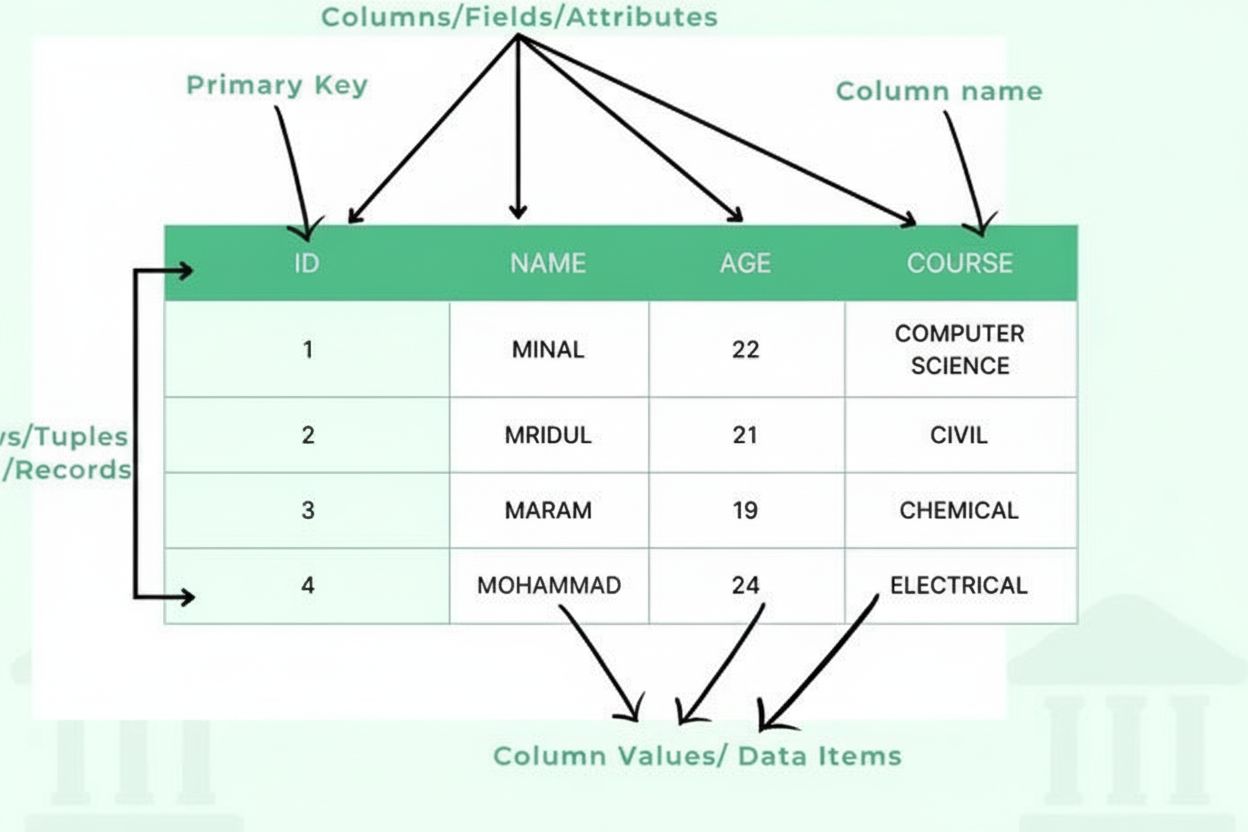
Definícia tabuľky: Organizované údaje v riadkoch a stĺpcoch
Tabuľka je základná dátová štruktúra, ktorá organizuje informácie do dvojrozmernej mriežky pozostávajúcej z vodorovných riadkov a zvislých stĺpcov. V najjednoduchšej forme tabuľka predstavuje kolekciu súvisiacich údajov usporiadaných štruktúrovaným spôsobom, kde každý prienik riadku a stĺpca obsahuje jednu údajovú položku alebo bunku. Tabuľky slúžia ako základný kameň relačných databáz, tabuľkových procesorov, dátových skladov a prakticky každého systému, ktorý vyžaduje organizované ukladanie a vyhľadávanie informácií. Sila tabuliek spočíva v ich schopnosti umožniť rýchle vizuálne prehľadávanie, logické porovnávanie údajov naprieč viacerými rozmermi a programový prístup ku konkrétnym informáciám cez štandardizované dotazovacie jazyky. Či už v podnikovej analytike, vedeckom výskume alebo v AI monitorovacích platformách, tabuľky poskytujú univerzálne zrozumiteľný formát na prezentáciu štruktúrovaných údajov, ktoré sú ľahko interpretovateľné pre ľudí aj stroje.
Historický kontext a vývoj organizácie údajov v tabuľkách
Koncept organizácie informácií do riadkov a stĺpcov predchádza moderným počítačom o stáročia. Staroveké civilizácie využívali tabuľkové formáty na zaznamenávanie inventára, finančných transakcií a astronomických pozorovaní. Formálna štruktúra tabuliek v informatike sa však objavila s vývojom teórie relačných databáz Edgara F. Codda v roku 1970, ktorá zásadne zmenila spôsob ukladania a dotazovania údajov. Relačný model stanovil, že údaje by mali byť organizované do tabuliek s jasne definovanými vzťahmi, čím zásadne ovplyvnil princípy návrhu databáz. V 80. a 90. rokoch sprístupnili aplikácie ako Lotus 1-2-3 a Microsoft Excel používanie tabuliek aj netechnickým používateľom. Dnes približne 97 % organizácií používa tabuľkové aplikácie na správu a analýzu údajov, čo dokazuje trvalý význam tabuľkovej organizácie údajov. Vývoj pokračuje modernými technológiami ako stĺpcové databázy, NoSQL systémy a data lakes, ktoré spochybňujú tradičné prístupy orientované na riadky, no stále zachovávajú základné tabuľkové štruktúry na organizáciu informácií.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Základné komponenty a štruktúra tabuliek
Tabuľka pozostáva z viacerých základných štruktúrnych komponentov, ktoré spolu vytvárajú organizovaný rámec údajov. Stĺpce (nazývané aj polia alebo atribúty) idú zvislo a reprezentujú kategórie informácií, ako napríklad „Meno zákazníka“, „E-mailová adresa“ alebo „Dátum nákupu“. Každý stĺpec má definovaný typ údajov, ktorý určuje, aké údaje môže obsahovať—celé čísla, textové reťazce, dátumy, desatinné čísla alebo zložitejšie štruktúry. Riadky (tiež záznamy alebo tupláty) idú vodorovne a predstavujú jednotlivé údaje alebo entity, pričom každý riadok obsahuje jeden kompletný záznam. Prienik riadku a stĺpca tvorí bunku alebo údajovú položku, ktorá uchováva jednu informáciu. Hlavičky stĺpcov identifikujú každý stĺpec a nachádzajú sa na vrchu tabuľky, poskytujúc kontext pre údaje nižšie. Primárne kľúče sú špeciálne stĺpce, ktoré jednoznačne identifikujú každý riadok, čím zabraňujú duplicitám. Cudzie kľúče vytvárajú vzťahy medzi tabuľkami odkazovaním na primárne kľúče v iných tabuľkách. Táto hierarchická organizácia umožňuje databázam udržiavať integritu údajov, predchádzať redundancii a podporovať zložité dotazy, ktoré vyhľadávajú informácie na základe viacerých kritérií.
Porovnanie metód organizácie tabuliek
| Aspekt | Tabuľky orientované na riadky | Tabuľky orientované na stĺpce | Hybridné prístupy |
|---|
| Spôsob ukladania | Údaje sa ukladajú a pristupujú podľa celých záznamov | Údaje sa ukladajú a pristupujú podľa jednotlivých stĺpcov | Kombinuje výhody oboch prístupov |
| Výkon dotazov | Optimalizované pre transakčné dotazy vracajúce celé záznamy | Optimalizované pre analytické dotazy na konkrétne stĺpce | Vyvážený výkon pre zmiešané pracovné zaťaženie |
| Prípadové použitia | OLTP (Online Transaction Processing), obchodné operácie | OLAP (Online Analytical Processing), dátové sklady | Analytika v reálnom čase, operačná inteligencia |
| Príklady databáz | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Efektivita kompresie | Nižšia kompresia kvôli rozmanitosti údajov | Vyššia kompresia vďaka podobnosti hodnôt v stĺpcoch | Optimalizovaná kompresia pre špecifické vzory |
| Výkon zápisu | Rýchly zápis celých záznamov | Pomalší zápis vyžadujúci aktualizáciu stĺpcov | Vyvážený výkon pri zápise |
| Škálovateľnosť | Dobrá škálovateľnosť pri objeme transakcií | Dobrá škálovateľnosť pri objeme údajov a zložitosti dotazov | Škáluje sa pre oba rozmery |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Technická implementácia a architektúra databáz
V relačných databázových systémoch (RDBMS) sú tabuľky implementované ako štruktúrované kolekcie riadkov, kde každý riadok zodpovedá vopred definovanej schéme. Schéma určuje štruktúru tabuľky, špecifikuje názvy stĺpcov, typy údajov, obmedzenia a vzťahy. Pri vkladaní údajov do tabuľky systém správy databázy kontroluje, či každá hodnota zodpovedá typu údajov stĺpca a spĺňa všetky definované obmedzenia. Napríklad stĺpec definovaný ako INTEGER odmietne textové hodnoty a stĺpec označený ako NOT NULL odmietne prázdne položky. Indexy sa vytvárajú na často dotazovaných stĺpcoch na zrýchlenie vyhľadávania údajov a fungujú ako organizované referencie, ktoré umožňujú databáze nájsť konkrétne riadky bez prehľadávania celej tabuľky. Normalizácia je princíp návrhu, ktorý organizuje tabuľky tak, aby sa minimalizovala redundancia údajov a zvýšila integrita údajov rozdelením informácií do súvisiacich tabuliek spojených kľúčmi. Moderné databázy podporujú transakcie, ktoré zabezpečujú, že viacero operácií nad tabuľkou buď všetky prebehne úspešne, alebo všetky zlyhajú, čím sa zachováva konzistentnosť aj pri zlyhaní systému. Optimalizátor dotazov v databázových enginoch analyzuje SQL dotazy a určuje najefektívnejší spôsob prístupu k údajom v tabuľke, pričom zohľadňuje dostupné indexy a štatistiky o tabuľkách.
Prezentácia a vizualizácia údajov v tabuľkách
Tabuľky slúžia ako primárny mechanizmus na prezentáciu štruktúrovaných údajov používateľom v digitálnej aj tlačenej podobe. V aplikáciách podnikovej inteligencie a analytiky tabuľky zobrazujú agregované metriky, výkonnostné ukazovatele a detailné záznamy transakcií, vďaka čomu môžu rozhodovatelia rýchlo pochopiť zložité dátové súbory. Výskum ukazuje, že 83 % obchodných profesionálov sa pri analýze údajov spolieha najmä na tabuľky, keďže umožňujú presné porovnávanie hodnôt a rozpoznať vzory. HTML tabuľky na webových stránkach využívajú sémantické značkovanie s prvkami <table>, <tr> (riadok tabuľky), <td> (údajová bunka), a <th> (hlavička tabuľky) na štruktúrovanie údajov pre vizuálne zobrazenie aj programové spracovanie. Tabuľkové aplikácie ako Microsoft Excel, Google Sheets a LibreOffice Calc rozširujú základnú funkcionalitu tabuliek o vzorce, podmienené formátovanie a kontingenčné tabuľky, ktoré umožňujú používateľom vykonávať výpočty a dynamicky reorganizovať údaje. Najlepšie praktiky vizualizácie údajov odporúčajú používať tabuľky tam, kde sú presné hodnoty dôležitejšie ako vizuálne vzory, pri porovnávaní viacerých atribútov jednotlivých záznamov alebo keď používatelia potrebujú vyhľadávať či počítať údaje. W3C Web Accessibility Initiative zdôrazňuje, že správne štruktúrované tabuľky s jasnými hlavičkami a vhodným značkovaním sú nevyhnutné pre prístupnosť údajov pre používateľov so zdravotným postihnutím, najmä pre tých, ktorí používajú čítačky obrazovky.
Tabuľky v AI monitoringu a sledovaní obsahu
V kontexte AI monitorovacích platforiem, ako je AmICited, zohrávajú tabuľky zásadnú úlohu v organizovaní a prezentovaní údajov o tom, ako sa obsah zobrazuje v rôznych AI systémoch. Monitorovacie tabuľky sledujú metriky ako frekvenciu citácií, dátumy výskytu, zdroje AI platforiem (ChatGPT, Perplexity, Google AI Overviews, Claude) a kontextové informácie o tom, ako sú domény a URL adresy referované. Tieto tabuľky umožňujú organizáciám pochopiť viditeľnosť značky v AI generovaných odpovediach a identifikovať trendy v spôsobe, akým rôzne AI systémy citujú alebo odkazujú na ich obsah. Štruktúrovaná povaha monitorovacích tabuliek umožňuje filtrovanie, triedenie a agregáciu citácií, takže je možné zodpovedať otázky ako „Ktoré naše URL sa najčastejšie objavujú v odpovediach Perplexity?“ alebo „Ako sa zmenila naša miera citácií za posledný mesiac?“. Dátové tabuľky v monitorovacích systémoch tiež umožňujú porovnávanie naprieč viacerými rozmermi—porovnávanie vzorcov citovania medzi AI platformami, analýzu rastu citácií v čase alebo identifikáciu typov obsahu s najväčším počtom AI referencií. Možnosť exportovať monitorovacie údaje z tabuliek do reportov, dashboardov a ďalších analytických nástrojov robí tabuľky nepostrádateľné pre organizácie, ktoré chcú pochopiť a optimalizovať svoju prítomnosť v AI generovanom obsahu.
Najlepšie praktiky návrhu a organizácie tabuliek
Efektívny návrh tabuľky si vyžaduje dôkladné zváženie štruktúry, pomenovávania a princípov organizácie údajov. Pomenovávanie stĺpcov by malo používať jasné, popisné identifikátory, ktoré presne vystihujú obsah údajov, bez skratiek, ktoré by mohli zmiasť používateľov alebo vývojárov. Výber typov údajov je kľúčový—správna voľba typov zabraňuje zadávaniu neplatných údajov a umožňuje správne triedenie a porovnávanie. Definícia primárneho kľúča zabezpečuje, že každý riadok možno jednoznačne identifikovať, čo je nevyhnutné pre integritu údajov a vytváranie vzťahov s inými tabuľkami. Normalizácia znižuje redundanciu údajov organizovaním informácií do súvisiacich tabuliek namiesto ukladania duplicitných údajov na viacerých miestach. Indexačná stratégia by mala vyvažovať výkon dotazov s náročnosťou údržby indexov pri zmenách údajov. Dokumentácia štruktúry tabuľky vrátane popisov stĺpcov, typov údajov, obmedzení a vzťahov je zásadná pre dlhodobú udržateľnosť. Riadenie prístupu by malo byť implementované tak, aby citlivé údaje v tabuľkách boli chránené pred neoprávneným prístupom. Optimalizácia výkonu zahŕňa monitorovanie časov vykonávania dotazov a úpravu štruktúr tabuliek, indexov alebo dotazov na zvýšenie efektivity. Zálohovanie a obnovovacie postupy musia byť nastavené na ochranu údajov v tabuľkách pred stratou alebo poškodením.
Zásadné aspekty organizácie a správy tabuliek
- Štrukturálne komponenty: Tabuľky pozostávajú zo stĺpcov (polia), riadkov (záznamy), hlavičiek, údajových položiek (buniek), typov údajov, primárnych a cudzích kľúčov, ktoré spolu vytvárajú organizované dátové štruktúry
- Integrita údajov: Obmedzenia, validačné pravidlá a kľúčové vzťahy udržiavajú presnosť údajov a zabraňujú nekonzistenciám či duplicitám
- Efektivita dotazov: Správne indexovanie, normalizácia a optimalizácia dotazov umožňujú rýchle vyhľadávanie špecifických informácií z veľkých tabuliek
- Prístupnosť: Sémantické HTML značkovanie, jasné hlavičky a správna štruktúra robia tabuľky prístupnými pre používateľov so zdravotným postihnutím a asistenčnými technológiami
- Škálovateľnosť: Dobre navrhnuté tabuľky zvládnu rastúce objemy údajov vďaka vhodnému indexovaniu, rozdeľovaniu a optimalizácii databázy
- Správa vzťahov: Cudzie kľúče vytvárajú prepojenia medzi tabuľkami, čo umožňuje zložité dotazy kombinujúce informácie z viacerých zdrojov
- Vynucovanie typov údajov: Definované typy údajov zabezpečujú, že v každom stĺpci sú len platné informácie, čím sa predchádza chybám a umožňuje správne triedenie
- Dokumentácia a údržba: Jasná dokumentácia štruktúry tabuľky a pravidelná údržba zabezpečujú dlhodobú použiteľnosť a výkon
Vývoj a budúcnosť tabuľkovej organizácie údajov
Budúcnosť tabuľkovej organizácie údajov sa vyvíja tak, aby spĺňala čoraz zložitejšie požiadavky na údaje, pričom zachováva základné princípy, ktoré robia tabuľky efektívnymi. Stĺpcové formáty ukladania ako Apache Parquet a ORC sa stávajú štandardom vo veľkých dátových prostrediach, optimalizujúc tabuľky pre analytické úlohy pri zachovaní tabuľkovej štruktúry. Polostruktúrované údaje vo formátoch JSON a XML sa čoraz častejšie ukladajú do stĺpcov tabuľky, čo umožňuje tabuľkám kombinovať štruktúrované aj flexibilné údaje. Integrácia strojového učenia umožňuje databázam automaticky optimalizovať štruktúry tabuliek a vykonávanie dotazov podľa vzorcov používania. Platformy na analýzu v reálnom čase rozširujú tabuľky o podporu streamovaných údajov a kontinuálnych aktualizácií, čím sa posúvajú za hranice tradičných dávkových operácií s tabuľkami. Cloud-native databázy navrhujú implementáciu tabuliek tak, aby využívali distribuované výpočty a umožňovali škálovanie tabuliek naprieč viacerými servermi a geografickými oblasťami. Rámce správy údajov kladú väčší dôraz na metadáta tabuliek, sledovanie pôvodu a metriky kvality na zabezpečenie spoľahlivosti údajov. Príchod AI poháňaných dátových platforiem prináša nové príležitosti pre tabuľky ako štruktúrované zdroje trénovacích dát pre modely strojového učenia, zároveň však vyvoláva otázky, ako by mali byť tabuľky navrhované pre poskytovanie kvalitných tréningových údajov. S tým, ako organizácie generujú exponenciálne viac údajov, zostávajú tabuľky základnou štruktúrou na organizáciu, dotazovanie a analýzu informácií, pričom inovácie smerujú k zlepšeniu výkonu, škálovateľnosti a integrácie s modernými dátovými technológiami.