
Vilken schema markup hjälper med AI-sök? Komplett guide för 2025
Upptäck vilka typer av schema markup som ökar din synlighet i AI-sökmotorer som ChatGPT, Perplexity och Gemini. Lär dig JSON-LD-implementeringsstrategier för AI...
9 min läsning

Lär dig vilka schema-typer som är viktigast för AI-synlighet. Upptäck hur LLM:er tolkar strukturerad data och implementera schema-strategier som får ditt varumärke citerat i AI-svar.
I flera år handlade schema markup främst om att vinna rika resultat – de där iögonfallande stjärnbetygen, produktkort och FAQ-ackordioner som visades i traditionella sökresultat. Idag håller den spelplanen på att bli föråldrad. Stora språkmodeller och AI-svarsmotorer tolkar schema markup på fundamentalt annorlunda sätt; de använder det inte för kosmetiska förbättringar utan för att bygga kunskapsgrafer och förstå entitetsrelationer i stor skala. Med cirka 45 miljoner webbplatser (12,4% av alla registrerade domäner) som nu använder någon form av schema.org-markup har AI-system tillgång till oöverträffade mängder strukturerad data att lära sig av och lita på. Skiftet är genomgripande: schema markup påverkar nu om ditt varumärke citeras i AI-genererade svar, hur korrekt modeller representerar dina produkter och tjänster, och om ditt innehåll blir en pålitlig källa i ett AI-först-söklanskap.
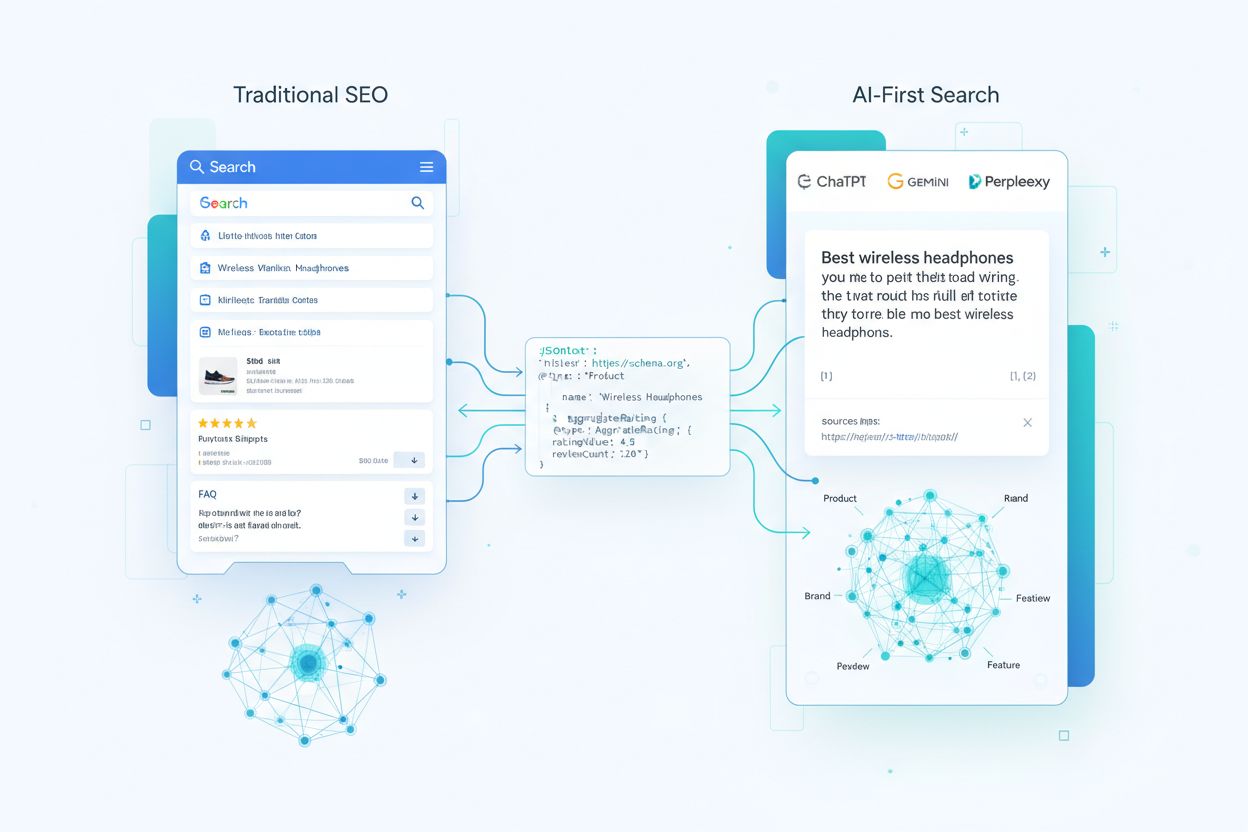
Att förstå hur AI-system konsumerar schema markup kräver att du följer din strukturerade datas resa från första crawl till LLM-genererade svar. När en crawler besöker din sida extraherar den JSON-LD, microdata eller RDFa-block och normaliserar dem till ett index tillsammans med ostrukturerad text och media. Denna strukturerade data blir en del av en webbaserad kunskapsgraf där entiteter kopplas samman via relationer och tilldelas embeddingar för semantisk sökning. I retrieval-augmented generation (RAG)-system kan schema vikas direkt in i de chunkar som fyller vektorindex – en enda chunk kan innehålla både en produktbeskrivning och dess JSON-LD-markup, vilket ger modellerna både narrativ kontext och strukturerade nyckel-värde-attribut. Olika LLM-arkitekturer konsumerar schema på olika sätt: vissa lägger lager ovanpå befintliga sökindex och kunskapsgrafer, medan andra använder pipelines som hämtar från både strukturerat och ostrukturerat innehåll. Den avgörande insikten är att välimplementerat schema fungerar som ett kontrakt med modellen, där du i högstrukturerad form anger vilka fakta på din sida som du betraktar som kanoniska och tillförlitliga.
| Arkitekturtyp | Användning av schema | Citatpåverkan | Viktiga egenskaper |
|---|---|---|---|
| Traditionell sök + LLM-lager | Förbättrar befintlig kunskapsgraf | Hög – modeller citerar välstrukturerade källor | Organization, Product, Article |
| Retrieval-Augmented Generation | Viks in i vektor-chunkar | Medelhög – schema hjälper till med precision | Alla typer med detaljerade egenskaper |
| Multi-Source Answer Engines | Används för entitetsupplösning | Medel – konkurrerar med andra signaler | Person, LocalBusiness, Service |
| Konversationell AI | Stödjer kontextförståelse | Varierande – beroende av träningsdata | FAQPage, HowTo, BlogPosting |
Alla schema-typer väger inte lika tungt i AI-eran. Organization-markup fungerar som ankare för hela din entitetsgraf och hjälper modeller förstå ditt varumärkes identitet, auktoritet och relationer. Product-schema är avgörande för e-handel och detaljhandel, så att AI-system kan jämföra funktioner, priser och betyg mellan olika källor. Article och BlogPosting-markup hjälper modeller identifiera långformade innehåll, lämpliga för förklarande frågor och thought leadership. Person-schema är kritiskt för att etablera författarens trovärdighet och expertattribution i AI-genererade svar. FAQPage-markup kartlägger direkt mot konversationella frågor som AI-assistenter är utformade för att besvara. För SaaS- och B2B-företag är SoftwareApplication och Service-typer lika viktiga och förekommer ofta i jämförelser som “bästa verktyg för X” och funktionsutvärderingar. För lokala företag och vårdgivare ger LocalBusiness och MedicalOrganization-typer geografisk precision och regulatorisk tydlighet. Den verkliga differentieringen kommer dock inte från grundläggande typanvändning utan från de avancerade egenskaper du lägger till ovanpå – konsekvens mellan sidor, tydliga entitetsidentifierare och explicit relationskartläggning.
Grundläggande schema-egenskaper som name, description och URL är numera ett minimikrav; 72,6% av sidorna som rankar på Googles första sida använder redan någon form av schema markup. De egenskaper som verkligen skapar skillnad för AI-synlighet är det bindväv som hjälper modeller att lösa entiteter, förstå relationer och särskilja betydelser. Här är de avancerade egenskaper som spelar störst roll:
Dessa egenskaper förvandlar schema från en enkel databehållare till en semantisk karta som modeller kan navigera med tillförsikt. När du använder sameAs för att länka din organisation till dess Wikipedia-sida lägger du inte bara till metadata – du säger till modellen “detta är den auktoritativa källan om oss.” När du använder additionalProperty för att koda produktspecifikationer eller tjänstefunktioner tillhandahåller du de exakta attribut AI-system letar efter när de bygger jämförelser eller rekommendationer.
De flesta organisationer ser schema markup som en engångsuppgift, men konkurrensfördel i AI-drivet sök kräver att man ser det som en löpande datastyrningsdisciplin. En användbar modell är en fyrastegs mognadstrappa som hjälper team förstå var de befinner sig och vad nästa steg är:
Nivå 1 – Grundläggande schema för rika resultat fokuserar på minimal markup på utvalda mallar, främst för att bli berättigad till stjärnor, produktkort eller FAQ-snippets. Styrningen är lös, konsekvensen låg och målet är kosmetisk förbättring snarare än semantisk tydlighet.
Nivå 2 – Entitetscentrerad täckning standardiserar Organization, Product, Article och Person-markup på viktiga mallar, inför konsekvent användning av @id-värden och lägger till grundläggande sameAs-länkar för att undvika entitetsförväxling.
Nivå 3 – Kunskapsgrafintegrerad schema anpassar schema-ID:n till interna datamodeller (CMS, PIM, CRM), använder about/mentions/additionalType-egenskaper i stor utsträckning och kodar relationsnät mellan sidor så att modeller förstår hur innehållsnoder hänger ihop med varandra och externa entiteter.
Nivå 4 – LLM-optimerad & RAG-anpassad schema strukturerar markup för konversationella frågor och AI-snippetformat, anpassar schema till interna RAG-pipelines och inkluderar mätning och iteration som kärnpraxis.
De flesta varumärken stannar idag på nivå 1–2, vilket innebär att grundläggande användning nu är hygienfaktor, inte differentiering. Att ta klivet till nivå 3–4 är där schema-LLM-optimering blir en varaktig konkurrensfördel, eftersom modeller då kan tolka dina entiteter tillförlitligt i många olika frågeformuleringar och ytor.
Olika branscher har olika entiteter, riskprofiler och användaravsikter, så avancerad schema-användning kan inte vara likadan överallt. Kärnprinciperna – entitetsklarhet, relationsmodellering och anpassning till on-page-innehåll – är konstanta, men de schema-typer och egenskaper du betonar bör återspegla hur folk faktiskt söker i din vertikal.
För e-handel och detaljhandel är de primära entiteterna Products, Offers, Reviews och din Organization. Varje produktsida med hög köppotential bör exponera detaljerad Product-markup som inkluderar identifierare (SKU, GTIN), varumärke, modell, mått, material och särskiljande attribut via additionalProperty. Kombinera detta med Offers för pris och tillgänglighet samt AggregateRating-strukturer som hjälper modeller förstå socialt bevis. Utöver grunderna, tänk på hur kunder formulerar frågor: “Är denna vattentät?”, “Ingår garanti?”, “Vad är returpolicyn?” Att koda dessa svar som FAQPage-markup på samma URL och se till att produktattribut och FAQ-innehåll är synkroniserade gör det mycket lättare för svarsmotorer att citera rätt sida.
För SaaS och B2B-tjänster är entiteterna mer abstrakta men passar väl med SoftwareApplication, Service och Organization-schema. För varje kärnprodukt eller erbjudande, definiera en SoftwareApplication eller Service-entitet med tydliga beskrivningar av kategori, stödda plattformar, integrationer och prismodeller – använd additionalProperty-fält för att räkna upp funktioner som ofta syns i “bästa verktyg för X”-jämförelser. Knyt dessa till din Organization via provider- eller offers-relationer och till dina experter via Person-markup. På innehållssidan hjälper Article, BlogPosting, FAQPage och HowTo-strukturer LLM:er att identifiera dina bästa tillgångar för utvärderande och utbildande frågor.
För lokala, vård- och reglerade branscher kan LocalBusiness, MedicalOrganization och relaterade MedicalEntity-typer koda adresser, verksamhetsområden, specialiteter, accepterade försäkringar och öppettider mycket mindre tvetydigt än fri text. Detta är viktigt när en AI-assistent får frågor som “hitta en barnkardiolog nära mig som accepterar min försäkring” eller “rekommendera en närakut som har öppet nu.” I dessa sektorer, var särskilt noga med att schema inte överdriver eller exponerar känsliga detaljer – markera bara fakta du är bekväm med att återanvändas i många sammanhang och säkerställ att compliance- och juridikgranskning sker för medicinska eller reglerade attribut.
LLM-beteende är i grunden stokastiskt, så du får inte perfekt attribution enbart från schema-ändringar. Vad du kan göra är att bygga ett lättviktigt övervakningssystem som regelbundet samplar AI-svar för en definierad fråga-uppsättning. Följ vilka entiteter som nämns, vilka URL:er som citeras, hur ditt varumärke beskrivs och om viktiga fakta (priser, kapabiliteter, compliance-detaljer) är korrekta på plattformar som ChatGPT, Gemini, Perplexity och Bing Copilot. När något går fel – hallucinerade funktioner, uteblivna omnämnanden eller citationer som gynnar aggregatorer över dina huvudsidor – börja med att leta efter motstridiga eller ofullständiga signaler. Säger on-page-texten något annat än schema? Saknas sameAs-länkar eller pekar de på föråldrade profiler? Hävdar flera sidor att de är kanonisk källa för samma entitet? Planera strategiskt en schema-granskning minst kvartalsvis för att anpassa till nya erbjudanden, innehållskluster och förändringar i hur AI-svarsmotorer visar ditt varumärke.
Flera mönster underminerar konsekvent schema-effektiviteten för AI-system. Att märka upp innehåll som inte faktiskt syns på sidan skapar ett förtroendegap – modeller lär sig att bortse från källor där schema och synligt innehåll skiljer sig. Att använda alltför generiska typer utan specificitet (t.ex. märka allt som “Thing” eller “CreativeWork”) ger ingen semantisk signal; modeller behöver precisa typer för att förstå kontext. Att kopiera standardschema mellan sidor utan att justera entitetsdetaljer är kanske det vanligaste misstaget – när varje produktsida har identisk Organization-markup eller varje artikel påstår sig ha samma författare får modeller svårt att särskilja och kan nedprioritera ditt innehåll som låg-signal. Inkonsekventa entitetsidentifierare mellan sidor (olika @id-värden för samma organisation eller produkt) bryter entitetsupplösning och tvingar modeller att behandla relaterat innehåll som separata entiteter. Saknade sameAs-länkar till auktoritativa profiler gör att modeller lättare förväxlar ditt varumärke med namnlika. Slutligen signalerar motstridig information mellan schema och on-page-text opålitlighet; om ditt schema säger att en produkt finns i lager men sidan säger “slut i lager” litar modeller på varken eller.
Schema markup håller på att gå från en kosmetisk SEO-taktik till en grundteknik för AI-först-sök. Sammanlänkad schema markup – där du uttryckligen definierar relationer mellan entiteter med egenskaper som sameAs, about och mentions – bygger kunskapsgrafer som AI-system kan navigera med förtroende. Konkurrensfördelen tillfaller inte längre den som frågar “Vilket minimischema behöver vi för rika resultat?” utan den som frågar “Vilken strukturerad representation skulle göra vårt innehåll otvetydigt för en maskin, även utanför SERP?” Detta skifte driver organisationer mot mer kompletta, sammankopplade och entitetscentrerade schema-mönster. När AI-drivet sök blir en primär upptäckskanal utvecklas schema-LLM-optimering från teknisk kuriositet till kärnkompetens inom SEO. Organisationer som avancerar genom mognadsnivåerna – från grundläggande schema för rika resultat till kunskapsgrafintegrerade och LLM-optimerade mönster – bygger varaktiga skyddsvallar i AI-baserad upptäckt och säkerställer att deras varumärken citeras som auktoriteter och att deras innehåll syns som pålitliga källor.
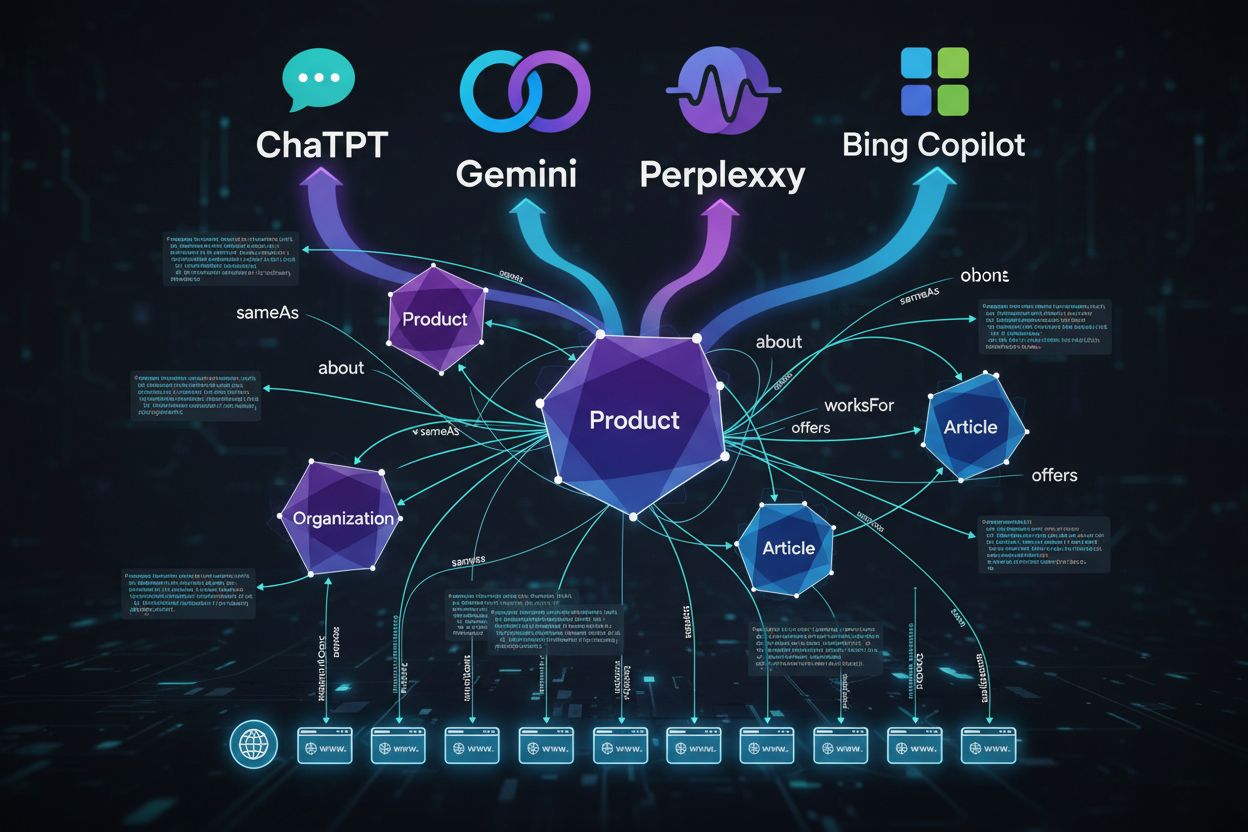
Traditionell schema fokuserade på rika resultat (stjärnor, snippets). För AI handlar schema om entitetsklarhet, relationer och kunskapsgrafer. AI-system använder schema för att förstå vad ditt innehåll handlar om på en semantisk nivå, inte bara för visuella förbättringar.
Organization, Product, Article, Person och FAQPage är grundläggande. För SaaS, lägg till SoftwareApplication och Service. För lokala/hälsovårdsföretag, lägg till LocalBusiness och MedicalOrganization. Vikten varierar beroende på bransch och användarens avsikt.
Nej. Börja med Organization och dina mest värdefulla sidor (produkter, tjänster, viktiga artiklar). Utöka täckningen gradvis utifrån din affärsmodell och där AI-svar skulle vara mest värdefulla.
Schema-ändringar kan påverka AI-citat inom några veckor, men sambandet är sannolikhetsbaserat. Planera för kvartalsvisa granskningar och kontinuerlig övervakning på flera AI-plattformar för att följa effekten.
sameAs länkar din entitet till kanoniska profiler (Wikipedia, LinkedIn) för att undvika förväxling med namnlika. about/mentions tydliggör vad din sida egentligen fokuserar på, vilket hjälper modeller att förstå nyanser och kontext.
Nej. Schema fungerar bäst när det samverkar med högkvalitativt, välstrukturerat on-page-innehåll. Modeller behöver både strukturerad data och narrativ kontext för att säkert kunna citera dina sidor.
Övervaka AI-svar på olika plattformar (ChatGPT, Gemini, Perplexity, Bing) för dina målsökningar. Följ entitetsomnämnanden, URL-citat, faktakorrekthet och varumärkesbeskrivning. Leta efter trender över veckor/månader.
JSON-LD är det rekommenderade formatet för de flesta fall. Det är enklare att implementera, underhålla och stör inte HTML. Microdata och RDFa är mindre vanliga i moderna implementationer.
Följ hur AI-system citerar ditt varumärke i ChatGPT, Gemini, Perplexity och Google AI Overviews. Få insikter om vilka schema-typer som driver synligheten.
Upptäck vilka typer av schema markup som ökar din synlighet i AI-sökmotorer som ChatGPT, Perplexity och Gemini. Lär dig JSON-LD-implementeringsstrategier för AI...
Schema markup är standardiserad kod som hjälper sökmotorer att förstå innehåll. Lär dig hur strukturerad data förbättrar SEO, möjliggör rika resultat och stöder...

Lär dig hur produktschema markup gör dina ehandelsprodukter synliga för AI-shoppingassistenter. Komplett guide till strukturerad data för ChatGPT, Perplexity oc...