
AI-innehållssyndikeringsnätverk
Lär dig vad AI-innehållssyndikeringsnätverk är, hur de fungerar och varför de är avgörande för modern innehållsdistribution. Upptäck hur AI-optimering förbättra...
7 min läsning
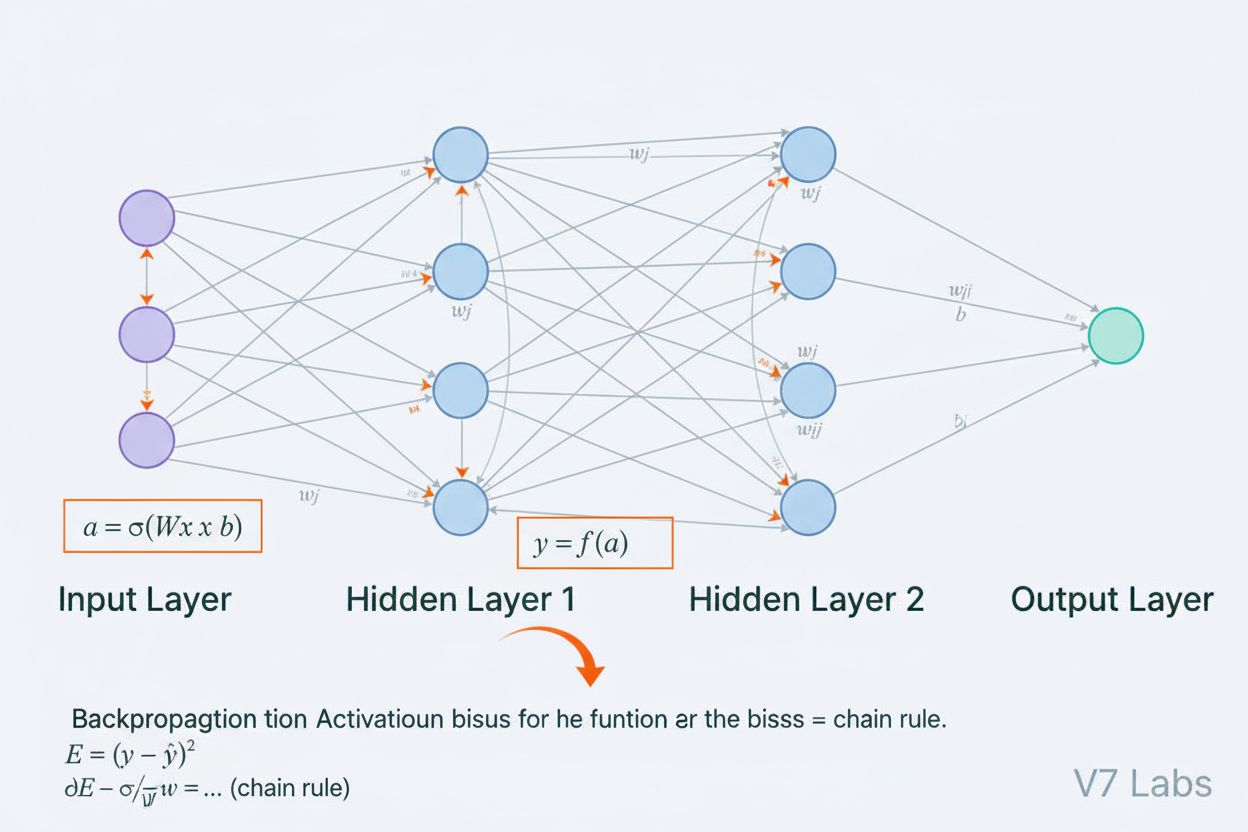
Ett neuralt nätverk är ett datorsystem inspirerat av biologiska neurala nätverk som består av sammankopplade artificiella neuroner organiserade i lager, kapabla att lära sig mönster från data genom en process som kallas backpropagation. Dessa system utgör grunden för modern artificiell intelligens och djupinlärning, och driver applikationer från naturlig språkbehandling till datorseende.
Ett neuralt nätverk är ett datorsystem inspirerat av biologiska neurala nätverk som består av sammankopplade artificiella neuroner organiserade i lager, kapabla att lära sig mönster från data genom en process som kallas backpropagation. Dessa system utgör grunden för modern artificiell intelligens och djupinlärning, och driver applikationer från naturlig språkbehandling till datorseende.
Ett neuralt nätverk är ett datorsystem som i grunden är inspirerat av strukturen och funktionen hos biologiska neurala nätverk som finns i djurhjärnor. Det består av sammankopplade artificiella neuroner organiserade i lager—typiskt ett indata-lager, ett eller flera dolda lager och ett utdata-lager—som samarbetar för att bearbeta data, känna igen mönster och göra prediktioner. Varje neuron tar emot indata, applicerar matematiska transformationer via vikter och bias, och skickar resultatet genom en aktiveringsfunktion för att producera en utdata. Den avgörande egenskapen hos neurala nätverk är deras förmåga att lära sig från data genom en iterativ process som kallas backpropagation, där nätverket justerar sina interna parametrar för att minimera prediktionsfel. Denna inlärningsförmåga, i kombination med deras kapacitet att modellera komplexa icke-linjära samband, har gjort neurala nätverk till den grundläggande tekniken som driver modern artificiell intelligens, från stora språkmodeller till applikationer inom datorseende.
Konceptet artificiella neurala nätverk uppstod ur tidiga försök att matematiskt modellera hur biologiska neuroner kommunicerar och bearbetar information. År 1943 föreslog Warren McCulloch och Walter Pitts den första matematiska modellen av en neuron, och visade att enkla beräkningsenheter kunde utföra logiska operationer. Denna teoretiska grund följdes av Frank Rosenblatts introduktion av perceptron 1958, en algoritm utvecklad för mönsterigenkänning som blev den historiska föregångaren till dagens sofistikerade neurala nätverksarkitekturer. Perceptron var i grunden en linjär modell med begränsad utdata, kapabel att lära sig enkla beslutgränser. Fältet drabbades dock av stora bakslag under 1970-talet när forskare upptäckte att enskiktsperceptroner inte kunde lösa icke-linjära problem som XOR-funktionen, vilket ledde till det så kallade “AI-vintern”. Genombrottet kom på 1980-talet med återupptäckten och förfiningen av backpropagation, en algoritm som möjliggjorde träning av flerskiktsnätverk. Denna återkomst accelererade dramatiskt under 2010-talet med tillgången på enorma datamängder, kraftfulla GPU:er och förfinade träningstekniker, vilket ledde till den djupinlärningsrevolution som omvandlade artificiell intelligens.
Ett neuralt nätverks arkitektur består av flera grundläggande komponenter som arbetar tillsammans. Indatalagret tar emot råa datafunktioner från externa källor, där varje neuron i detta lager motsvarar en funktion. Dolda lager utför det beräkningsmässiga tunga arbetet och transformerar indata till alltmer abstrakta representationer genom viktade kombinationer och icke-linjära aktiveringsfunktioner. Antalet och storleken på de dolda lagren avgör nätverkets kapacitet att lära sig komplexa mönster—djupare nätverk kan fånga mer sofistikerade samband men kräver mer data och beräkningsresurser. Utdatalagret producerar de slutliga prediktionerna, och dess struktur beror på uppgiften: en neuron för regression, flera neuroner för multiklassklassificering eller specialiserade arkitekturer för andra applikationer. Varje koppling mellan neuroner har en vikt som avgör styrkan i påverkan, medan varje neuron har en bias som förskjuter dess aktiveringströskel. Dessa vikter och bias är de lärbara parametrarna som nätverket justerar under träning. Aktiveringsfunktionen som appliceras på varje neuron introducerar avgörande icke-linearitet, vilket gör det möjligt för nätverket att lära sig komplexa beslutgränser och mönster som linjära modeller inte kan fånga.
Neurala nätverk lär sig genom en tvåfasig iterativ process. Under framåtpropagering flödar indata genom nätverket från indata-lagret till utdata-lagret. Vid varje neuron beräknas den viktade summan av indata plus bias (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), som sedan skickas genom en aktiveringsfunktion för att producera neuronens utdata. Denna process upprepas genom varje dolt lager tills utdata-lagret nås, vilket producerar nätverkets prediktion. Nätverket beräknar sedan felet mellan sin prediktion och det sanna värdet med hjälp av en förlustfunktion, som kvantifierar hur långt prediktionen är från det korrekta svaret. Vid backpropagation propageras detta fel bakåt genom nätverket med hjälp av kedjeregeln i kalkyl. Vid varje neuron beräknar algoritmen gradienten av förlusten med avseende på varje vikt och bias, och avgör hur mycket varje parameter bidrog till det totala felet. Dessa gradienter styr parameteruppdateringarna: vikter och bias justeras i motsatt riktning mot gradienten, skalat med en inlärningshastighet som styr steglängden. Denna process upprepas genom många iterationer över träningsdatan, vilket gradvis minskar förlusten och förbättrar nätverkets prediktioner. Kombinationen av framåtpropagering, förlustberäkning, backpropagation och parameteruppdateringar utgör hela träningscykeln som gör det möjligt för neurala nätverk att lära sig från data.
| Arkitekturtyp | Primärt användningsområde | Nyckelkaraktäristik | Styrkor | Begränsningar |
|---|---|---|---|---|
| Feedforward-nätverk | Klassificering, regression på strukturerad data | Information flödar bara i en riktning | Enkel, snabb träning, tolkbar | Klarar inte sekventiell eller spatial data bra |
| Konvolutionella neurala nätverk (CNN:er) | Bildigenkänning, datorseende | Konvolutionella lager detekterar spatiala funktioner | Utmärkt på att fånga lokala mönster, parameter-effektiva | Kräver stora märkta bilddatamängder |
| Rekurrenta neurala nätverk (RNN:er) | Sekventiell data, tidsserier, NLP | Dolt tillstånd bibehåller minne över tidssteg | Kan bearbeta sekvenser av varierande längd | Lider av försvinnande/exploderande gradienter |
| Long Short-Term Memory (LSTM) | Långdistansberoenden i sekvenser | Minnesceller med in-/glömske-/utgångsportar | Hanterar långvariga beroenden effektivt | Mer komplexa, långsammare träning än RNN:er |
| Transformer-nätverk | Naturlig språkbehandling, stora språkmodeller | Multi-head attention-mekanism, parallell bearbetning | Mycket parallelliserbara, fångar långdistansberoenden | Kräver massiva beräkningsresurser |
| Generative Adversarial Networks (GAN:er) | Bildgenerering, syntetisk dataskapning | Generator- och diskriminatornätverk tävlar | Kan generera realistisk syntetisk data | Svåra att träna, problem med mode collapse |
Införandet av aktiveringsfunktioner är en av de viktigaste innovationerna i designen av neurala nätverk. Utan aktiveringsfunktioner skulle ett neuralt nätverk vara matematiskt ekvivalent med en enda linjär transformation, oavsett hur många lager det innehåller. Detta eftersom sammansättningen av linjära funktioner också är linjär, vilket kraftigt begränsar nätverkets förmåga att lära sig komplexa mönster. Aktiveringsfunktioner löser detta problem genom att införa icke-linearitet i varje neuron. ReLU (Rectified Linear Unit)-funktionen, definierad som f(x) = max(0, x), har blivit det mest populära valet inom modern djupinlärning tack vare sin beräkningsmässiga effektivitet och effektivitet vid träning av djupa nätverk. Sigmoidfunktionen, f(x) = 1/(1 + e^(-x)), trycker utdata till ett intervall mellan 0 och 1, vilket gör den användbar för binär klassificering. Tanh-funktionen, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), ger utdata mellan -1 och 1 och presterar ofta bättre än sigmoid i dolda lager. Valet av aktiveringsfunktion påverkar nätverkets inlärningsdynamik, konvergenshastighet och slutliga prestanda avsevärt. Moderna arkitekturer använder ofta ReLU i dolda lager för dess beräkningsmässiga effektivitet och sigmoid eller softmax i utdata-lager för sannolikhetsuppskattning. Den icke-linearitet som aktiveringsfunktioner tillför gör att neurala nätverk kan approximera vilken kontinuerlig funktion som helst, en egenskap som kallas universella approximationssatsen, vilket förklarar deras anmärkningsvärda mångsidighet över olika tillämpningar.
Marknaden för neurala nätverk har upplevt explosiv tillväxt, vilket speglar teknikens centrala roll inom modern artificiell intelligens. Enligt färsk marknadsforskning värderades den globala marknaden för programvara för neurala nätverk till cirka 34,76 miljarder dollar år 2025 och förväntas nå 139,86 miljarder dollar år 2030, vilket motsvarar en årlig tillväxttakt (CAGR) på 32,10%. Den bredare marknaden för neurala nätverk uppvisar en ännu mer dramatisk expansion, med uppskattningar som tyder på en ökning från 34,05 miljarder dollar år 2024 till 385,29 miljarder dollar år 2033, med en CAGR på 31,4%. Denna explosiva tillväxt drivs av flera faktorer: ökad tillgång till stora datamängder, utveckling av effektivare träningalgoritmer, spridning av GPU:er och specialiserad AI-hårdvara samt den utbredda användningen av neurala nätverk inom olika branscher. Enligt Stanfords AI Index Report 2025 rapporterade 78 % av organisationerna att de använde AI år 2024, upp från 55 % året innan, där neurala nätverk utgör ryggraden i de flesta AI-implementationer inom företag. Användningen sträcker sig över sjukvård, finans, tillverkning, detaljhandel och praktiskt taget alla andra sektorer, då organisationer inser den konkurrensfördel neurala nätverksbaserade system ger för mönsterigenkänning, prediktion och beslutsfattande.
Neurala nätverk driver de mest avancerade AI-systemen som används idag, inklusive ChatGPT, Perplexity, Google AI Overviews och Claude. Dessa stora språkmodeller är byggda på transformerbaserade neurala nätverksarkitekturer som använder attention-mekanismer för att bearbeta och generera mänskligt språk med imponerande sofistikation. Transformerarkitekturen, som introducerades 2017, revolutionerade naturlig språkbehandling genom att möjliggöra parallell bearbetning av hela sekvenser i stället för sekventiell bearbetning, vilket dramatiskt förbättrade träningseffektivitet och modellprestanda. I kontexten av varumärkesövervakning och AI-citationspårning är förståelsen av neurala nätverk avgörande eftersom dessa system använder neurala nätverk för att förstå kontext, hämta relevant information och generera svar som kan referera till eller citera ditt varumärke, domän eller innehåll. AmICited utnyttjar kunskap om hur neurala nätverk bearbetar och hämtar information för att övervaka var ditt varumärke förekommer i AI-genererade svar över flera plattformar. Eftersom neurala nätverk fortsätter att förbättras i sin förmåga att förstå semantisk betydelse och hämta relevant information blir vikten av att övervaka ditt varumärkes närvaro i AI-svar alltmer kritisk för att upprätthålla varumärkesynlighet och hantera ditt rykte online i en tid av AI-drivna sök- och innehållsgenerering.
Att träna neurala nätverk effektivt innebär flera betydande utmaningar som forskare och praktiker måste hantera. Överanpassning uppstår när ett nätverk lär sig träningsdatan alltför väl, inklusive dess brus och egenheter, vilket leder till dålig prestanda på ny, osedd data. Detta är särskilt problematiskt med djupa nätverk som har många parametrar i förhållande till träningsdatans storlek. Underanpassning är det motsatta problemet, där nätverket saknar tillräcklig kapacitet eller träning för att fånga de underliggande mönstren i datan. Försvinnande gradientproblem uppstår i mycket djupa nätverk där gradienterna blir exponentiellt mindre när de propageras bakåt, vilket gör att vikterna i tidiga lager uppdateras mycket långsamt eller inte alls. Exploderande gradientproblem är motsatsen, där gradienterna blir exponentiellt större, vilket ger instabil träning. Moderna lösningar inkluderar batchnormalisering, som normaliserar lagerindatan för att bibehålla stabil gradientflöde; residual connections (skip connections), som tillåter gradienter att flöda direkt genom lager; samt gradientklippning, som begränsar gradienternas storlek. Regulariseringstekniker som L1- och L2-regularisering ger straff för stora vikter och uppmuntrar enklare modeller som generaliserar bättre. Dropout inaktiverar slumpmässigt neuroner under träning, vilket förhindrar samanpassning och förbättrar generalisering. Valet av optimerare (såsom Adam, SGD eller RMSprop) och inlärningshastighet påverkar träningseffektivitet och slutlig prestanda avsevärt. Praktiker måste noggrant balansera modellens komplexitet, träningsdatans storlek, regulariseringsstyrka och optimeringsparametrar för att uppnå nätverk som lär sig effektivt utan överanpassning.
Utvecklingen av neurala nätverksarkitekturer har följt en tydlig bana mot alltmer sofistikerade mekanismer för informationsbearbetning. Tidiga feedforward-nätverk var begränsade till indata av fast storlek och kunde inte fånga temporala eller sekventiella beroenden. Rekurrenta neurala nätverk (RNN:er) introducerade återkopplingsslingor som möjliggjorde att information kunde kvarstå över flera tidssteg, vilket gjorde det möjligt att bearbeta sekvenser av varierande längd. Men RNN:er drabbades av gradientflödesproblem och var i grunden sekventiella, vilket hindrade parallellisering på modern hårdvara. Long Short-Term Memory (LSTM)-nätverk löste vissa av dessa problem genom minnesceller och portmekanismer, men förblev ändå i grunden sekventiella. Genombrottet kom med transformer-nätverk, som helt ersatte sekvensbaserad återkoppling med attention-mekanismer. Attention-mekanismen gör att nätverket dynamiskt kan fokusera på olika delar av indata och beräkna viktade kombinationer av alla indataelement parallellt. Detta gör att transformers kan fånga långdistansberoenden effektivt och samtidigt vara fullt parallelliserbara över GPU-kluster. Transformerarkitekturen, i kombination med massiv skala (moderna stora språkmodeller innehåller miljarder till triljoner parametrar), har visat sig extremt effektiv för naturlig språkbehandling, datorseende och multimodala uppgifter. Framgången för transformers har lett till att de blivit standardarkitekturen för toppmoderna AI-system, inklusive alla stora språkmodeller. Denna utveckling visar hur arkitekturinnovationer, tillsammans med ökade beräkningsresurser och större datamängder, fortsätter att driva gränserna för vad neurala nätverk kan uppnå.
Fältet neurala nätverk utvecklas snabbt med flera lovande riktningar på horisonten. Neuromorf databehandling syftar till att skapa hårdvara som mer liknar biologiska neurala nätverk och därigenom potentiellt uppnå större energieffektivitet och beräkningskraft. Few-shot- och zero-shot-inlärning fokuserar på att göra det möjligt för neurala nätverk att lära sig från minimala exempel, mer likt mänsklig inlärning. Förklarbarhet och tolkbarhet har blivit allt viktigare, med forskare som utvecklar tekniker för att förstå och visualisera vad neurala nätverk lär sig, vilket är avgörande vid tillämpningar med höga insatser inom exempelvis sjukvård, finans och rättsväsende. Federerad inlärning möjliggör träning av neurala nätverk på distribuerad data utan att centralisera känslig information, vilket adresserar integritetsfrågor. Kvantneurala nätverk är ett område där principer från kvantdatorer kombineras med neurala nätverksarkitekturer, vilket potentiellt kan ge exponentiella hastighetsvinster för vissa problem. Multimodala neurala nätverk som sömlöst integrerar text, bild, ljud och video blir allt mer sofistikerade och möjliggör mer heltäckande AI-system. Energieffektiva neurala nätverk utvecklas för att minska de beräknings- och miljömässiga kostnaderna för att träna och använda stora modeller. I takt med att neurala nätverk fortsätter att utvecklas blir deras integration i AI-övervakningssystem som AmICited allt viktigare för organisationer som vill förstå och hantera sin varumärkesnärvaro i AI-genererat innehåll och svar över plattformar som ChatGPT, Perplexity, Google AI Overviews och Claude.
Neurala nätverk är inspirerade av strukturen och funktionen hos biologiska neuroner i den mänskliga hjärnan. I hjärnan kommunicerar neuroner genom elektriska signaler via synapser, som kan förstärkas eller försvagas baserat på erfarenhet. Artificiella neurala nätverk efterliknar detta beteende genom att använda matematiska modeller av neuroner som är sammankopplade via viktade länkar, vilket gör det möjligt för systemet att lära och anpassa sig från data på ett sätt som liknar hur biologiska hjärnor bearbetar information och bildar minnen.
Backpropagation är den primära algoritmen som gör det möjligt för neurala nätverk att lära sig. Under framåtpropagering flödar data genom nätverkets lager och genererar prediktioner. Nätverket beräknar sedan felet mellan de förutsagda och faktiska utgångarna med en förlustfunktion. Under bakåtpasset propageras detta fel tillbaka genom nätverket med hjälp av kedjeregeln i kalkyl, vilket beräknar hur mycket varje vikt och bias har bidragit till felet. Vikterna justeras sedan i den riktning som minimerar felet, vanligtvis med hjälp av gradientnedstigning.
De primära neurala nätverksarkitekturerna inkluderar feedforward-nätverk (data flödar i en riktning), konvolutionella neurala nätverk eller CNN:er (optimerade för bildbehandling), rekurrenta neurala nätverk eller RNN:er (designade för sekventiell data), long short-term memory-nätverk eller LSTM:er (förbättrade RNN:er med minnesceller) och transformer-nätverk (använder attention-mekanismer för parallell bearbetning). Varje arkitektur är specialiserad för olika typer av data och uppgifter, från bildigenkänning till naturlig språkbehandling.
Moderna AI-system som ChatGPT, Perplexity och Claude är uppbyggda på transformerbaserade neurala nätverk, som använder attention-mekanismer för att bearbeta språk effektivt. Dessa neurala nätverk gör det möjligt för systemen att förstå kontext, generera sammanhängande text och utföra komplexa resonemangsuppgifter. Neurala nätverks förmåga att lära sig från massiva datamängder och fånga invecklade mönster i språk gör dem oumbärliga för att bygga konversations-AI som kan förstå och svara på mänskliga frågor med anmärkningsvärd precision.
Vikter i neurala nätverk styr styrkan i kopplingarna mellan neuroner och avgör hur mycket inflytande varje indata har på utdata. Bias är ytterligare parametrar som förskjuter aktiveringströskeln hos neuroner, vilket gör att de kan aktiveras även när indatan är svag. Tillsammans utgör vikter och bias de lärbara parametrarna i nätverket som justeras under träning för att minimera prediktionsfel och möjliggöra att nätverket kan lära sig komplexa mönster från data.
Aktiveringsfunktioner introducerar icke-linearitet i neurala nätverk och gör det möjligt för dem att lära sig komplexa, icke-linjära samband i data. Utan aktiveringsfunktioner skulle stapling av flera lager fortfarande resultera i linjära transformationer, vilket kraftigt begränsar nätverkets inlärningskapacitet. Vanliga aktiveringsfunktioner inkluderar ReLU (Rectified Linear Unit), sigmoid och tanh, som alla introducerar olika typer av icke-linearitet som hjälper nätverket att fånga detaljerade mönster och göra mer sofistikerade prediktioner.
Dolda lager är mellanliggande lager mellan in- och utgångslager där nätverket utför huvuddelen av sitt beräkningsarbete. Dessa lager extraherar och transformerar funktioner från rå indata till alltmer abstrakta representationer. Djupet och bredden på de dolda lagren avgör nätverkets kapacitet att lära sig komplexa mönster. Djupare nätverk med fler dolda lager kan fånga mer sofistikerade samband i data, men de kräver mer beräkningsresurser och noggrann träning för att undvika överanpassning.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Lär dig vad AI-innehållssyndikeringsnätverk är, hur de fungerar och varför de är avgörande för modern innehållsdistribution. Upptäck hur AI-optimering förbättra...

Lär dig vad Natural Language Processing (NLP) är, hur det fungerar och dess avgörande roll i AI-system. Utforska NLP-tekniker, applikationer och utmaningar inom...
Lär dig vad ett Privat Bloggnätverk (PBN) är, hur det fungerar, varför det bryter mot Googles riktlinjer och riskerna med att använda PBN:er för länkbygge. Omfa...