
Hur du hanterar duplicerat innehåll för AI-sökmotorer
Lär dig hur du hanterar och förebygger duplicerat innehåll när du använder AI-verktyg. Upptäck kanoniska taggar, omdirigeringar, verktyg för upptäckt och bästa ...
11 min läsning
AI-deduplikationslogik avser de automatiserade processer och algoritmer som AI-system använder för att identifiera, analysera och eliminera redundanta eller dubblerade uppgifter från flera källor. Dessa system använder maskininlärning, naturlig språkbehandling och likhetsmatchningstekniker för att känna igen identiskt eller mycket likartat innehåll över olika datalager, vilket säkerställer datakvalitet, minskar lagringskostnader och förbättrar beslutsfattandets noggrannhet.
AI-deduplikationslogik avser de automatiserade processer och algoritmer som AI-system använder för att identifiera, analysera och eliminera redundanta eller dubblerade uppgifter från flera källor. Dessa system använder maskininlärning, naturlig språkbehandling och likhetsmatchningstekniker för att känna igen identiskt eller mycket likartat innehåll över olika datalager, vilket säkerställer datakvalitet, minskar lagringskostnader och förbättrar beslutsfattandets noggrannhet.
AI-deduplikationslogik är en sofistikerad algoritmisk process som identifierar och eliminerar dubbletter eller nästan identiska poster från stora datamängder med hjälp av artificiell intelligens och maskininlärningstekniker. Denna teknik upptäcker automatiskt när flera poster representerar samma entitet—oavsett om det är en person, produkt, ett dokument eller en informationsbit—trots variationer i formatering, stavning eller presentation. Huvudsyftet med deduplikation är att upprätthålla dataintegritet och förhindra redundans som kan snedvrida analyser, öka lagringskostnader och försämra beslutsfattandets noggrannhet. I dagens datadrivna värld, där organisationer hanterar miljontals poster dagligen, har effektiv deduplikation blivit avgörande för operativ effektivitet och tillförlitliga insikter.
AI-deduplikation använder flera kompletterande tekniker för att identifiera och gruppera liknande poster med imponerande precision. Processen börjar med att analysera dataattribut—såsom namn, adresser, e-postadresser och andra identifierare—och jämföra dem mot etablerade likhetströsklar. Moderna deduplikeringssystem använder en kombination av fonetisk matchning, stränglikhetsalgoritmer och semantisk analys för att fånga dubbletter som traditionella regelbaserade system kan missa. Systemet tilldelar likhetspoäng till möjliga träffar och klustrar poster som överskrider den inställda tröskeln i grupper som representerar samma entitet. Användare behåller kontrollen över inkluderingsnivån för deduplikation, vilket gör det möjligt att justera känsligheten efter specifikt användningsområde och tolerans för falska positiva.
| Metod | Beskrivning | Bäst för |
|---|---|---|
| Fonetisk likhet | Grupperar strängar som låter lika (t.ex. “Smith” vs “Smyth”) | Namnvarianter, fonetisk förväxling |
| Stavningslikhet | Grupperar strängar med liknande stavning | Stavfel, mindre stavningsvarianter |
| TFIDF-likhet | Tillämpa algoritmen termfrekvens–inverterad dokumentfrekvens | Allmän textmatchning, dokumentsimilaritet |
Deduplikationsmotorn bearbetar poster i flera steg, identifierar först uppenbara träffar innan mer subtila variationer granskas. Detta lager-på-lager-förfarande säkerställer omfattande täckning samtidigt som beräkningskostnaden hålls nere, även vid hantering av datamängder med miljontals poster.
Modern AI-deduplikation utnyttjar vektorinbäddningar och semantisk analys för att förstå betydelsen bakom data istället för att bara jämföra ytliga egenskaper. Naturlig språkbehandling (NLP) gör det möjligt för systemen att tolka kontext och avsikt, så att de kan känna igen att “Robert”, “Bob” och “Rob” syftar på samma person trots olika former. Fuzzy matching-algoritmer beräknar redigeringsavstånd mellan strängar och identifierar poster som skiljer sig med bara några tecken—viktigt för att fånga stavfel och transkriptionsmisstag. Systemet analyserar även metadata såsom tidsstämplar, skapandedatum och ändringshistorik för att ge ytterligare säkerhetssignaler vid avgörande av dubbletter. Avancerade implementationer inkorporerar maskininlärningsmodeller tränade på märkta datamängder, och förbättrar kontinuerligt noggrannheten i takt med att de bearbetar mer data och får återkoppling på deduplikeringsbeslut.
AI-deduplikationslogik har blivit oumbärlig i princip varje sektor som hanterar storskaliga dataprocesser. Organisationer använder tekniken för att upprätthålla rena, tillförlitliga datamängder som ligger till grund för korrekta analyser och informerade beslut. Praktiska tillämpningar omfattar flera viktiga affärsfunktioner:

Dessa tillämpningar visar hur deduplikation direkt påverkar regelefterlevnad, bedrägeribekämpning och operativ integritet i olika branscher.
De ekonomiska och operationella vinsterna med AI-deduplikation är betydande och mätbara. Organisationer kan avsevärt minska lagringskostnader genom att eliminera redundant data, där vissa implementationer uppnår 20–40 % minskning av lagringsbehovet. Förbättrad datakvalitet leder direkt till bättre analyser och beslutsfattande, eftersom analyser baserade på ren data ger mer tillförlitliga insikter och prognoser. Forskning visar att data scientists ägnar cirka 80 % av sin tid åt databereddning, där dubblettposter är en stor orsak—automatiserad deduplikation frigör värdefull analytikertid för mer värdeskapande arbete. Studier visar att 10–30 % av posterna i typiska databaser är dubbletter, vilket utgör en betydande källa till ineffektivitet och fel. Utöver kostnadsminskning stärker deduplikation regelefterlevnad genom att säkerställa korrekt dokumentation och förhindra dubbla inlämningar som kan leda till revisioner eller sanktioner. Effektivitetsvinsterna inkluderar snabbare sökningar, minskad beräkningsbelastning och förbättrad systemstabilitet.
Trots sin sofistikering är AI-deduplikation inte utan utmaningar och begränsningar som organisationer måste hantera noggrant. Falska positiva—felaktig identifiering av olika poster som dubbletter—kan leda till dataförlust eller sammanslagna poster som borde vara separata, medan falska negativa gör att verkliga dubbletter passerar obemärkt. Deduplikation blir exponentiellt mer komplext vid data i flera format över olika system, språk och datastrukturer, var och en med unika formateringskonventioner och kodningsstandarder. Integritets- och säkerhetsfrågor uppstår när deduplikation kräver analys av känslig personlig information, vilket kräver robust kryptering och åtkomstkontroller för att skydda data under matchningen. Deduplikeringssystemens noggrannhet är i grunden begränsad av kvaliteten på indata; skräp in ger skräp ut, och ofullständiga eller korrupta poster kan förvilla även de mest avancerade algoritmer.
AI-deduplikation har blivit en avgörande komponent i moderna AI-svarsövervakningsplattformar och söksystem som samlar information från flera källor. När AI-system sammanställer svar från många dokument och källor säkerställer deduplikation att samma information inte räknas flera gånger, vilket annars skulle blåsa upp förtroendepoäng och snedvrida relevansrankingen. Källangivelse blir mer meningsfull när deduplikation tar bort redundanta källor, så att användare kan se den faktiska mångfalden av bevis som stöder ett svar. Plattformar som AmICited.com använder deduplikationslogik för att ge transparent och korrekt källspårning genom att identifiera när flera källor innehåller i princip identisk information och konsolidera dem på lämpligt sätt. Detta förhindrar att AI-svar ser ut att ha bredare stöd än de faktiskt har, och upprätthåller integriteten i källangivelsen och svarens trovärdighet. Genom att filtrera bort dubbla källor förbättrar deduplikation kvaliteten på AI-söksvar och ser till att användare får verkligt olika perspektiv istället för variationer av samma information upprepad över flera källor. Tekniken stärker slutligen förtroendet för AI-system genom att ge renare och mer ärliga representationer av bevisen bakom AI-genererade svar.
AI-deduplikation och datakomprimering minskar båda datavolymen, men de fungerar på olika sätt. Deduplikation identifierar och tar bort exakta eller nästan identiska poster och behåller endast en instans medan andra ersätts med referenser. Datakomprimering, däremot, kodar data mer effektivt utan att ta bort dubbletter. Deduplikation arbetar på makronivå (hela filer eller poster), medan komprimering sker på mikronivå (enskilda bitar och byte). För organisationer med mycket dubblerad data ger deduplikation vanligtvis större lagringsbesparingar.
AI använder flera sofistikerade tekniker för att hitta dubbletter som inte är exakta kopior. Fonetiska algoritmer känner igen namn som låter lika (t.ex. "Smith" vs "Smyth"). Osäker matchning beräknar redigeringsavstånd för att hitta poster som skiljer sig med bara några tecken. Vektorinbäddningar omvandlar text till matematiska representationer som fångar semantisk betydelse, vilket gör att systemet kan känna igen omformulerat innehåll. Maskininlärningsmodeller tränade på märkta datamängder lär sig mönster för vad som utgör en dubblett i specifika sammanhang. Dessa tekniker samverkar för att identifiera dubbletter trots variationer i stavning, formatering eller presentation.
Deduplikation kan avsevärt minska lagringskostnaderna genom att eliminera redundant data. Organisationer uppnår vanligtvis 20–40 % minskning av lagringsbehov efter att ha infört effektiv deduplikation. Dessa besparingar ökar över tid i takt med att ny data kontinuerligt deduplikeras. Förutom direkt minskning av lagringskostnader minskar deduplikation även utgifter kopplade till datamanagement, backup och systemunderhåll. För stora företag som hanterar miljontals poster kan besparingarna uppgå till hundratusentals dollar årligen, vilket gör deduplikation till en investering med hög avkastning.
Ja, moderna AI-deduplikationssystem kan arbeta över olika filformat, men det kräver mer avancerad bearbetning. Systemet måste först normalisera data från olika format (PDF-filer, Word-dokument, kalkylblad, databaser osv.) till en jämförbar struktur. Avancerade implementationer använder optisk teckenigenkänning (OCR) för skannade dokument och format-specifika tolkar för att extrahera meningsfullt innehåll. Dock kan deduplikeringsnoggrannheten variera beroende på formatets komplexitet och datakvalitet. Organisationer uppnår vanligtvis bäst resultat när deduplikation tillämpas på strukturerad data inom enhetliga format, men deduplikation över flera format blir alltmer möjlig med moderna AI-tekniker.
Deduplikation förbättrar AI:s sökresultat genom att se till att relevansrankingen återspeglar genuin mångfald av källor istället för variationer av samma information. När flera källor innehåller identiskt eller nästan identiskt innehåll konsoliderar deduplikationen dem, vilket förhindrar konstgjord uppblåsning av förtroendepoäng. Detta ger användarna renare och mer ärliga representationer av bevis som stöder AI-genererade svar. Deduplikation förbättrar också sökprestandan genom att minska mängden data som systemet måste bearbeta, vilket ger snabbare svar på frågor. Genom att filtrera bort redundanta källor kan AI-system fokusera på verkligt olika perspektiv och information, vilket i slutändan ger högre kvalitet och mer tillförlitliga resultat.
Falska positiva uppstår när deduplikation felaktigt identifierar olika poster som dubbletter och slår ihop dem. Till exempel när poster för 'John Smith' och 'Jane Smith', som är olika personer men har samma efternamn, slås ihop. Falska positiva är problematiska eftersom de leder till permanent dataförlust – när poster har slagits samman blir det svårt eller omöjligt att återställa ursprunglig information. Inom kritiska tillämpningar som sjukvård eller finansiella tjänster kan falska positiva få allvarliga konsekvenser, som felaktiga medicinska journaler eller bedrägliga transaktioner. Organisationer måste noggrant kalibrera deduplikeringskänsligheten för att minimera falska positiva, och accepterar ofta vissa falska negativa (missade dubbletter) som en säkrare kompromiss.
Deduplikation är avgörande för AI-innehållsövervakningsplattformar som AmICited som spårar hur AI-system refererar till varumärken och källor. Vid övervakning av AI-svar över flera plattformar (GPTs, Perplexity, Google AI) hindrar deduplikation att samma källa räknas flera gånger om den förekommer i olika AI-system eller i olika format. Detta säkerställer korrekt attribution och förhindrar uppblåsta synlighetsmått. Deduplikation hjälper också till att identifiera när AI-system hämtar från en begränsad uppsättning källor trots att det verkar finnas mångfald. Genom att konsolidera dubbla källor ger innehållsövervakningsplattformar tydligare insikter i vilka unika källor som faktiskt påverkar AI-svar.
Metadata – information om data såsom skapandedatum, ändringsdatum, författarinformation och filattribut – spelar en avgörande roll vid upptäckt av dubbletter. Metadata hjälper till att fastställa posternas livscykel och visar när dokument skapades, uppdaterades eller användes. Denna tidsmässiga information hjälper till att särskilja legitima versioner av utvecklingsdokument från verkliga dubbletter. Författarinformation och avdelningstillhörighet ger kontext om postens ursprung och syfte. Åtkomstmönster visar om dokument används aktivt eller är föråldrade. Avancerade deduplikeringssystem integrerar metadataanalyser med innehållsanalys, och använder båda signalerna för att göra mer exakta bedömningar om dubbletter och för att identifiera vilken version som ska behållas som auktoritativ källa.
AmICited spårar hur AI-system som GPTs, Perplexity och Google AI refererar till ditt varumärke över flera källor. Säkerställ korrekt källangivelse och förhindra att dubbelt innehåll snedvrider din AI-synlighet.
Lär dig hur du hanterar och förebygger duplicerat innehåll när du använder AI-verktyg. Upptäck kanoniska taggar, omdirigeringar, verktyg för upptäckt och bästa ...

Lär dig hur kanoniska URL:er förhindrar problem med duplicerat innehåll i AI-söksystem. Upptäck bästa praxis för implementering av kanoniska taggar för att förb...
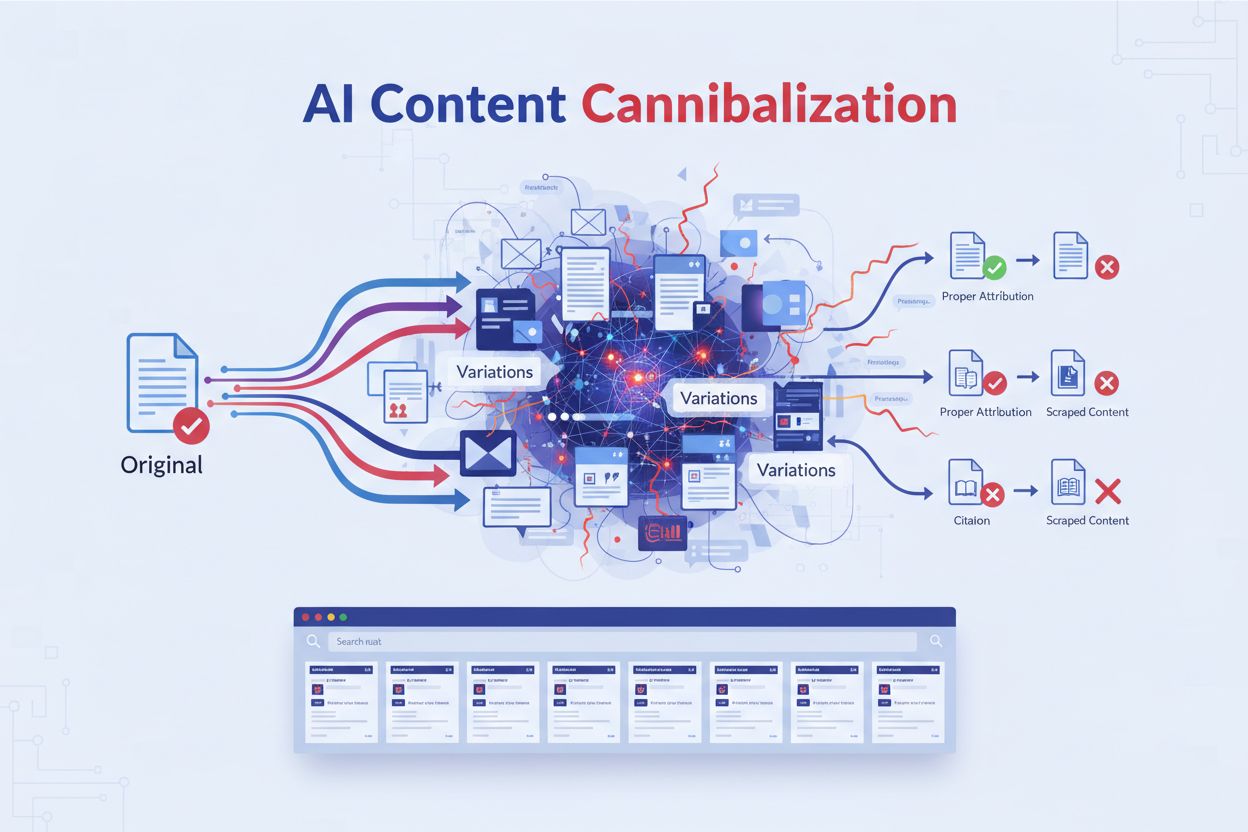
Lär dig vad AI-innehållskannibalisering är, hur det skiljer sig från duplicerat innehåll, varför det skadar rankingar, och strategier för att skydda ditt innehå...