
Vad är Multimodalt Innehåll för AI? Definition och Exempel
Lär dig vad multimodalt innehåll för AI är, hur det fungerar och varför det är viktigt. Utforska exempel på multimodala AI-system och deras tillämpningar inom o...
9 min läsning

AI-system som behandlar och besvarar frågor som innefattar text, bilder, ljud och video samtidigt, vilket möjliggör mer heltäckande förståelse och kontextmedvetna svar över flera datatyper.
AI-system som behandlar och besvarar frågor som innefattar text, bilder, ljud och video samtidigt, vilket möjliggör mer heltäckande förståelse och kontextmedvetna svar över flera datatyper.
Multimodal AI-sökning avser artificiella intelligenssystem som behandlar och integrerar information från flera datatyper eller modaliteter—såsom text, bilder, ljud och video—samtidigt för att leverera mer heltäckande och kontextuellt relevanta resultat. Till skillnad från unimodal AI, som förlitar sig på en enda typ av inmatning (till exempel textbaserade sökmotorer), utnyttjar multimodala system de kompletterande styrkorna hos olika dataformat för att uppnå djupare förståelse och mer exakta utfall. Detta tillvägagångssätt speglar mänsklig kognition, där vi naturligt kombinerar visuell, auditiv och textuell information för att förstå vår omgivning. Genom att behandla olika inmatningstyper tillsammans kan multimodala AI-söksystem fånga nyanser och samband som skulle vara osynliga för metoder med endast en modalitet.
Multimodal AI-sökning fungerar genom sofistikerade fusionstekniker som kombinerar information från olika modaliteter vid olika bearbetningsnivåer. Systemet extraherar först egenskaper från varje modalitet separat, för att sedan strategiskt slå samman dessa representationer till en enhetlig förståelse. Tidpunkten och metoden för fusion påverkar resultatet avsevärt, vilket illustreras i jämförelsen nedan:
| Fusionstyp | När den används | Fördelar | Nackdelar |
|---|---|---|---|
| Tidig fusion | Inmatningsstadiet | Fångar lågnivåkorrelationer | Mindre robust mot feljusterad data |
| Mellanfusion | Förbehandlingsstadier | Balanserad metod | Mer komplex |
| Sen fusion | Utdatanivå | Modulär design | Minskad sammanhängande kontext |
Tidig fusion kombinerar rådata omedelbart, vilket fångar detaljerade interaktioner men har svårt med feljusterade indata. Mellanfusion används under mellanliggande bearbetningssteg och erbjuder ett balanserat kompromiss mellan komplexitet och prestanda. Sen fusion sker på utdatanivå, vilket möjliggör oberoende bearbetning av modaliteter men riskerar att tappa viktig tvärmodal kontext. Valet av fusionstrategi beror på den specifika applikationens krav och datats karaktär.
Flera nyckelteknologier driver dagens multimodala AI-söksystem och gör det möjligt för dem att effektivt bearbeta och integrera olika datatyper:
Dessa teknologier samverkar för att skapa system som kan förstå komplexa relationer mellan olika typer av information.
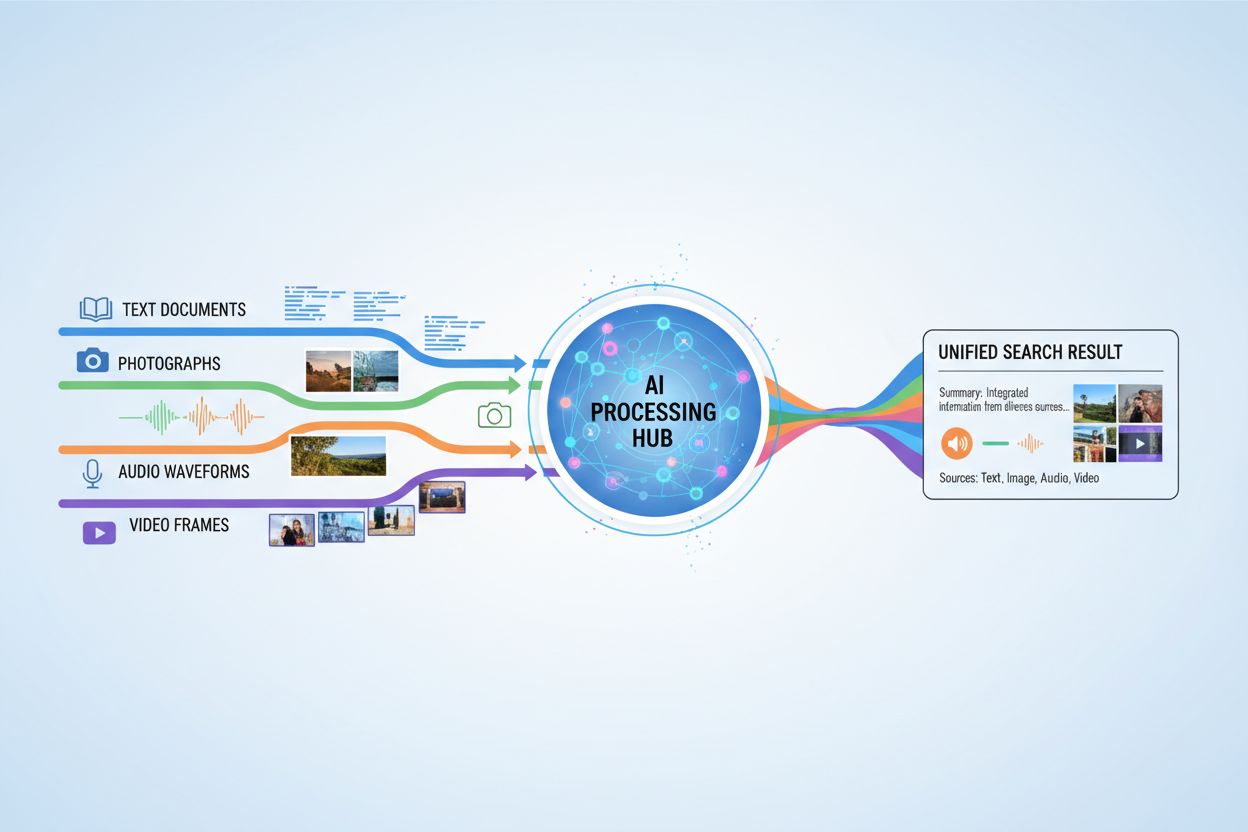
Multimodal AI-sökning har transformerande tillämpningar inom många branscher och områden. Inom hälso- och sjukvården analyserar system medicinska bilder tillsammans med patientjournaler och kliniska anteckningar för att förbättra diagnostisk precision och behandlingsrekommendationer. E-handelsplattformar använder multimodal sökning för att låta kunder hitta produkter genom att kombinera textbeskrivningar med visuella referenser eller till och med skisser. Autonoma fordon förlitar sig på multimodal fusion av kamerabilder, radardata och sensorinmatningar för att navigera säkert och fatta beslut i realtid. Innehållsmoderering kombinerar bildigenkänning, textanalys och ljudbearbetning för att identifiera skadligt innehåll mer effektivt än metoder med enbart en modalitet. Dessutom förbättrar multimodal sökning tillgängligheten genom att låta användare söka med sitt föredragna inmatningssätt—röst, bild eller text—samtidigt som systemet förstår avsikten över alla format.

Multimodal AI-sökning ger stora fördelar som motiverar dess ökade komplexitet och beräkningskrav. Förbättrad noggrannhet uppnås genom att utnyttja kompletterande informationskällor och minska fel som system med en enda modalitet kan göra. Förbättrad kontextuell förståelse uppstår när visuell, textuell och auditiv information kombineras för att skapa rikare semantisk mening. Överlägsen användarupplevelse nås genom mer intuitiva sökgränssnitt som accepterar olika inmatningstyper och levererar mer relevanta resultat. Tvärdomänsinlärning blir möjlig då kunskap från en modalitet kan informera förståelsen i en annan, vilket möjliggör transfer learning över olika datatyper. Ökad robusthet innebär att systemet bibehåller prestanda även när en modalitet är försämrad eller otillgänglig, eftersom andra modaliteter kan kompensera för saknad information.
Trots sina fördelar står multimodal AI-sökning inför betydande tekniska och praktiska utmaningar. Datajustering och synkronisering är fortsatt svårt, eftersom olika modaliteter ofta har olika tidsmässiga egenskaper och kvalitetsnivåer som måste hanteras noggrant. Beräkningskomplexiteten ökar avsevärt när flera datakanaler bearbetas samtidigt, vilket kräver stora resurser och specialiserad hårdvara. Bias och rättvisa blir ett bekymmer när träningsdata är obalanserad över modaliteter eller när vissa grupper är underrepresenterade i specifika datatyper. Integritet och säkerhet blir mer komplicerat med flera datakanaler, vilket ökar risken för dataintrång och kräver noggrann hantering av känslig information. Stora datakrav innebär att träning av effektiva multimodala system kräver betydligt större och mer varierade dataset än unimodala alternativ, vilket kan vara kostsamt och tidskrävande att samla in och annotera.
Multimodal AI-sökning har en viktig koppling till AI-övervakning och citatspårning, särskilt i takt med att AI-system allt oftare genererar svar som refererar till eller sammanställer information från flera källor. Plattformar som AmICited.com fokuserar på att övervaka hur AI-system citerar och attribuerar information till ursprungskällor, vilket säkerställer transparens och ansvar i AI-genererade svar. På liknande sätt spårar FlowHunt.io AI-innehållsgenerering och hjälper organisationer att förstå hur deras varumärkesinnehåll behandlas och refereras av multimodala AI-system. I takt med att multimodal AI-sökning blir vanligare blir det avgörande för företag att följa hur dessa system citerar varumärken, produkter och ursprungskällor för att förstå sin synlighet i AI-genererade resultat. Denna övervakningsmöjlighet hjälper organisationer att verifiera att deras innehåll representeras korrekt och attribueras på rätt sätt när multimodala AI-system sammanställer information över text, bilder och andra modaliteter.
Framtiden för multimodal AI-sökning pekar mot en allt mer enhetlig och sömlös integration av olika datatyper, där man går bortom dagens fusionstekniker mot mer holistiska modeller som behandlar alla modaliteter som naturligt sammankopplade. Realtidsbearbetning kommer att expandera, vilket gör det möjligt för multimodal sökning att fungera på live videoströmmar, kontinuerligt ljud och dynamisk text samtidigt utan fördröjning. Avancerade dataförstärkningstekniker kommer att motverka dagens dataknapphet genom att syntetiskt generera multimodala träningsexempel som behåller semantisk konsistens mellan modaliteter. Framväxande utveckling inkluderar grundmodeller tränade på stora multimodala dataset som kan anpassas effektivt för specifika uppgifter, neuromorfiska datortekniker som mer liknar biologisk multimodal bearbetning samt federerad multimodal inlärning som möjliggör träning över distribuerade datakällor med bibehållen integritet. Dessa framsteg kommer att göra multimodal AI-sökning mer tillgänglig, effektiv och kapabel att hantera alltmer komplexa scenarier i verkligheten.
Spåra hur multimodala AI-sökmotorer citerar och attribuerar ditt innehåll över text, bilder och andra modaliteter med AmICiteds heltäckande övervakningsplattform.
Lär dig vad multimodalt innehåll för AI är, hur det fungerar och varför det är viktigt. Utforska exempel på multimodala AI-system och deras tillämpningar inom o...

Lär dig hur du optimerar text, bilder och video för multimodala AI-system. Upptäck strategier för att förbättra AI-citeringar och synlighet i ChatGPT, Gemini oc...

Bemästra multimodal AI-sökoptimering. Lär dig hur du optimerar bilder och röstfrågor för AI-drivna sökresultat, med strategier för GPT-4o, Gemini och LLMs....
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.