
Hur du hanterar duplicerat innehåll för AI-sökmotorer
Lär dig hur du hanterar och förebygger duplicerat innehåll när du använder AI-verktyg. Upptäck kanoniska taggar, omdirigeringar, verktyg för upptäckt och bästa ...
11 min läsning

Lär dig hur kanoniska URL:er förhindrar problem med duplicerat innehåll i AI-söksystem. Upptäck bästa praxis för implementering av kanoniska taggar för att förbättra AI-synlighet och säkerställa korrekt attribuering av innehåll.
Stora språkmodeller och AI-söksystem använder sofistikerade klustringsalgoritmer för att identifiera och gruppera nästan identiska URL:er, och behandlar flera versioner av samma innehåll som en enda enhet för ranking och citeringsändamål. När AI-system stöter på duplicerat innehåll måste de välja vilken version som ska prioriteras—ett beslut som direkt påverkar vilken URL som får synlighet, auktoritetssignaler och användarattribuering. Det kritiska problemet uppstår när AI väljer fel version: om din kanoniska URL pekar på den föredragna sidan men AI-systemet klustrar och rankar en dubblett av lägre kvalitet istället, förlorar ditt innehåll synlighet och citeringskredit. Intent-signaler blir utspädda över dubblettversioner, vilket fragmenterar den auktoritet som borde koncentreras på en enda URL och gör att varje dubblett får svagare rankingsignaler än om all auktoritet hade enats på den kanoniska versionen.
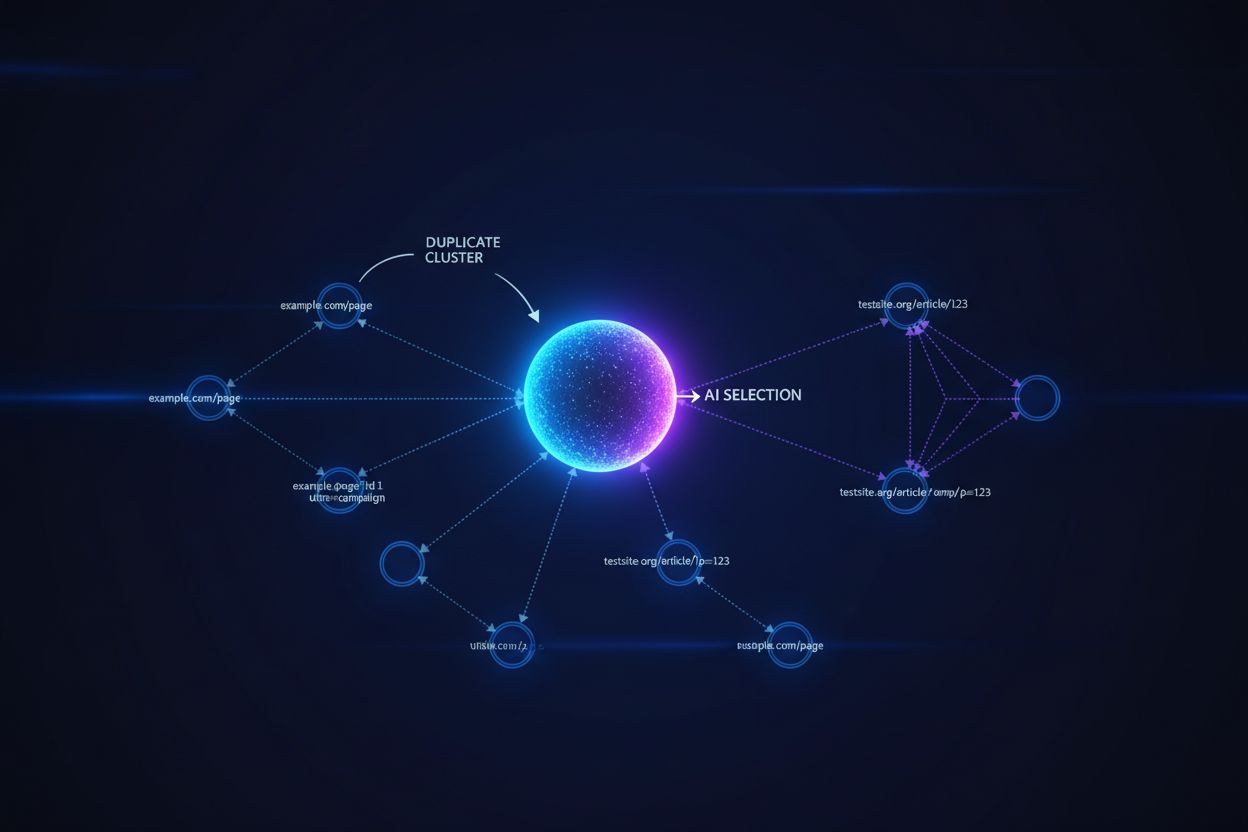
Kanoniska taggar fungerar som tydliga signaler till AI-system om vilken version av duplicerat innehåll som ska betraktas som auktoritativ, och påverkar direkt om din föredragna URL visas i AI-genererade svar och får korrekt attribuering. Utan kanoniska taggar måste AI-system själva fatta beslut om klustring baserat på innehållslikhet, länkmönster och färskhetssignaler—vilket ofta leder till att fel version väljs som kanonisk källa. När duplicerat innehåll finns utan korrekt kanonisk implementation kan AI-svar citera en syndikerad version, en cachad kopia eller en variant av lägre kvalitet istället för ditt originalinnehåll, vilket splittrar din synlighet över flera URL:er. Kanoniska URL:er säkerställer att när AI-system stöter på ditt innehåll över olika domäner, parametrar eller versioner, förstår de vilken enskild URL som ska få kredit och lyftas fram i svar.
| Scenario | Utan kanonisk | Med kanonisk |
|---|---|---|
| Påverkan på AI | AI klustrar dubbletter självständigt; kan välja fel version för ranking | AI känner igen en auktoritativ källa; konsoliderar alla signaler till kanonisk URL |
| Citeringskredit | Attribuering sprids ut över flera URL:er; svagare auktoritet per URL | Alla citeringar och auktoritet går till kanonisk URL; starkare synlighet |
| Resultat | Innehållet visas i AI-svar men fel URL får kredit; splittrad synlighet | Föredragen URL visas i AI-svar med konsoliderade auktoritetssignaler |
Kanoniska taggar och omdirigeringar har olika syften när det gäller att hantera duplicerat innehåll för AI-system: kanoniska talar om för sökmotorer och AI-system vilken version som är att föredra samtidigt som båda URL:erna är tillgängliga, medan omdirigeringar permanent skickar användare och crawlers från en URL till en annan. Omdirigeringar (301 för permanenta flyttar, 302 för temporära) är starkare signaler eftersom de konsoliderar all auktoritet till en enda URL och eliminerar dubbletten helt från webben, vilket gör dem idealiska när du permanent stänger en URL eller konsoliderar domäner. Kanoniska taggar är att föredra när du behöver behålla flera URL:er av affärsskäl—till exempel spårningsparametrar för analys, behålla äldre URL:er för bokmärken eller tillhandahålla olika versioner till olika målgrupper—samtidigt som du signalerar till AI-system vilken version som är auktoritativ. Använd omdirigeringar när du konsoliderar domäner efter en migration, tar bort inaktuella versioner eller eliminerar parametervariationer som inte har eget syfte. Använd kanoniska taggar när du måste behålla flera URL:er men vill undvika straff för duplicerat innehåll och säkerställa att AI-system förstår din föredragna version.
Viktiga skillnader mellan kanoniska taggar och omdirigeringar:
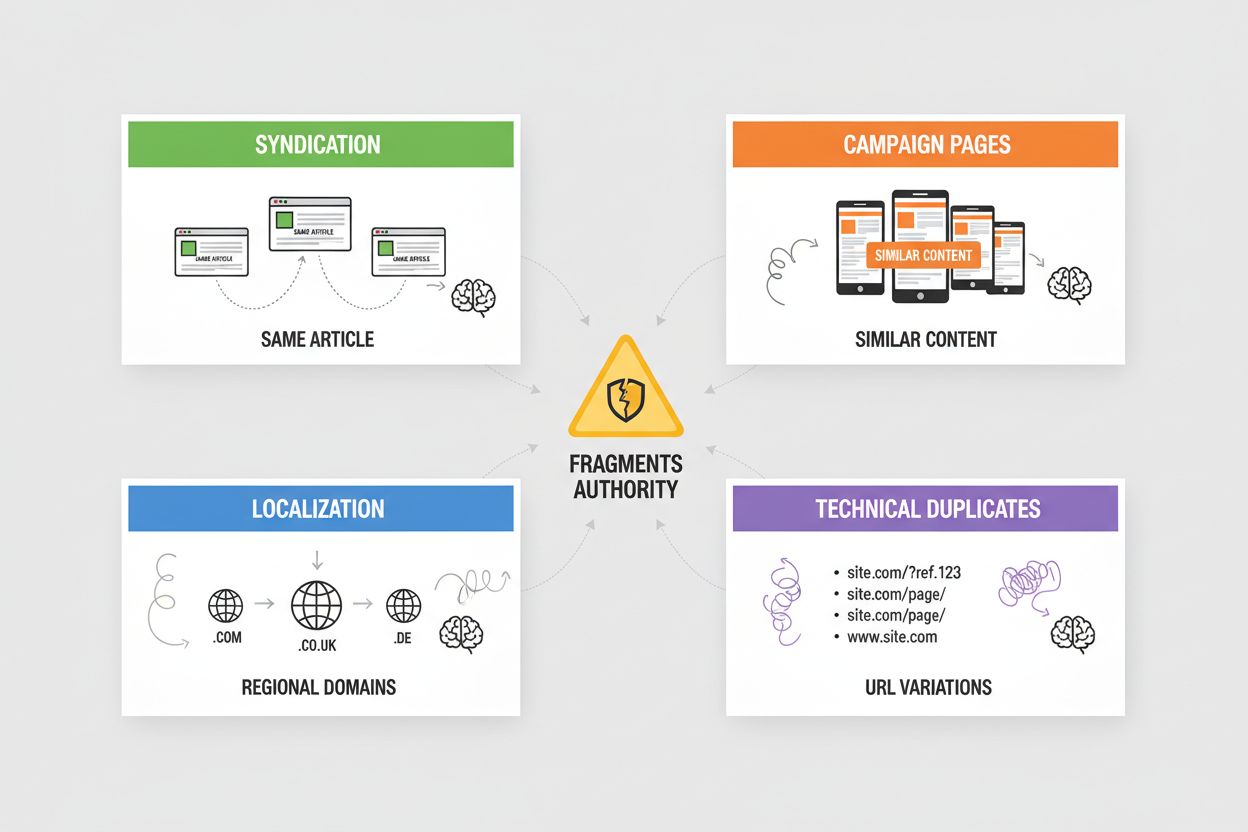
Syndikering skapar utbrett duplicerat innehåll när dina artiklar ompubliceras på partnersajter, nyhetsaggregatorer eller innehållsnätverk—AI-system måste avgöra om originalkällan eller den syndikerade versionen ska få kredit, och väljer ofta den som först crawlas. Kampanjsidor skapar dubbletter när du gör flera landningssidor med identiskt eller nästan identiskt innehåll för olika marknadsföringskanaler, UTM-parametrar eller A/B-tester, vilket gör att AI-system fragmenterar auktoriteten över varianter som borde konsolideras. Lokalisering och internationalisering ger dubbletter när du tillhandahåller liknande innehåll över regionala domäner (exempel.se, exempel.co.uk, exempel.de) eller språkversioner, vilket kräver hreflang-taggar och kanonisk implementation för att förhindra att AI-system betraktar dessa som duplicerat innehåll istället för avsiktliga variationer. Tekniska dubbletter uppstår från sessions-ID:n, spårningsparametrar, utskriftsvänliga versioner och URL-varianter (www vs. icke-www, http vs. https, snedstreck på slutet) som skapar flera URL:er till identiskt innehåll—AI-system ser dessa som dubbletter och måste avgöra vilken version som ska prioriteras. Var och en av dessa scenarier utspäder den auktoritet som borde koncentreras på din föredragna URL, minskar din synlighet i AI-genererade svar och gör att citeringskredit sprids över flera versioner.
Använd alltid absoluta URL:er i dina kanoniska taggar istället för relativa URL:er, så att AI-system och sökmotorer otvetydigt kan identifiera mål-URL oavsett var taggen används. Inkludera självrefererande kanoniska på dina föredragna sidor—även sidor utan dubbletter bör referera till sig själva som kanoniska, för att förhindra att AI-system drar slutsatser om kanonisk baserat på länkmönster eller innehållslikhet. Placera kanoniska taggar i <head>-sektionen av ditt HTML-dokument, och för icke-HTML-innehåll (PDF:er, bilder), implementera kanoniska via HTTP-rubriker så att AI-crawlers känner igen din preferens oavsett innehållstyp.
<!-- Korrekt implementering av kanonisk tagg i HTML-head -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
Inkludera kanoniska URL:er i dina XML-sitemaps för att förstärka vilka versioner som är auktoritativa, och kombinera kanoniska med hreflang-taggar när du hanterar internationellt eller lokaliserat innehåll för att förhindra att AI-system betraktar regionala variationer som dubbletter. Undvik vanliga misstag: skapa aldrig kedjor av kanoniska (A→B→C), peka aldrig kanoniska mot sidor med noindex, och använd aldrig kanoniska för att försöka manipulera ranking genom att peka mot orelaterat innehåll. Övervaka din kanoniska implementation med verktyg som Google Search Console, Bing Webmaster Tools och AmICited.com för att kontrollera att AI-systemen känner igen dina föredragna URL:er och attribuerar innehåll korrekt.
<!-- Korrekt implementation med hreflang för internationellt innehåll -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/article/canonical-urls-ai" />
<link rel="alternate" hreflang="de" href="https://example.de/artikel/canonical-urls-ai" />
Granska dina kanoniska URL:er genom att crawla hela din sajt med verktyg som Screaming Frog, SEMrush eller Ahrefs för att identifiera sidor med saknade kanoniska, trasiga kanoniska kedjor eller kanoniska som pekar mot sidor med noindex—dessa problem förhindrar att AI-system korrekt konsoliderar auktoritet. Använd Google Search Console’s täckningsrapport för att hitta sidor med duplicerat innehåll och verifiera att Google känner igen dina kanoniska preferenser, och korsverifiera med Bing Webmaster Tools för att säkerställa konsekvens i AI-söksystem. Implementera IndexNow för att omedelbart meddela sökmotorer och AI-crawlers när du lägger till, uppdaterar eller tar bort kanoniska taggar, så att dina kanoniska preferenser upptäcks snabbare än med naturlig crawling. Övervaka AI-citeringar med verktyg som AmICited.com och manuella sökningar i ChatGPT, Claude och Perplexity för att verifiera att dina föredragna URL:er får attribuering i AI-genererade svar—om dubbletter citeras istället, se över din kanoniska implementation och kontrollera att taggarna är korrekt formaterade och placerade. Granska regelbundet för nytt duplicerat innehåll som skapas genom syndikering, kampanjer eller tekniska förändringar och implementera kanoniska proaktivt för att bibehålla konsekvent AI-synlighet.
En kanonisk URL är den föredragna versionen av en sida som du vill att sökmotorer och AI-system ska känna igen som auktoritativ. Det är viktigt för AI-sök eftersom LLM:er klustrar nästan identiska URL:er och väljer en version som representant. Utan korrekt implementering av kanonisk kan AI-system citera fel version av ditt innehåll, vilket splittrar din synlighet och attribuering över flera URL:er.
AI-system använder klustringsalgoritmer för att gruppera nästan identiska URL:er till enskilda enheter och väljer sedan en version som representant för hela klustret. Detta skiljer sig från traditionella sökmotorer eftersom AI-svar kräver en enda käll-URL för attribuering. Om din kanoniska inte är korrekt implementerad kan AI välja en syndikerad version, cachad kopia eller variant av lägre kvalitet istället för din föredragna URL.
Använd kanoniska taggar när du behöver behålla flera URL:er av affärsskäl (spårningsparametrar, äldre URL:er, olika målgrupper) och samtidigt signalera preferens till AI-system. Använd omdirigeringar när du permanent tar bort en URL, konsoliderar domäner eller eliminerar parametervariationer som inte tjänar något syfte. Omdirigeringar är starkare signaler eftersom de helt konsoliderar auktoritet, medan kanoniska taggar fördelar auktoritet men signalerar preferens.
De vanligaste problemen är: syndikering (ompublicerade artiklar på partnersajter), kampanjsidor (flera landningssidor med identiskt innehåll), lokalisering (liknande innehåll på regionala domäner) och tekniska dubbletter (URL-parametrar, sessions-ID:n, snedstreck på slutet). Var och en av dessa splittrar auktoriteten över flera URL:er och minskar synligheten i AI-genererade svar.
Använd alltid absoluta URL:er (https://exempel.se/sida, inte /sida), placera kanoniska taggar i HTML-huvudet, inkludera självrefererande kanoniska på alla sidor och undvik kanoniska kedjor (A→B→C). För icke-HTML-innehåll som PDF:er, använd HTTP-rubriker. Inkludera kanoniska i din XML-sitemap och kombinera med hreflang-taggar för internationellt innehåll.
Använd Google Search Console och Bing Webmaster Tools för att verifiera kanoniskt igenkännande, övervaka AI-citeringar med AmICited.com och manuella sökningar i ChatGPT/Claude/Perplexity, samt granska din sajt med crawlverktyg som Screaming Frog eller SEMrush. Om dubbletter citeras istället för din kanoniska, se över din implementation och kontrollera att taggarna är korrekt formaterade och placerade i HTML-huvudet.
IndexNow är ett protokoll som omedelbart meddelar sökmotorer och AI-crawlers när du lägger till, uppdaterar eller tar bort kanoniska taggar, istället för att vänta på naturliga crawl-cykler. Detta påskyndar upptäckten av dina kanoniska preferenser och hjälper till att säkerställa att AI-system snabbare känner igen dina föredragna URL:er, vilket minskar tiden dubbletter visas i AI-svar.
Ja, kanoniska taggar är starka signaler men inte direkta instruktioner. AI-system kan åsidosätta din kanoniska preferens om de bedömer att en annan version är mer auktoritativ baserat på innehållskvalitet, länkmönster, färskhet eller andra signaler. Därför är korrekt implementering i kombination med starkt innehåll och auktoritetssignaler viktigt—det ökar sannolikheten att AI-systemen respekterar din kanoniska preferens.
Spåra hur AI-system som ChatGPT, Claude och Perplexity citerar ditt innehåll. Se till att dina kanoniska URL:er känns igen korrekt och att ditt varumärke får rätt attribuering i AI-genererade svar.
Lär dig hur du hanterar och förebygger duplicerat innehåll när du använder AI-verktyg. Upptäck kanoniska taggar, omdirigeringar, verktyg för upptäckt och bästa ...
Diskussion i communityt om hur AI-system hanterar duplicerat innehåll annorlunda än traditionella sökmotorer. SEO-proffs delar insikter om innehållsunicitet för...

Duplicerat innehåll är identiskt eller liknande innehåll på flera URL:er som förvirrar sökmotorer och urholkar auktoritet. Lär dig hur det påverkar SEO, AI-synl...