
AI-hallucinationer och varumärkessäkerhet: Skydda ditt rykte
Lär dig hur AI-hallucinationer hotar varumärkessäkerhet i Google AI Overviews, ChatGPT och Perplexity. Upptäck strategier för övervakning, tekniker för innehåll...
9 min läsning

Upptäck hur LLM-grundning och webbsökning gör det möjligt för AI-system att få tillgång till realtidsinformation, minska hallucinationer och ge korrekta källhänvisningar. Lär dig RAG, implementeringsstrategier och bästa praxis för företag.
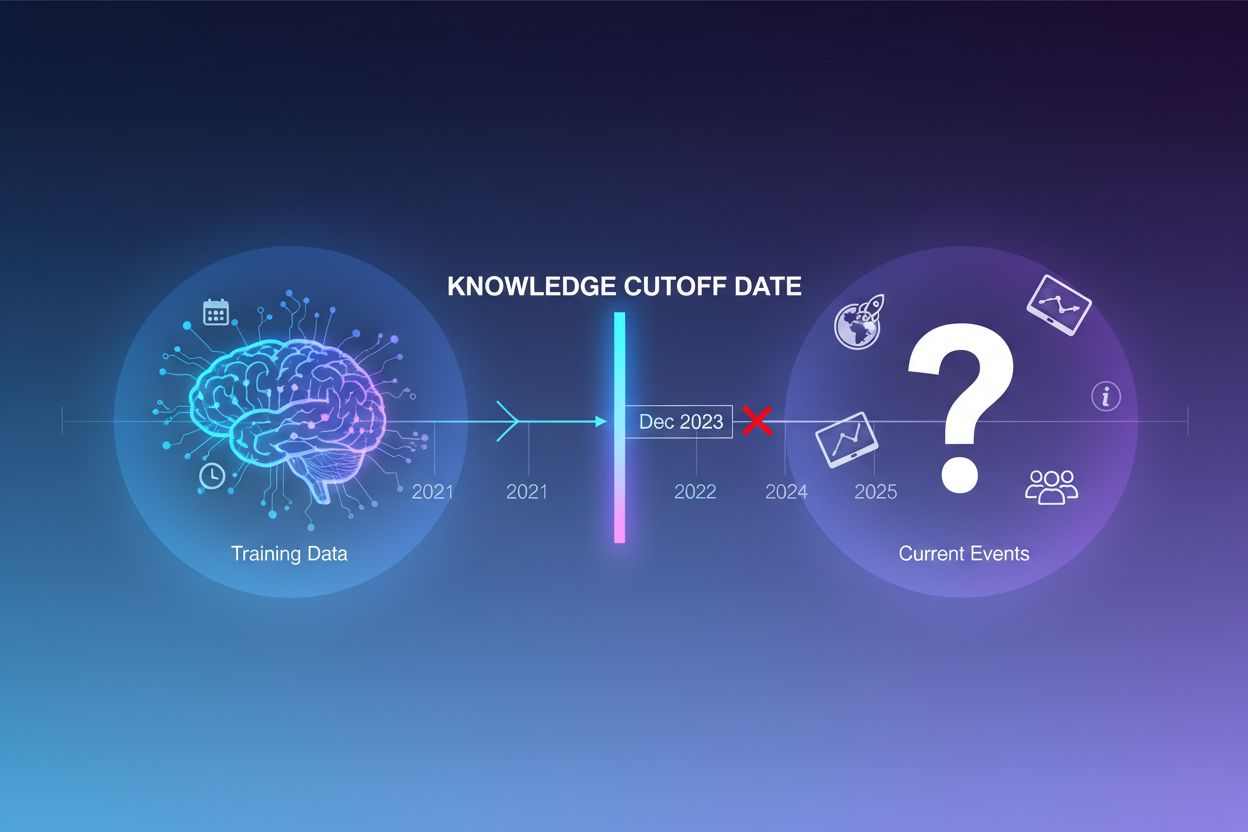
Stora språkmodeller tränas på enorma mängder textdata, men denna träningsprocess har en avgörande begränsning: den fångar bara information fram till en specifik tidpunkt, känd som kunskapsgränsdatumet. Om en LLM till exempel tränades med data fram till december 2023 har den ingen kännedom om händelser, upptäckter eller utvecklingar som inträffat därefter. När användare ställer frågor om aktuella händelser, nya produktlanseringar eller senaste nyheter kan modellen inte komma åt denna information från sin träningsdata. Istället för att erkänna osäkerhet genererar LLM:er ofta svar som låter trovärdiga men är felaktiga – ett fenomen kallat hallucination. Denna tendens blir särskilt problematisk i applikationer där noggrannhet är avgörande, som kundsupport, finansiell rådgivning eller medicinsk information, där inaktuell eller påhittad information kan få allvarliga konsekvenser.
Grundning är processen att förstärka en LLM:s förtränade kunskap med extern, kontextuell information vid inferenstid. Istället för att enbart lita på mönster från träningen kopplas modellen till verkliga datakällor – vare sig det är webbsidor, interna dokument, databaser eller API:er. Detta koncept hämtar inspiration från kognitiv psykologi, särskilt teorin om situated cognition, som menar att kunskap bäst appliceras när den är förankrad i den kontext där den används. Praktiskt innebär grundning att problemet omvandlas från “generera ett svar ur minnet” till “sammansätt ett svar utifrån tillhandahållen information”. En strikt definition från ny forskning kräver att LLM:en använder all nödvändig kunskap från den givna kontexten och håller sig inom dess ramar utan att hitta på ytterligare information.
| Aspekt | Icke-grundat svar | Grundat svar |
|---|---|---|
| Informationskälla | Endast förtränad kunskap | Förtränad kunskap + extern data |
| Noggrannhet för aktuella händelser | Låg (kunskapsgräns) | Hög (tillgång till aktuell information) |
| Risk för hallucinationer | Hög (modellen gissar) | Låg (begränsad av kontext) |
| Källhänvisningar | Begränsad eller omöjlig | Full spårbarhet till källor |
| Skalbarhet | Fast (modellstorlek) | Flexibel (kan lägga till nya källor) |
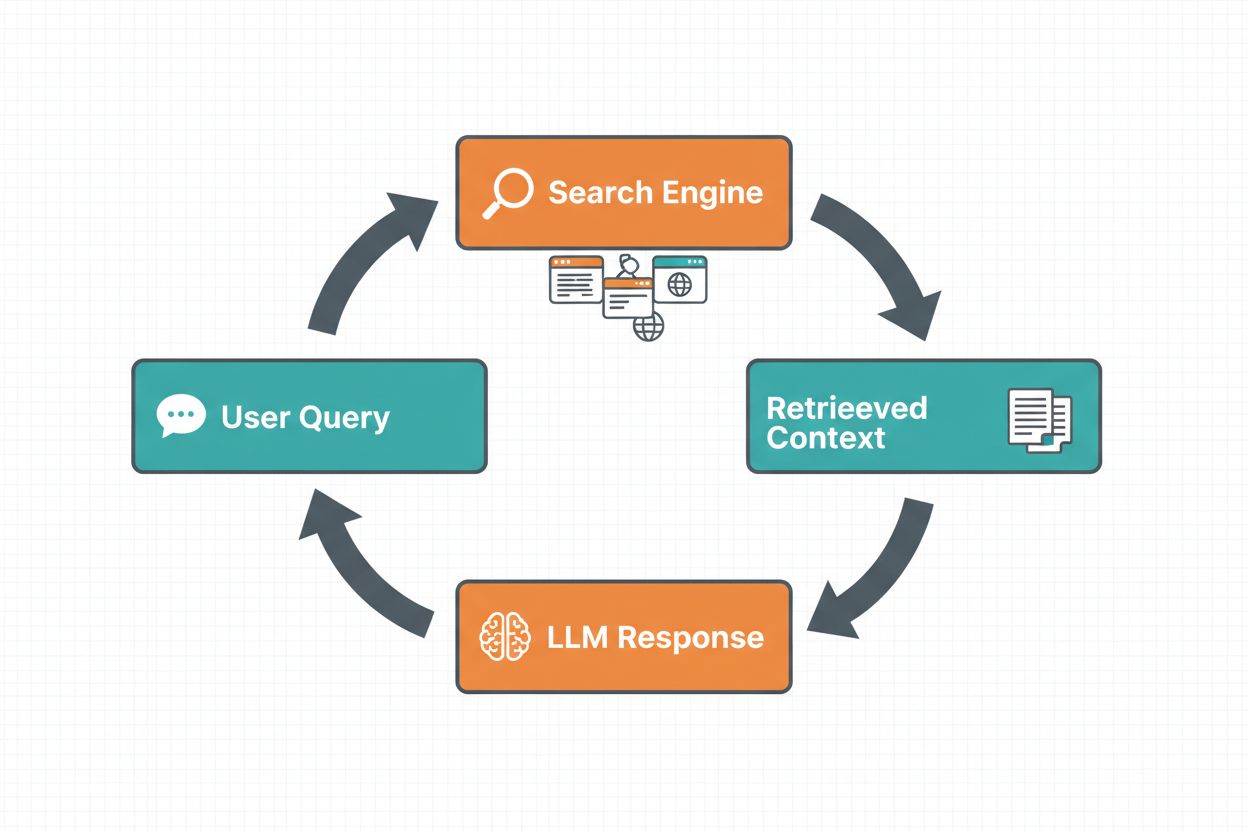
Webbsöksgrundning gör att LLM:er kan få tillgång till realtidsinformation genom att automatiskt söka på webben och införliva resultaten i modellens svarsgenerering. Arbetsflödet följer en strukturerad sekvens: först analyserar systemet användarens prompt för att avgöra om en webbsökning skulle förbättra svaret; därefter genereras en eller flera sökfrågor optimerade för att hämta relevant information; sedan utförs dessa frågor mot en sökmotor (såsom Google Search eller DuckDuckGo); därefter bearbetas sökresultaten och relevant innehåll extraheras; slutligen tillhandahålls denna kontext till LLM:en som en del av prompten, vilket gör att modellen kan generera ett grundat svar. Systemet returnerar även grundningsmetadata – strukturerad information om vilka sökfrågor som gjorts, vilka källor som hämtats och hur specifika delar av svaret stöds av dessa källor. Denna metadata är avgörande för att bygga förtroende och möjliggöra verifiering.
Arbetsflöde för webbsöksgrundning:
Retrieval Augmented Generation (RAG) har blivit den dominerande grundningstekniken, som kombinerar decennier av forskning inom informationssökning med moderna LLM-förmågor. RAG fungerar genom att först hämta relevanta dokument eller stycken från en extern kunskapskälla (ofta indexerad i en vektordatabas), och sedan tillhandahålla dessa hämtade objekt som kontext till LLM:en. Hämtningen sker vanligtvis i två steg: en retriever använder effektiva algoritmer (som BM25 eller semantisk sökning med embeddingar) för att identifiera kandidater, och en ranker använder mer sofistikerade neurala modeller för att rangordna dessa kandidater efter relevans. Den hämtade kontexten införlivas sedan i prompten så att LLM:en kan syntetisera svar förankrade i auktoritativ information. RAG ger betydande fördelar jämfört med finjustering: det är mer kostnadseffektivt (ingen ominlärning av modellen behövs), mer skalbart (lägg bara till nya dokument i kunskapsbasen) och enklare att underhålla (uppdatera information utan ominlärning). Ett RAG-prompt kan till exempel se ut så här:
Använd följande dokument för att besvara frågan.
[Fråga]
Vad är Kanadas huvudstad?
[Dokument 1]
Ottawa är Kanadas huvudstad, belägen i Ontario...
[Dokument 2]
Kanada är ett land i Nordamerika med tio provinser...
En av de mest övertygande fördelarna med webbsöksgrundning är möjligheten att införliva realtidsinformation i LLM-svar. Detta är särskilt värdefullt för applikationer som kräver aktuell data – nyhetsanalys, marknadsundersökningar, evenemangsinformation eller produkttillgänglighet. Utöver tillgång till färsk information ger grundning även källhänvisningar och källattribution, vilket är avgörande för att bygga användarförtroende och möjliggöra verifiering. När en LLM genererar ett grundat svar returneras strukturerad metadata som kartlägger specifika påståenden till deras källdokument, vilket möjliggör källhänvisningar såsom “[1] source.com” direkt i svaret. Denna förmåga är i linje med plattformars mission som AmICited.com, som övervakar hur AI-system refererar till och citerar källor över olika plattformar. Att kunna spåra vilka källor ett AI-system konsulterat och hur det attribuerat information blir allt viktigare för varumärkesövervakning, innehållsattribution och ansvarsfull AI-användning.
Hallucinationer uppstår eftersom LLM:er i grunden är designade för att förutsäga nästa token baserat på tidigare tokens och inlärda mönster, utan någon inneboende förståelse för sina kunskapsgränser. När de får frågor utanför sin träningsdata fortsätter de att generera trovärdiga texter istället för att erkänna osäkerhet. Grundning adresserar detta genom att fundamentalt ändra modellens uppgift: istället för att generera från minnet syntetiserar modellen nu utifrån tillhandahållen information. Tekniskt sett, när relevant extern kontext inkluderas i prompten, skiftas tokenfördelningen mot svar som är förankrade i den kontexten, vilket gör hallucinationer mindre sannolika. Forskning visar att grundning kan minska hallucinationsfrekvensen med 30–50 % beroende på uppgift och implementation. Till exempel, när frågan “Vem vann EM 2024?” ställs utan grundning kan en äldre modell ge fel svar; med grundning via webbsökning anger den korrekt Spanien som vinnare med specifika matchdetaljer. Detta fungerar eftersom modellens attention-mekanismer nu kan fokusera på den tillhandahållna kontexten istället för potentiellt ofullständig eller motstridig träningsdata.
Att implementera webbsöksgrundning kräver integration av flera komponenter: ett sök-API (såsom Google Search, DuckDuckGo via Serp API eller Bing Search), logik för att avgöra när grundning behövs och promptdesign för att effektivt införliva sökresultat. En praktisk implementation börjar ofta med att utvärdera om användarens fråga kräver aktuell information – detta kan göras genom att låta LLM:en själv avgöra om prompten behöver information nyare än dess kunskapsgräns. Om grundning behövs utför systemet en webbsökning, bearbetar resultaten för att extrahera relevanta utdrag och konstruerar en prompt som innehåller både den ursprungliga frågan och sökkontexten. Kostnadsaspekten är viktig: varje webbsökning innebär API-kostnader, så dynamisk grundning (söka bara när det behövs) kan kraftigt minska utgifterna. Till exempel kräver frågan “Varför är himlen blå?” sannolikt ingen webbsökning, medan “Vem är nuvarande president?” definitivt gör det. Avancerade implementationer använder mindre, snabbare modeller för att fatta grundningsbeslutet, vilket minskar svarstid och kostnader och reserverar större modeller för slutlig svarsgenerering.
Även om grundning är kraftfullt innebär det flera utmaningar som måste hanteras noggrant. Datakvalitet är avgörande – om den hämtade informationen inte faktiskt besvarar användarens fråga hjälper inte grundning och kan till och med tillföra irrelevant kontext. Datamängd innebär ett dilemma: även om mer information kan verka bättre visar forskning att LLM-prestanda ofta försämras med för mycket inmatning, ett fenomen kallat “lost in the middle”-bias där modeller har svårt att hitta och använda information placerad i mitten av långa kontexter. Tokeneffektivitet blir en fråga eftersom varje hämtad kontextdel förbrukar tokens, vilket ökar svarstid och kostnad. Principen “less is more” gäller: hämta bara de k mest relevanta resultaten (vanligtvis 3–5), arbeta med mindre textstycken snarare än hela dokument och överväg att extrahera nyckelmeningar från längre passager.
| Utmaning | Konsekvens | Lösning |
|---|---|---|
| Datakvalitet | Irrelevant kontext förvirrar modellen | Använd semantisk sökning + rankers; testa hämtkvalitet |
| Lost in Middle-bias | Modellen missar viktig info i mitten | Minimera inmatningsstorlek; placera kritisk info i början/slutet |
| Tokeneffektivitet | Hög svarstid och kostnad | Hämta färre resultat; använd mindre stycken |
| Föråldrad information | Inaktuell kontext i kunskapsbasen | Implementera uppdateringspolicyer; versionshantering |
| Svarstid | Långsamma svar p.g.a. sökning + inferens | Använd asynkrona operationer; cache:a vanliga frågor |
Att driftsätta grundningssystem i produktionsmiljöer kräver noggrann uppmärksamhet på styrning, säkerhet och operativa frågor. Datakvalitetssäkring är grundläggande – informationen du grundar på måste vara korrekt, aktuell och relevant för dina användningsfall. Åtkomstkontroll blir kritiskt när du grundar på proprietära eller känsliga dokument; du måste säkerställa att LLM:en bara kommer åt information som är lämplig för varje användare utifrån deras rättigheter. Uppdaterings- och driftshantering kräver policyer för hur ofta kunskapsbaser uppdateras och hur motstridig information mellan källor hanteras. Loggning är nödvändigt för regelefterlevnad och felsökning – du bör registrera vilka dokument som hämtats, hur de rankades och vilken kontext som gavs till modellen. Ytterligare aspekter inkluderar:
Fältet för LLM-grundning utvecklas snabbt bortom enkel textbaserad hämtning. Multimodal grundning är på frammarsch, där system kan grunda svar i bilder, videor och strukturerad data utöver text – särskilt viktigt för områden som juridisk dokumentanalys, medicinsk bildtolkning och teknisk dokumentation. Automatiserat resonemang läggs ovanpå RAG, vilket gör det möjligt för agenter att inte bara hämta information utan även syntetisera över flera källor, dra logiska slutsatser och förklara sitt resonemang. Skyddsräcken integreras med grundning för att säkerställa att modeller även med extern information bibehåller säkerhetskrav och efterlever policy. In-place-modeluppdateringar är ett annat område – istället för att helt förlita sig på extern hämtning undersöker forskare sätt att uppdatera modellvikter direkt med ny information, vilket potentiellt minskar behovet av omfattande externa kunskapsbaser. Dessa framsteg tyder på att framtidens grundningssystem kommer att vara smartare, effektivare och bättre lämpade för komplexa, flerstegiga resonemangsuppgifter med bibehållen faktakoll och spårbarhet.
Grundning förstärker en LLM med extern information vid inferenstid utan att ändra själva modellen, medan finjustering återtränar modellen på ny data. Grundning är mer kostnadseffektiv, snabbare att implementera och enklare att uppdatera med ny information. Finjustering är bättre om du behöver förändra modellens beteende i grunden eller har domänspecifika mönster att lära in.
Grundning minskar hallucinationer genom att ge LLM:en faktuell kontext att utgå från istället för att enbart lita på träningsdatan. När relevant extern information inkluderas i prompten skiftas modellens sannolikhetsfördelning för tokens mot svar som är förankrade i kontexten, vilket gör påhittad information mindre sannolik. Forskning visar att grundning kan minska hallucinationsfrekvensen med 30–50 %.
Retrieval Augmented Generation (RAG) är en grundningsteknik som hämtar relevanta dokument från en extern kunskapskälla och tillhandahåller dem som kontext till LLM:en. RAG är viktigt eftersom det är skalbart, kostnadseffektivt och gör det möjligt att uppdatera information utan att träna om modellen. Det har blivit industristandard för att bygga förankrade AI-applikationer.
Implementera webbsöksgrundning när din applikation behöver tillgång till aktuell information (nyheter, händelser, färska data), när noggrannhet och källhänvisningar är avgörande, eller när din LLM:s kunskapsgräns är en begränsning. Använd dynamisk grundning för att bara söka när det behövs och minska kostnader och svarstid för frågor som inte kräver färsk information.
Viktiga utmaningar inkluderar att säkerställa datarelevans (den hämtade informationen måste faktiskt besvara frågan), hantering av datamängd (mer är inte alltid bättre), att hantera 'lost in the middle'-bias där modeller missar information i långa kontexter, samt optimering av tokenizeffektivitet. Lösningar är att använda semantisk sökning med rankers, hämta färre men mer relevanta resultat och placera kritisk information i början eller slutet av kontexten.
Grundning är direkt relevant för AI-svarsövervakning eftersom det möjliggör källhänvisningar och källattribution. Plattformar som AmICited spårar hur AI-system refererar till källor, vilket bara är möjligt när grundning är korrekt implementerat. Detta hjälper till att säkerställa ansvarsfull AI-användning och varumärkesattribution över olika AI-plattformar.
'Lost in the middle'-bias är ett fenomen där LLM:er presterar sämre när relevant information placeras i mitten av långa kontexter jämfört med information i början eller slutet. Detta sker eftersom modeller tenderar att 'skumma igenom' när de bearbetar stora mängder text. Lösningar är att minimera inmatningsstorleken, placera kritisk information på föredragna platser och använda mindre textstycken.
För produktion, fokusera på datakvalitetssäkring, implementera åtkomstkontroller för känslig information, etablera uppdaterings- och förnyelsepolicyer, möjliggör loggning för regelefterlevnad och skapa feedbackloopar från användare för att identifiera fel. Övervaka tokenanvändning för att optimera kostnader, implementera versionshantering för kunskapsbaser och spåra modellbeteende för att upptäcka avvikelser.
AmICited spårar hur GPTs, Perplexity och Google AI Overviews citerar och refererar till ditt innehåll. Få insikter i realtid om AI-svarsövervakning och varumärkesattribution.
Lär dig hur AI-hallucinationer hotar varumärkessäkerhet i Google AI Overviews, ChatGPT och Perplexity. Upptäck strategier för övervakning, tekniker för innehåll...

Lär dig vad AI-hallucination är, varför det händer i ChatGPT, Claude och Perplexity, och hur du upptäcker falsk AI-genererad information i sökresultat.

Lär dig vad AI-hallucinationsövervakning är, varför det är avgörande för varumärkessäkerhet och hur detektionsmetoder som RAG, SelfCheckGPT och LLM-as-Judge hjä...