Att Köra GEO-Experiment: Kontrollgrupper och Variabler
Behärska GEO-experiment med vår omfattande guide om kontrollgrupper och variabler. Lär dig att designa, genomföra och analysera geografiska experiment för exakt marknadsföringsmätning och AI-synlighetsspårning.
Publicerad den Jan 3, 2026.Senast ändrad den Jan 3, 2026 kl 3:24 am
GEO-experiment, även kallade geo lift-tester eller geografiska experiment, representerar en grundläggande förändring i hur marknadsförare mäter den verkliga effekten av sina kampanjer. Dessa experiment delar in geografiska regioner i test- och kontrollgrupper, vilket gör det möjligt för marknadsförare att isolera den inkrementella effekten av marknadsföringsinsatser utan att förlita sig på spårning på individnivå. I en tid då integritetsregler som GDPR och CCPA skärps och tredjepartscookies fasas ut, erbjuder GEO-experiment ett integritetssäkert, statistiskt robust alternativ till traditionella mätmetoder. Genom att jämföra resultat mellan regioner som utsatts för marknadsföring och de som inte gjort det, kan organisationer med självförtroende besvara frågan: “Vad skulle ha hänt utan vår kampanj?” Denna metod har blivit avgörande för varumärken som vill förstå verklig inkrementalitet och optimera sin marknadsföringsbudget med precision.
Förstå kontrollgrupper i GEO-experiment
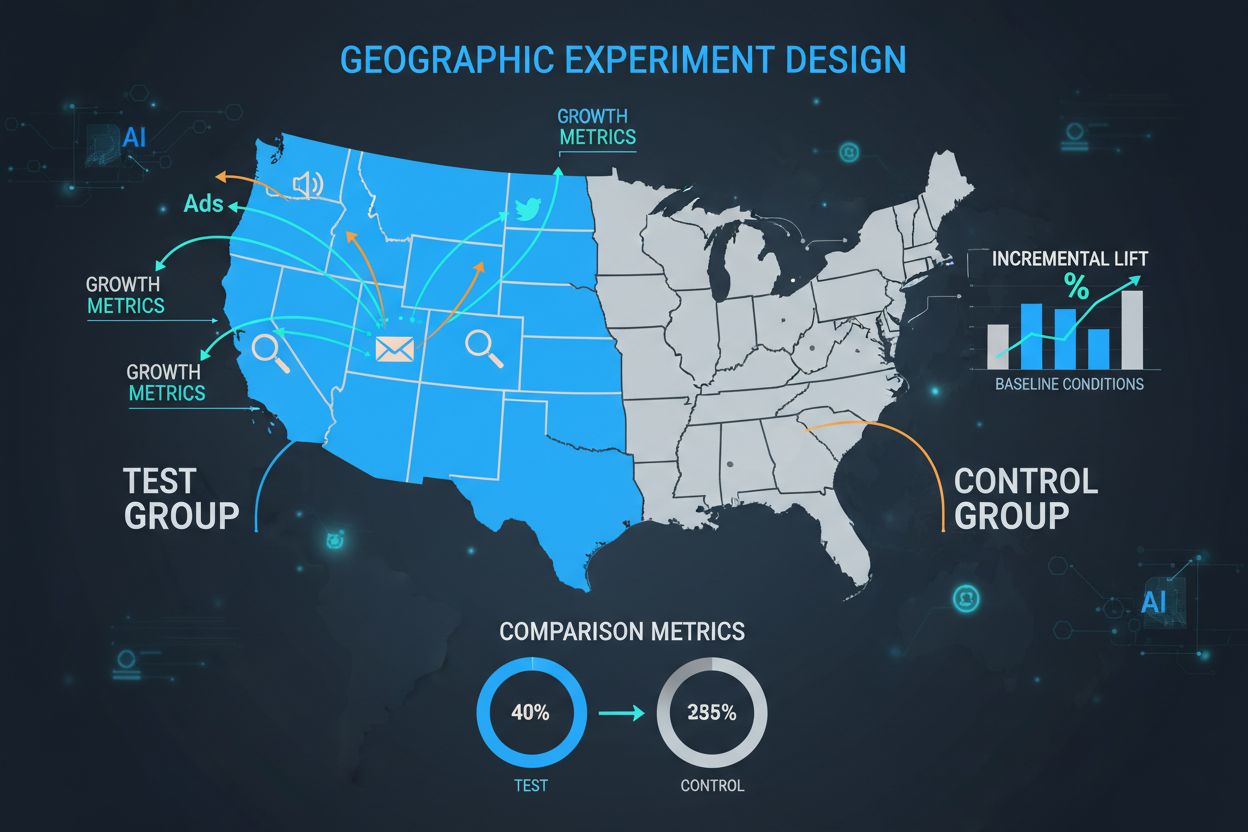
Kontrollgruppen är hörnstenen i varje GEO-experiment och fungerar som den kritiska baslinjen mot vilken alla behandlingseffekter mäts. En kontrollgrupp består av geografiska regioner som inte får marknadsföringsinsatsen, vilket gör det möjligt för marknadsförare att se vad som skulle ha hänt naturligt utan kampanjen. Kontrollgruppers styrka ligger i deras förmåga att ta hänsyn till externa faktorer—säsongsvariationer, konkurrentaktivitet, ekonomiska förhållanden och marknadstrender—som annars skulle förvilla resultaten. När de är korrekt utformade möjliggör kontrollgrupper att forskare kan isolera den verkliga kausala effekten av marknadsföringsinsatser istället för att bara observera korrelation. Urvalet av kontrollregioner kräver noggrann matchning av flera dimensioner inklusive demografiska egenskaper, historiska prestationsmått, marknadsstorlek och konsumentbeteendemönster. Dåligt valda kontrollgrupper leder till hög varians i resultaten, breda konfidensintervall och i slutändan opålitliga slutsatser som kan leda till kostsamma felallokeringar av marknadsföringsbudgeten.
Aspekt
Kontrollgrupp
Testgrupp
Marknadsföringsinsats
Ingen (Business as Usual)
Aktiv kampanj
Syfte
Fastställa baslinje
Mäta effekt
Geografiskt urval
Matchat mot test
Primärt fokus
Datainsamling
Samma mått
Samma mått
Urvalsstorlek
Jämförbar
Jämförbar
Konfunderande variabler
Minimerade
Minimerade
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Lyckade GEO-experiment kräver noggrann hantering av flera typer av variabler som påverkar resultat och tolkbarhet. Att förstå skillnaden mellan oberoende, beroende, kontroll- och konfunderande variabler är avgörande för att utforma experiment som ger handlingsbara insikter.
Oberoende variabler: Det är de marknadsföringstaktiker du aktivt manipulerar och testar, t.ex. annonsbudgetnivåer, kreativa variationer, kanalval, målgruppsparametrar eller kampanjerbjudanden. Den oberoende variabeln är det du försöker mäta effekten av.
Beroende variabler: Det är resultaten du mäter för att bedöma effekten av din marknadsföringsinsats, inklusive intäkter, konverteringar, kundanskaffning, varumärkeskännedom, webbtrafik och, viktigt för moderna marknadsförare, AI-citatsynlighet och varumärkesomnämnanden i AI-system.
Kontrollvariabler: Det är faktorer du håller konstanta i både test- och kontrollgrupper för att säkerställa rättvis jämförelse, såsom budskapets konsistens, erbjudandestruktur, kampanjens längd och mediemixens sammansättning.
Konfunderande variabler: Det är oväntade externa faktorer som kan påverka resultat oberoende av din marknadsföringsinsats, inklusive konkurrentkampanjer, naturkatastrofer, stora nyhetshändelser, säsongsvariationer och ekonomiska skiften.
Mätningsvariabler: Det är de specifika KPI:er och mått du spårar, inklusive inkrementell lyft, inkrementell ROAS (iROAS), inkrementell CAC (iCAC) och konfidensintervall kring dina uppskattningar.
Design av balanserade test- och kontrollgrupper
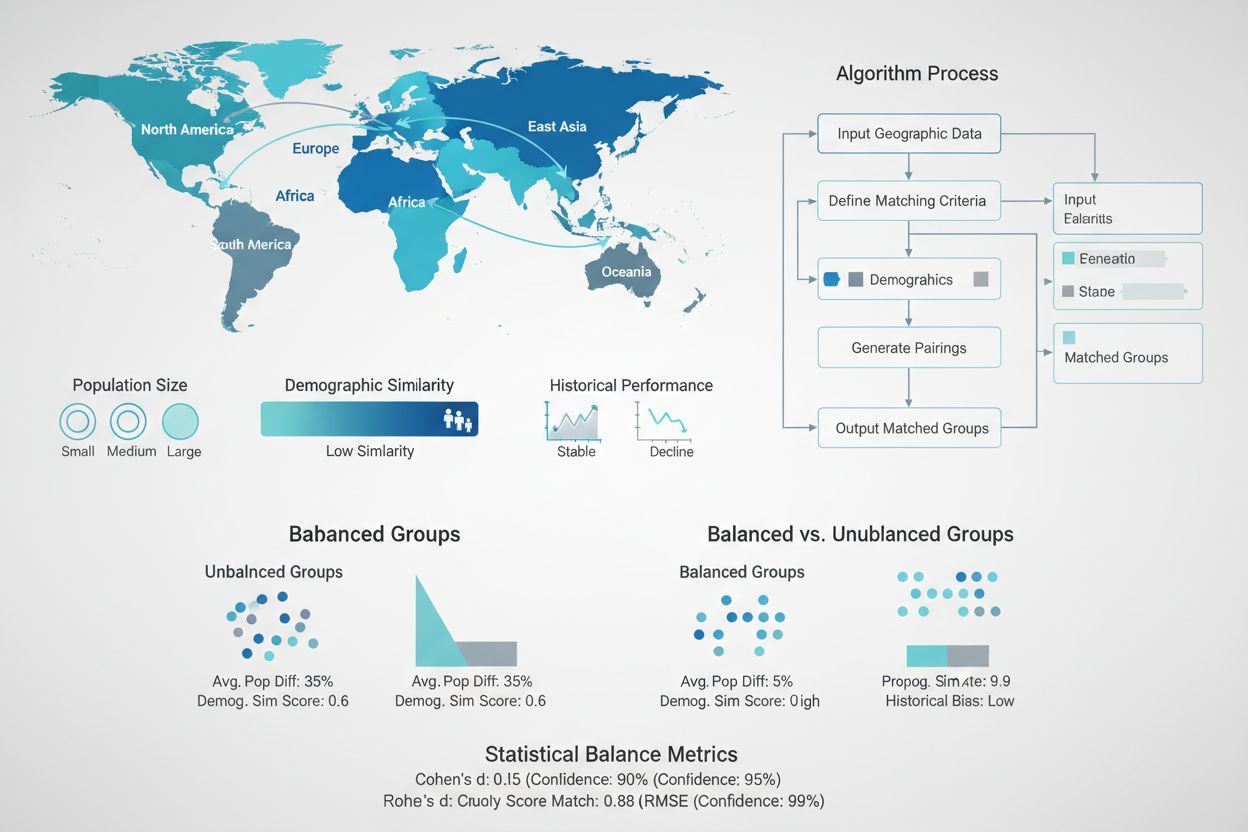
Att skapa statistiskt likvärdiga test- och kontrollgrupper är en av de mest avgörande aspekterna av GEO-experimentdesign, men också en av de mest utmanande. Till skillnad från randomiserade kontrollerade studier med miljontals individuella användare arbetar GEO-experiment vanligtvis med endast dussintals till hundratals geografiska enheter, vilket gör slumpmässig fördelning ofta otillräcklig för att uppnå balans. Avancerade matchningsalgoritmer och optimeringstekniker har utvecklats för att möta denna utmaning. Syntetiska kontrollmetoder, utvecklade av ekonometriker och populariserade av företag som Wayfair och Haus, använder historisk data för att identifiera och vikta kontrollregioner som bäst matchar egenskaperna för testregionerna. Dessa algoritmer beaktar flera dimensioner samtidigt—befolkningsstorlek, demografisk sammansättning, historiska försäljningsmönster, mediekonsumtion och konkurrenslandskap—för att skapa kontrollgrupper som fungerar som exakta kontrafaktiska jämförelser. Målet är att minimera skillnaden mellan test- och kontrollgrupper på alla pre-behandlingsmått, så att alla observerade skillnader efter behandling med säkerhet kan tillskrivas marknadsföringsinsatsen snarare än förhandsbefintliga skillnader.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Statistiska grunder och konfidensintervall
Den statistiska noggrannheten i GEO-experiment skiljer dem från vardagliga observationer eller anekdotiska bevis. Konfidensintervall representerar det intervall inom vilket den verkliga behandlingseffekten sannolikt ligger, uttryckt med en angiven säkerhetsnivå (vanligtvis 95%). Ett smalt konfidensintervall indikerar hög precision och säkerhet i dina resultat, medan ett brett intervall antyder betydande osäkerhet. Om ett GEO-experiment till exempel visar en 10% lyft med ett 95%-igt konfidensintervall på ±2%, kan du vara ganska säker på att den verkliga effekten ligger mellan 8% och 12%. Omvänt ger en 10% lyft med ett ±8%-igt konfidensintervall (från 2% till 18%) mycket mindre handlingsbar information. Bredden på konfidensintervallen beror på flera faktorer: urvalsstorlek (antal regioner), variation i utfall, testets längd och storleken på den förväntade effekten. Beräkningar av minsta detekterbara effekt (MDE) hjälper till att avgöra i förväg om din föreslagna experimentdesign kan pålitligt upptäcka den lyft du hoppas mäta. Poweranalys säkerställer att du har tillräcklig statistisk styrka—vanligtvis 80% eller mer—för att upptäcka verkliga effekter när de finns, samtidigt som du kontrollerar för typ I-fel (falska positiva) och typ II-fel (falska negativa).
Vanliga fallgropar och hur du undviker dem
Även välmenande GEO-experiment kan ge missvisande resultat om vanliga fallgropar inte noggrant undviks. Att förstå dessa fallgropar och implementera skyddsåtgärder är avgörande för tillförlitlig mätning.
Obalanserade grupper: När test- och kontrollregioner skiljer sig avsevärt åt på viktiga pre-behandlingsmått, gör den ökade variansen det svårt att upptäcka verkliga effekter. Åtgärd: Använd matchningsalgoritmer och syntetiska kontrollmetoder för att säkerställa att grupperna är statistiskt likvärdiga på alla viktiga dimensioner.
Spillover-effekter: Användare och mediakontakt respekterar inte geografiska gränser. Människor reser mellan regioner och digital annonsering kan nå målgrupper utanför avsedda områden. Åtgärd: Använd geografiska gränser som minimerar korskontaminering, ta hänsyn till pendlingsmönster och använd geofenceteknik för exakt kontroll.
Otillräcklig testlängd: Kampanjer behöver tid för att ge resultat och kundresor varierar i längd. Korta testperioder missar fördröjda konverteringseffekter och säsongsmönster. Åtgärd: Kör experiment i minst 4–6 veckor, längre för produkter med längre betänketid, och ta hänsyn till efterbehandlingsfönster.
Ändringar i analysplanen i efterhand: Att ändra din analysplan efter att ha sett preliminära resultat introducerar bias och ökar risken för falska positiva. Åtgärd: Fördefiniera din analysmetodik, KPI:er och framgångskriterier innan experimentet startar.
Att ignorera externa chocker: Naturkatastrofer, konkurrentaktiviteter, stora nyhetshändelser och ekonomiska skiften kan ogiltigförklara resultat. Åtgärd: Övervaka konfunderande händelser under hela testperioden och var beredd att förlänga eller göra om experimentet om betydande störningar uppstår.
Otillräcklig urvalsstorlek: För få regioner minskar statistisk styrka och ger breda konfidensintervall. Åtgärd: Gör poweranalys i förväg för att avgöra det minsta antal regioner som krävs för din förväntade effektstorlek.
Mäta inkrementalitet och lyft
Inkrementalitet representerar den sanna kausala effekten av marknadsföring—skillnaden mellan vad som faktiskt hände och vad som skulle ha hänt utan insatsen. Lyft är det kvantitativa måttet på denna inkrementalitet, beräknat som skillnaden i nyckelmått mellan test- och kontrollgrupper. Om testregioner genererade 1 000 000 kr i intäkter medan matchade kontrollregioner genererade 900 000 kr är den absoluta lyften 100 000 kr. Den procentuella lyften skulle vara 11,1% (100 000 / 900 000). Råa lyfttal tar dock inte hänsyn till kostnaden för marknadsföringsinsatsen. Inkrementell ROAS (iROAS) delar den inkrementella intäkten med den inkrementella utgiften och visar avkastningen för varje extra investerad krona. Om testregionen spenderade 50 000 kr extra på marknadsföring för att generera de 100 000 kr i inkrementella intäkter skulle iROAS vara 2,0x. På liknande sätt mäter inkrementell CAC (iCAC) kostnaden för att förvärva varje inkrementell kund, vilket är viktigt för att utvärdera effektiviteten i anskaffningskanaler. Dessa mått blir särskilt värdefulla kopplade till varumärkessynlighetsmätning—att förstå inte bara försäljningslyft, utan även hur marknadsföring påverkar AI-systemcitat och varumärkesomnämnanden över GPT:er, Perplexity och Google AI Overviews.
GEO-experiment för AI-synlighet och varumärkesövervakning
När AI-system blir primära upptäcktskanaler för konsumenter har det blivit avgörande att mäta hur marknadsföring påverkar varumärkessynlighet i AI-svar. GEO-experiment ger en rigorös ram för att testa olika innehållsstrategier och deras effekter på AI-citatsfrekvens och noggrannhet. Genom att genomföra experiment där vissa regioner får förbättrad innehållsoptimering för AI-synlighet—förbättrad strukturerad data, tydligare varumärkesbudskap, optimerade innehållsformat—medan kontrollregioner behåller grundläggande praxis, kan marknadsförare kvantifiera den inkrementella effekten på AI-omnämnanden. Detta är särskilt värdefullt för att förstå vilka innehållsformat, budskapsmetoder och informationsstrukturer AI-system föredrar när de citerar källor. AmICited övervakar dessa experiment genom att spåra hur ofta ditt varumärke förekommer i AI-genererade svar över olika geografiska regioner och tidsperioder och ger datagrunden för att mäta synlighetslyft. Inkrementaliteten i synlighetsförbättringar kan sedan kopplas till affärsresultat: visar regioner med högre AI-citatsfrekvens ökad webbtrafik, varumärkessökningar eller konverteringar? Denna koppling förvandlar AI-synlighet från en fåfängamått till en mätbar drivkraft för affärsresultat, vilket möjliggör säker budgetallokering till initiativ fokuserade på synlighet.
Avancerade metoder: Syntetisk kontroll och bayesianska angreppssätt
Utöver enkel difference-in-differences-analys har sofistikerade statistiska metoder utvecklats för att förbättra precisionen och tillförlitligheten i GEO-experiment. Den syntetiska kontrollmetoden konstruerar en viktad kombination av kontrollregioner som bäst matchar testregionernas förbehandlingsutveckling och skapar en mer exakt kontrafaktisk än någon enskild kontrollregion kan erbjuda. Detta tillvägagångssätt är särskilt kraftfullt när du har många potentiella kontrollregioner och vill utnyttja all tillgänglig information. Bayesianska strukturella tidsseriemodeller (BSTS), populariserade av Googles CausalImpact-paket, utökar syntetisk kontroll genom att införliva osäkerhetskvantifiering och probabilistisk prognos. BSTS-modeller lär sig det historiska sambandet mellan test- och kontrollregioner under förbehandlingsperioden och prognostiserar sedan hur testregionen skulle ha sett ut utan intervention. Skillnaden mellan faktiska och prognostiserade värden representerar den uppskattade behandlingseffekten, med trovärdighetsintervall som kvantifierar osäkerhet. Difference-in-differences (DiD)-analys jämför förändringen i resultat före och efter behandling mellan test- och kontrollgrupper och eliminerar effektivt tidinvarianta skillnader. Varje metod har kompromisser: syntetisk kontroll kräver många kontrollenheter men antar inte parallella trender; BSTS fångar komplexa tidsdynamiker men kräver noggrann modellering; DiD är enkel och intuitiv men känslig för brott mot antagandet om parallella trender. Moderna plattformar som Lifesight och Haus automatiserar dessa metoder, så att marknadsförare kan dra nytta av avancerad analys utan att kräva avancerad statistisk expertis.
Fallstudier från verkligheten och resultat
Ledande organisationer har visat GEO-experimentens styrka genom imponerande resultat. Wayfair utvecklade en heltalsoptimeringsmetod för att tilldela hundratals geografiska enheter till test- och kontrollgrupper samtidigt som de exakt balanserar flera KPI:er, vilket gjorde det möjligt för dem att köra känsligare experiment med mindre andel holdout. Polar Analytics’ analys av hundratals geo-tester visade att syntetiska kontrollmetoder ger resultat som är cirka 4 gånger mer precisa än enkla matchade marknadsmetoder, med snävare konfidensintervall som möjliggör säkrare beslutsfattande. Haus introducerade fasta geo-tester särskilt utformade för utomhus- och detaljhandelskampanjer, där marknadsförare inte kan slumpmässigt fördela regioner men behöver mäta effekten av förutbestämda geografiska utrullningar. Deras fallstudie med Jones Road Beauty visade hur fasta geo-tester exakt mätte den inkrementella effekten av billboardkampanjer i specifika marknader. Lifesights arbete med stora varumärken inom detaljhandel, CPG och DTC visar att automatiserade geo-testplattformar kan minska testlängden från 8–12 veckor till 4–6 veckor samtidigt som precisionen förbättras med avancerade matchningsalgoritmer. Dessa fallstudier visar konsekvent att korrekt utformade och genomförda GEO-experiment avslöjar oväntade insikter: kanaler som antas vara mycket effektiva visar ofta blygsam inkrementalitet, medan underinvesterade kanaler ofta visar stark inkrementell avkastning, vilket leder till betydande möjligheter till budgetomfördelning.
Implementering av GEO-experiment: Steg-för-steg-process
Att genomföra ett framgångsrikt GEO-experiment kräver systematisk genomförande över flera faser:
Definiera tydliga mål och KPI:er: Identifiera vad du vill mäta (intäkter, konverteringar, varumärkeskännedom, AI-citat) och sätt specifika, mätbara mål. Säkerställ att de är i linje med affärsprioriteringar och realistiska förväntningar på effektstorlek.
Välj och matcha geografiska regioner: Välj regioner som representerar din målmarknad och har tillräcklig datavolym. Använd matchningsalgoritmer för att identifiera kontrollregioner som speglar testregioner på historiska mått.
Säkerställ databereddhet: Kontrollera att du kan spåra KPI:er korrekt över alla regioner under testperioden. Genomför datagranskningar för att säkerställa kvalitet, fullständighet och konsistens.
Designa experimentparametrar: Bestäm testlängd (vanligtvis minst 4–6 veckor), specificera marknadsföringsinsatsen exakt och dokumentera alla antaganden och framgångskriterier innan du startar.
Utför kampanj samtidigt: Starta kampanjen i testregionerna och behåll baslinjeförhållanden i kontrollregionerna samtidigt. Samordna mellan team för att säkerställa konsekvent genomförande.
Övervaka under hela perioden: Spåra nyckelmått dagligen för att identifiera oväntade mönster, externa chocker eller implementationsproblem som kan äventyra resultaten.
Samla in och analysera data: Sammanställ data från alla regioner och tillämpa din fördefinierade analysmetodik. Beräkna lyft, konfidensintervall och sekundära mått.
Tolka resultaten noggrant: Utvärdera inte bara statistisk signifikans utan även praktisk betydelse. Beakta konfidensintervallens bredd, effektstorlek och affärspåverkan när du drar slutsatser.
Dokumentera och dela insikter: Skapa en omfattande rapport som dokumenterar metodik, resultat och lärdomar. Dela insikter med intressenter för att informera framtida strategi.
Planera nästa experiment: Använd lärdomarna för att informera nästa testomgång och bygg en kontinuerlig kultur av experimenterande och optimering.
Verktyg och plattformar för GEO-experiment
GEO-experimentlandskapet har utvecklats avsevärt och idag automatiserar specialiserade plattformar mycket av komplexiteten. Haus erbjuder GeoLift för standardiserade randomiserade geo-tester och Fixed Geo Tests för förutbestämda geografiska utrullningar, med särskild styrka inom omnichannel-mätning. Lifesight erbjuder automatisering från design till analys, med egna matchningsalgoritmer och syntetisk kontrollmetodik som minskar testlängden samtidigt som precisionen förbättras. Polar Analytics fokuserar på inkrementalitetstestning med tonvikt på kausal lyftmätning och konfidensintervallens noggrannhet. Paramark är specialiserade på marketing mix-modellering förstärkt med geo-experimentvalidering, vilket hjälper varumärken att kalibrera MMM-prognoser mot verkliga testresultat. När du utvärderar plattformar, leta efter: automatiserad regionmatchning och balansering, stöd för både digitala och offlinekanaler, realtidsövervakning och möjligheter till tidig avstängning, transparent metodik och rapportering av konfidensintervall samt integration med din befintliga datainfrastruktur. AmICited kompletterar dessa plattformar genom att tillhandahålla synlighetsmätning—spårar hur ditt varumärke förekommer i AI-genererade svar över test- och kontrollregioner, så att du kan mäta inkrementaliteten av synlighetsfokuserade marknadsinitiativ.
Best practices och rekommendationer
Lyckad GEO-experimentering kräver följande av beprövade best practices som maximerar tillförlitlighet och handlingsbarhet:
Börja med tydliga hypoteser: Definiera specifika, testbara hypoteser innan du startar experiment. Undvik fisketurer där flera variabler testas samtidigt utan tydliga förutsägelser.
Investera i korrekt gruppmatchning: Lägg tid på att säkerställa att test- och kontrollgrupper verkligen är jämförbara. Dålig matchning underminerar all efterföljande analys och slösar resurser.
Kör tester tillräckligt länge: Motstå frestelsen att avbryta i förtid när resultaten ser lovande ut. För tidigt avbrott introducerar bias och ökar risken för falska positiva. Fullfölj hela planerad period.
Övervaka konfunderande faktorer: Spåra aktivt externa händelser, konkurrentaktiviteter och marknadsförhållanden under hela testet. Var beredd att förlänga eller göra om experiment om betydande störningar inträffar.
Dokumentera allt: För detaljerade register över experimentdesign, genomförande, analys och resultat. Denna dokumentation möjliggör lärande, replikation och uppbyggnad av institutionell kunskap.
Bygg en testkultur: Gå bortom enstaka experiment till systematiska testprogram. Varje experiment ska informera nästa, och skapa en god cirkel av lärande och optimering.
Koppla till affärsresultat: Säkerställ att experiment mäter mått som direkt påverkar affärsmål. Undvik fåfängamått som inte leder till intäkter eller strategiska mål.
Vanliga frågor
Vad är skillnaden mellan GEO-experiment och A/B-testning?
GEO-experiment testar på geografisk/regional nivå för att mäta inkrementalitet av kampanjer som inte kan testas på individuell användarnivå, medan A/B-tester randomiserar individuella användare för digital optimering. GEO-experiment är bättre för offline-media, övre tratten-kampanjer och för att mäta verklig kausal påverkan, medan A/B-tester utmärker sig på att optimera digitala upplevelser med snabbare resultat.
Hur länge bör ett GEO-experiment pågå?
Vanligtvis minst 4–6 veckor, även om detta beror på din konverteringscykel och säsongsvariationer. Längre tester ger mer tillförlitliga resultat men högre kostnader. Testperioden bör vara tillräckligt lång för att fånga hela kundresan och ta hänsyn till fördröjda konverteringseffekter.
Vad är minsta marknadsstorlek för ett GEO-experiment?
Det finns ingen fast minsta nivå, men du behöver tillräcklig datavolym för att uppnå statistisk signifikans. Generellt behöver du tillräckligt många regioner och transaktioner för att kunna upptäcka din förväntade effektstorlek med tillräcklig statistisk styrka (vanligtvis 80% eller högre). Mindre marknader kräver längre testperioder.
Hur förhindrar man spillover mellan test- och kontrollregioner?
Använd geografiska gränser som minimerar korskontaminering, ta hänsyn till pendlingsmönster och mediakorsning, använd geofenceteknik för exakt kontroll och välj regioner som är geografiskt isolerade. Spillover-effekter uppstår när användare eller mediakontakt går mellan test- och kontrollregioner, vilket späder ut resultaten.
Vilken konfidensnivå bör jag sikta på för GEO-experiment?
Standard är 95% konfidens (p < 0,05), vilket innebär att du kan vara 95% säker på att den observerade effekten är verklig och inte beror på slumpen. Tänk dock på din affärskontext – kostnaden för falska positiva jämfört med falska negativa – när du bestämmer din konfidensnivå.
Kan GEO-experiment mäta varumärkeskännedom och AI-synlighet?
Ja, genom enkäter, varumärkeslyftstudier och AI-citatspårning. Du kan mäta hur marknadsföring påverkar varumärkeskännedom, välvilja och, viktigt nog, hur ofta ditt varumärke förekommer i AI-genererade svar över olika regioner, vilket möjliggör mätning av synlighetsinkrementalitet.
Hur påverkar externa händelser GEO-experiment?
Naturkatastrofer, konkurrentkampanjer, stora nyhetshändelser och ekonomiska förändringar kan ogiltigförklara resultat genom att introducera konfunderande variabler. Övervaka dessa under hela din testperiod och var beredd att förlänga testet eller göra om experimentet om betydande störningar inträffar.
Vad är ROI för att köra GEO-experiment?
GEO-experiment betalar sig vanligtvis själva genom att förhindra bortkastade utgifter på ineffektiva kanaler och möjliggöra säker budgetomfördelning till högpresterande taktiker. De ger grundläggande sanning som förbättrar all nedströmsmätning och beslutsfattande, från MMM-kalibrering till kanaloptimering.
Övervaka ditt varumärkes AI-synlighet med AmICited
GEO-experiment avslöjar hur din marknadsföring påverkar synlighet. AmICited spårar hur AI-system citerar ditt varumärke över GPT:er, Perplexity och Google AI Overviews, vilket hjälper dig att mäta den sanna inkrementaliteten av synlighetsförbättringar.
Hur testar du egentligen om din GEO-strategi fungerar? Söker mät-ramverk
Diskussion i communityt om att testa GEO-strategins effektivitet. Ramverk och metoder för att mäta om dina Generative Engine Optimization-insatser faktiskt fung...
Så bedömer du din GEO-mognad: Ramverk och utvärderingsguide
Lär dig utvärdera din GEO-mognad inom strategiska, innehållsmässiga, tekniska och auktoritetsdimensioner. Upptäck bedömningsramverk, mognadsnivåer och praktiska...
Hur du testar din GEO-strategis effektivitet: Viktiga mätvärden och verktyg
Lär dig hur du mäter GEO-strategins effektivitet med AI-synlighetspoäng, frekvens av attribution, engagemangsgrader och geografiska insikter om prestation. Uppt...
7 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.