Štruktúrované dáta
Štruktúrované dáta sú štandardizované označenie, ktoré pomáha vyhľadávačom pochopiť obsah webových stránok. Zistite, ako JSON-LD, schema.org a microdata zlepšuj...
9 min čítania

Schéma značkovania špeciálne navrhnutá na to, aby AI systémy dokázali presne pochopiť a citovať obsah. Štruktúrované dáta využívajú štandardizované formáty ako JSON-LD na poskytnutie explicitného kontextu o obsahu stránky, čím umožňujú veľkým jazykovým modelom spoľahlivejšie analyzovať informácie a s väčšou istotou citovať zdroje.
Schéma značkovania špeciálne navrhnutá na to, aby AI systémy dokázali presne pochopiť a citovať obsah. Štruktúrované dáta využívajú štandardizované formáty ako JSON-LD na poskytnutie explicitného kontextu o obsahu stránky, čím umožňujú veľkým jazykovým modelom spoľahlivejšie analyzovať informácie a s väčšou istotou citovať zdroje.
Štruktúrované dáta pre AI označujú organizované, strojovo čitateľné informácie formátované podľa štandardizovaných schém, ktoré umožňujú systémom umelej inteligencie presne pochopiť, interpretovať a využiť obsah. Na rozdiel od neštruktúrovaného textu, ktorý si vyžaduje zložitú analýzu prirodzeného jazyka na pochopenie významu, štruktúrované dáta poskytujú explicitný kontext o tom, čo informácia predstavuje. Táto jasnosť je zásadná, pretože AI systémy—najmä veľké jazykové modely a vyhľadávače—spracúvajú denne miliardy dátových bodov. Keď je obsah štruktúrovaný pomocou štandardov ako schema.org, JSON-LD alebo microdata, AI dokáže okamžite rozpoznať entity, vzťahy a atribúty bez nejasností. Tento štruktúrovaný prístup prináša o 300 % vyššiu presnosť v porozumení AI v porovnaní s neštruktúrovanými alternatívami. Pre organizácie, ktoré chcú byť viditeľné v AI Overviews a iných AI-generovaných výsledkoch, sa štruktúrované dáta stali nevyhnutnou infraštruktúrou. Premieňajú surový obsah na inteligenciu, ktorú AI systémy môžu s istotou citovať, odkazovať a začleňovať do svojich odpovedí, čo zásadne mení spôsob, akým je digitálny obsah objavovaný v svete riadenom AI.

AI systémy spracúvajú štruktúrované dáta pomocou sofistikovaného pipeline, ktorý premieňa označený obsah na využiteľnú inteligenciu. Keď AI narazí na správne naformátované štruktúrované dáta, dokáže okamžite extrahovať kľúčové informácie bez výpočtovej náročnosti potrebnej na interpretáciu prirodzeného jazyka. Technický mechanizmus zahŕňa tieto základné kroky:
Tento proces umožňuje AI dosiahnuť o 30 % vyššiu viditeľnosť v AI Overviews pre správne štruktúrovaný obsah. Štruktúrovaný prístup znižuje riziko halucinácií tým, že AI odpovede zakotvuje v explicitných, overiteľných dátach namiesto pravdepodobnostnej generácie textu. Organizácie, ktoré zavádzajú komplexné stratégie štruktúrovaných dát, zaznamenávajú merateľné zlepšenia v tom, ako AI systémy objavujú, chápu a propagujú ich obsah naprieč viacerými platformami a aplikáciami.
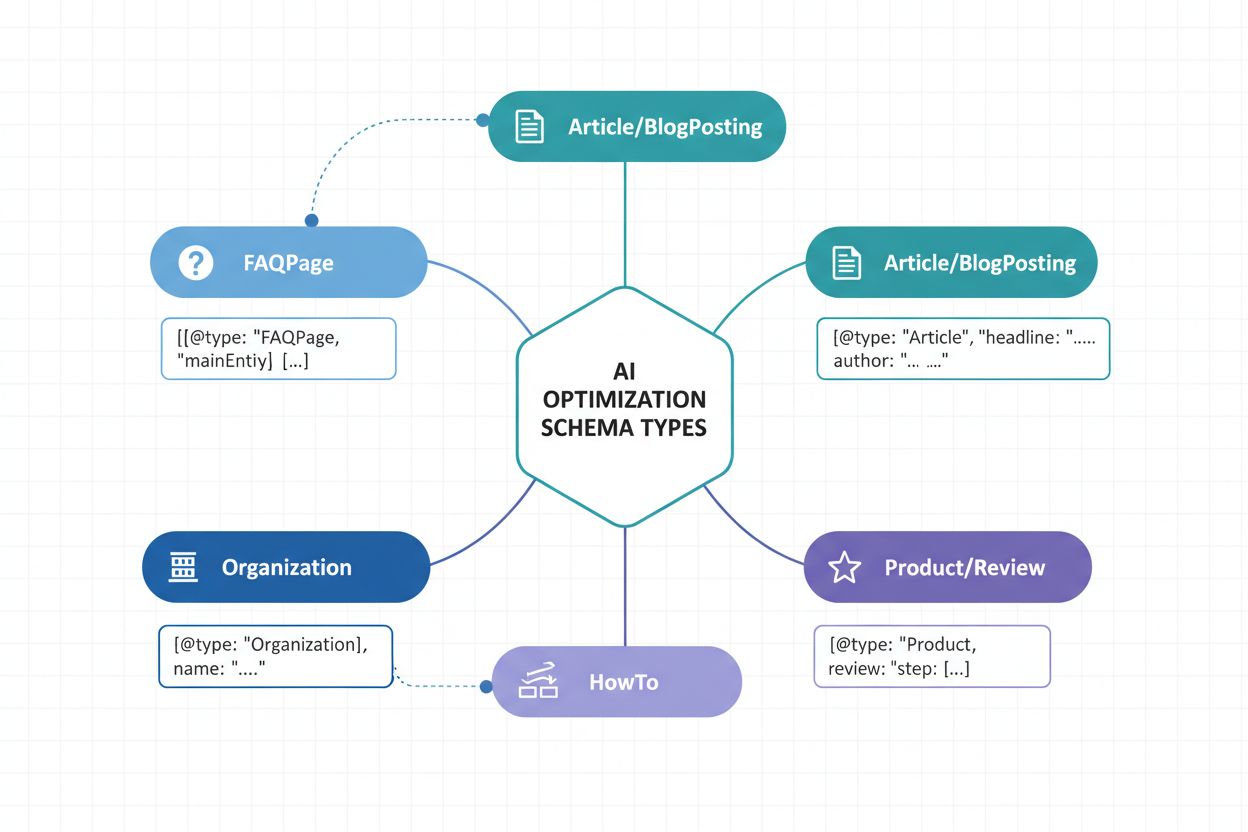
Implementácia správnych typov schém je základom stratégie zvýšenia viditeľnosti v AI. Rôzne typy obsahu vyžadujú špecifické štruktúrované značkovanie na komunikáciu ich charakteru a hodnoty pre AI systémy. Tu sú základné typy schém na maximalizáciu rozpoznania AI:
Article Schema – Označuje spravodajské články, blogové príspevky a dlhé texty s nadpisom, autorom, dátumom publikácie a telom textu. Kritické pre AI pri identifikácii autoritatívnych zdrojov a stanovení dôveryhodnosti publikácie.
Organization Schema – Definuje identitu spoločnosti vrátane názvu, loga, kontaktných informácií a sociálnych profilov. Umožňuje AI správne rozpoznať a priradiť obsah organizácie v rôznych kontextoch.
Product Schema – Štruktúruje informácie o produkte vrátane názvu, popisu, ceny, dostupnosti a recenzií. Nevyhnutné pre viditeľnosť v AI nákupných asistentoch a systémoch odporúčaní produktov.
LocalBusiness Schema – Označuje polohu firmy, otváracie hodiny, kontaktné údaje a služby. Kľúčové pre lokálne AI dopyty a lokalizované AI Overviews, ktoré čoraz viac dominujú výsledkom vyhľadávania.
BreadcrumbList Schema – Definuje hierarchiu navigácie na stránke, pomáha AI pochopiť štruktúru obsahu a vzťahy medzi stránkami v rámci vašej informačnej architektúry.
FAQPage Schema – Štruktúruje často kladené otázky s odpoveďami, čím umožňuje AI priamo extrahovať a citovať konkrétny Q&A obsah v odpovediach.
NewsArticle a BlogPosting Schemas – Špecializované typy článkov, ktoré signalizujú kategóriu obsahu AI systémom a zlepšujú presnosť kategorizácie a relevancie.
Event Schema – Označuje detaily udalostí vrátane dátumu, miesta, popisu a registračných informácií, nevyhnutné pre AI objavovanie udalostí a integráciu kalendára.
V súčasnosti používa schéma.org značkovanie 45 miliónov domén, čo predstavuje 12,4 % všetkých domén globálne. Organizácie, ktoré implementujú viaceré typy schém súčasne, zaznamenávajú kumulatívne výhody viditeľnosti, keďže AI systémy získavajú bohatší kontext ich obsahového ekosystému.
Úspešná implementácia štruktúrovaných dát si vyžaduje strategické plánovanie a technickú presnosť. Organizácie by mali nasledovať tieto osvedčené postupy, aby maximalizovali AI viditeľnosť a zabezpečili presnosť údajov:
Tu je praktický príklad JSON-LD pre článok:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Štruktúrované dáta pre AI: Strategický sprievodca implementáciou",
"author": {
"@type": "Person",
"name": "Autor obsahu"
},
"datePublished": "2024-01-15",
"image": "https://example.com/image.jpg",
"articleBody": "Celý text článku tu...",
"publisher": {
"@type": "Organization",
"name": "Vaša organizácia",
"logo": "https://example.com/logo.png"
}
}
Správna implementácia prináša o 35 % vyššie CTR vďaka rozšíreným výsledkom v tradičnom vyhľadávaní a ďalšie výhody s rastúcou dôležitosťou AI Overviews. Organizácie, ktoré monitorujú výkon štruktúrovaných dát pomocou riešení ako AmICited.com, získavajú konkurenčnú výhodu identifikovaním typov obsahu a implementácií schém, ktoré prinášajú najvyššiu AI viditeľnosť.
Oba prístupy—štruktúrované dáta aj llms.txt—slúžia na zlepšenie objaviteľnosti v AI, ale fungujú na odlišných princípoch. Štruktúrované dáta využívajú štandardizované schémy (schema.org, JSON-LD) vložené do HTML na označovanie konkrétnych prvkov obsahu explicitným sémantickým významom. Tento prístup je priamo integrovaný do webstránok, vďaka čomu sú informácie okamžite dostupné vyhľadávačom aj AI systémom počas crawl-ovania obsahu. Štruktúrované dáta umožňujú detailné značkovanie jednotlivých článkov, produktov, udalostí a organizácií, čo AI umožňuje chápať presné vzťahy a atribúty.
llms.txt je naopak textový súbor v koreňovom adresári webu, ktorý obsahuje inštrukcie a smernice pre veľké jazykové modely. Funguje ako manifest, ktorý komunikuje preferencie ohľadom interakcie AI systémov s vaším obsahom a citovania. llms.txt poskytuje všeobecné usmernenia o právach na používanie obsahu a preferenciách atribúcie, ale chýba mu sémantická presnosť štruktúrovaných dát. Štruktúrované dáta odpovedajú na otázku „čo je tento obsah?“ explicitnými strojovo čitateľnými odpoveďami, zatiaľ čo llms.txt odpovedá „ako by ste mali tento obsah používať?“ ako usmernenie.
Najefektívnejšia stratégia kombinuje oba prístupy: štruktúrované dáta zabezpečujú, že AI systémy správne pochopia a vedia citovať váš obsah, zatiaľ čo llms.txt stanovuje jasné pravidlá používania a požiadavky na atribúciu. Organizácie využívajúce oba prístupy majú o 36 % vyššiu pravdepodobnosť objavenia sa v AI-generovaných sumároch v porovnaní s tými, ktoré nepoužívajú ani jeden z nich. Štruktúrované dáta poskytujú základ pre porozumenie AI, llms.txt zase rámec pre správnu atribúciu a dodržiavanie pravidiel.
Meranie efektivity štruktúrovaných dát si vyžaduje sledovanie špecifických metrík, ktoré ukazujú, ako AI systémy objavujú, chápu a citujú váš obsah. Organizácie by mali sledovať tieto základné ukazovatele výkonnosti:
AmICited.com poskytuje špecializované monitorovanie výkonu AI citácií, čo umožňuje organizáciám sledovať, ako sa ich investície do štruktúrovaných dát premietajú do reálnej AI viditeľnosti a atribúcie. Platforma odhaľuje, ktorý obsah získava AI citácie, ktoré dopyty ich spúšťajú a ako vaša frekvencia citácií porovnáva s konkurenciou. Tento prístup založený na dátach premieňa implementáciu štruktúrovaných dát z teoreticky najlepšej praxe na merateľný biznisový dopad.
Organizácie s komplexnými stratégiami štruktúrovaných dát hlásia, že 93 % dopytov AI zodpovie bez kliknutí, čím sa viditeľnosť citácií stáva čoraz kritickejšou pre získavanie návštevnosti. Meranie výkonu citácií zabezpečuje, že vaše investície do štruktúrovaných dát prinášajú kvantifikovateľné výnosy v podobe zlepšenej AI objaviteľnosti a atribúcie značky.
Úspešná implementácia štruktúrovaných dát postupuje fázovito, čím buduje kapacitu postupne a prináša merateľné výsledky v každej fáze. Organizácie by mali štruktúrovať svoj implementačný harmonogram nasledovne:
Fáza 1: Základy (1–2. mesiac)
Fáza 2: Rozšírenie (3–4. mesiac)
Fáza 3: Optimalizácia (5–6. mesiac)
Fáza 4: Strategická integrácia (7+ mesiacov)
Táto časová os umožňuje organizáciám dosiahnuť významné zlepšenie AI viditeľnosti už do 2–3 mesiacov a budovať smerom ku komplexnej, podnikovej infraštruktúre štruktúrovaných dát. Skorí osvojitelia tejto cesty získavajú konkurenčnú výhodu s rastúcou dôležitosťou AI Overviews ako hlavného kanála objavovania.
Štruktúrované dáta sa vyvinuli z voliteľného SEO vylepšenia na nevyhnutnú strategickú infraštruktúru v digitálnom prostredí poháňanom AI. Ako AI systémy čoraz viac sprostredkúvajú objavovanie informácií, organizácie bez komplexného štruktúrovaného značkovania čelia systémovým nevýhodám v oblasti viditeľnosti. Tento posun odráža zásadné zmeny v toku informácií: tradičné vyhľadávanie vyžadovalo, aby používatelia klikli na stránky, ale AI Overviews odpovedajú priamo, čím sa viditeľnosť citácií stáva novým konkurenčným bojiskom.
Organizácie, ktoré implementujú štruktúrované dáta strategicky, sa pripravujú na dlhodobý úspech naprieč viacerými AI platformami a novými kanálmi objavovania. Investície do tejto infraštruktúry prinášajú dividendy aj mimo okamžitej AI viditeľnosti—štruktúrované dáta zlepšujú interné riadenie obsahu, umožňujú lepšiu personalizáciu, podporujú optimalizáciu pre hlasové vyhľadávanie a vytvárajú dátové aktíva cenné pre budúce AI aplikácie. Skorí osvojitelia komplexných základov štruktúrovaných dát získavajú kumulatívne výhody s rastúcou prioritizáciou dobre označeného obsahu v AI systémoch.
Konkurenčná výhoda včasnej implementácie je neprekonateľná. Ako čoraz viac organizácií rozpoznáva význam štruktúrovaných dát, implementácia sa stáva základnou požiadavkou na viditeľnosť. Organizácie, ktoré si robustnú infraštruktúru štruktúrovaných dát vybudujú už dnes, budú dominovať AI-generovaným výsledkom, keď tieto kanály dozrejú. Naopak, organizácie, ktoré implementáciu odkladajú, budú mať čoraz väčší problém dosiahnuť viditeľnosť, keďže AI systémy sa učia uprednostňovať komplexne označený obsah. Štruktúrované dáta nie sú len technickou implementáciou, ale zásadným strategickým záväzkom zostať objaviteľný a citovateľný v ekosystéme informácií sprostredkovaných AI.
Štruktúrované dáta priamo neovplyvňujú pozície v Google, ale výrazne zlepšujú vzhľad výsledkov vyhľadávania prostredníctvom rozšírených úryvkov, čo zvyšuje mieru preklikov až o 35 %. Pre AI systémy majú štruktúrované dáta priamy vplyv na to, či je váš obsah citovaný v AI-generovaných odpovediach.
Áno, AI systémy spracúvajú štruktúrované dáta počas tréningu aj v reálnych dopytoch. Hoci OpenAI neposkytlo verejné vyhlásenia, existujú dôkazy, že GPTBot a iné AI crawlery spracúvajú JSON-LD značkovanie. Microsoft oficiálne potvrdil, že Bingove AI systémy využívajú schéma značkovanie na lepšie pochopenie obsahu.
Odporúčaný je formát JSON-LD, pretože oddeľuje schému od HTML obsahu, čo uľahčuje implementáciu a údržbu vo veľkom meradle. Google výslovne odporúča JSON-LD a je menej náchylný na chyby ako Microdata alebo RDFa.
Rozšírené úryvky sa môžu objaviť do 1–4 týždňov po implementácii. Zlepšenie CTR je často merateľné do 2 týždňov. Pri AI citáciách očakávajte 4–8 týždňov na prvotné výsledky, pričom výhody v budovaní autority sa kumulujú počas 3–6 mesiacov.
Uprednostnite najskôr schéma značkovanie—je overené a široko podporované. llms.txt je zatiaľ vznikajúci štandard s obmedzeným prijatím AI crawlermi. Ak ste spoločnosť zameraná na vývojárov s rozsiahlymi dokumentáciami, minimálne úsilie na vytvorenie llms.txt môže byť užitočné pre budúcu pripravenosť.
Začnite so schémou Organization na domovskej stránke (s vlastnosťami sameAs), potom Article schémou na kľúčových stránkach s obsahom. Ďalej nasleduje FAQPage schéma—je najpriamejšie využiteľná pre AI extrakciu. Potom pridajte HowTo schému do návodov a SoftwareApplication schému na produktové stránky.
Iba nesprávne implementované značkovanie poškodzuje výkon. Pokyny od Googlu sú jasné: používajte relevantné typy schém zodpovedajúce viditeľnému obsahu, udržiavajte ceny a dátumy presné a neoznačujte obsah, ktorý nie je pre používateľov viditeľný. Pred publikovaním vždy validujte pomocou Google Rich Results Test.
Štruktúrované dáta poskytujú explicitný kontext, ktorý AI systémom pomáha pochopiť, čo informácie predstavujú—entity, vzťahy, atribúty. Táto jasnosť umožňuje AI s dôverou extrahovať a citovať váš obsah. LLMs ukotvené v znalostných grafoch dosahujú o 300 % vyššiu presnosť v porovnaní s modelmi spoliehajúcimi sa len na neštruktúrované dáta.
Sledujte, ako AI systémy citujú váš obsah naprieč ChatGPT, Perplexity, Google AI Overviews a ďalšími platformami. Získajte prehľad v reálnom čase o svojej AI prítomnosti.
Štruktúrované dáta sú štandardizované označenie, ktoré pomáha vyhľadávačom pochopiť obsah webových stránok. Zistite, ako JSON-LD, schema.org a microdata zlepšuj...
Zistite, ako AI crawlery spracovávajú štruktúrované dáta. Objavte, prečo spôsob implementácie JSON-LD rozhoduje o viditeľnosti vo vyhľadávaní ChatGPT, Perplexit...
Zistite, čo je JSON-LD a ako ho implementovať pre SEO. Objavte výhody štruktúrovaného označenia pre Google, ChatGPT, Perplexity a viditeľnosť vo vyhľadávaní AI....
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.