. Toto rozlíšenie je kľúčové pre pochopenie, ako sa viditeľnosť v AI answer engine líši od tradičného SEO, keďže Sonar hodnotí obsah nie pre jeho schopnosť umiestniť sa v zozname, ale pre jeho schopnosť byť extrahovaný, syntetizovaný a pripísaný v AI-generovanej odpovedi.
Kontext a pozadie: Evolúcia AI-poháňaného hodnotenia
Vznik Sonar Algoritmu odráža širší posun v odvetví smerom k retrieval-augmented generation ako dominantnej architektúre pre AI answer engine. Keď Perplexity spustila svoju službu koncom roka 2022, identifikovala zásadnú medzeru v AI prostredí: zatiaľ čo ChatGPT poskytoval silné konverzačné schopnosti, chýbal mu prístup k aktuálnym informáciám a atribúcia zdrojov, čo viedlo k halucináciám a zastaraným odpovediam. Zakladajúci tím Perplexity, pôvodne pracujúci na nástroji na preklad databázových dopytov, sa úplne preorientoval na vytvorenie answer engine schopného kombinovať živé vyhľadávanie na webe so syntézou LLM. Toto strategické rozhodnutie formovalo architektúru Sonaru od začiatku—algoritmus bol navrhnutý nie na hodnotenie stránok pre ľudské prehliadanie, ale na získavanie a hodnotenie fragmentov obsahu pre strojovú syntézu a citovanie. Za uplynulé dva roky sa Sonar vyvinul na jeden z najsofistikovanejších hodnotiacich systémov v AI ekosystéme, pričom Sonar modely Perplexity obsadili priečky 1 až 4 v Search Arena Evaluation, čím výrazne prekonali konkurenčné modely od Google a OpenAI. Algoritmus teraz spracúva viac ako 400 miliónov vyhľadávacích dopytov mesačne, indexuje viac ako 200 miliárd unikátnych URL a udržiava aktuálnosť v reálnom čase prostredníctvom desaťtisícov aktualizácií indexu za sekundu. Tento rozsah a sofistikovanosť podčiarkujú význam Sonaru ako určujúcej hodnotiacej paradigmy v ére AI vyhľadávania.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Ako Sonar Algoritmus funguje: Viacfázový RAG pipeline
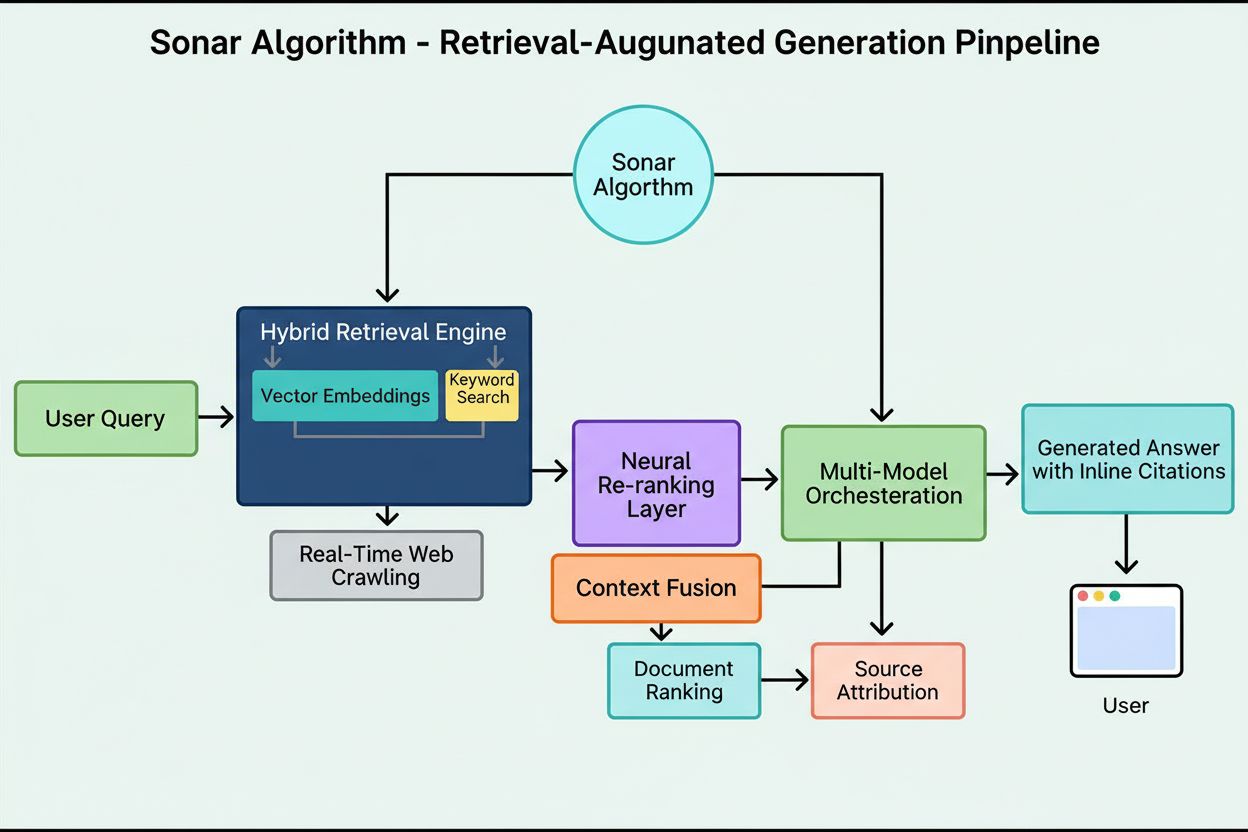
Hodnotiaci systém Sonaru funguje prostredníctvom starostlivo organizovaného päťstupňového retrieval-augmented generation pipeline, ktorý premieňa používateľské dopyty na ukotvené, citované odpovede. Prvá fáza, Analýza úmyslu dopytu, využíva LLM na prekročenie jednoduchého párovania kľúčových slov a dosiahnutie sémantického pochopenia toho, na čo sa používateľ skutočne pýta, vrátane interpretácie kontextu, nuansy a základného zámeru. Druhá fáza, Živé vyhľadávanie na webe, odosiela analyzovaný dopyt do rozsiahleho distribuovaného indexu Perplexity poháňaného Vespa AI, ktorý v reálnom čase prehľadáva web pre relevantné stránky a dokumenty. Tento vyhľadávací systém kombinuje husté vyhľadávanie (vektorové vyhľadávanie pomocou sémantických embeddingov) a riedke vyhľadávanie (lexikálne/na základe kľúčových slov), pričom zlúčené výsledky tvoria približne 50 rôznorodých kandidátnych dokumentov. Tretia fáza, Extrahovanie úryvkov a kontextualizácia, neposiela generatívnemu modelu celý text stránky; algoritmy namiesto toho extrahujú najrelevantnejšie úryvky, odseky alebo časti priamo súvisiace s dopytom, ktoré agregujú do zameraného kontextového okna. Štvrtá fáza, Generovanie syntetizovanej odpovede s citáciami, odovzdáva tento kurátorsky kontext vybranému LLM (z proprietárnej rodiny Sonar Perplexity alebo modelom tretích strán ako GPT-4 či Claude), ktorý generuje odpoveď v prirodzenom jazyku striktne na základe získaných informácií. Kľúčové je, že vnútorné citácie prepájajú každé tvrdenie so zdrojovými dokumentmi, čím sa zabezpečuje transparentnosť a možnosť overenia. Piata fáza, Konverzačné vylepšenie, udržiava konverzačný kontext v rámci viacerých otázok, umožňuje doplňujúce otázky a doladenie odpovedí prostredníctvom iteratívneho vyhľadávania na webe. Definujúcim princípom tohto pipeline je—“nemáte hovoriť nič, čo ste nezískali”—čo zaručuje, že odpovede poháňané Sonarom sú ukotvené v overiteľných zdrojoch a zásadne znižujú halucinácie v porovnaní s modelmi spoliehajúcimi sa výlučne na trénovacie dáta.
Porovnávacia tabuľka: Sonar Algoritmus vs. tradičné vyhľadávanie a konkurenčné LLM systémy hodnotenia
| Aspekt | Tradičné vyhľadávanie (Google) | Sonar Algoritmus (Perplexity) | ChatGPT hodnotenie | Gemini hodnotenie | Claude hodnotenie |
|---|
| Primárna jednotka | Rebríček odkazov | Jedna syntetizovaná odpoveď s citáciami | Konsenzuálne zmienky entít | Obsah zarovnaný na E-E-A-T | Neutrálne, faktické zdroje |
| Zameranie vyhľadávania | Kľúčové slová, odkazy, ML signály | Hybridné sémantické + kľúčové vyhľadávanie | Trénovacie dáta + prehliadanie webu | Integrácia knowledge graphu | Filtre ústavnej bezpečnosti |
| Priorita aktuálnosti | Query-deserves-freshness (QDF) | Vyhľadávanie na webe v reálnom čase, 37% nárast do 48 hodín | Nižšia priorita, závislá od trénovacích dát | Stredná, integrovaná s Google Search | Nižšia priorita, dôraz na stabilitu |
| Hodnotiace signály | Spätné odkazy, autorita domény, CTR | Aktuálnosť obsahu, sémantická relevantnosť, citovateľnosť, autoritatívne zvýhodnenia | Rozpoznávanie entít, konsenzuálne zmienky | E-E-A-T, konverzačné zarovnanie, štruktúrované dáta | Transparentnosť, overiteľné citácie, neutralita |
| Mechanizmus citovania | Úryvky URL vo výsledkoch | Vnútorné citácie s odkazmi na zdroje | Implicitné, často bez citácií | AI Overviews s atribúciou | Explicitná atribúcia zdrojov |
| Diverzita obsahu | Viacero výsledkov naprieč webmi | Výber niekoľkých zdrojov na syntézu | Syntetizované z viacerých zdrojov | Viacero zdrojov v prehľade | Vyvážené, neutrálne zdroje |
| Personalizácia | Jemná, prevažne implicitná | Explicitné focus módy (Web, Academic, Finance, Writing, Social) | Implicitná na základe konverzácie | Implicitná podľa typu dopytu | Minimálna, dôraz na konzistentnosť |
| Spracovanie PDF | Štandardné indexovanie | 22% výhoda v citovaní oproti HTML | Štandardné indexovanie | Štandardné indexovanie | Štandardné indexovanie |
| Vplyv schémy markup | FAQ schéma vo featured snippets | FAQ schéma zvyšuje citácie o 41%, skracuje čas do citácie o 6 hodín | Minimálny priamy vplyv | Stredný vplyv na knowledge graph | Minimálny priamy vplyv |
| Optimalizácia latencie | Milisekundy pre hodnotenie | Podsekundové vyhľadávanie + generovanie | Sekundy pre syntézu | Sekundy pre syntézu | Sekundy pre syntézu |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Technická architektúra: Hybridné vyhľadávanie a neurónové prehodnocovanie
Technický základ Sonar Algoritmu spočíva v hybridnom vyhľadávacom engine, ktorý kombinuje viacero vyhľadávacích stratégií na maximalizáciu recall aj presnosti. Husté vyhľadávanie (vektorové vyhľadávanie) využíva sémantické embeddingy na pochopenie koncepčného významu dopytov a vyhľadáva kontextovo podobné dokumenty aj bez presných zhôd kľúčových slov. Tento prístup využíva embeddingy založené na transformeroch, ktoré mapujú dopyty a dokumenty do vysokorozmerných vektorových priestorov, kde sa sémanticky podobný obsah zhlukuje. Riedke vyhľadávanie (lexikálne vyhľadávanie) dopĺňa husté vyhľadávanie tým, že poskytuje presnosť pre vzácne termíny, názvy produktov, interné identifikátory firiem a špecifické entity, kde je sémantická nejednoznačnosť nežiaduca. Systém využíva hodnotiace funkcie ako BM25 na presné párovanie týchto kritických termínov. Tieto dve vyhľadávacie metódy sú zlúčené a deduplikované, aby vytvorili približne 50 rôznorodých kandidátnych dokumentov, čo zabraňuje pretrénovaniu domén a zabezpečuje široké pokrytie naprieč viacerými autoritatívnymi zdrojmi. Po počiatočnom vyhľadaní neurónová prehodnocovacia vrstva Sonaru využíva pokročilé machine-learning modely (napr. DeBERTa-v3 cross-encodery) na hodnotenie kandidátov pomocou bohatej množiny znakov vrátane lexikálnych skóre relevantnosti, vektorovej podobnosti, autority dokumentu, signálov aktuálnosti, metrík zapojenia používateľov a metadát. Táto viacfázová architektúra hodnotenia umožňuje Sonaru progresívne spresňovať výsledky v rámci prísnych latencií, čím zaisťuje, že konečný rebríček predstavuje najkvalitnejšie a najrelevantnejšie zdroje pre syntézu. Celá infraštruktúra vyhľadávania je postavená na Vespa AI, distribuovanej vyhľadávacej platforme schopnej zvládnuť indexovanie v internetovom meradle (200+ miliárd URL), aktualizácie v reálnom čase (desaťtisíce za sekundu) a detailné porozumenie obsahu pomocou chunkingu dokumentov. Táto architektonická voľba umožňuje relatívne malému inžinierskemu tímu Perplexity sústrediť sa na diferencované komponenty—RAG orchestráciu, doladenie Sonar modelov a optimalizáciu inferencie—namiesto toho, aby od nuly vytvárali distribuované vyhľadávanie.
Aktuálnosť obsahu ako dominantný hodnotiaci faktor
Aktuálnosť obsahu patrí medzi najsilnejšie hodnotiace signály Sonaru, pričom empirický výskum ukazuje, že nedávno aktualizované stránky dosahujú dramaticky vyššie miery citácií. V kontrolovaných A/B testoch počas 24 týždňov na 120 URL boli články aktualizované za posledných 48 hodín citované o 37% častejšie ako identický obsah so starším dátumom. Tento náskok pretrvával približne 14% po dvoch týždňoch, čo naznačuje, že aktuálnosť poskytuje trvalý, no postupne slabnúci boost. Mechanizmus tejto preferencie je zakotvený vo filozofii návrhu Sonaru: algoritmus považuje zastaraný obsah za vyššie riziko halucinácií, predpokladajúc, že staré informácie mohli byť prekonané novšími udalosťami. Infraštruktúra Perplexity spracúva desaťtisíce požiadaviek na aktualizáciu indexu za sekundu, čím umožňuje signály aktuálnosti v reálnom čase. ML model predpovedá, či URL vyžaduje reindexáciu a plánuje aktualizácie podľa dôležitosti stránky a historickej frekvencie aktualizácií, aby bol hodnotný obsah obnovovaný agresívnejšie. Aj drobné kozmetické úpravy obnovujú časovač aktuálnosti, ak CMS prepíše časovú pečiatku. Pre vydavateľov to znamená strategickú nevyhnutnosť: buď prijať redakčný rytmus s týždennými alebo dennými aktualizáciami, alebo sledovať, ako evergreen obsah postupne stráca viditeľnosť. Dôsledky sú zásadné—v ére Sonaru je rýchlosť obsahu nie márnym ukazovateľom, ale mechanizmom prežitia. Značky, ktoré automatizujú týždenné mikroaktualizácie, pripájajú živé changelogy alebo udržiavajú kontinuálne workflow optimalizácie obsahu, získajú neúmerný podiel citácií oproti konkurentom spoliehajúcim sa na statické, zriedkavo aktualizované stránky.
Sémantická relevantnosť a answer-first štruktúra obsahu
Sonar uprednostňuje sémantickú relevantnosť pred hustotou kľúčových slov, pričom zásadne oceňuje obsah, ktorý priamo odpovedá na používateľské otázky v prirodzenom, konverzačnom jazyku. Vyhľadávací systém algoritmu používa husté vektorové embeddingy na párovanie dopytov s obsahom na koncepčnej úrovni, čo znamená, že stránky využívajúce synonymá, príbuznú terminológiu alebo kontextovo bohatý jazyk môžu prekonať stránky prepchaté kľúčovými slovami, ktoré postrádajú sémantickú hĺbku. Tento posun od kľúčových slov k významu má zásadné dôsledky pre obsahovú stratégiu. Úspešný obsah v Sonare má viacero štruktúrnych charakteristík: začína krátkym, faktickým zhrnutím pred rozpracovaním detailov, používa deskriptívne H2/H3 nadpisy a krátke odseky pre jednoduchú extrakciu pasáží, obsahuje jasné citácie a odkazy na primárne zdroje a udržiava viditeľné časové pečiatky a poznámky o verzii na signalizáciu aktuálnosti. Každý odsek je optimalizovaný ako samostatná sémantická jednotka pre zrozumiteľnosť na úrovni copy-paste a porozumenie LLM. Tabuľky, odrážky a označené grafy sú obzvlášť cenné, pretože prezentujú informácie v štruktúrovanej, ľahko citovateľnej podobe. Algoritmus tiež oceňuje originálne analýzy a unikátne dáta pred jednoduchou agregáciou, keďže syntetizačný engine Sonaru vyhľadáva zdroje, ktoré prinášajú nové pohľady, primárne dokumenty alebo vlastné poznatky, ktoré ich odlišujú od generických prehľadov. Tento dôraz na sémantickú bohatosť a answer-first štruktúru predstavuje zásadný odklon od tradičného SEO, kde dominovala hustota kľúčových slov a autorita odkazov. V ére Sonaru musí byť obsah navrhnutý pre strojové získavanie a syntézu, nie pre ľudské prehliadanie.
Hosting PDF ako strategická výhoda
Verejne dostupné PDF súbory predstavujú významnú, často prehliadanú výhodu v hodnotiacom systéme Sonaru, pričom empirické testy ukazujú, že PDF verzie obsahu prekonávajú HTML ekvivalenty približne o 22% v miere citácií. Táto výhoda vyplýva z toho, že crawler Sonaru pristupuje k PDF priaznivejšie ako k HTML stránkam. PDF neobsahujú cookie lišty, požiadavky na vykresľovanie JavaScriptu, autentifikáciu cez paywall ani iné HTML komplikácie, ktoré môžu zakryť alebo spomaliť prístup k obsahu. Crawler Sonaru dokáže PDF čítať čisto a predvídateľne, extrahovať text bez nejednoznačností v parsovaní, ktoré trápia komplexné HTML štruktúry. Vydavatelia môžu túto výhodu strategicky využiť hostovaním PDF v verejne prístupných adresároch, použitím sémantických názvov súborov a označením PDF ako kanonický pomocou <link rel="alternate" type="application/pdf"> tagov v HTML hlavičke. Takto vzniká to, čo výskumníci nazývajú “LLM honey-trap”—aktívum s vysokou viditeľnosťou, ktoré trackovacie skripty konkurencie nemôžu ľahko detegovať ani monitorovať. Pre B2B spoločnosti, SaaS dodávateľov a výskumné organizácie je táto stratégia mimoriadne silná: publikovanie whitepaperov, výskumných správ, prípadových štúdií a technickej dokumentácie vo forme PDF môže dramaticky zvýšiť mieru citácií v Sonare. Kľúčové je vnímať PDF nie ako vedľajší súbor na stiahnutie, ale ako kanonickú kópiu, ktorá si zaslúži rovnakú alebo väčšiu optimalizačnú snahu ako HTML verzia. Tento prístup sa osvedčil najmä pri enterprise obsahu, kde PDF často obsahujú štruktúrovanejšie a autoritatívnejšie informácie než webstránky.
FAQ schema markup a optimalizácia štruktúrovaných dát
JSON-LD FAQ schema markup výrazne zvyšuje mieru citácií v Sonare, pričom stránky s tromi a viac FAQ blokmi získavajú citácie o 41% častejšie ako kontrolné stránky bez schémy. Tento dramatický nárast odráža preferenciu Sonaru pre štruktúrovaný, chunk-based obsah, ktorý ladí s jeho logikou získavania a syntézy. FAQ schéma poskytuje oddelené, samostatné Q&A jednotky, ktoré algoritmus dokáže ľahko extrahovať, hodnotiť a citovať ako atómové sémantické bloky. Na rozdiel od tradičného SEO, kde bola FAQ schéma len „nice-to-have“, Sonar považuje štruktúrovanú Q&A markup za kľúčový hodnotiaci pákový efekt. Navyše Sonar často cituje FAQ otázky ako anchor text, čím sa znižuje riziko kontextového posunu, ktorý vzniká, keď LLM sumarizuje náhodné klauzuly v strede odseku. Schéma tiež urýchľuje čas do prvej citácie približne o šesť hodín, čo naznačuje, že parser Sonaru uprednostňuje štruktúrované Q&A bloky už na začiatku svojho hodnotiaceho procesu. Pre vydavateľov je optimalizačná stratégia priamočiara: vložte tri až päť cielene zameraných FAQ blokov pod hlavnú časť stránky, použite konverzačné frázy, ktoré zodpovedajú reálnym otázkam používateľov. Ot