Upptäck hur Retrieval-Augmented Generation omvandlar AI-citeringar och möjliggör korrekt källhänvisning och förankrade svar i ChatGPT, Perplexity och Google AI Overviews.
Publicerad den Jan 3, 2026.Senast ändrad den Jan 3, 2026 kl 3:24 am
Stora språkmodeller har revolutionerat AI, men de har en avgörande brist: kunskapsgränser. Dessa modeller tränas på data fram till en viss tidpunkt och kan därför inte komma åt information efter det datumet. Utöver att bli inaktuella lider traditionella LLM:er av hallucinationer—de genererar självsäkert falsk information som låter trovärdig—och de lämnar ingen källhänvisning till sina påståenden. När ett företag behöver aktuell marknadsdata, egen forskning eller verifierbara fakta räcker inte traditionella LLM:er till, och användarna lämnas med svar de inte kan lita på eller verifiera.
Vad är RAG – kärndefinition & komponenter
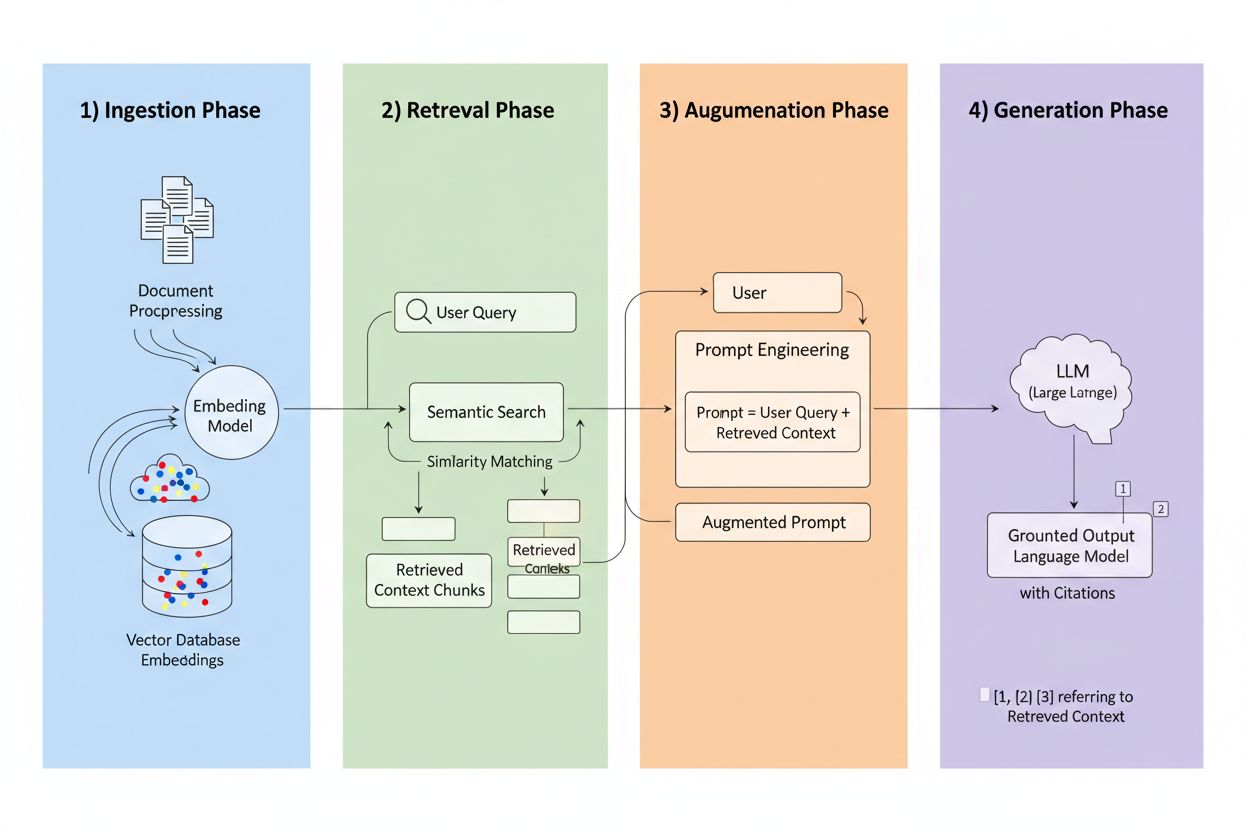
Retrieval-Augmented Generation (RAG) är en ram som kombinerar den generativa kraften hos LLM:er med noggrannheten i informationssökningssystem. Istället för att enbart förlita sig på träningsdata hämtar RAG-system relevant information från externa källor innan de genererar svar, och skapar därmed en process där svaren grundas i faktisk data. De fyra huvudkomponenterna arbetar tillsammans: Ingestion (omvandlar dokument till sökbara format), Retrieval (hittar de mest relevanta källorna), Augmentation (berikar prompten med hämtat sammanhang) och Generation (skapar det slutliga svaret med citeringar). Så här jämförs RAG med traditionella metoder:
Aspekt
Traditionell LLM
RAG-system
Kunskapskälla
Statisk träningsdata
Externa indexerade källor
Citeringsförmåga
Ingen/hallucinerad
Spårbar till källor
Noggrannhet
Benägen för fel
Grundad i fakta
Realtidsdata
Nej
Ja
Hallucinationsrisk
Hög
Låg
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Sökmotorn är RAG:s hjärta och är betydligt mer avancerad än enkel nyckelords-matchning. Dokument konverteras till vektorinbäddningar—matematiska representationer som fångar semantisk betydelse—vilket gör att systemet kan hitta konceptuellt liknande innehåll även när exakta ord inte matchar. Systemet delar upp dokument i hanterbara delar, vanligtvis 256–1024 token, för att balansera bevarandet av sammanhang med precision i sökningen. De mest avancerade RAG-systemen använder hybridsökning, där semantisk likhet kombineras med traditionell nyckelords-matchning för att fånga både konceptuella och exakta träffar. En omrankningsmekanism ger sedan dessa kandidater poäng, ofta med hjälp av cross-encoder-modeller som utvärderar relevans mer exakt än den initiala sökningen. Relevansen beräknas via flera signaler: semantiska likhetspoäng, nyckelordsöverensstämmelse, metadatasmatchning och domänauktoritet. Hela processen sker på millisekunder, så användaren får snabba, korrekta svar utan märkbar fördröjning.
Citeringsfördelen
Här omvandlar RAG citeringslandskapet: när ett system hämtar information från en specifik indexerad källa blir den källan spårbar och verifierbar. Varje textstycke kan kopplas tillbaka till sitt ursprungliga dokument, URL eller publikation, vilket gör citeringen automatisk istället för hallucinerad. Denna grundläggande förändring skapar en aldrig tidigare skådad transparens i AI-beslutsfattande—användare kan se exakt vilka källor som påverkat svaret, verifiera påståenden själva och bedöma källans trovärdighet. Till skillnad från traditionella LLM:er där citeringar ofta är påhittade eller generiska, är RAG-citeringar förankrade i verkliga händelser. Denna spårbarhet bygger dramatiskt användarförtroende, eftersom folk kan kontrollera informationen istället för att ta den på tro. För innehållsskapare och publicister innebär det att deras arbete kan upptäckas och tillskrivas via AI-system, vilket öppnar helt nya synlighetskanaler.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Faktorer för citeringskvalitet i RAG-system
Alla källor är inte lika i RAG-system, och flera faktorer avgör vilket innehåll som citeras oftast:
Auktoritet: Domänrykte, bakåtlänksprofiler och närvaro i kunskapsgrafer signalerar trovärdighet till sökalgoritmer
Aktualitet: Innehåll som uppdateras inom 48–72 timmar rankas högre, eftersom färskhet indikerar aktivt underhåll och tillförlitlighet
Relevans: Semantisk överensstämmelse med användarfrågor avgör om innehållet överhuvudtaget dyker upp i sökresultaten
Struktur: Tydlig hierarki, beskrivande rubriker och semantisk markup hjälper systemen att tolka och extrahera information korrekt
Faktadensitet: Innehåll fyllt med specifika data, statistik och källhänvisningar erbjuder fler sökbara bitar än generella översikter
Kunskapsgraf: Närvaro i Wikipedia, Wikidata eller branschspecifika kunskapsbaser ökar dramatiskt sannolikheten för citering
Varje faktor förstärker de andra—en välstrukturerad, ofta uppdaterad artikel från en auktoritativ domän med starka bakåtlänkar och kunskapsgraf-närvaro blir en citeringsmagnet i RAG-system. Detta skapar ett nytt optimeringsparadigm där synlighet beror mindre på trafikdriven SEO och mer på att bli en trovärdig, strukturerad informationskälla.
Hur olika AI-plattformar använder RAG för citeringar
Olika AI-plattformar implementerar RAG med olika strategier, vilket skapar varierande citeringsmönster. ChatGPT viktar Wikipedia-källor tungt, och studier visar att cirka 26–35% av citeringarna kommer från just Wikipedia, tack vare dess auktoritet och strukturerade format. Google AI Overviews använder mer diversifierade källor, inklusive nyhetssajter, akademiska artiklar och forum, där Reddit står för cirka 5% av citeringarna trots lägre traditionell auktoritet. Perplexity AI citerar vanligtvis 3–5 källor per svar och visar tydliga preferenser för branschspecifika publikationer och senaste nyheter, med fokus på omfattning och aktualitet. Dessa plattformar värderar domänauktoritet olika—vissa prioriterar traditionella faktorer som bakåtlänkar och domänålder, medan andra betonar innehållets färskhet och semantisk relevans. Att förstå dessa plattformsspecifika hämtstrategier är avgörande för innehållsskapare, eftersom optimering för ett plattforms RAG-system kan skilja sig avsevärt från ett annats.
RAG kontra traditionell sökning – citeringsimplikationer
RAG:s framväxt omkullkastar grundläggande SEO-principer. Inom sökmotoroptimering korrelerar citeringar och synlighet direkt med trafik—du måste få klick för att vara relevant. RAG vänder på detta: innehåll kan bli citerat och påverka AI-svar utan att generera någon trafik. En välstrukturerad, auktoritativ artikel kan dyka upp i dussintals AI-svar dagligen utan att få ett enda klick, eftersom användarna får sitt svar direkt från AI-sammanfattningen. Det innebär att auktoritetssignaler är viktigare än någonsin, eftersom de är den primära mekanismen för hur RAG-system utvärderar källkvalitet. Konsekvens över plattformar blir avgörande—om ditt innehåll finns på din hemsida, LinkedIn, branschdatabaser och kunskapsgrafer ser RAG-system förstärkta auktoritetssignaler. Närvaro i kunskapsgrafer går från att vara “bra att ha” till avgörande infrastruktur, eftersom dessa strukturerade databaser är primära hämtkällor för många RAG-implementationer. Citeringsspelet har fundamentalt ändrats från “driv trafik” till “bli en pålitlig informationskälla”.
Optimera innehåll för RAG-citeringar
För att maximera RAG-citeringar måste innehållsstrategin skifta från trafikoptimering till källoptimering. Implementera uppdateringscykler på 48–72 timmar för ständigt aktuellt innehåll, vilket signalerar till hämtande system att din information är färsk. Använd strukturerad datamarkering (Schema.org, JSON-LD) för att hjälpa systemen att tolka och förstå innehållets betydelse och relationer. Anpassa innehållet semantiskt till vanliga frågemönster—använd naturligt språk som matchar hur folk ställer frågor, inte bara hur de söker. Formatera innehåll med FAQ- och Q&A-avsnitt, eftersom dessa direkt matchar det fråge-svarsmönster som RAG-system använder. Utveckla eller bidra till Wikipedia- och kunskapsgrafsposter, eftersom dessa är primära hämtkällor för de flesta plattformar. Bygg bakåtlänksauktoritet genom strategiska samarbeten och citeringar från andra auktoritativa källor, eftersom länkar fortfarande är starka auktoritetssignaler. Slutligen, upprätthåll konsekvens över plattformar—se till att dina kärnpåståenden, data och budskap är samstämmiga över din webbplats, sociala profiler, branschdatabaser och kunskapsgrafer, vilket skapar förstärkta signaler om pålitlighet.
Framtiden för RAG och citeringar
RAG-teknologin utvecklas snabbt, med flera trender som förändrar hur citeringar fungerar. Mer sofistikerade hämtalgoritmer kommer att gå bortom semantisk likhet mot en djupare förståelse av frågeintention och sammanhang, vilket förbättrar citeringsrelevansen. Specialiserade kunskapsbaser kommer att växa fram för specifika områden—medicinska RAG-system som använder kuraterad medicinsk litteratur, juridiska system med rättsfall och lagar—vilket skapar nya citeringsmöjligheter för auktoritativa domänkällor. Integration med multi-agent-system kommer att göra det möjligt för RAG att samordna flera specialiserade hämtare, och kombinera insikter från olika kunskapsbaser för mer heltäckande svar. Realtidsåtkomst till data kommer att förbättras dramatiskt, så RAG-system kan införliva liveinformation från API:er, databaser och strömmande källor. Agentisk RAG—där AI-agenter självständigt avgör vad de ska hämta, hur de ska bearbeta det och när de ska iterera—kommer skapa mer dynamiska citeringsmönster och potentiellt citera källor flera gånger när agenter förfinar sitt resonemang.
AmICiteds roll i RAG-citeringsövervakning
När RAG omformar hur AI-system upptäcker och citerar källor blir det avgörande att förstå din citeringsprestanda. AmICited övervakar AI-citeringar över plattformar och spårar vilka av dina källor som visas i ChatGPT, Google AI Overviews, Perplexity och framväxande AI-system. Du ser vilka specifika källor som citeras, hur ofta de förekommer och i vilket sammanhang—vilket avslöjar vilket innehåll som tilltalar RAG:s hämtalgoritmer. Vår plattform hjälper dig att förstå citeringsmönster i din innehållsportfölj, identifiera vad som gör vissa delar citeringsvärda och andra osynliga. Mät ditt varumärkes synlighet i AI-svar med mätvärden som spelar roll i RAG-eran, bortom traditionell trafikanalys. Genomför konkurrensanalys av citeringsprestanda och se hur dina källor står sig mot konkurrenterna i AI-genererade svar. I en värld där AI-citeringar driver synlighet och auktoritet är tydlig insyn i din citeringsprestanda inte valfritt—det är så du förblir konkurrenskraftig.
Vanliga frågor
Vad är skillnaden mellan RAG och traditionella LLM:er?
Traditionella LLM:er förlitar sig på statisk träningsdata med kunskapsgränser och kan inte komma åt information i realtid, vilket ofta leder till hallucinationer och icke-verifierbara påståenden. RAG-system hämtar information från externa indexerade källor innan de genererar svar, vilket möjliggör korrekta citeringar och förankrade svar baserade på aktuell, verifierbar data.
Hur förbättrar RAG citeringsnoggrannheten?
RAG spårar varje hämtad informationsbit tillbaka till dess ursprungliga källa, vilket gör citeringar automatiska och verifierbara istället för hallucinerade. Detta skapar en direkt koppling mellan svaret och källmaterialet, så att användare kan verifiera påståenden oberoende och bedöma källans trovärdighet.
Vilka faktorer avgör vilka källor som citeras i RAG-system?
RAG-system utvärderar källor baserat på auktoritet (domänrykte och bakåtlänkar), aktualitet (innehåll uppdaterat inom 48–72 timmar), semantisk relevans för frågan, innehållsstruktur och tydlighet, faktadensitet med specifika datapunkter samt närvaro i kunskapsgrafer som Wikipedia. Dessa faktorer samverkar för att avgöra sannolikheten för citering.
Hur kan jag optimera mitt innehåll för RAG-citeringar?
Uppdatera innehåll var 48–72 timme för att upprätthålla färskhetssignaler, implementera strukturerad datamarkering (Schema.org), anpassa innehållet semantiskt till vanliga frågor, använd FAQ- och Q&A-format, utveckla närvaro i Wikipedia och kunskapsgrafer, bygg auktoritet med bakåtlänkar och säkerställ konsekvens på alla plattformar.
Varför är närvaro i en kunskapsgraf viktig för AI-citeringar?
Kunskapsgrafer som Wikipedia och Wikidata är primära hämtkällor för de flesta RAG-system. Närvaro i dessa strukturerade databaser ökar dramatiskt sannolikheten för citering och skapar grundläggande förtroendesignaler som AI-system hänvisar till upprepade gånger vid olika frågor.
Hur ofta bör jag uppdatera innehåll för RAG-synlighet?
Innehållet bör uppdateras var 48–72 timme för att upprätthålla starka aktualitetssignaler i RAG-system. Det kräver inte fullständiga omskrivningar – att lägga till nya datapunkter, uppdatera statistik eller utöka avsnitt med senaste utvecklingar räcker för att behålla citeringsberättigande.
Vilken roll spelar domänauktoritet i RAG-citeringar?
Domänauktoritet fungerar som en pålitlighetsindikator i RAG-algoritmer och står för cirka 5% av citeringssannolikheten. Den bedöms genom domänålder, SSL-certifikat, bakåtlänksprofiler, expertattribution och närvaro i kunskapsgrafer, vilka samverkar och påverkar källvalet.
Hur hjälper AmICited till att övervaka RAG-citeringar?
AmICited spårar vilka av dina källor som visas i AI-genererade svar på ChatGPT, Google AI Overviews, Perplexity och andra plattformar. Du ser citeringsfrekvens, sammanhang och konkurrensprestation, vilket hjälper dig att förstå vad som gör innehåll citeringsvärt i RAG-eran.
Övervaka ditt varumärkes AI-citeringar
Förstå hur ditt varumärke syns i AI-genererade svar på ChatGPT, Perplexity, Google AI Overviews och fler. Spåra citeringsmönster, mät synlighet och optimera din närvaro i det AI-drivna söklandskapet.
Vad är RAG i AI-sök: Komplett guide till Retrieval-Augmented Generation
Lär dig vad RAG (Retrieval-Augmented Generation) är inom AI-sök. Upptäck hur RAG förbättrar noggrannhet, minskar hallucinationer och driver ChatGPT, Perplexity ...
Lär dig vad Retrieval-Augmented Generation (RAG) är, hur det fungerar och varför det är avgörande för exakta AI-svar. Utforska RAG-arkitektur, fördelar och före...
Hur Retrieval-Augmented Generation Fungerar: Arkitektur och Process
Lär dig hur RAG kombinerar LLM:er med externa datakällor för att generera exakta AI-svar. Förstå processen i fem steg, komponenterna och varför det är viktigt f...
9 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.