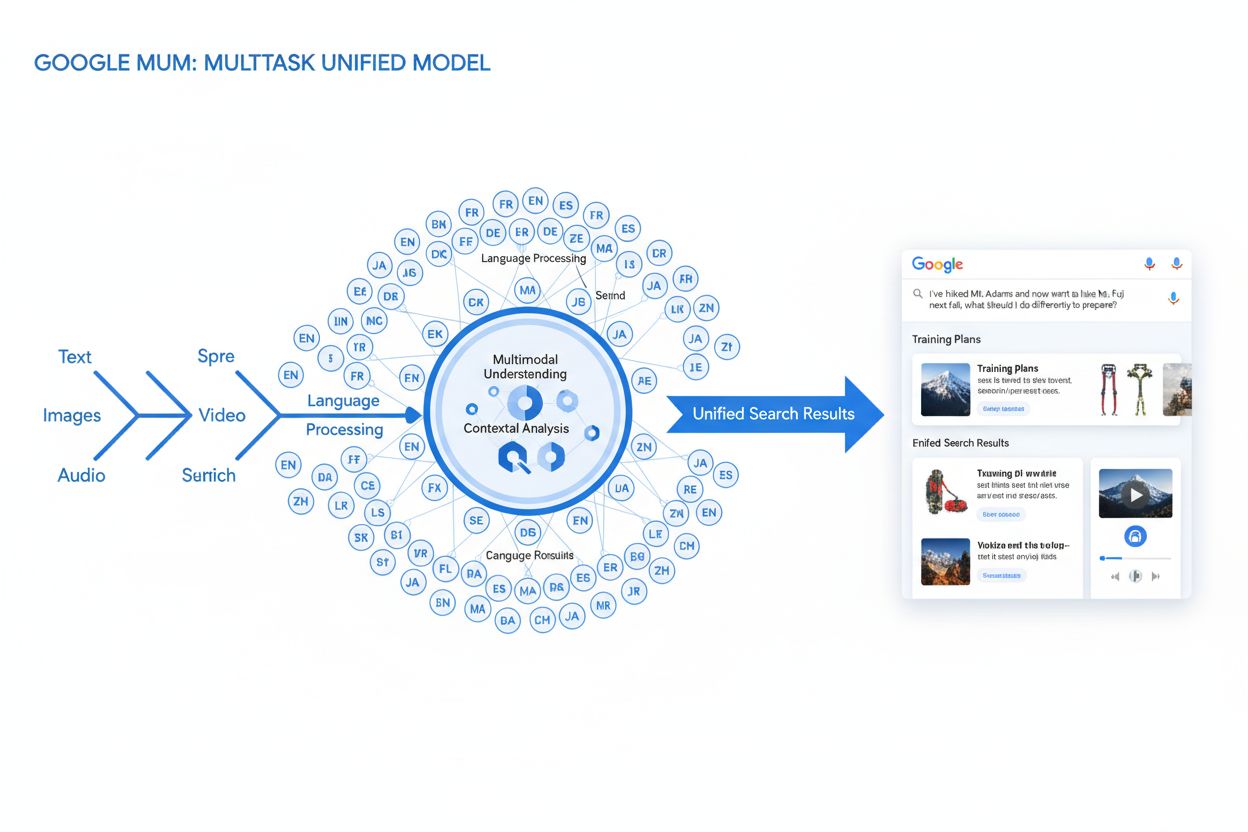
Definition av MUM (Multitask Unified Model)
MUM (Multitask Unified Model) är Googles avancerade multimodala artificiella intelligensmodell som är utformad för att revolutionera hur sökmotorer förstår och besvarar komplexa användarfrågor. MUM tillkännagavs i maj 2021 av Pandu Nayak, Google Fellow och Vice President of Search, och representerar ett grundläggande skifte inom teknik för informationshämtning. Den är byggd på T5 text-till-text-ramverket och består av cirka 110 miljarder parametrar. MUM är 1 000 gånger kraftfullare än BERT, Googles tidigare genombrottsmodell för naturlig språkbehandling. Till skillnad från traditionella sökalgoritmer som bearbetar text isolerat, bearbetar MUM text, bilder, video och ljud samtidigt och förstår information på över 75 språk inbyggt. Denna multimodala och flerspråkiga kapacitet gör att MUM kan förstå komplexa frågor som tidigare krävde att användaren gjorde flera sökningar, och omvandlar sök från en enkel nyckelordsbaserad övning till ett intelligent, kontextmedvetet informationshämtande system. MUM förstår inte bara språk utan kan även generera det, vilket gör den kapabel att syntetisera information från olika källor och format för att ge heltäckande, nyanserade svar som adresserar hela användarens avsikt.
Historisk kontext och utveckling av Googles AI-modeller
Googles resa mot MUM representerar år av stegvis innovation inom naturlig språkbehandling och maskininlärning. Utvecklingen började med Hummingbird (2013), som introducerade semantisk förståelse för att tolka betydelsen bakom sökfrågor istället för att bara matcha nyckelord. Därefter kom RankBrain (2015), som använde maskininlärning för att förstå långsvansade sökord och nya sökmönster. Neural Matching (2018) tog detta vidare genom att använda neurala nätverk för att matcha frågor med relevant innehåll på en djupare semantisk nivå. BERT (Bidirectional Encoder Representations from Transformers), lanserad 2019, var en milstolpe genom att förstå kontext inom meningar och stycken och förbättra Googles förmåga att tolka nyanserat språk. Men BERT hade betydande begränsningar—den bearbetade endast text, hade begränsat flerspråkigt stöd och kunde inte hantera den komplexitet som krävs för att syntetisera information över flera format. Enligt Googles forskning gör användare i genomsnitt åtta separata sökningar för att besvara komplexa frågor, som att jämföra två vandringsdestinationer eller utvärdera produktalternativ. Denna statistik belyste en kritisk brist i söktekniken som MUM var särskilt utformad för att lösa. Helpful Content Update (2022) och E-E-A-T-ramverket (2023) ytterligare förfinade hur Google prioriterar auktoritativt och tillförlitligt innehåll. MUM bygger vidare på alla dessa innovationer men introducerar kapaciteter som överträffar tidigare begränsningar och representerar inte bara en gradvis förbättring utan ett paradigmskifte i hur sökmotorer bearbetar och levererar information.
Teknisk arkitektur och multimodal bearbetning
MUM:s tekniska grund vilar på Transformer-arkitekturen, specifikt T5 (Text-to-Text Transfer Transformer) ramverket som Google utvecklade tidigare. T5-ramverket behandlar alla uppgifter inom naturlig språkbehandling som text-till-text-problem och omvandlar indata och utdata till enhetliga textrepresentationer. MUM utökar detta tillvägagångssätt genom att inkludera multimodala bearbetningskapaciteter, vilket gör att den kan hantera text, bilder, video och ljud samtidigt inom en och samma modell. Detta arkitekturval är betydelsefullt eftersom det gör att MUM kan förstå samband och kontext över olika medietyper på sätt som tidigare modeller inte kunde. Till exempel, när modellen bearbetar en fråga om att vandra på Mt. Fuji tillsammans med en bild på specifika vandringskängor, analyserar MUM inte text och bild separat—den bearbetar dem tillsammans och förstår hur kängans egenskaper relaterar till frågans kontext. Modellens 110 miljarder parametrar ger den kapacitet att lagra och bearbeta enorma mängder kunskap om språk, visuella koncept och deras relationer. MUM är tränad på 75 olika språk och många olika uppgifter samtidigt, vilket gör att den utvecklar en mer heltäckande förståelse av information och världskunskap än modeller som tränats på enskilda språk eller uppgifter. Detta multitask-lärande innebär att MUM lär sig känna igen mönster och samband som kan överföras mellan språk och domäner, vilket gör den mer robust och generaliserbar än tidigare modeller. Den samtidiga bearbetningen av flera språk under träning gör att MUM kan utföra kunskapsöverföring mellan språk, vilket innebär att den kan förstå information skriven på ett språk och tillämpa den förståelsen på frågor på ett annat språk, och därmed effektivt bryta ner språkbarriärer som tidigare begränsat sökresultaten.
Jämförelsetabell: MUM vs. relaterade AI-modeller och teknologier
| Attribut | MUM (2021) | BERT (2019) | RankBrain (2015) | T5 Framework |
|---|
| Huvudfunktion | Multimodal frågeförståelse och svarssyntes | Textbaserad kontextuell förståelse | Långsvansad sökordsinterpretation | Text-till-text transfer learning |
| Indataformat | Text, bilder, video, ljud | Endast text | Endast text | Endast text |
| Språkstöd | 75+ språk inbyggt | Begränsat flerspråkigt stöd | Främst engelska | Främst engelska |
| Modellparametrar | ~110 miljarder | ~340 miljoner | Ej offentliggjort | ~220 miljoner |
| Kraftjämförelse | 1 000x kraftfullare än BERT | Baslinje | Föregångare till BERT | Grund för MUM |
| Kapabiliteter | Förståelse + generering | Endast förståelse | Mönsterigenkänning | Texttransformation |
| SERP-påverkan | Multiformat berikade resultat | Bättre utdrag och kontext | Förbättrad relevans | Grundläggande teknik |
| Hantering av frågekomplexitet | Komplexa flerstegsfrågor | Enstaka frågekontext | Långsvansvariationer | Texttransformation |
| Kunskapsöverföring | Mellan språk och format | Endast inom språk | Begränsad överföring | Mellan uppgifter |
| Användning i verkligheten | Google Sök, AI Overviews | Google Sök-rankning | Google Sök-rankning | Teknisk grund för MUM |
Hur MUM bearbetar komplexa sökfrågor
MUM:s frågebearbetning involverar flera sofistikerade steg som samarbetar för att leverera heltäckande, kontextuella svar. När en användare skickar in en sökfråga börjar MUM med att utföra språkagnostisk förbearbetning, där den förstår frågan på något av sina 75+ stödda språk utan att behöva översätta. Denna inbyggda språkförståelse bevarar nyanser och regional kontext som annars kan gå förlorade vid översättning. Sedan använder MUM sekvens-till-sekvens-matchning, där hela frågan analyseras som en meningssekvens snarare än isolerade nyckelord. Detta gör att MUM kan förstå relationer mellan begrepp—till exempel att en fråga om “förbereda sig för Mt. Fuji efter att ha klättrat på Mt. Adams” involverar jämförelse, förberedelse och kontextuell anpassning. Samtidigt utför MUM multimodal indatabearbetning, där den bearbetar eventuella bilder, videor eller annat media som ingår i frågan. Modellen genomför sedan samtidig frågebearbetning, där den utvärderar flera möjliga användaravsikter parallellt istället för att begränsa sig till en tolkning. Det innebär att MUM kan inse att en fråga om att vandra på Mt. Fuji kan handla om fysisk förberedelse, val av utrustning, kulturella upplevelser eller reseplanering—och visar relevant information för alla dessa tolkningar. Vektorbaserad semantisk förståelse omvandlar frågan och indexerat innehåll till högdimensionella vektorer som representerar semantisk betydelse, vilket möjliggör hämtning baserat på konceptuell likhet snarare än nyckelordsmatchning. MUM tillämpar sedan innehållsfiltrering via kunskapsöverföring, där maskininlärning tränad på sökloggar, surfbeteende och användarmönster prioriterar högkvalitativa, auktoritativa källor. Slutligen genererar MUM en multimedialt berikad SERP-komposition, där textutdrag, bilder, videor, relaterade frågor och interaktiva element kombineras till en enhetlig, visuellt lagerbaserad sökupplevelse. Hela denna process sker på några millisekunder, vilket gör att MUM kan leverera resultat som adresserar inte bara den uttryckliga frågan utan även förväntade följdfrågor och relaterade informationsbehov.
Multimodala och flerspråkiga kapaciteter
MUM:s multimodala kapacitet innebär ett grundläggande avsteg från textbaserade söksystem. Modellen kan samtidigt bearbeta och förstå information från text, bilder, video och ljud, extrahera betydelse från varje modalitet och syntetisera det till sammanhängande svar. Denna kapacitet är särskilt kraftfull för frågor som gynnas av visuell kontext. Om en användare till exempel frågar “Kan jag använda dessa vandringskängor för Mt. Fuji?” och visar en bild på sina kängor, förstår MUM kängans egenskaper från bilden—material, mönster på sulan, höjd, färg—och kopplar den visuella förståelsen med kunskap om Mt. Fujis terräng, klimat och vandringskrav för att ge ett kontextuellt svar. MUM:s flerspråkiga dimension är lika omvälvande. Med inbyggt stöd för över 75 språk kan MUM utföra kunskapsöverföring mellan språk, vilket innebär att den lär sig från källor på ett språk och tillämpar den kunskapen på frågor på ett annat språk. Detta bryter ner en betydande barriär som tidigare begränsat sökresultat till innehåll på användarens modersmål. Om omfattande information om Mt. Fuji huvudsakligen finns på japanska källor—inklusive lokala vandringsguider, säsongsbetonade vädermönster och kulturella insikter—kan MUM förstå detta japanskspråkiga innehåll och visa relevant information för engelskspråkiga användare. Enligt Googles tester kunde MUM lista 800 varianter av covid-19-vacciner på över 50 språk inom några sekunder, vilket visar omfattningen och hastigheten i dess flerspråkiga bearbetningskapacitet. Denna flerspråkiga förståelse är särskilt värdefull för användare på icke-engelska marknader och för frågor om ämnen med rik information på flera språk. Kombinationen av multimodal och flerspråkig bearbetning gör att MUM kan visa den mest relevanta informationen oavsett vilket format den presenteras i eller vilket språk den ursprungligen publicerades på, och skapar därmed en verkligt global sökupplevelse.
Påverkan på sökresultat och användarupplevelse
MUM förändrar i grunden hur sökresultat visas och upplevs av användare. Istället för den traditionella listan med blå länkar som dominerat sök i årtionden skapar MUM berikade, interaktiva SERP:er som kombinerar flera innehållsformat på en och samma sida. Användare kan nu se textutdrag, högupplösta bilder, videokaruseller, relaterade frågor och interaktiva element utan att lämna sökresultatsidan. Denna förändring har stora konsekvenser för hur användare interagerar med sök. Istället för att genomföra flera sökningar för att samla information om ett komplext ämne kan användare utforska olika vinklar och underteman direkt i SERP:en. Till exempel kan en fråga om “förberedelse för Mt. Fuji på hösten” visa höjdjämförelser, väderprognoser, utrustningsrekommendationer, videoguides och användarrecensioner—allt kontextuellt organiserat på en sida. Google Lens-integration som drivs av MUM gör att användare kan söka med bilder istället för nyckelord, vilket förvandlar visuella element i foton till interaktiva upptäcktsverktyg. “Things to Know”-paneler bryter ner komplexa frågor i hanterbara underteman och vägleder användare genom olika aspekter av ett ämne med relevanta utdrag för varje. Zoomningsbara, högupplösta bilder visas direkt i sökresultaten och möjliggör visuell jämförelse och minskar friktionen i tidiga beslutsprocesser. “Förfina och bredda”-funktionalitet föreslår relaterade begrepp för att hjälpa användare att antingen fördjupa sig i specifika aspekter eller utforska närliggande ämnen. Dessa förändringar innebär ett skifte från sök som ett enkelt hämtverktyg till sök som en interaktiv, utforskande upplevelse som förutser användarens behov och ger heltäckande information direkt i sökgränssnittet. Forskning visar att denna rikare SERP-upplevelse minskar det genomsnittliga antalet sökningar som behövs för att besvara komplexa frågor, men det innebär också att användare kan konsumera information direkt i sökresultaten istället för att klicka sig vidare till webbplatser.
MUM:s roll i AI-övervakning och varumärkessynlighet
För organisationer som spårar sin närvaro i AI-system innebär MUM en avgörande utveckling i hur information upptäcks och visas. När MUM blir alltmer integrerad i Google Sök och påverkar andra AI-system blir det viktigt att förstå hur varumärken och domäner syns i MUM-drivna resultat för att bibehålla synlighet. MUM:s multimodala bearbetning innebär att varumärken måste optimera över flera innehållsformat, inte bara text. Ett varumärke som tidigare förlitade sig på att ranka för specifika nyckelord måste nu säkerställa att dess innehåll kan upptäckas via bilder, videor och strukturerad data. Modellens förmåga att syntetisera information från olika källor innebär att ett varumärkes synlighet beror inte bara på den egna webbplatsen utan även på hur dess information visas i det bredare ekosystemet. MUM:s flerspråkiga kapacitet skapar nya möjligheter och utmaningar för globala varumärken. Innehåll som publiceras på ett språk kan nu upptäckas av användare som söker på andra språk, vilket utökar den potentiella räckvidden. Detta innebär dock också att varumärken måste säkerställa att deras information är korrekt och konsekvent på olika språk, eftersom MUM kan visa information från flera språkkällor för en och samma fråga. För AI-övervakningsplattformar som AmICited är det avgörande att spåra MUM:s påverkan eftersom den visar hur moderna AI-system hämtar och presenterar information. När man övervakar var ett varumärke syns i AI-svar—oavsett om det är i Google AI Overviews, Perplexity, ChatGPT eller Claude—hjälper förståelsen för MUM:s underliggande teknik till att förklara varför visst innehåll visas och hur man optimerar för synlighet. Skiftet mot multimodal och flerspråkig sök innebär att varumärken behöver omfattande övervakning som spårar deras närvaro över olika innehållsformat och språk, inte bara traditionella nyckelordsrankningar. Organisationer som förstår MUM:s kapacitet kan bättre optimera sin innehållsstrategi för att säkerställa synlighet i detta nya söklandskap.
Viktiga fördelar och styrkor med MUM
- Minskad sökfriktion: Användare behöver färre sökningar för att besvara komplexa frågor, då MUM syntetiserar information från flera källor och format till heltäckande svar
- Multimodal förståelse: Samtidig bearbetning av text, bilder, video och ljud ger rikare kontext och mer exakta svar på frågor som kräver visuell eller multimedial förståelse
- Flerspråkig kunskapsöverföring: Inbyggt stöd för över 75 språk möjliggör upptäckt av information över språkbarriärer och ökar räckvidd och tillgänglighet globalt
- Kontextuell relevans: MUM förstår användarens avsikt på djupare nivå, känner igen samband mellan begrepp och visar information som besvarar förväntade följdfrågor
- Berikad SERP-upplevelse: Interaktiva, visuellt lagerbaserade sökresultat ger mer information direkt i sök, vilket förbättrar användarengagemang och beslutsfattande
- Bättre hantering av otydliga frågor: MUM:s förmåga att utvärdera flera tolkningar samtidigt gör att den kan ge relevanta resultat även för vaga eller tvetydiga frågor
- Kunskapssyntes: Istället för att bara hämta existerande innehåll kan MUM syntetisera information från flera källor för att skapa heltäckande svar
- Förbättrad tillgänglighet: Flerspråkig och multimodal bearbetning gör information mer tillgänglig för olika användare med olika språkpreferenser och tillgänglighetsbehov
- Förbättrade utdrag: MUM möjliggör mer sofistikerad utdragsgenerering, med flera utdragsformat per fråga baserat på olika användaravsikter
- Upptäckt av innehåll i olika format: Innehåll i vilket format som helst—text, bilder, video, ljud—har potential att upptäckas och visas, vilket gynnar multimediala innehållsstrategier
Begränsningar och utmaningar med MUM
Även om MUM innebär ett stort framsteg medför den också nya utmaningar och begränsningar som organisationer måste hantera. Lägre klickfrekvens är en stor oro för publicister och innehållsskapare, då användare nu kan ta till sig heltäckande information direkt i sökresultaten utan att klicka vidare till webbplatser. Detta innebär att traditionella trafikmått blir mindre tillförlitliga indikatorer på innehållsframgång. Ökade tekniska SEO-krav innebär att för att förstås korrekt av MUM måste innehållet vara välstrukturerat med rätt schema-markup, semantisk HTML och tydliga entitetsrelationer. Innehåll som saknar denna tekniska grund kan bli felindexerat eller missförstått av MUM:s multimodala bearbetning. SERP-mättnad skapar utmaningar för synlighet, då fler innehållsformat konkurrerar om uppmärksamhet på en och samma sida. Även starkt innehåll kan få färre eller inga klick om användarna hittar tillräcklig information i SERP:en. Risk för missvisande resultat finns när MUM visar information från olika källor som kan motsäga varandra eller när kontext går förlorad i syntesen. Beroende av strukturerad data innebär att ostrukturerat eller dåligt formaterat innehåll kanske inte förstås eller visas korrekt av MUM. Språk- och kulturspecifika nyanser kan gå förlorade när MUM överför kunskap mellan språk, vilket kan leda till att kulturell kontext eller regionala variationer missas. Beräkningsresurser för att köra MUM i stor skala är betydande, även om Google har satsat på effektivitetsförbättringar för att minska koldioxidavtrycket. Bias och rättviseproblem kräver kontinuerlig uppmärksamhet för att säkerställa att MUM inte befäster fördomar i träningsdata eller missgynnar vissa perspektiv eller grupper.
SEO- och innehållsstrategiska implikationer
MUM:s framväxt kräver grundläggande förändringar i hur organisationer närmar sig SEO och innehållsstrategi. Traditionell nyckelordsfokuserad optimering blir mindre effektiv när MUM kan förstå avsikt och kontext bortom exakta nyckelordsfraser. Ämnesbaserad innehållsstrategi blir viktigare än nyckelordsbaserad, där organisationer behöver skapa heltäckande innehållskluster som behandlar ämnen från flera vinklar. Multimedialt innehållsskapande är inte längre valfritt—organisationer måste investera i att skapa högkvalitativa bilder, videor och interaktivt innehåll som kompletterar textinnehållet. Implementering av strukturerad data blir avgörande, då schemamarkup hjälper MUM att förstå innehållets struktur och relationer. Entitetsbyggande och semantisk optimering hjälper till att etablera ämnesauktoritet och förbättra hur MUM tolkar innehållssamband. Flerspråkig innehållsstrategi ökar i betydelse, eftersom MUM:s språköverföringskapaciteter innebär att innehåll kan upptäckas på flera marknader. Kartläggning av användaravsikt blir mer avancerad, och kräver att organisationer förstår inte bara primär avsikt utan också relaterade frågor och underteman användare kan utforska. Innehållets aktualitet och korrekthet blir viktigare när MUM syntetiserar information från flera källor—föråldrat eller felaktigt innehåll kan prioriteras ned. Optimering över plattformar sträcker sig utöver Google Sök och inkluderar hur innehållet syns i AI-system som Google AI Overviews, Perplexity och andra AI-drivna sökgränssnitt. E-E-A-T-signaler (Erfarenhet, Expertis, Auktoritet, Trovärdighet) blir allt viktigare när MUM prioriterar innehåll från auktoritativa källor. Organisationer som anpassar sina strategier för att matcha MUM:s kapacitet—fokuserar på heltäckande, multimodalt, välstrukturerat innehåll som visar expertis och auktoritet—kommer att behålla synlighet i detta föränderliga söklandskap.
Framtida utveckling och strategiska utsikter
MUM är inte en slutdestination utan en hållplats i utvecklingen av AI-drivna sökningar. Google har indikerat att MUM kommer att fortsätta utöka sina kapaciteter, med alltmer sofistikerad video- och ljudbearbetning. Företaget forskar aktivt på hur man kan minska MUM:s beräkningsavtryck samtidigt som prestandan bibehålls eller förbättras, för att möta hållbarhetsutmaningar kring storskaliga AI-modeller. Integrationen av MUM med andra Google-tekniker antyder framtida utveckling där MUM:s förståelse driver inte bara sök utan även Google Assistant, Google Lens och andra produkter. Konkurrenstryck från andra AI-system som OpenAI:s ChatGPT, Anthropics Claude och Perplexitys AI-sökmotor gör att MUM sannolikt kommer att fortsätta utvecklas för att bibehålla Googles konkurrensfördel. Regulatorisk granskning av AI-system kan påverka hur MUM utvecklas, särskilt vad gäller bias, rättvisa och transparens. Användarbeteendets anpassning kommer att forma hur MUM utvecklas—när användare vänjer sig vid rikare, mer interaktiva sökupplevelser kommer förväntningarna på sökkvalitet och heltäckande svar att öka. Den generativa AI:n:s framväxt innebär att MUM:s kapacitet för att syntetisera och generera information sannolikt kommer att bli mer framträdande, och kan göra det möjligt för MUM att skapa originalinnehåll istället för att bara hämta och organisera existerande information. Multimodal AI som standard antyder att MUM:s tillvägagångssätt att bearbeta flera format samtidigt kommer att bli norm istället för undantag bland AI-system. Integritet och dataskydd kommer att påverka hur MUM använder användardata och beteendesignaler för att personanpassa och förbättra resultat. Organisationer bör förbereda sig för fortsatt utveckling genom att bygga flexibla, anpassningsbara innehållsstrategier som prioriterar kvalitet, heltäckande täckning och teknisk excellens snarare än att förlita sig på specifika taktiker som kan bli föråldrade när MUM utvecklas. Den grundläggande principen—att skapa innehåll som verkligen tillgodoser användarens avsikt över flera format och språk—kommer att förbli relevant oavsett hur MUM:s specifika kapaciteter utvecklas.