
Token
Lär dig vad tokens är i språkmodeller. Tokens är grundläggande enheter för textbearbetning i AI-system och representerar ord, delord eller tecken som numeriska ...
10 min läsning

Utforska hur tokenbegränsningar påverkar AI-prestanda och lär dig praktiska strategier för innehållsoptimering, inklusive RAG, chunking och summeringstekniker.
Tokens är de grundläggande byggstenarna som AI-modeller använder för att bearbeta och förstå information. Istället för att arbeta med fullständiga ord eller meningar bryter stora språkmodeller ner text till mindre enheter som kallas tokens, vilka kan vara enskilda tecken, delord eller hela ord beroende på tokeniseringsalgoritmen. Varje token tilldelas ett unikt numeriskt ID som modellen använder internt för beräkningar. Denna tokeniseringsprocess är avgörande eftersom den gör det möjligt för AI-system att hantera indata av varierande längd effektivt och upprätthålla konsekvent bearbetning över olika typer av innehåll. Att förstå tokens är avgörande för alla som arbetar med AI-system, eftersom de direkt påverkar prestanda, kostnad och den kvalitet på resultat du kan uppnå.
Olika AI-modeller har mycket olika tokenbegränsningar, vilket definierar den maximala mängd information de kan hantera i en enskild förfrågan. Dessa begränsningar har utvecklats dramatiskt under de senaste åren, där nyare modeller stöder avsevärt större kontextfönster. Tokenbegränsningen omfattar både ingående tokens (din prompt och data) och utgående tokens (modellens svar), vilket skapar en gemensam budget som måste hanteras noggrant. Att förstå dessa begränsningar är avgörande för att välja rätt modell för ditt användningsfall och planera din applikationsarkitektur därefter.
| Modell | Tokenbegränsning | Huvudsakligt användningsområde | Kostnadsnivå |
|---|---|---|---|
| GPT-3.5 Turbo | 4 096 | Korta konversationer, snabba uppgifter | Låg |
| GPT-4 | 8 192 | Standardapplikationer, måttlig komplexitet | Medel |
| GPT-4 Turbo | 128 000 | Långa dokument, komplex analys | Hög |
| Claude 3.5 Sonnet | 200 000 | Utökade dokument, omfattande analys | Hög |
| Gemini 1.5 Pro | 1 000 000 | Massiva datamängder, hela böcker, videoanalys | Mycket hög |
Viktiga överväganden vid utvärdering av tokenbegränsningar:
Tokenbegränsningar skapar betydande begränsningar som direkt påverkar noggrannhet, tillförlitlighet och kostnadseffektivitet i AI-applikationer. Om du överskrider en modells tokenbegränsning misslyckas applikationen helt – det finns ingen gradvis försämring eller delvis bearbetning. Även om du håller dig inom gränserna kan naiva metoder som enkel trunkering allvarligt försämra prestandan genom att ta bort viktig kontext som modellen behöver för att generera korrekta svar. Detta är särskilt problematiskt inom områden som juridisk analys, medicinsk forskning och mjukvaruutveckling, där även en enda missad detalj kan leda till felaktiga slutsatser. Utmaningen blir ännu mer komplex eftersom olika typer av innehåll konsumerar tokens i olika takt – strukturerad data som kod eller JSON kräver betydligt fler tokens än vanlig engelsk text på grund av symboler och formatering.
Trunkering är den enklaste metoden för att hantera tokenbegränsningar – du klipper helt enkelt bort överflödigt innehåll när det överskrider modellens kapacitet. Även om detta är lätt att implementera medför metoden betydande risker. När du trunkerar text förlorar du oundvikligen information, och modellen har ingen möjlighet att veta vad som tagits bort. Detta kan leda till ofullständig analys, saknad kontext och hallucinationer där modellen genererar trovärdig men felaktig information för att fylla luckor i sin förståelse.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
En mer sofistikerad trunkeringsstrategi särskiljer mellan väsentligt och valfritt innehåll. Du kan prioritera nödvändiga element som aktuell användarfråga och kärninstruktioner, och sedan lägga till valfri kontext som konversationshistorik endast om utrymme tillåter. Denna metod bevarar kritisk information samtidigt som tokenbegränsningar respekteras.
Istället för att trunkera delar chunking upp ditt innehåll i mindre, hanterbara delar som kan bearbetas självständigt eller selektivt. Chunking med fast storlek delar upp text i lika stora segment, medan semantisk chunking använder embeddingar för att identifiera naturliga brytpunkter baserat på betydelse istället för godtyckliga tokenantal. Glidande fönster med överlappning bevarar kontext mellan chunkar och säkerställer att viktig information som sträcker sig över chunkgränser inte går förlorad.
Hierarkisk chunking skapar flera abstraktionsnivåer – enskilda stycken på lägsta nivå, avsnitt på nästa nivå och kapitel på högsta nivå. Denna metod möjliggör avancerade hämtningstekniker där du snabbt kan identifiera relevanta sektioner utan att behöva bearbeta hela dokumentet. I kombination med vektordatabaser och semantisk sökning blir chunking ett kraftfullt verktyg för att hantera stora kunskapsbaser samtidigt som relevans och noggrannhet bibehålls.
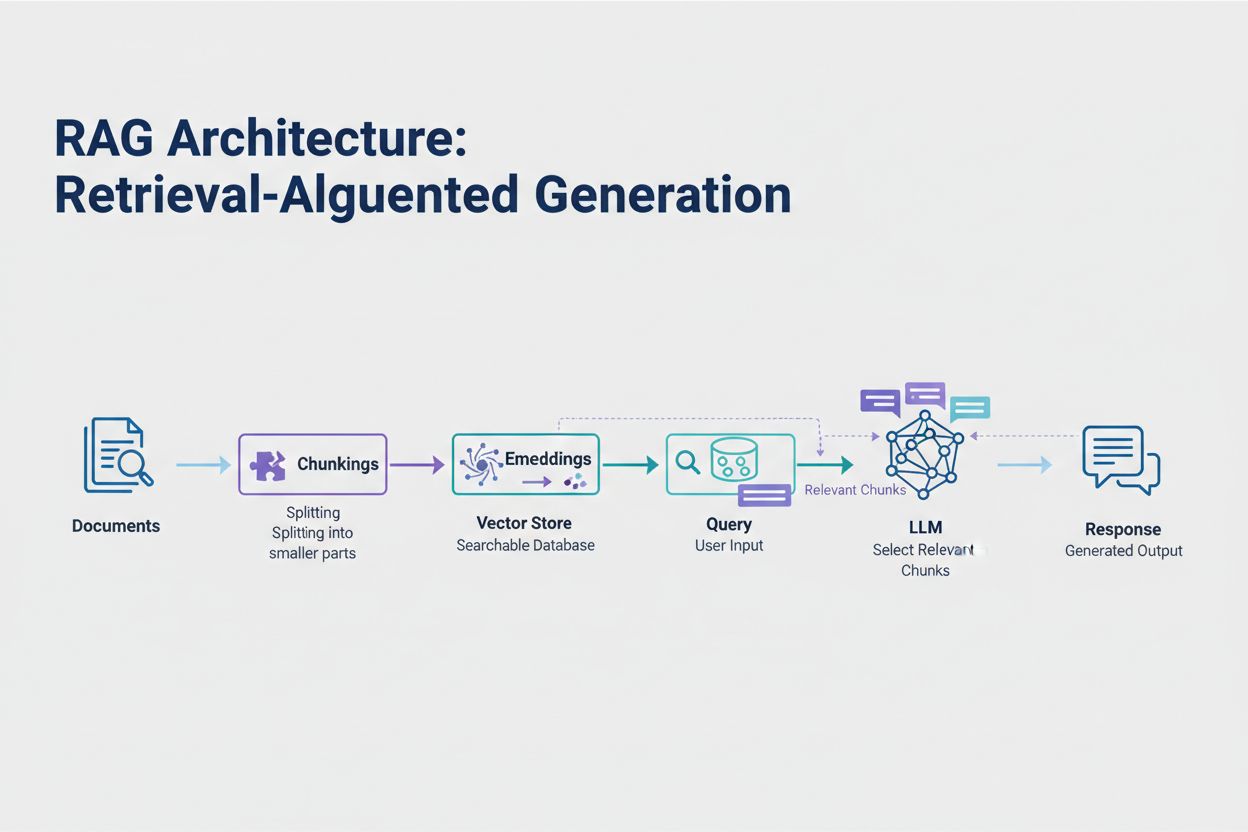
Retrieval-Augmented Generation (RAG) representerar det mest effektiva moderna sättet att hantera tokenbegränsningar. Istället för att försöka få plats med all din data i modellens kontextfönster hämtar RAG endast den mest relevanta informationen vid frågetillfället. Processen börjar med att dina dokument konverteras till embeddingar – numeriska representationer som fångar semantisk betydelse. Dessa embeddingar lagras i en vektordatabas, vilket möjliggör snabba likhetssökningar.
När en användare skickar en fråga omvandlas frågan till en embedding och de mest relevanta dokumentdelarna hämtas från vektorlagret. Endast dessa relevanta delar injiceras i prompten tillsammans med användarens fråga, vilket dramatiskt minskar tokenförbrukningen och samtidigt förbättrar noggrannheten. Till exempel kan analys av ett 100-sidigt juridiskt avtal med RAG kräva endast 3–5 nyckelparagrafer i prompten, jämfört med de tusentals tokens som annars krävs för att inkludera hela dokumentet.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
Summering kondenserar långa texter samtidigt som den väsentliga informationen bevaras, vilket effektivt minskar tokenförbrukningen. Extraktiv summering väljer ut nyckelmeningar från originaltexten, medan abstraktiv summering genererar ny, kortfattad text som fångar huvudidéerna. Hierarkisk summering skapar flera nivåer av sammanfattningar – först summeras enskilda avsnitt, sedan kombineras dessa till mer övergripande översikter. Denna metod fungerar särskilt bra för strukturerade dokument som forskningsartiklar eller tekniska rapporter.
Kontextkomprimering angriper problemet genom att ta bort redundans och utfyllnad medan den ursprungliga formuleringen bibehålls. Kunskapsgrafer extraherar entiteter och relationer ur texten och återskapar sedan kontext med endast de mest relevanta fakta. Dessa tekniker kan ge en tokenreduktion på 40–60% samtidigt som den semantiska noggrannheten bibehålls, vilket gör dem värdefulla för kostnadsoptimering i produktsystem.
Tokenhantering påverkar direkt kostnaderna för din AI-applikation. Varje token som används under inferens medför en avgift, och kostnaderna ökar linjärt med tokenanvändningen. Att övervaka tokenförbrukningen är avgörande för att förstå din kostnadsstruktur och identifiera optimeringsmöjligheter. Många AI-plattformar erbjuder nu verktyg för tokenräkning och realtidsdashboards som spårar användningsmönster och hjälper dig att identifiera vilka frågor eller funktioner som förbrukar mest tokens.
Effektiv övervakning avslöjar optimeringsmöjligheter – kanske överskrider vissa frågetyper konsekvent tokenbegränsningar eller så förbrukar specifika funktioner oproportionerligt mycket resurser. Genom att spåra dessa mönster kan du fatta informerade beslut om vilken optimeringsstrategi du ska implementera. Vissa applikationer tjänar på att dirigera stora förfrågningar till mer kapabla (men dyrare) modeller, medan andra tjänar mer på att implementera RAG eller summering. Nyckeln är att mäta faktisk prestanda och kostnader för att validera dina optimeringsval.
Att välja rätt strategi för tokenhantering beror på ditt specifika användningsfall, prestandakrav och kostnadsbegränsningar. Applikationer som kräver hög noggrannhet med källhänvisade svar tjänar mest på RAG, som bevarar informationskvalitet och hanterar tokenförbrukningen. Långvariga konversationsapplikationer gynnas av minnesbuffringstekniker som summerar konversationshistorik men bevarar viktiga beslut och kontext. Dokumenttunga applikationer som juridisk analys eller forskning drar ofta nytta av hierarkisk summering i kombination med semantisk chunking.
Testning och validering är avgörande innan någon tokenhanteringsstrategi tas i produktion. Skapa testfall som överskrider din modells tokenbegränsningar och utvärdera sedan hur olika strategier påverkar noggrannhet, latens och kostnad. Mät mått som svarens relevans, saklig noggrannhet och tokeneffektivitet för att säkerställa att den valda metoden möter dina krav. Vanliga fallgropar inkluderar för aggressiv summering som förlorar viktiga detaljer, hämtning som missar relevanta uppgifter och chunkingstrategier som delar upp innehåll på semantiskt olämpliga ställen.
Tokenbegränsningar fortsätter att öka i takt med att modeller blir mer sofistikerade och effektiva. Nya tekniker som sparsamma attention-mekanismer och effektiva transformatorer lovar att minska de beräkningskostnader som krävs för att bearbeta stora kontextfönster. Multimodala modeller som hanterar text, bilder, ljud och video samtidigt introducerar nya utmaningar och möjligheter för tokenisering. “Resonemangstokens” – speciella tokens som modeller använder för att “tänka igenom” komplexa problem – representerar en ny kategori av tokenförbrukning som möjliggör mer avancerad problemlösning men kräver noggrann hantering.
Utvecklingen är tydlig: i takt med att kontextfönster växer och tokenbearbetningen blir effektivare flyttas flaskhalsen från ren kapacitet till intelligent innehållsurval. Framtiden tillhör system som effektivt kan identifiera och hämta den mest relevanta informationen ur massiva kunskapsbaser, snarare än system som bara bearbetar större datamängder. Detta gör tekniker som RAG och semantisk sökning allt viktigare för att bygga skalbara, kostnadseffektiva AI-applikationer.
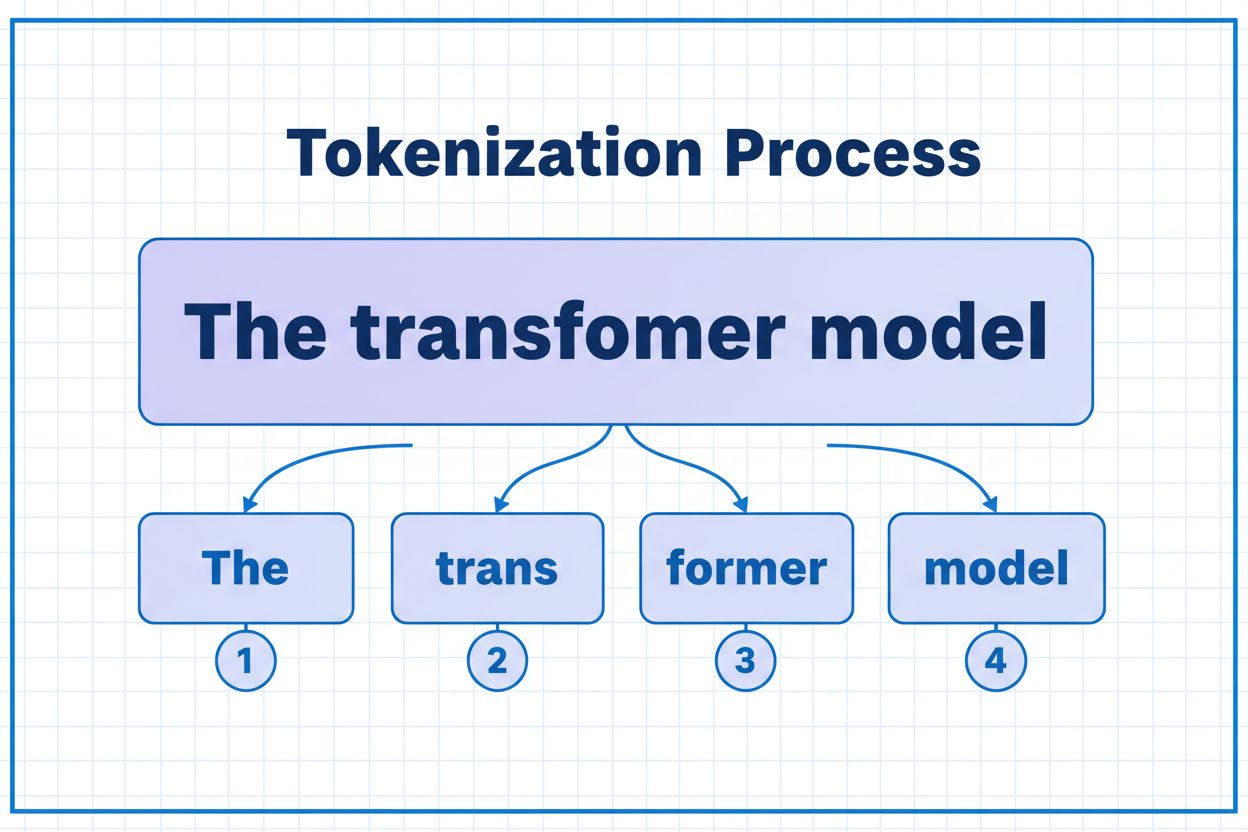
En token är den minsta dataenhet som en AI-modell bearbetar. Tokens kan vara enskilda tecken, delord eller hela ord beroende på vilken tokeniseringsalgoritm som används. Till exempel kan ordet 'transformer' delas upp i 'trans' och 'former' som två separata tokens. Varje token tilldelas ett unikt numeriskt ID som modellen använder internt för beräkningar.
Tokenbegränsningar definierar den maximala mängd information som din AI-modell kan bearbeta i en enskild förfrågan. Om du överskrider denna gräns misslyckas din applikation helt. Även om du håller dig inom gränserna kan naiva metoder som trunkering försämra noggrannheten genom att ta bort viktig kontext. Tokenbegränsningar påverkar även kostnader direkt, eftersom du vanligtvis betalar per förbrukad token.
Ingående tokens är de tokens som finns i din prompt och data som du skickar till modellen, medan utgående tokens är de tokens modellen genererar i sitt svar. Dessa delar på en gemensam budget som definieras av modellens kontextfönster. Om din indata upptar 90% av ett 128K-tokenfönster återstår endast 10% för modellens utdata.
Trunkering är enkelt att implementera men riskabelt. Det tar bort information utan att modellen vet vad som saknas, vilket leder till ofullständig analys och potentiella hallucinationer. Även om det kan vara användbart i nödfall är bättre metoder som RAG, chunking eller summering mer effektiva för att bevara informationskvalitet och hantera tokenförbrukning.
Retrieval-Augmented Generation (RAG) hämtar endast den mest relevanta informationen vid frågetillfället istället för att inkludera hela dokument. Dina dokument konverteras till embeddingar och lagras i en vektordatabas. När en användare ställer en fråga hämtar systemet endast relevanta delar och injicerar dem i prompten, vilket minskar tokenförbrukningen dramatiskt och förbättrar noggrannheten.
De flesta AI-plattformar erbjuder verktyg för tokenräkning och realtidsdashboards för att spåra användningsmönster. Övervaka vilka frågor eller funktioner som förbrukar flest tokens och implementera sedan optimeringsstrategier som RAG för dokumenttunga applikationer, summering för långa konversationer eller dirigera till större modeller för komplexa uppgifter. Mät faktisk prestanda och kostnader för att validera dina val.
AI-tjänster debiterar vanligtvis per förbrukad token. Kostnaderna ökar linjärt med tokenanvändningen, vilket gör tokenoptimering direkt avgörande för dina utgifter. En minskning av tokenförbrukningen med 20% ger en kostnadsminskning på 20%. Genom att förstå tokeneffektivitet kan du välja rätt optimeringsstrategi utifrån dina budgetbegränsningar.
Tokenbegränsningar fortsätter att öka i takt med att modeller blir mer avancerade. Nya tekniker som sparsamma uppmärksamhetsmekanismer förväntas minska beräkningskostnaderna för att hantera stora kontexter. Framtiden fokuserar på intelligent innehållsurval och hämtning snarare än ren bearbetningskapacitet, vilket gör tekniker som RAG allt viktigare för skalbara AI-applikationer.
Förstå tokeneffektivitet och spåra hur AI-modeller citerar ditt varumärke med AmICiteds omfattande plattform för AI-citationsövervakning.
Lär dig vad tokens är i språkmodeller. Tokens är grundläggande enheter för textbearbetning i AI-system och representerar ord, delord eller tecken som numeriska ...

Lär dig hur AI-modeller bearbetar text genom tokenisering, inbäddningar, transformerblock och neurala nätverk. Förstå hela processen från indata till utdata....
Lär dig viktiga strategier för att optimera ditt supportinnehåll för AI-system som ChatGPT, Perplexity och Google AI Overviews. Upptäck bästa praxis för tydligh...