
PerplexityBot: Vad Varje Webbplatsägare Behöver Veta
Komplett guide till PerplexityBot crawler – förstå hur den fungerar, hantera åtkomst, övervaka citeringar och optimera för synlighet i Perplexity AI. Lär dig om...
8 min läsning

Amazons webcrawler som används för att förbättra produkter och tjänster, inklusive Alexa, Rufus shoppingassistent och Amazons AI-drivna sökfunktioner. Den följer Robots Exclusion Protocol och kan styras via direktiv i robots.txt. Kan användas för AI-modellträning.
Amazons webcrawler som används för att förbättra produkter och tjänster, inklusive Alexa, Rufus shoppingassistent och Amazons AI-drivna sökfunktioner. Den följer Robots Exclusion Protocol och kan styras via direktiv i robots.txt. Kan användas för AI-modellträning.
Amazonbot är Amazons officiella webcrawler skapad för att förbättra företagets produkter och tjänster genom att samla in och analysera webbinnehåll. Denna avancerade crawler driver viktiga Amazon-funktioner, inklusive Alexa röstassistent, Rufus AI-shoppingassistent och Amazons AI-drivna sökupplevelser. Amazonbot använder user agent-strängen Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, som identifierar den för webbservrar. Den insamlade datan kan användas för att träna Amazons artificiella intelligensmodeller, vilket gör Amazonbot till en avgörande del av Amazons bredare AI-infrastruktur och produktutvecklingsstrategi.
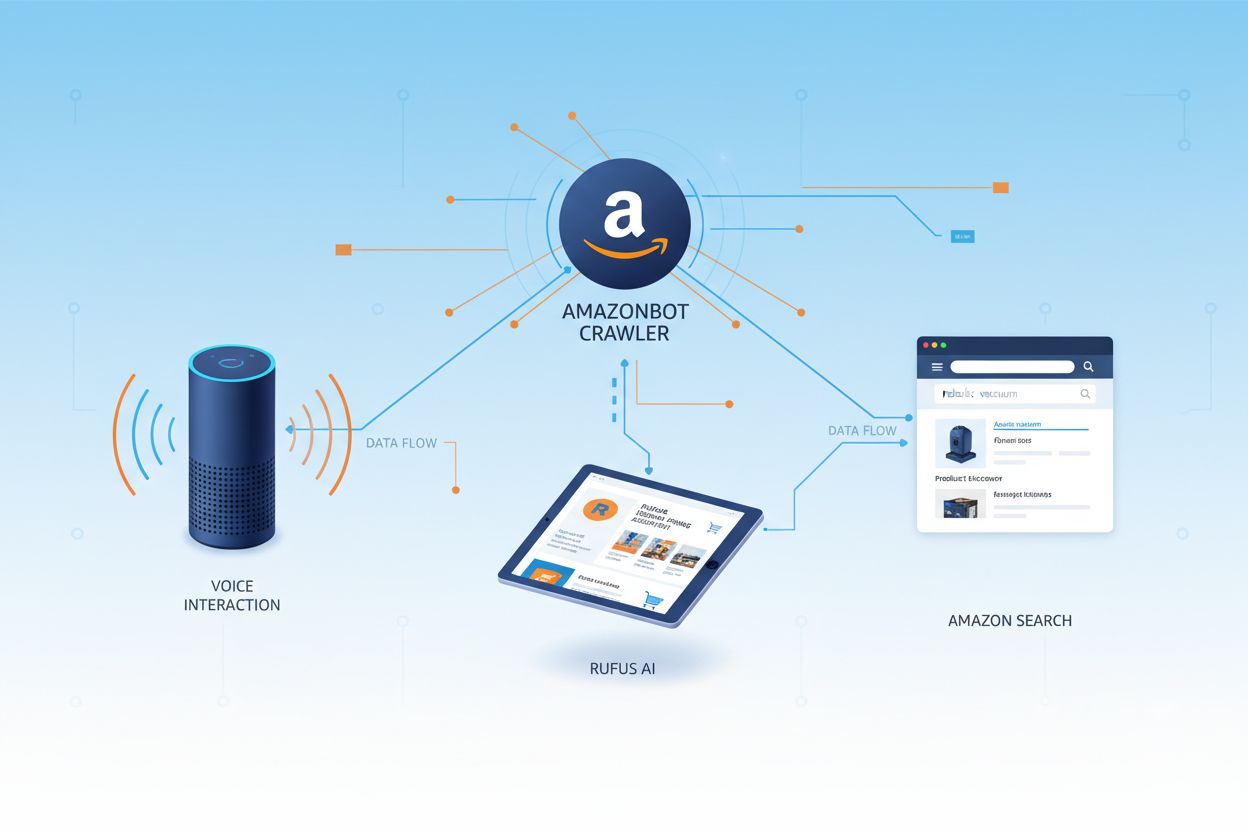
Amazon har tre olika webcrawlers som alla har specifika syften inom ekosystemet. Amazonbot är huvudcrawlern som används för generell förbättring av produkter och tjänster, och den kan användas för AI-modellträning. Amzn-SearchBot är specifikt utvecklad för att förbättra sökupplevelser i Amazons produkter som Alexa och Rufus, men den crawlar INTE innehåll för generativ AI-modellträning. Amzn-User stödjer användarinitierade åtgärder, exempelvis när Alexa hämtar aktuell information från webben när kunder ställer frågor – och den crawlar inte för AI-träning. Alla tre crawlers följer Robots Exclusion Protocol och respekterar direktiv i robots.txt, vilket gör det möjligt för webbplatsägare att styra deras åtkomst. Amazon publicerar IP-adresser för varje crawler på sin utvecklarportal, vilket gör det möjligt för webbägare att verifiera legitim trafik. Dessutom respekterar alla Amazon-crawlers länk-nivå rel=nofollow-direktiv samt sid-nivå robots meta-taggar som noarchive (förhindrar användning för modellträning), noindex (förhindrar indexering) och none (förhindrar båda).
| Crawler-namn | Huvudsyfte | AI-modellträning | User Agent | Viktiga användningsområden |
|---|---|---|---|---|
| Amazonbot | Generell förbättring av produkt/tjänst | Ja | Amazonbot/0.1 | Övergripande förbättring av Amazon-tjänster, AI-träning |
| Amzn-SearchBot | Förbättring av sökupplevelse | Nej | Amzn-SearchBot/0.1 | Alexa-sök, indexering för Rufus shoppingassistent |
| Amzn-User | Användarinitierad hämtning av live-data | Nej | Amzn-User/0.1 | Realtidsfrågor till Alexa, efterfrågan på aktuell information |
Amazon följer det branschstandardiserade Robots Exclusion Protocol (RFC 9309), vilket innebär att webbplatsägare kan styra Amazonbots åtkomst via sin robots.txt-fil. Amazon hämtar robots.txt-filer från rotnivån på din domän (t.ex. example.com/robots.txt) och använder en cachad kopia från de senaste 30 dagarna om filen inte kan hämtas. Ändringar i robots.txt återspeglas normalt inom cirka 24 timmar i Amazons system. Protokollet stöder standarddirektiv som user-agent samt allow/disallow, vilket möjliggör detaljerad kontroll över vilka crawlers som får åtkomst till specifika mappar eller filer. Det är dock viktigt att veta att Amazons crawlers INTE stöder direktivet crawl-delay, så denna parameter ignoreras om den inkluderas i robots.txt.
Här är ett exempel på hur du kan styra Amazonbots åtkomst:
# Blockera Amazonbot från att crawla hela webbplatsen
User-agent: Amazonbot
Disallow: /
# Tillåt Amzn-SearchBot för synlighet i sök
User-agent: Amzn-SearchBot
Allow: /
# Blockera en specifik mapp för Amazonbot
User-agent: Amazonbot
Disallow: /private/
# Tillåt alla andra crawlers
User-agent: *
Disallow: /admin/
Webbplatsägare som är oroliga för bottrafik bör verifiera att crawlers som utger sig för att vara Amazonbot verkligen är legitima Amazon-crawlers. Amazon erbjuder en verifieringsprocess med DNS-uppslagningar för att bekräfta äktheten hos Amazonbot-trafik. För att verifiera en crawlers legitimitet, börja med att hämta IP-adressen från din serverlogg och gör sedan en omvänd DNS-uppslagning på den IP-adressen med kommandot host. Det domännamn som erhålls ska vara en subdomän till crawl.amazonbot.amazon. Gör därefter en framåtriktad DNS-uppslagning på domännamnet för att säkerställa att det pekar tillbaka på den ursprungliga IP-adressen. Denna tvåvägsverifiering förhindrar spoofing-attacker, eftersom illvilliga aktörer annars skulle kunna sätta omvända DNS-poster för att utge sig för att vara Amazonbot. Amazon publicerar verifierade IP-adresser för alla sina crawlers på utvecklarportalen på developer.amazon.com/amazonbot/ip-addresses/, vilket ger ytterligare en referenspunkt för verifiering.
Exempel på verifieringsprocess:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Om du har frågor om Amazonbot eller behöver rapportera misstänkt aktivitet, kontakta Amazon direkt på amazonbot@amazon.com och inkludera relevanta domännamn i ditt meddelande.
Det finns en viktig skillnad mellan Amazons crawlers vad gäller AI-modellträning. Amazonbot kan användas för att träna Amazons artificiella intelligensmodeller, vilket är relevant för innehållsskapare som är oroliga för att deras material används för AI-träning. Däremot crawlar Amzn-SearchBot och Amzn-User uttryckligen INTE för generativ AI-modellträning, utan fokuserar enbart på att förbättra sökupplevelser och stödja användarfrågor. Om du vill förhindra att ditt innehåll används för AI-modellträning kan du använda robots meta-taggen noarchive i din sid-header, vilket instruerar Amazonbot att inte använda sidan för modellträning. Denna skillnad är viktig för publicister, skapare och webbplatsägare som vill ha kontroll över hur deras innehåll används i AI-träningsprocessen, men ändå vill synas i Amazons sökresultat och Rufus-rekommendationer.
Rufus är Amazons avancerade AI-shoppingassistent som använder webbcrawling och AI-teknik för att ge personliga shoppingrekommendationer och assistans. Medan Amazonbot bidrar till Amazons övergripande AI-infrastruktur, använder Rufus specifikt Amzn-SearchBot för att indexera produktinformation och webbinnehåll som är relevant för shoppingfrågor. Rufus är byggd på Amazon Bedrock och använder avancerade språkmodeller som Anthropics Claude Sonnet och Amazon Nova, kombinerat med en egenutvecklad modell tränad på Amazons omfattande produktkatalog, kundrecensioner, community Q&A och webbinformation. Shoppingassistenten hjälper kunder att undersöka produkter, jämföra alternativ, följa priser, hitta erbjudanden och till och med automatiskt köpa varor när de når önskat pris. Sedan lanseringen har Rufus blivit mycket populär, med över 250 miljoner användare, månatliga aktiva användare upp 149 %, och interaktioner har ökat med 210 % år över år. Kunder som använder Rufus när de shoppar är över 60 % mer benägna att genomföra ett köp under samma shoppingtillfälle, vilket visar den betydande effekten av AI-baserad shoppingassistans på konsumentbeteende.
Webbplatsägare bör utforma en strategisk plan för hantering av Amazons crawlers baserat på sina affärsmål och innehållspolicy:
noarchive eller blockera den helt via robots.txtamazonbot@amazon.com och ange din domän för personlig vägledning om du har särskilda frågor eller funderingar kring hur Amazons crawlers interagerar med din webbplatsAmazonbot är Amazons generalist-crawler som används för att förbättra produkter och tjänster, och den kan användas för AI-modellträning. Amzn-SearchBot är specifikt utformad för sökupplevelser i Alexa och Rufus, och den crawlar uttryckligen INTE för AI-modellträning. Om du vill förhindra användning för AI-träning, blockera Amazonbot men tillåt Amzn-SearchBot för sökbarhet.
Lägg till följande rader i din robots.txt-fil i roten av din domän: User-agent: Amazonbot följt av Disallow: /. Det förhindrar Amazonbot från att crawla hela din webbplats. Du kan även använda Disallow: /specifik-mapp/ för att blockera enskilda kataloger.
Ja, Amazonbot kan användas för att träna Amazons artificiella intelligensmodeller. Om du vill förhindra detta, använd robots meta-taggen i sidans HTML-header, vilket instruerar Amazonbot att inte använda sidan för modellträning.
Utför en omvänd DNS-uppslagning på crawlerns IP-adress och verifiera att domänen är en subdomän till crawl.amazonbot.amazon. Gör sedan en framåt DNS-uppslagning för att bekräfta att domänen pekar tillbaka på den ursprungliga IP-adressen. Du kan också kontrollera Amazons publicerade IP-adresser på developer.amazon.com/amazonbot/ip-addresses/.
Använd standard-syntax för robots.txt: User-agent: Amazonbot för att rikta in dig på crawlern, följt av Disallow: / för att blockera all åtkomst eller Disallow: /sökväg/ för att blockera specifika kataloger. Du kan även använda Allow: / för att uttryckligen tillåta åtkomst.
Amazon brukar återspegla ändringar i robots.txt inom cirka 24 timmar. Amazon hämtar regelbundet din robots.txt-fil och behåller en cachad kopia i upp till 30 dagar, så det kan ta en hel dag innan ändringar slår igenom i deras system.
Ja, absolut. Du kan skapa separata regler för varje crawler i din robots.txt-fil. Till exempel, tillåt Amzn-SearchBot med User-agent: Amzn-SearchBot och Allow: /, medan du blockerar Amazonbot med User-agent: Amazonbot och Disallow: /.
Kontakta Amazon direkt på amazonbot@amazon.com. Inkludera alltid din domän och relevanta detaljer om din fråga i meddelandet. Amazons supportteam kan ge personlig vägledning för just din situation.
Spåra omnämnanden av ditt varumärke över AI-system som Alexa, Rufus och Google AI Overviews med AmICited – den ledande plattformen för övervakning av AI-svar.
Komplett guide till PerplexityBot crawler – förstå hur den fungerar, hantera åtkomst, övervaka citeringar och optimera för synlighet i Perplexity AI. Lär dig om...

Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet...

Lär dig vad GPTBot är, hur det fungerar och om du bör tillåta eller blockera OpenAI:s webcrawler. Förstå effekten på din varumärkesexponering i AI-sökmotorer oc...