Den strategiska praktiken att selektivt tillåta eller blockera AI-crawlers för att kontrollera hur innehåll används för träning kontra realtidsåtervinning. Detta innebär att använda robots.txt-filer, servernivåkontroller och övervakningsverktyg för att hantera vilka AI-system som kan komma åt ditt innehåll och för vilka ändamål.
AI-crawlerhantering
Den strategiska praktiken att selektivt tillåta eller blockera AI-crawlers för att kontrollera hur innehåll används för träning kontra realtidsåtervinning. Detta innebär att använda robots.txt-filer, servernivåkontroller och övervakningsverktyg för att hantera vilka AI-system som kan komma åt ditt innehåll och för vilka ändamål.
Vad är AI-crawlerhantering?
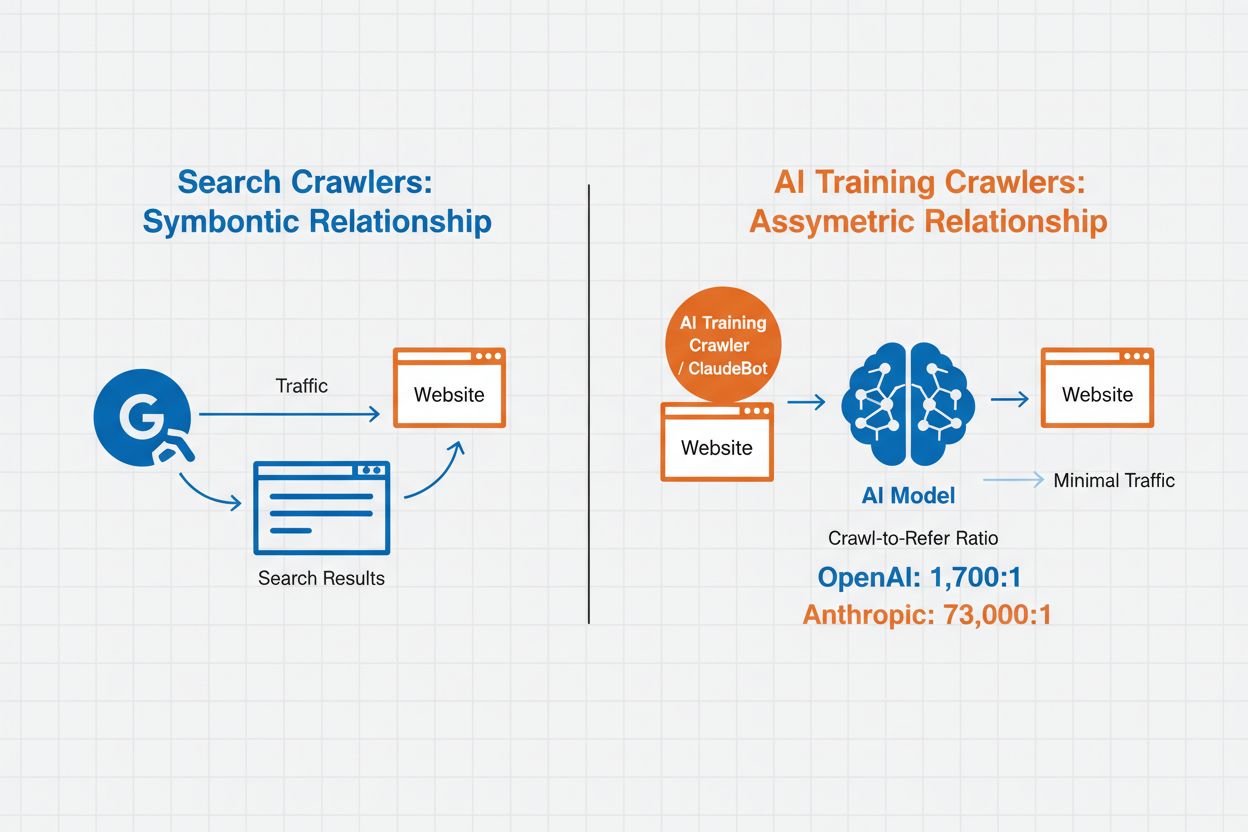
AI-crawlerhantering syftar på praktiken att kontrollera och övervaka hur artificiella intelligenssystem får tillgång till och använder webbplatsinnehåll för tränings- och sökändamål. Till skillnad från traditionella sökmotorcrawlers som indexerar innehåll för webbsökresultat är AI-crawlers specifikt utformade för att samla data för träning av stora språkmodeller eller för att driva AI-baserade sökfunktioner. Omfattningen på denna aktivitet varierar kraftigt mellan organisationer—OpenAI:s crawlers har ett crawl-to-refer-förhållande på 1 700:1, vilket betyder att de hämtar innehåll 1 700 gånger för varje referens de ger, medan Anthropics förhållande når 73 000:1, vilket belyser den enorma datamängd som krävs för att träna moderna AI-system. Effektiv crawlerhantering låter webbplatsägare avgöra om deras innehåll ska bidra till AI-träning, synas i AI-sökresultat eller förbli skyddat mot automatiserad åtkomst.
Typer av AI-crawlers
AI-crawlers delas in i tre tydliga kategorier baserat på syfte och datamönster. Träningscrawlers är utformade för att samla in data för utveckling av maskininlärningsmodeller och konsumerar stora mängder innehåll för att förbättra AI:s förmågor. Sök- och citeringscrawlers indexerar innehåll för att driva AI-baserade sökfunktioner och ge källhänvisning i AI-genererade svar, vilket möjliggör att användare hittar ditt innehåll via AI-gränssnitt. Användarinitierade crawlers körs på begäran när användare interagerar med AI-verktyg, till exempel när en ChatGPT-användare laddar upp ett dokument eller begär analys av en viss webbsida. Att förstå dessa kategorier hjälper dig att fatta informerade beslut om vilka crawlers du ska tillåta eller blockera utifrån din innehållsstrategi och affärsmål.
Crawlertyp
Syfte
Exempel
Använder träningsdata
Träning
Modellutveckling och förbättring
GPTBot, ClaudeBot
Ja
Sök/Citering
AI-sökresultat och källhänvisning
Google-Extended, OAI-SearchBot, PerplexityBot
Varierar
Användarinitierad
Analys av innehåll på begäran
ChatGPT-User, Meta-ExternalAgent, Amazonbot
Kontextsberoende
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
AI-crawlerhantering påverkar direkt din webbplatstrafik, intäkter och innehållets värde. När crawlers konsumerar ditt innehåll utan ersättning förlorar du möjligheten att dra nytta av trafiken genom hänvisningar, annonsvisningar eller användarinteraktion. Webbplatser har rapporterat betydande trafikminskningar när användare hittar svar direkt i AI-genererade svar istället för att klicka vidare till ursprungskällan, vilket i praktiken eliminerar hänvisningstrafik och tillhörande annonsintäkter. Utöver de ekonomiska aspekterna finns viktiga juridiska och etiska överväganden—ditt innehåll är din immateriella egendom och du har rätt att kontrollera hur det används och om du får källhänvisning eller ersättning. Dessutom kan obegränsad crawleråtkomst öka serverbelastning och bandbreddskostnader, särskilt från crawlers med aggressiva crawl-hastigheter som inte respekterar begränsningar.
Robots.txt och tekniska kontroller
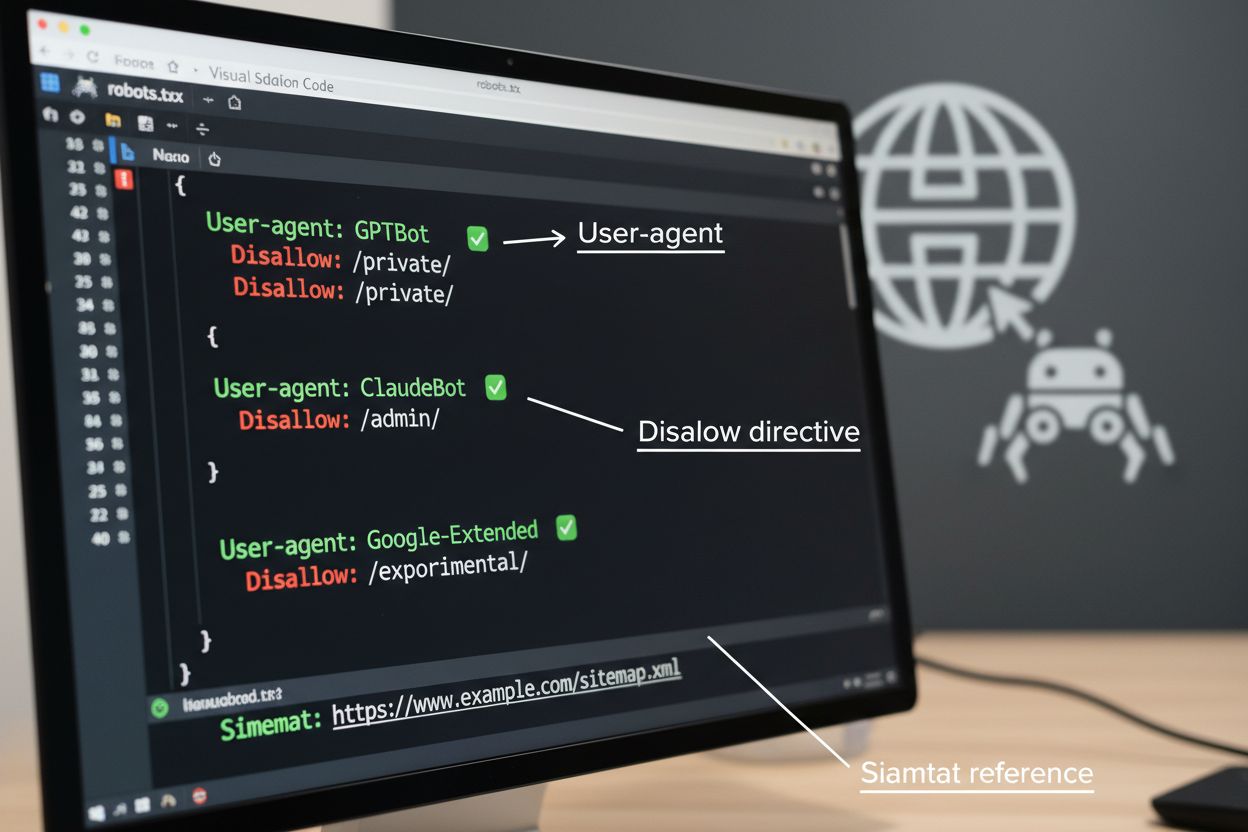
robots.txt-filen är det grundläggande verktyget för att hantera crawleråtkomst, placerad i webbplatsens rotkatalog för att kommunicera crawl-preferenser till automatiserade agenter. Denna fil använder User-agent-direktiv för att rikta in sig på specifika crawlers och Disallow- eller Allow-regler för att tillåta eller begränsa åtkomst till särskilda sökvägar och resurser. Dock har robots.txt viktiga begränsningar—det är en frivillig standard som bygger på crawlerns efterlevnad och illvilliga eller dåligt utformade bots kan ignorera den helt. Dessutom hindrar inte robots.txt crawlers från att komma åt offentligt tillgängligt innehåll; det begär bara att de respekterar dina önskemål. Av dessa skäl bör robots.txt vara en del av ett lagerbaserat tillvägagångssätt för crawlerhantering och inte ditt enda skydd.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Avancerade kontrollmetoder
Utöver robots.txt finns flera avancerade tekniker som ger starkare efterlevnad och mer detaljerad kontroll över crawleråtkomst. Dessa metoder verkar på olika nivåer i din infrastruktur och kan kombineras för ett heltäckande skydd:
.htaccess-regler: Servernivådirektiv som kan blockera specifika user agents eller IP-intervall innan innehåll levereras
IP-vitlistning/blocklista: Begränsa åtkomst baserat på IP-adresser kopplade till kända AI-crawlers, men detta kräver underhåll av uppdaterade IP-listor
Cloudflare WAF-lösningar: Använd brandväggsregler för webbapplikationer för att identifiera och blockera crawlertrafik baserat på beteendemönster och signaturer
HTTP-rubriker (X-Robots-Tag): Skicka crawlerdirektiv direkt i svarsheaders, vilket ger sid- eller resursbaserad kontroll som är svårare att ignorera än robots.txt
Begränsning av hastighet (rate limiting): Implementera aggressiva begränsningar på crawlertrafik för att göra storskalig datainsamling ekonomiskt omöjlig
Bot-fingeravtryck: Analysera begärandemönster, headers och beteende för att identifiera sofistikerade crawlers som utger sig för att vara något annat
Balansera skydd med synlighet
Beslutet att blockera AI-crawlers innebär viktiga kompromisser mellan innehållsskydd och synlighet. Att blockera alla AI-crawlers eliminerar möjligheten att ditt innehåll visas i AI-sökresultat, AI-genererade sammanfattningar eller citeras av AI-verktyg—vilket kan minska synligheten för användare som upptäcker innehåll via dessa nya kanaler. Å andra sidan innebär obegränsad åtkomst att ditt innehåll används för AI-träning utan ersättning och kan minska hänvisningstrafiken när användare får svar direkt från AI-system. En strategisk metod innebär selektiv blockering: tillåt citeringsbaserade crawlers som OAI-SearchBot och PerplexityBot som ger hänvisningstrafik, men blockera träningscrawlers som GPTBot och ClaudeBot som konsumerar data utan källhänvisning. Du kan även överväga att tillåta Google-Extended för att bibehålla synlighet i Google AI Overviews, vilket kan driva betydande trafik, samtidigt som du blockerar konkurrenters träningscrawlers. Den optimala strategin beror på din innehållstyp, affärsmodell och målgrupp—nyhetsmedier och publicister kanske prioriterar blockering, medan utbildningsinnehållsskapare kan gynnas av bredare AI-synlighet.
Övervakning och efterlevnad
Att implementera crawlerkontroller är endast effektivt om du verifierar att crawlers faktiskt följer dina direktiv. Serverloggsanalys är den primära metoden för att övervaka crawleraktivitet—granska dina accessloggar efter User-Agent-strängar och begärandemönster för att identifiera vilka crawlers som besöker din sida och om de respekterar dina robots.txt-regler. Många crawlers hävdar att de följer reglerna men fortsätter att komma åt blockerade sökvägar, vilket gör kontinuerlig övervakning avgörande. Verktyg som Cloudflare Radar ger realtidsöversikt över trafikmönster och kan hjälpa dig att identifiera misstänkt eller icke-efterlevande crawlerbeteende. Ställ in automatiska varningar för försök att komma åt blockerade resurser och granska regelbundet dina loggar för att upptäcka nya crawlers eller förändrade mönster som kan tyda på försök att kringgå skydd.
Bästa praxis och implementering
Effektiv AI-crawlerhantering kräver ett systematiskt tillvägagångssätt som balanserar skydd med strategisk synlighet. Följ dessa åtta steg för att etablera en omfattande strategi för crawlerhantering:
Granska nuvarande åtkomst: Analysera dina serverloggar för att identifiera vilka AI-crawlers som för närvarande besöker din sida, deras frekvens och vilka resurser de riktar in sig på
Definiera din policy: Bestäm vilka crawlers som stämmer överens med dina affärsmål—beakta tränings- kontra sökcrawlers, trafikpåverkan och innehållsvärde
Dokumentera dina beslut: Skapa tydlig dokumentation över din crawlerpolicy och motiveringarna bakom varje beslut för framtida referens och teamets samsyn
Implementera kontroller: Tillämpa robots.txt-regler, HTTP-rubriker och avancerade kontroller som rate limiting eller IP-blockering utifrån din policy
Övervaka efterlevnad: Granska regelbundet serverloggar och använd övervakningsverktyg för att säkerställa att crawlers följer dina direktiv
Skapa varningar: Konfigurera automatiska varningar för icke-efterlevande crawleråtkomst eller försök att kringgå dina kontroller
Granska kvartalsvis: Ompröva din strategi för crawlerhantering varje kvartal i takt med att nya crawlers dyker upp och dina affärsbehov förändras
Uppdatera när nya crawlers tillkommer: Håll dig informerad om nya AI-crawlers och uppdatera dina kontroller proaktivt snarare än reaktivt
AmICited.com: Övervaka dina AI-referenser
AmICited.com tillhandahåller en specialiserad plattform för att övervaka hur AI-system refererar till och använder ditt innehåll över olika modeller och applikationer. Tjänsten erbjuder realtidsspårning av dina källhänvisningar i AI-genererade svar, vilket ger dig insikt om vilka crawlers som mest aktivt använder ditt innehåll och hur ofta ditt material förekommer i AI-resultat. Genom att analysera crawlermönster och citeringsdata möjliggör AmICited.com datadrivna beslut om din strategi för crawlerhantering—du kan se exakt vilka crawlers som ger värde genom källhänvisningar och hänvisningstrafik, jämfört med de som konsumerar innehåll utan attribution. Denna intelligens omvandlar crawlerhantering från en defensiv åtgärd till ett strategiskt verktyg för att optimera ditt innehålls synlighet och genomslag i den AI-drivna webben.
Vanliga frågor
Vad är skillnaden mellan att blockera AI-träningscrawlers och sökcrawlers?
Träningscrawlers som GPTBot och ClaudeBot samlar in innehåll för att bygga dataset till stora språkmodeller, och använder ditt innehåll utan att ge någon hänvisningstrafik. Sökmotorcrawlers som OAI-SearchBot och PerplexityBot indexerar innehåll för AI-driven sökresultat och kan skicka besökare tillbaka till din sida via källhänvisningar. Att blockera träningscrawlers skyddar ditt innehåll från att användas i AI-modeller, medan blockering av sökcrawlers kan minska din synlighet i AI-drivna upptäcktsplattformar.
Kommer blockering av AI-crawlers att skada mina SEO-rankningar?
Nej. Blockering av AI-träningscrawlers som GPTBot, ClaudeBot och CCBot påverkar inte dina Google- eller Bing-sökrankningar. Traditionella sökmotorer använder andra crawlers (Googlebot, Bingbot) som fungerar oberoende av AI-träningsbotar. Blockera endast traditionella sökcrawlers om du vill försvinna helt från sökresultaten, vilket skulle skada din SEO.
Hur vet jag vilka crawlers som besöker min webbplats?
Granska dina serverloggar för att identifiera crawler User-Agent-strängar. Leta efter poster som innehåller 'bot', 'crawler' eller 'spider' i User-Agent-fältet. Verktyg som Cloudflare Radar ger realtidsöversikt över vilka AI-crawlers som besöker din sida och deras trafikmönster. Du kan även använda analysplattformar som särskiljer bottrafik från mänskliga besökare.
Kan AI-crawlers ignorera robots.txt-direktiv?
Ja. robots.txt är en rådgivande standard som bygger på att crawlers följer den—den är inte tvingande. Skötsamma crawlers från stora aktörer som OpenAI, Anthropic och Google respekterar vanligtvis robots.txt-direktiv, men vissa crawlers ignorerar dem helt. För starkare skydd, implementera servernivåblockering via .htaccess, brandväggsregler eller IP-baserade restriktioner.
Ska jag blockera alla AI-crawlers eller använda selektiv blockering?
Detta beror på dina affärsprioriteringar. Blockering av alla träningscrawlers skyddar ditt innehåll från att användas i AI-modeller, men kan tillåta sökcrawlers som kan ge hänvisningstrafik. Många publicister använder selektiv blockering som riktar sig mot träningscrawlers men tillåter sök- och citeringscrawlers. Tänk på din innehållstyp, trafikkällor och intäktsmodell när du bestämmer din strategi.
Hur ofta bör jag uppdatera min policy för crawlerhantering?
Granska och uppdatera din policy för crawlerhantering minst en gång per kvartal. Nya AI-crawlers dyker regelbundet upp, och befintliga crawlers uppdaterar sina user agents utan förvarning. Följ resurser som ai.robots.txt-projektet på GitHub för community-drivna listor, och kontrollera dina serverloggar varje månad för att identifiera nya crawlers som besöker din webbplats.
Vilken påverkan har AI-crawlers på min webbplatstrafik och intäkter?
AI-crawlers kan påverka din trafik och intäkter avsevärt. När användare får svar direkt från AI-system istället för att besöka din sida, förlorar du hänvisningstrafik och tillhörande annonsvisningar. Forskning visar crawl-to-refer-kvoter på upp till 73 000:1 för vissa AI-plattformar, vilket innebär att de besöker ditt innehåll tusentals gånger för varje besökare de skickar tillbaka. Blockering av träningscrawlers kan skydda din trafik, medan tillåtande av sökcrawlers kan ge vissa hänvisningsfördelar.
Hur kan jag verifiera att min robots.txt-konfiguration fungerar?
Kontrollera dina serverloggar för att se om blockerade crawlers fortfarande förekommer i dina accessloggar. Använd testverktyg som Google Search Consoles robots.txt-tester eller Merkle's Robots.txt Tester för att validera din konfiguration. Gå direkt till din robots.txt-fil på dinwebbplats.se/robots.txt för att säkerställa att innehållet är korrekt. Övervaka dina loggar regelbundet för att fånga crawlers som borde blockeras men ändå förekommer.
Övervaka hur AI-system refererar till ditt innehåll
AmICited.com spårar AI-referenser till ditt varumärke i realtid via ChatGPT, Perplexity, Google AI Overviews och andra AI-system. Fatta datadrivna beslut om din strategi för crawlerhantering.
Hur du Identifierar AI-crawlers i Serverloggar: Komplett Guide för Upptäckt
Lär dig identifiera och övervaka AI-crawlers som GPTBot, PerplexityBot och ClaudeBot i dina serverloggar. Upptäck user-agent-strängar, IP-verifieringsmetoder oc...
Hur du Tillåter AI-botar att Crawla din Webbplats: Komplett robots.txt & llms.txt-guide
Lär dig hur du tillåter AI-botar som GPTBot, PerplexityBot och ClaudeBot att crawla din webbplats. Konfigurera robots.txt, ställ in llms.txt och optimera för AI...
Vilka AI-crawlers bör jag tillåta? Komplett guide för 2025
Lär dig vilka AI-crawlers du ska tillåta eller blockera i din robots.txt. Omfattande guide som täcker GPTBot, ClaudeBot, PerplexityBot och 25+ AI-crawlers med k...
10 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.