
AI-citering
Lär dig vad AI-citeringar är, hur de fungerar i ChatGPT, Perplexity och Google AI, och varför de är viktiga för ditt varumärkes synlighet i generativa sökmotore...
12 min läsning

Query-to-citation mapping är processen att analysera och spåra vilka specifika sökfrågor som utlöser citeringar till särskilt innehåll, varumärken eller webbplatser i AI-genererade svar. Det avslöjar sambandet mellan användarens avsikt, frågeformulering och vilka källor AI-modeller väljer som auktoritativa. Detta gör det möjligt för varumärken att förstå och optimera sin synlighet över olika frågetyper och AI-plattformar. Genom att kartlägga frågor till citeringar kan organisationer identifiera mönster i hur AI-system citerar deras innehåll och justera sin innehållsstrategi därefter.
Query-to-citation mapping är processen att analysera och spåra vilka specifika sökfrågor som utlöser citeringar till särskilt innehåll, varumärken eller webbplatser i AI-genererade svar. Det avslöjar sambandet mellan användarens avsikt, frågeformulering och vilka källor AI-modeller väljer som auktoritativa. Detta gör det möjligt för varumärken att förstå och optimera sin synlighet över olika frågetyper och AI-plattformar. Genom att kartlägga frågor till citeringar kan organisationer identifiera mönster i hur AI-system citerar deras innehåll och justera sin innehållsstrategi därefter.
Query-to-citation mapping är processen att analysera och spåra vilka specifika sökfrågor som utlöser citeringar till särskilt innehåll, varumärken eller webbplatser i AI-genererade svar. Till skillnad från traditionell sökrankning, som mäter hur webbplatser visas i resultat med blå länkar, fokuserar query-to-citation mapping särskilt på när och varför AI-system citerar ditt innehåll som källa. Denna distinktion är viktig eftersom en webbplats kan ranka högt i Google men aldrig citeras av ChatGPT, Gemini eller Perplexity—eller omvänt, citeras ofta utan att ranka högt. Att förstå detta samband är avgörande eftersom AI-modeller citerar källor olika beroende på frågeavsikt, användarens plats och plattformsspecifika preferenser, vilket gör det nödvändigt att spåra vilka frågor som faktiskt driver citeringar till ditt varumärke.
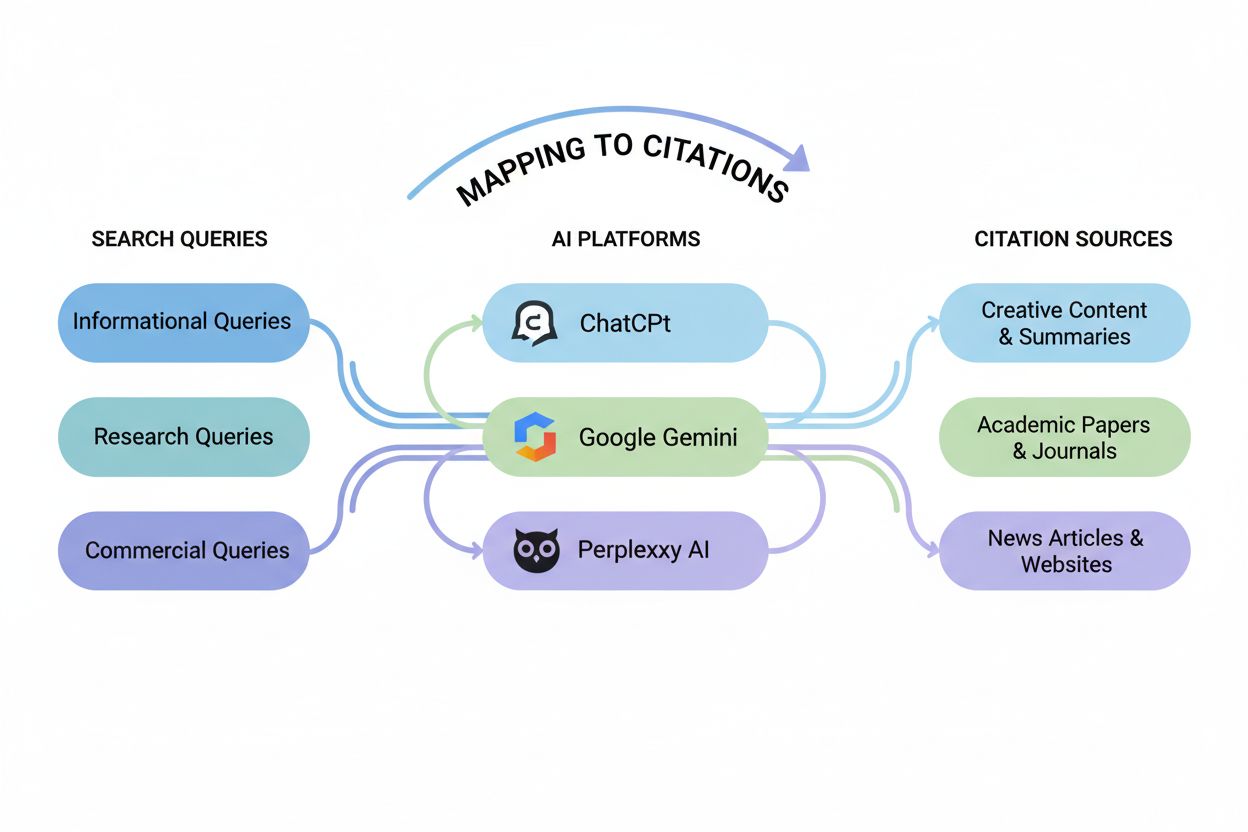
Query-to-citation mapping fungerar genom en systematisk process med frågeanalys, citeringsspårning och upprepade tester över flera AI-plattformar. Processen börjar med att kategorisera frågor längs två dimensioner: varumärkesfrågor kontra icke-varumärkesfrågor (nämner frågan ditt varumärke?) och objektiva kontra subjektiva frågor (frågar den efter fakta eller åsikter?). När frågorna är klassificerade kör forskare dem upprepade gånger genom olika AI-system—ChatGPT, Google Gemini, Perplexity och Google AI Overviews—och registrerar vilka källor varje plattform citerar som svar. Dessa upprepade tester avslöjar ett kritiskt fenomen som kallas citeringsdrift: tendensen hos AI-system att rotera mellan olika källor även när de besvarar samma fråga flera gånger. Citeringsdrift uppstår eftersom stora språkmodeller inte “rankar” källor på samma sätt som traditionella sökmotorer; istället samplar de dynamiskt från en pool av relevanta dokument för att balansera variation, auktoritet och aktualitet i varje svar.
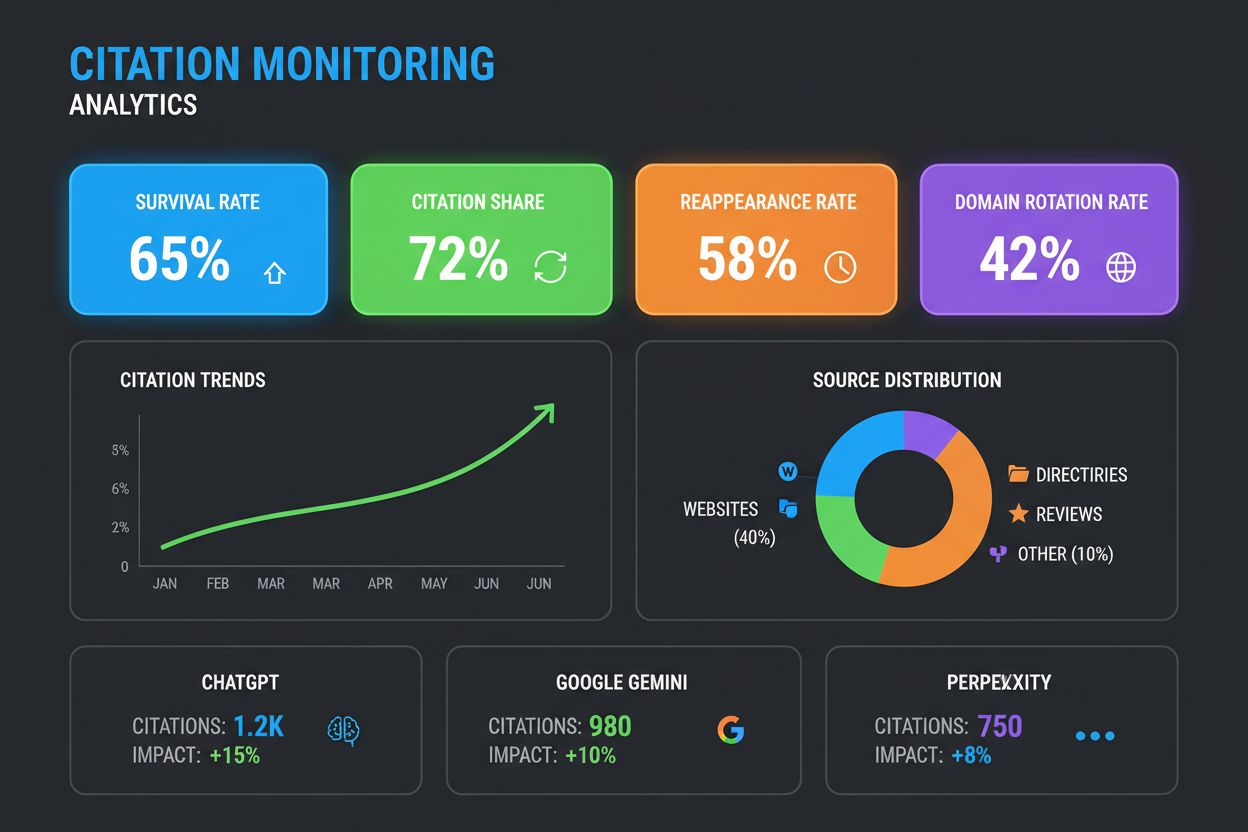
För att mäta och hantera citeringsdrift effektivt spårar varumärken flera nyckelmetrik som visar om deras synlighet är hållbar eller kortvarig:
| Metrik | Vad den mäter | Formel | Exempel |
|---|---|---|---|
| Överlevnadsgrad | Hur länge ditt varumärke är synligt utan avbrott | (antalet på varandra följande synliga körningar) ÷ (totalt antal körningar) | Citerad i 4 på varandra följande körningar av 10: 40% |
| Återuppträdandegrad | Hur ofta ditt varumärke återfår synlighet efter att ha försvunnit | (antal gånger varumärket återkommer) ÷ (totalt antal bortfall) | Försvann 5 gånger, återkom 3: 60% |
| Citeringsandel | Hur ofta ditt varumärke citeras över upprepade körningar | (antal körningar där varumärket citeras) ÷ (totalt antal körningar) | Citerad i 7 av 10 körningar: 70% |
| Domänrotationsgrad | Hur ofta den citerade URL:en från din domän ändras över körningar | (antal körningar med annan URL än föregående) ÷ (totalt antal körningar) | URL ändras 5 gånger på 10 körningar: 50% |
| Konkurrensersättningsgrad | Hur ofta ditt varumärke ersätts av en konkurrents citering | (antal körningar ersatt av konkurrent) ÷ (totalt antal körningar) | Citerad i 6, ersatt i 3 av 10: 30% |
Typen av fråga påverkar kraftigt vilka källor AI-systemen citerar, vilket gör analys av frågeavsikt avgörande för synlighetsstrategin. Frågor delas in i fyra kategorier: varumärkes objektiv (t.ex. “Salesforce-priser”), varumärkes subjektiv (t.ex. “Är Salesforce värt det?”), icke-varumärkes objektiv (t.ex. “Vad är CRM-programvara?”) och icke-varumärkes subjektiv (t.ex. “Vilken är den bästa CRM-programvaran?”). Varje kategori utlöser olika citeringsmönster eftersom AI-systemen justerar sin källstrategi utifrån vad användaren försöker uppnå. För objektiva frågor prioriterar AI-modeller saklig noggrannhet och citerar auktoritativa källor som varumärkessajter, Wikipedia och officiell dokumentation. För subjektiva frågor förlitar de sig mer på recensioner, expertutlåtanden och tredjepartsjämförelser för att ge balanserade perspektiv. Dessutom visar B2B- och B2C-frågor tydliga mönster: B2B-frågor (som “bästa CRM-leverantörer”) citerar branschpublikationer, analytikerrapporter och företagswebbplatser oftare, medan B2C-frågor (som “bästa smartphones”) oftare inkluderar konsumentrecensioner, teknikbloggar och mainstreammedia. Att förstå dessa mönster är avgörande eftersom det visar att ett enskilt varumärke inte kan förvänta sig samma citeringsgrad för alla frågetyper—istället måste varumärken optimera olika innehåll för olika frågeavsikter för att maximera sin totala synlighet i AI-genererade svar.
Varje stor AI-plattform har utvecklat distinkta preferenser för källor som påverkar vilka varumärken som citeras. ChatGPT föredrar starkt etablerade, auktoritativa källor, där Wikipedia står för 27 % av citeringarna, följt av större nyhetsmedier som Reuters och Financial Times. Denna preferens för auktoritet gör att ChatGPT sällan citerar användargenererat innehåll eller leverantörsbloggar, vilket gör det avgörande för varumärken att etablera närvaro i neutrala, referensliknande material och stora publikationer. Google Gemini har en mer balanserad strategi, där bloggar (39 %), nyheter (26 %) och YouTube (3 %) citeras i liknande utsträckning, samtidigt som visst communityinnehåll inkluderas. Denna mångfald gör Gemini mer tillgänglig för mellanstora varumärken som inte kan dominera Wikipedia men kan skapa kvalitetsblogginnehåll. Perplexity AI betonar expertkällor och specialiserade recensionssajter, med branschspecifika kataloger som NerdWallet och Consumer Reports som ofta dyker upp tillsammans med bloggar och nyheter. För Perplexity bör strategin fokusera på att bygga närvaro på auktoritativa nischsajter och ansedda recensionsplattformar inom din bransch. Google AI Overviews har störst bredd och hämtar från bloggar (46 %), nyheter (20 %), communityinnehåll som Reddit (4 %) och även LinkedIn-artiklar, vilket gör dem till den mest tillgängliga plattformen för olika varumärken. Den viktiga insikten är att ingen enskild optimeringsstrategi fungerar över alla plattformar—varumärken måste anpassa sin strategi efter varje plattforms källpreferenser och bygga närvaro i de specifika källtyper som prioriteras av respektive plattform.
Att förstå vilka citeringskällor du kan påverka är grundläggande för query-to-citation mapping-strategin. Forskning på 6,8 miljoner AI-citeringar visar att varumärken kan kategoriseras i fyra kontrollnivåer: Full kontroll omfattar varumärkesägda webbplatser och egendomar (över 40 % av citeringarna), där du har full kontroll över innehållet. Kontrollerbara källor är tredjepartslistningar och kataloger som Google Business Profile, Mapquest och branschspecifika plattformar (ytterligare 40 % av citeringarna), där du kan hävda och hantera din profil men inte äger plattformen. Påverkade källor är recensioner och socialt innehåll på plattformar som Google Reviews, Yelp och Facebook (5–10 % av citeringarna), där du inte kan skapa innehåll direkt men kan svara och uppmuntra kundfeedback. Okontrollerade källor är nyheter, forum och annat tredjepartsinnehåll (5–10 % av citeringarna) där du inte har direkt påverkan. Den mest kraftfulla upptäckten är att varumärken direkt kan kontrollera eller påverka cirka 86 % av alla konsumentinriktade citeringar, en kontrollnivå som bara blir synlig vid analys på plats- och frågenivå snarare än på varumärkesnivå. Detta innebär att vägen till förbättrad AI-synlighet inte är mystisk eller beroende av tur—det handlar om att strategiskt hantera de källor du kan påverka samtidigt som du bygger auktoritet i de källor du kan kontrollera.
Effektiv mätning av query-to-citation-mönster kräver ett systematiskt tillvägagångssätt som fångar både kortsiktig volatilitet och långsiktiga trender. Processen börjar med upprepade tester: välj ett antal värdefulla frågor (informationssökande, kommersiella och varumärkesrelaterade) och kör dem flera gånger över olika svarsplattformar, och registrera om ditt varumärke citeras, nämns eller saknas i varje körning. Forskning visar att endast cirka 30 % av varumärkena behåller synlighet för en given fråga i AI-sökresultat vid upprepade körningar, vilket understryker varför upprepade tester är avgörande för att förstå verkliga synlighetsmönster. Nästa steg är att spåra överlevnadsgrad genom att mäta hur många på varandra följande körningar ditt varumärke förblir synligt, vilket hjälper till att skilja ut sidor med hållbar auktoritet från de som snabbt försvinner. Därefter övervaka fluktuationer genom att spåra när och hur ofta ditt varumärke återkommer efter att ha försvunnit—hög återuppträdandegrad indikerar stark ämnesauktoritet även om du inte syns varje gång. Det är också viktigt att klassificera driftens typ: domänrotation (din sajt växlar mellan olika URL:er) är positivt och signalerar ämnesdjup, medan konkurrensersättning (en konkurrent ersätter din citering) är negativt och kräver åtgärder. När det gäller mätningsfrekvens är bästa praxis att mäta över flera tidsfönster, inte bara en enda frekvens—daglig mätning avslöjar kortsiktig volatilitet, veckovis visar återkommande mönster och månadsvis avslöjar om synligheten är hållbar eller i riskzonen. Slutligen, tolka data genom att jämföra dina metrik mot konkurrenter och branschstandarder för att förstå om dina citeringsmönster förbättras, försämras eller stagnerar över tid.
Att förbättra din query-to-citation-synlighet kräver en mångfacetterad strategi som adresserar innehållskvalitet, ämnesauktoritet och plattformsnärvaro. De mest effektiva metoderna inkluderar:
Flera plattformar erbjuder nu specialiserade verktyg för att spåra och analysera query-to-citation-mönster, vilket gör det enklare för varumärken att förstå och optimera sin AI-synlighet. AmICited.com erbjuder övervakning av AI-svar speciellt utformad för att spåra hur ditt varumärke citeras i GPT:er, Perplexity och Google AI Overviews, så att du får realtidsinsyn i vilka frågor som utlöser citeringar till ditt innehåll. Conductor erbjuder en företagsanpassad AI-synlighetsplattform som spårar citeringar tillsammans med traditionella sökmetrik, vilket hjälper team att förstå hur AI-sök påverkar deras övergripande organiska strategi. AirOps är specialiserade på att mäta och hantera citeringsdrift och tillhandahåller detaljerade metrik på överlevnadsgrad, återuppträdandegrad och citeringsandel för att hjälpa varumärken förstå hållbarheten i sin synlighet. Yext Scout har ett platsfokuserat tillvägagångssätt för citeringsanalys och visar hur citeringsmönster varierar mellan geografiska marknader och hjälper varumärken med flera platser att optimera lokalt. Rankscale.ai ger omfattande citeringsdataanalys över flera AI-motorer, vilket möjliggör detaljerad jämförelse av hur olika plattformar citerar ditt innehåll. Nyckeln till framgång är inte bara att ha tillgång till dessa verktyg, utan att använda dem konsekvent för att spåra mönster över tid, identifiera vilka frågor och plattformar som driver de mest värdefulla citeringarna och justera din innehållsstrategi utifrån datadrivna insikter snarare än antaganden om hur AI-system fungerar.
Traditionell SEO fokuserar på hur webbplatser rankas för specifika nyckelord i sökresultat, medan query-to-citation mapping spårar vilka frågor som får AI-system att citera ditt innehåll som källa. En webbplats kan ranka högt för ett nyckelord men ändå inte citeras av AI-modeller, eller tvärtom. Query-to-citation mapping är specifikt för AI-genererade svar och kräver förståelse för hur olika AI-plattformar väljer och citerar källor baserat på frågeavsikt och kontext.
Bästa praxis är att mäta citeringsdrift över flera tidsfönster istället för att bara lita på en enda frekvens. Daglig mätning avslöjar kortsiktig volatilitet, veckovis mätning kan visa återkommande mönster och månadsöversikter visar om din synlighet är hållbar eller riskerar att försvinna. Du bör också göra upprepade tester med samma fråga och jämföra dessa ögonblicksbilder mot resultat från olika tidsramar för att fånga både omedelbara svängningar och långsiktiga trender.
Ja, citeringsdrift kan vara positivt när det drivs av URL-rotation inom din egen domän. Om flera starka sidor från din webbplats roterar in och ut ur AI-citeringar signalerar det ämnesdjup och varumärkesauktoritet. Den verkliga risken uppstår när drift ersätter ditt innehåll med konkurrenters citeringar, vilket minskar din synlighet. Positiv drift indikerar att ditt varumärke har flera auktoritativa sidor som AI-systemen känner igen som värdefulla källor.
Svaret beror på din målgrupp och affärsmål. ChatGPT prioriterar auktoritativa källor som Wikipedia och nyhetsmedier, vilket gör den idealisk för varumärkesauktoritet. Google Gemini och AI Overviews erbjuder bred räckvidd med varierande källtyper. Perplexity betonar expert- och recensionssajter, värdefullt för nischade branscher. Google AI Overviews är särskilt viktiga eftersom de visas i Googles sökresultat. En diversifierad strategi som riktar sig mot alla större plattformar ger oftast bäst resultat.
Frågeavsikten påverkar dramatiskt citeringsmönster. Objektiva frågor (faktabaserade som 'Vad är X?') tenderar att citera auktoritativa källor och varumärkessajter. Subjektiva frågor (åsiktsbaserade som 'Vilken är den bästa X?') förlitar sig mer på recensioner, kataloger och expertsajter. Varumärkesfrågor citerar oftare förstahandsinnehåll, medan icke-varumärkesfrågor drar från bredare källor. B2B-frågor favoriserar branschpublikationer och kataloger, medan B2C-frågor inkluderar konsumentrecensioner och mainstreammedier. Att förstå dessa mönster hjälper dig att optimera innehåll för de särskilda frågetyper din målgrupp använder.
De snabbaste förbättringarna kommer från att optimera befintligt innehåll för tydlighet och anpassning till frågeavsikt. Se till att ditt innehåll har tydliga rubriker som matchar vanliga frågor, placera svar tidigt i avsnitt och använd format som listor och tabeller för att göra det lätt för AI-system att extrahera. Samtidigt bör du stärka auktoritetssignaler genom kvalitetslänkar och omnämnanden från tredje part. Att bygga ämnesdjup med flera sidor om relaterade ämnen tar längre tid men skapar mer hållbar synlighet. De flesta varumärken ser märkbara förbättringar inom 4–8 veckor efter att ha implementerat dessa strategier.
Platskontext påverkar kraftigt vilka källor AI-system citerar. För platsspecifika frågor (som 'bästa restauranger nära mig') viktar AI-modeller förstahandssajter och lokala listningar högt. Samma varumärke kan ha 70 % citeringsgrad i landsbygdsområden men bara 20 % i konkurrensutsatta storstäder där aggregatorer dominerar. Geografiska variationer gör nationella mått mindre användbara för lokal synlighetsstrategi. Varumärken med flera platser bör analysera citeringsmönster på platsnivå för att förstå var de vinner och förlorar synlighet.
Varumärkesfrågor (som innehåller ditt varumärkesnamn) citerar oftast förstahandsinnehåll eftersom användarna specifikt söker information om ditt varumärke. Icke-varumärkesfrågor (som 'bästa CRM-programvara') innebär att ditt varumärke konkurrerar med många alternativ, och AI-systemen kan föredra tredjepartsrecensioner eller jämförelser för objektivitet. För att förbättra citeringar på icke-varumärkesfrågor, skapa omfattande jämförelseinnehåll, bygg närvaro på recensions- och katalogsajter och etablera ämnesauktoritet genom flera sidor som adresserar olika aspekter av din kategori. Detta signalerar för AI-system att ditt varumärke är en trovärdig källa även när det inte nämns explicit i frågan.
Spåra vilka frågor som utlöser citeringar till ditt varumärke i ChatGPT, Perplexity, Google AI Overviews och andra AI-plattformar. Få insikter i realtid om din AI-synlighet och optimera din innehållsstrategi.
Lär dig vad AI-citeringar är, hur de fungerar i ChatGPT, Perplexity och Google AI, och varför de är viktiga för ditt varumärkes synlighet i generativa sökmotore...

Lär dig vad citeringsoptimering för AI är och hur du optimerar ditt innehåll för att bli citerad av ChatGPT, Perplexity, Google Gemini och andra AI-sökmotorer....

Lär dig hur du formaterar innehåll för maximal synlighet i Perplexity-citat. Bemästra citerbart innehåll, schema-markering och citeringsstrategier för att domin...