
Bästa sättet att formatera rubriker för AI: Komplett guide för 2025
Lär dig bästa praxis för att formatera rubriker för AI-system. Upptäck hur korrekt H1-, H2-, H3-hierarki förbättrar AI-innehållsåterhämtning, citeringar och syn...
9 min läsning
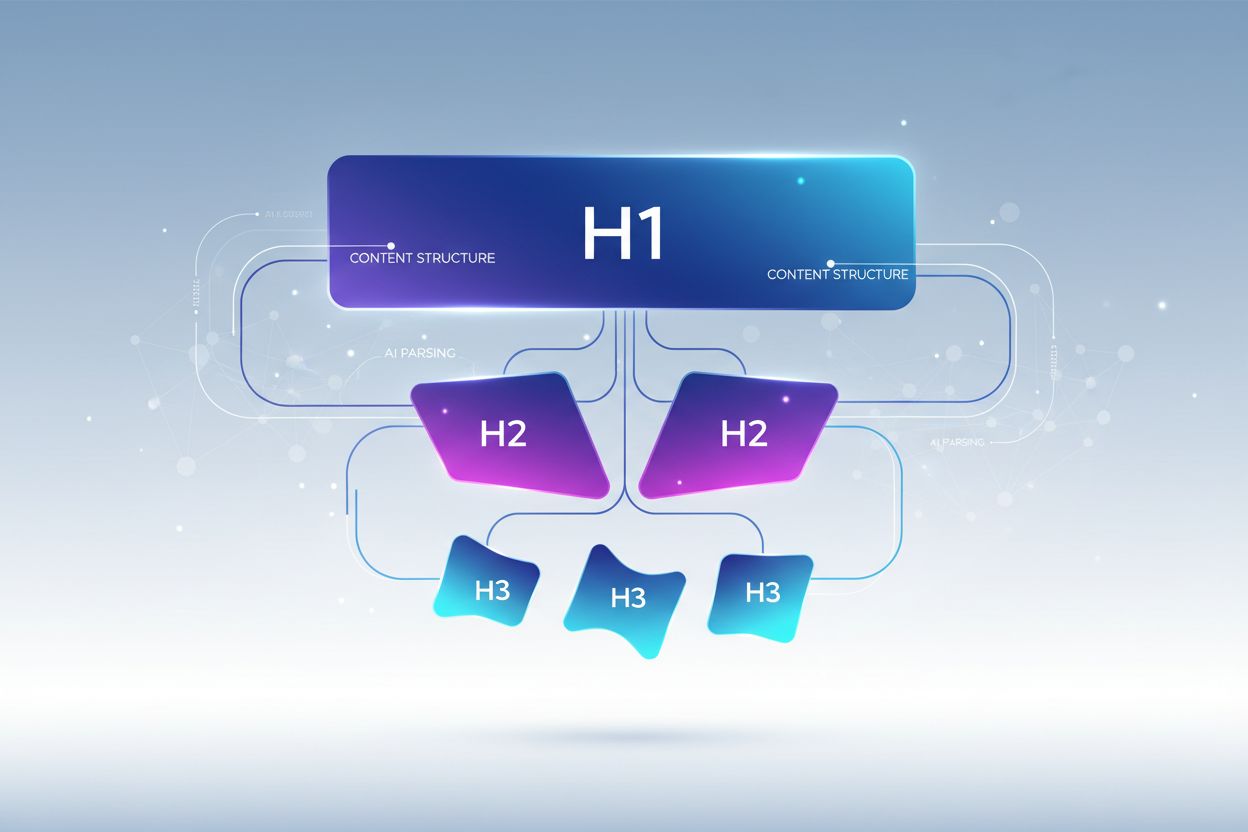
Lär dig optimera rubrikhierarki för LLM-tolkning. Bemästra H1-, H2-, H3-struktur för att förbättra AI-synlighet, citeringar och innehållsupptäckbarhet i ChatGPT, Perplexity och Google AI Overviews.
Stora språkmodeller bearbetar innehåll fundamentalt annorlunda än mänskliga läsare, och att förstå denna skillnad är avgörande för att optimera din innehållsstrategi. Medan människor skummar sidor visuellt och intuitivt uppfattar dokumentstrukturen, förlitar sig LLM:er på tokenisering och uppmärksamhetsmekanismer för att utvinna mening ur sekventiell text. När en LLM stöter på ditt innehåll delar den upp det i tokens (små textenheter) och tilldelar uppmärksamhetsvikter till olika sektioner baserat på strukturella signaler—och rubrikhierarki är en av de kraftfullaste struktursignalerna som finns. Utan tydlig rubrikorganisation har LLM:er svårt att identifiera huvudämnen, stödjande argument och kontextuella relationer i ditt innehåll, vilket leder till mindre exakta svar och minskad synlighet i AI-drivna sök- och hämtningssystem.
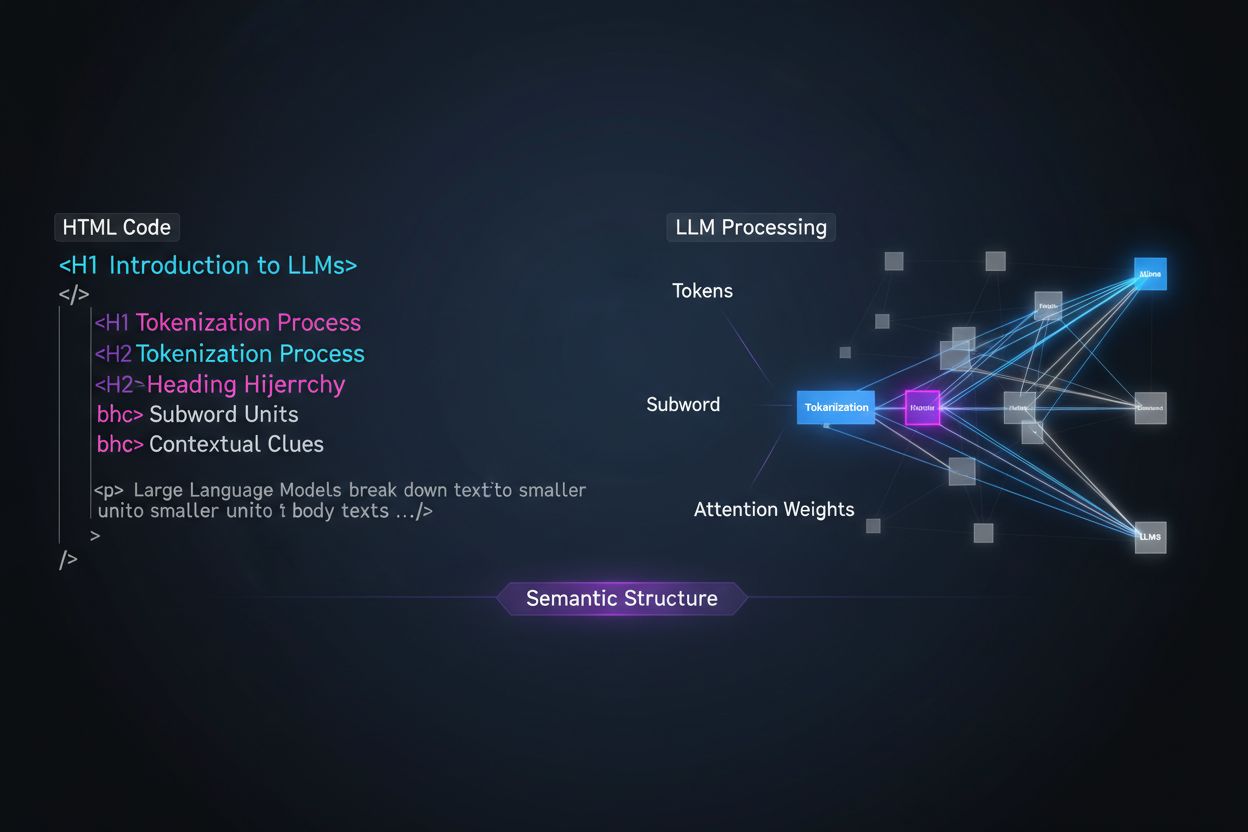
Moderna strategier för innehållsuppdelning (content chunking) i retrieval-augmented generation (RAG)-system och AI-sökmotorer är starkt beroende av rubrikstruktur för att avgöra var dokument ska delas upp i hämtbara segment. När en LLM möter välorganiserade rubrikhierarkier använder den H2- och H3-gränser som naturliga snitt för att skapa semantiska chunkar—diskreta informationsenheter som kan hämtas och citeras oberoende av varandra. Den här processen är betydligt effektivare än att dela efter teckenantal, eftersom rubrikbaserade chunkar bevarar sammanhang och semantisk helhet. Tänk på skillnaden mellan två tillvägagångssätt:
| Tillvägagångssätt | Chunk-kvalitet | LLM-citeringsfrekvens | Hämtningsnoggrannhet |
|---|---|---|---|
| Semantisk (rubrikbaserad) | Hög sammanhang, fullständiga tankar | 3x högre | 85 %+ noggrannhet |
| Generisk (teckenbaserad) | Splittrad, ofullständig kontext | Baslinje | 45–60 % noggrannhet |
Forskning visar att dokument med tydlig rubrikhierarki får 18–27 % förbättrad fråga-svar-noggrannhet när de behandlas av LLM:er, främst eftersom chunkningen bevarar logiska samband mellan idéer. System som Retrieval-Augmented Generation (RAG)-pipelines, som driver verktyg som ChatGPT:s webbläsarfunktion och företags-AI-system, letar uttryckligen efter rubrikstrukturer för att optimera sina hämtningstekniker och förbättra citeringsnoggrannheten.
Korrekt rubrikhierarki följer en strikt nivåstruktur som speglar hur LLM:er förväntar sig att information ska organiseras, där varje nivå har en tydlig funktion i din innehållsarkitektur. H1-taggen representerar dokumentets huvudämne—det ska bara finnas en per sida, och den bör tydligt ange huvudämnet. H2-taggar representerar större avdelningar som stöder eller utvecklar H1, var och en behandlar en särskild aspekt av huvudämnet. H3-taggar går djupare in på specifika delämnen inom varje H2-sektion, ger detaljer och besvarar följdfrågor. Den avgörande regeln för LLM-optimering är att du aldrig ska hoppa över nivåer (t.ex. från H1 direkt till H3) och hålla konsekvent inbäddning—varje H3 måste höra till en H2, och varje H2 till en H1. Denna hierarkiska struktur skapar det forskare kallar ett “semantiskt träd” som LLM:er kan följa för att förstå innehållets logiska flöde och exakt extrahera relevant information.
Den mest effektiva rubrikstrategin för LLM-synlighet behandlar varje H2-rubrik som ett direkt svar på en specifik användarintention eller fråga, med H3-rubriker kopplade till följdfrågor som ger stödjande detaljer. Detta “svar-först”-tänk ligger i linje med hur moderna LLM:er hämtar och sammanställer information—de söker efter innehåll som direkt besvarar användarfrågor, och rubriker som tydligt anger svar är mycket mer benägna att bli utvalda och citerade. Varje H2 bör fungera som en svarenhet, ett självständigt svar på en specifik fråga som en användare kan ha om ditt ämne. Om din H1 till exempel är “Så optimerar du webbplatsens prestanda” kan dina H2:or vara “Minska bildfilstorlekar (förbättrar laddningstiden med 40 %)” eller “Implementera webbläsarcache (minskar serverförfrågningar med 60 %)"—varje rubrik besvarar direkt en prestandafråga. H3:orna under varje H2 tar sedan upp följdfrågor: under “Minska bildfilstorlekar” kan H3:orna vara “Välj rätt bildformat”, “Komprimera utan kvalitetsförlust” och “Använd responsiva bilder”. Denna struktur gör det dramatiskt enklare för LLM:er att identifiera, extrahera och citera ditt innehåll eftersom rubrikerna själva innehåller svaren, inte bara ämnesetiketter.
För att maximera LLM-synlighet med din rubrikstrategi krävs att du implementerar specifika, handlingsbara tekniker som går längre än grundläggande struktur. Här är de mest effektiva optimeringsmetoderna:
Använd beskrivande, specifika rubriker: Byt ut vaga titlar som “Översikt” eller “Detaljer” mot specifika beskrivningar som “Hur maskininlärning förbättrar rekommendationsprecisionen” eller “Tre faktorer som påverkar sökrankning”. Forskning visar att specifika rubriker ökar LLM-citeringsfrekvensen upp till tre gånger jämfört med generiska titlar.
Använd frågeformulerade rubriker: Strukturera H2:or som direkta frågor som användare ställer (“Vad är semantisk sökning?” eller “Varför är rubrikhierarki viktig?”). LLM:er är tränade på fråge- och svarsdata och prioriterar naturligt rubriker i frågeform vid hämtning av svar.
Inkludera tydliga entiteter i rubriker: När du diskuterar specifika koncept, verktyg eller entiteter, namnge dem explicit i rubrikerna istället för att använda pronomen eller vaga referenser. Till exempel är “PostgreSQL-prestandaoptimering” mycket mer LLM-vänligt än “Databasoptimering”.
Undvik att kombinera flera intentioner: Varje rubrik ska behandla ett enda, fokuserat ämne. Rubriker som “Installation, konfiguration och felsökning” urvattnar semantisk tydlighet och förvirrar LLM:ers chunkningsalgoritmer.
Lägg till kvantifierbar kontext: När det är relevant, inkludera siffror, procenttal eller tidsramar i rubriker (“Minska laddningstiden med 40 % med bildoptimering” vs. “Bildoptimering”). Studier visar att 80 % av LLM-citerat innehåll har kvantifierbar kontext i rubrikerna.
Använd parallell struktur på varje nivå: Håll konsekvent grammatisk struktur över H2:or och H3:or inom samma sektion. Om en H2 börjar med ett verb (“Implementera cache”), bör övriga göra det också (“Konfigurera databasindex”, “Optimera frågor”).
Inkludera nyckelord naturligt: Även om det inte är enbart för SEO, hjälper relevanta nyckelord i rubriker LLM:er att förstå ämnesrelevans och förbättrar hämtningsnoggrannheten med 25–35 %.
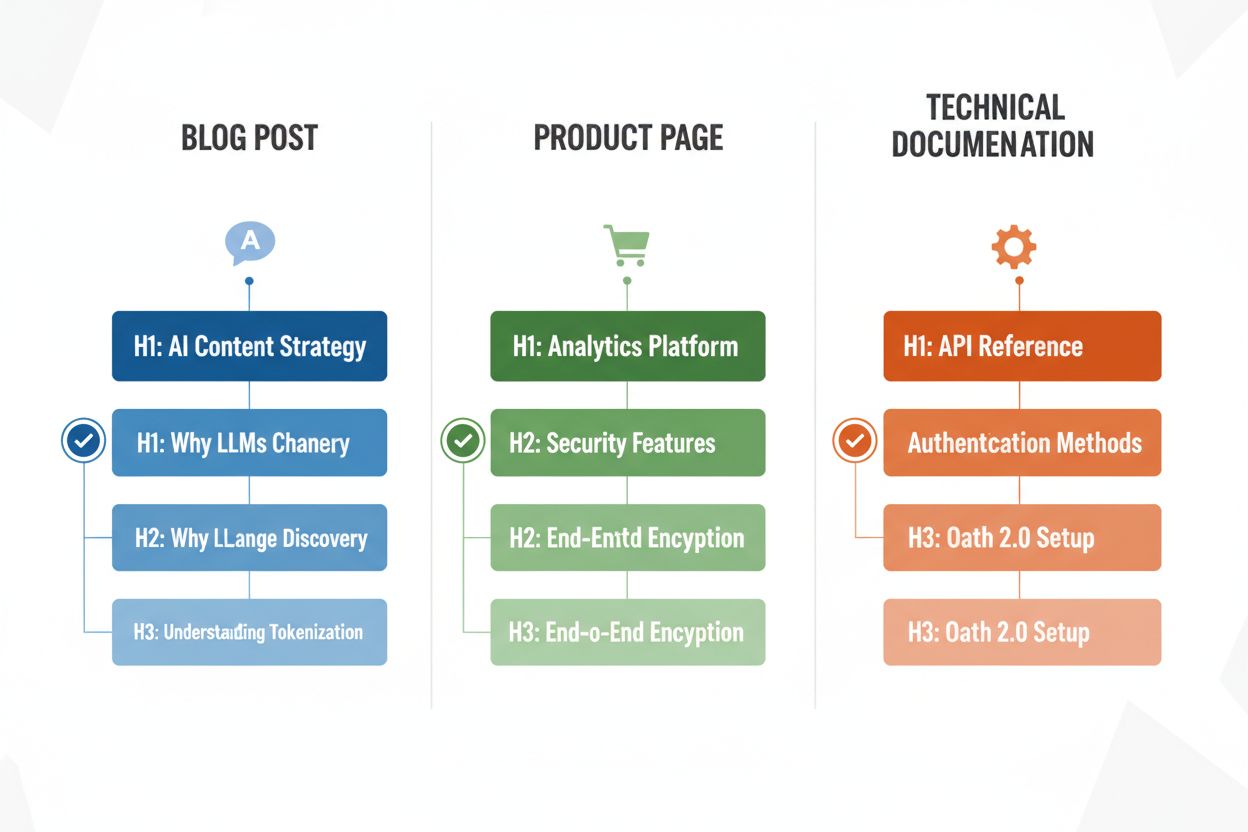
Olika innehållstyper kräver anpassade rubrikstrategier för att maximera LLM-tolkningens effektivitet, och förståelse för dessa mönster säkerställer att ditt innehåll är optimerat oavsett format. Blogginlägg gynnas av berättelsedrivna rubrikhierarkier där H2:or följer en logisk progression genom ett argument eller en förklaring, och H3:or ger evidens, exempel eller djupare utforskning—till exempel kan ett inlägg om “AI-innehållsstrategi” använda H2:or som “Varför LLM:er förändrar innehållsupptäckt”, “Så optimerar du för AI-synlighet” och “Mät din AI-innehållsprestanda”. Produktsidor bör använda H2:or som direkt kopplas till användarfrågor och beslutsfaktorer (“Säkerhet och efterlevnad”, “Integrationsmöjligheter”, “Pris och skalbarhet”), med H3:or som behandlar specifika funktionsfrågor eller användningsfall. Teknisk dokumentation kräver den mest detaljerade rubrikstrukturen, med H2:or som representerar huvudfunktioner eller arbetsflöden och H3:or som bryter ner specifika uppgifter, parametrar eller konfigurationsalternativ—denna struktur är avgörande eftersom dokumentation ofta citeras av LLM:er när användare ställer tekniska frågor. FAQ-sidor bör använda H2:or som själva frågorna (formulerade som riktiga frågor) och H3:or för följdförklaringar eller relaterade ämnen, eftersom denna struktur passar perfekt för hur LLM:er hämtar och presenterar Q&A-innehåll. Varje innehållstyp har olika användarintentioner och din rubrikhierarki bör spegla dessa för att maximera relevansen och chansen att bli citerad.
När du har omstrukturerat dina rubriker är validering avgörande för att säkerställa att de faktiskt förbättrar LLM-tolkning och synlighet. Det mest praktiska sättet är att testa ditt innehåll direkt med AI-verktyg som ChatGPT, Perplexity eller Claude genom att ladda upp ditt dokument eller ange en URL och ställa frågor som dina rubriker är utformade för att besvara. Notera om AI-verktyget korrekt identifierar och citerar ditt innehåll, och om det extraherar rätt sektioner—om din H2 om “Att minska laddningstiden” inte citeras när användare frågar om prestandaoptimering kan rubriken behöva förbättras. Du kan också använda specialverktyg som SEO-plattformar med AI-citeringsspårning (som Semrush eller Ahrefs nya AI-funktioner) för att följa hur ofta ditt innehåll visas i LLM-svar över tid. Iterera baserat på resultat: om vissa sektioner inte citeras, testa mer specifika eller frågeformulerade rubriker, lägg till kvantifierbar kontext eller förtydliga kopplingen mellan rubriken och vanliga användarfrågor. Denna testcykel tar vanligtvis 2–4 veckor innan du ser mätbara resultat, eftersom det tar tid för AI-system att indexera om och omvärdera ditt innehåll.
Även välmenande innehållsskapare gör ofta rubrikmisstag som minskar LLM-synlighet och tolkningsprecision avsevärt. Ett av de vanligaste felen är att kombinera flera intentioner i en och samma rubrik—till exempel “Installation, konfiguration och felsökning” tvingar LLM:er att välja vilket ämne sektionen gäller, vilket ofta leder till fel chunkning och minskad chans att bli citerad. Vaga, generiska rubriker som “Översikt”, “Viktiga punkter” eller “Ytterligare information” ger ingen semantisk klarhet och gör det omöjligt för LLM:er att förstå vad sektionen faktiskt innehåller; när en LLM stöter på dessa rubriker hoppar den ofta över sektionen helt eller misstolkar dess relevans. Saknad kontext är ett annat kritiskt fel—en rubrik som “Bästa praxis” säger inte till en LLM vilket område eller ämne rekommendationerna gäller, medan “Bästa praxis för API-rate limiting” är omedelbart tydligt och hämtbart. Inkonsekvent hierarki (att hoppa över nivåer, använda H4 utan H3, eller blanda rubrikstilar) förvirrar LLM:s tolkningsalgoritmer eftersom de förlitar sig på konsekventa mönster för att förstå dokumentstruktur. Till exempel skapar ett dokument som använder H1 → H3 → H2 → H4 oklarhet om vilka sektioner som hänger ihop och vilka som är självständiga, vilket försämrar hämtningsnoggrannheten med 30–40 %. Att testa ditt innehåll med ChatGPT eller liknande verktyg avslöjar snabbt dessa misstag—om AI:n har svårt att förstå din innehållsstruktur eller citerar fel sektioner behöver dina rubriker troligen revideras.
Att optimera rubrikhierarki för LLM-tolkning ger en kraftfull sekundär fördel: förbättrad tillgänglighet för mänskliga användare med funktionsnedsättningar. Semantisk HTML-rubrikstruktur (korrekt användning av H1–H6-taggar) är grundläggande för skärmläsarfunktionalitet och gör det möjligt för synskadade användare att navigera i dokument effektivt och förstå innehållets organisation. När du skapar tydliga, beskrivande rubriker optimerade för LLM-tolkning skapar du samtidigt bättre navigation för skärmläsare—samma specifika och tydliga rubriker som hjälper LLM:er att förstå ditt innehåll hjälper hjälpmedel att guida användare genom det. Denna samverkan mellan AI-optimering och tillgänglighet är en sällsynt win-win: de tekniska kraven för LLM-vänligt innehåll stödjer direkt WCAG:s tillgänglighetsstandarder och förbättrar upplevelsen för alla användare. Organisationer som prioriterar rubrikhierarki för AI-synlighet ser ofta oväntade förbättringar i tillgänglighetsbetyg och nöjdhetsmätningar från användare som är beroende av hjälpmedel.
Att införa förbättringar i rubrikhierarkin kräver mätning för att motivera insatsen och identifiera vad som fungerar. Den mest direkta KPI:n är LLM-citeringsfrekvens—följ hur ofta ditt innehåll dyker upp i svar från ChatGPT, Perplexity, Claude och andra AI-verktyg genom att regelbundet ställa relevanta frågor och logga vilka källor som citeras. Verktyg som Semrush, Ahrefs och nyare plattformar som Originality.AI erbjuder nu LLM-citeringsspårning som övervakar din synlighet i AI-genererade svar över tid. Du bör förvänta dig en 2–3 gånger ökning av citeringar inom 4–8 veckor efter implementering av korrekt rubrikhierarki, men resultatet varierar beroende på innehållstyp och konkurrensnivå. Utöver citeringar, spåra organisk trafik från AI-drivna sökfunktioner (Googles AI Overviews, Bing Chat-citeringar etc.) separat från traditionell organisk sökning, eftersom dessa ofta förbättras snabbare med rubrikoptimering. Följ dessutom engagemangsmått för innehåll som tid på sidan och scroll-djup för sidor med optimerade rubriker—bättre struktur ökar vanligtvis engagemanget med 15–25 % eftersom användare lättare hittar relevant information. Slutligen, mät hämtningsnoggrannhet i dina egna system om du använder RAG-pipelines eller interna AI-verktyg genom att testa om rätt sektioner hämtas för vanliga frågor. Dessa mått visar tillsammans ROI för rubrikoptimering och vägleder fortsatt utveckling av din innehållsstrategi.
Rubrikhierarki påverkar främst AI-synlighet och LLM-citeringar snarare än traditionella Google-rankingar. Dock förbättrar korrekt rubrikstruktur den övergripande innehållskvaliteten och läsbarheten, vilket indirekt stödjer SEO. Den största fördelen är ökad synlighet i AI-drivna sökresultat som Google AI Overviews, ChatGPT och Perplexity, där rubrikstruktur är avgörande för innehållsextraktion och citering.
Ja, om dina nuvarande rubriker är vaga eller inte följer en tydlig H1→H2→H3-hierarki. Börja med att granska dina mest populära sidor och implementera rubrikförbättringar på innehåll med hög trafik först. Det positiva är att LLM-vänliga rubriker också är mer användarvänliga, så förändringarna gynnar både människor och AI-system.
Absolut. Faktum är att de bästa rubrikstrukturerna fungerar bra för båda. Tydliga, beskrivande och hierarkiska rubriker som hjälper människor att förstå innehållsorganisation är precis vad LLM:er behöver för tolkning och uppdelning. Det finns ingen konflikt mellan människovänliga och LLM-vänliga rubrikrutiner.
Det finns ingen strikt gräns, men sikta på 3–7 H2:or per sida beroende på innehållets längd och komplexitet. Varje H2 bör representera ett specifikt ämne eller svarsenhet. Under varje H2, inkludera 2–4 H3:or för stödjande detaljer. Sidor med totalt 12–15 rubriksektioner (H2:or och H3:or tillsammans) tenderar att prestera bra i LLM-citeringar.
Ja, även kortare innehåll gynnas av korrekt rubrikstruktur. En artikel på 500 ord kan ha bara 1–2 H2:or, men de bör ändå vara beskrivande och specifika. Kort innehåll med tydliga rubriker citeras oftare i LLM-svar än ostrukturerat kortinnehåll.
Testa ditt innehåll direkt med ChatGPT, Perplexity eller Claude genom att ställa frågor som dina rubriker är tänkta att besvara. Om AI:n korrekt identifierar och citerar ditt innehåll fungerar din struktur. Om den har svårt eller citerar fel sektioner behöver rubrikerna förbättras. De flesta förbättringar ger resultat inom 2–4 veckor.
Google AI Overviews och ChatGPT gynnas båda av tydlig rubrikhierarki, men ChatGPT lägger ännu större vikt vid det. ChatGPT citerar innehåll med sekventiell rubrikstruktur tre gånger oftare än innehåll utan sådan. Grundprinciperna är desamma, men LLM:er som ChatGPT är mer känsliga för rubrikkvalitet och struktur.
Frågeformulerade rubriker fungerar bäst för FAQ-sidor, felsökningsguider och utbildningsinnehåll. För blogginlägg och produktsidor fungerar ofta en blandning av fråge- och påståenderubriker bäst. Det viktiga är att rubrikerna tydligt anger vad sektionen handlar om, oavsett om det är en fråga eller ett påstående.
Följ hur ofta ditt innehåll citeras i ChatGPT, Perplexity, Google AI Overviews och andra LLM:er. Få insikter i realtid om din AI-sökprestanda och optimera din innehållsstrategi.
Lär dig bästa praxis för att formatera rubriker för AI-system. Upptäck hur korrekt H1-, H2-, H3-hierarki förbättrar AI-innehållsåterhämtning, citeringar och syn...
Upptäck varför AI-modeller föredrar listiklar och numrerade listor. Lär dig optimera listbaserat innehåll för ChatGPT, Gemini och Perplexity-citat med beprövade...

Lär dig identifiera och rikta in dig på LLM-källsidor för strategiska bakåtlänkar. Upptäck vilka AI-plattformar som citerar källor mest och optimera din länkstr...