AI模型在答案中如何决定引用哪些来源
了解ChatGPT、Perplexity和Gemini等AI模型如何选择被引用的来源。理解AI引用机制、排名因素以及AI可见性优化策略。
1 分钟阅读
AI生成答案已成为数百万用户的主要信息发现方式,彻底改变了互联网信息的流动方式。最新研究显示,2025年研究人员中AI使用率跃升至84%,其中62%专门用AI工具进行科研与发表任务——相比2024年总AI使用率的57%大幅增长。然而,大多数内容创作者并不了解,AI生成答案中的引用位置并非随机决定,而是遵循一套复杂的技术架构,决定了哪些来源能获得可见性,哪些则被忽略。了解引用出现的位置及其原因,对于希望在AI驱动的信息发现环境中保持可见性的内容创作者而言,已变得至关重要。
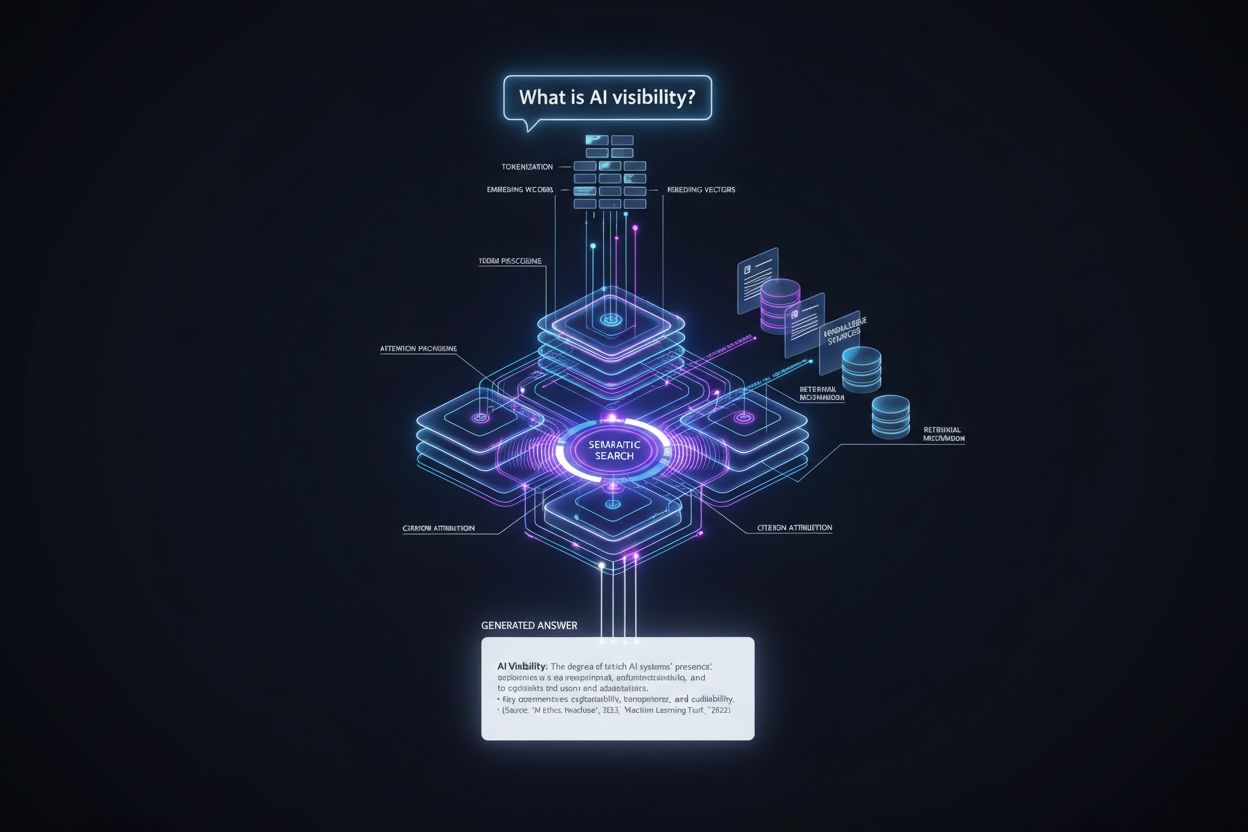
模型原生合成与**检索增强生成(RAG)**的区别,根本上决定了AI回答中引用的呈现方式。模型原生合成完全依赖训练期间编码的知识,而RAG则动态检索外部来源,为回答提供最新的事实基础。这一差异对引用位置和可见性有着深远影响。
| 特征 | 模型原生合成 | RAG |
|---|---|---|
| 定义 | 仅依赖训练数据生成答案 | 基于实时检索到的来源生成答案 |
| 速度 | 更快(无需检索) | 较慢(需检索步骤) |
| 准确性 | 可能出现幻觉和信息过时 | 依赖最新来源,准确性更高 |
| 引用能力 | 引用有限或缺失 | 引用丰富且可追溯 |
| 适用场景 | 常识、创意类任务 | 新闻、科研、事实核查、专有数据 |
像Perplexity和Google AI Overviews这类RAG系统,天然会生成更多引用,因为需要标明信息来源;而传统ChatGPT等模型原生方法则引用更少。了解平台采用哪种方式,有助于内容创作者预判被引用概率并进行优化。
从用户提问到答案被引用,整个过程遵循精确的技术流程,在多个环节决定引用位置。具体流程如下:
各大AI平台引用位置差异显著,为内容创作者带来不同的曝光机会。主要平台引用方式如下:
这意味着,Perplexity引用的来源可能直接获得流量,而同一来源在ChatGPT中若只出现在“来源”面板,则用户不点击就看不到。平台差异直接影响流量和可见性。

引用位置的决策早在答案生成前的检索系统环节就已开始。语义搜索将用户查询和索引文档都转化为向量嵌入(捕捉语义而非关键词的数字表示),系统随后计算查询与文档嵌入的相似度分数,找出最贴合用户意图的来源。
排序算法再根据多种信号重新排序候选项:相关分数、域名权威性、内容新鲜度、用户互动指标、结构化数据质量等。检索阶段得分最高的来源,更有可能进入生成模型的上下文窗口,也就更容易被引用。因此,结构清晰、语义明确且权威域名下的文章,比结构差、新域名下的内容,即使信息同样准确,也被检索和引用的概率更高。检索环节本质上预先筛选了引用池。
内容结构不仅仅是用户体验问题——它直接决定AI系统能否提取、理解并引用您的内容。AI模型依赖格式线索判断信息边界与关系。以下结构有助于提升被引用概率:
符合这些结构原则的内容,被引用概率是结构不佳内容的2-3倍,无论其本身质量如何,因为AI更易提取与归属。
当来源被检索并组装进上下文窗口后,模型会多维度评估每个来源的可信度,决定是否引用。来源可信度评估包括域名权威性(如外链、域名历史、品牌认知)、作者专业度(如署名、作者简介、资质信号)、主题相关性(来源主旨是否与查询匹配)。
相关性评分则衡量来源对具体查询的直接性,精准匹配答案得分更高。新鲜度因素影响新闻、科研、快节奏领域中对新来源的优先级。权威信号包含被其它权威来源引用、学术数据库收录、知识图谱中的表现。元数据影响则体现在标题标签、meta描述、结构化数据能否明确传达内容目的和可信度。最后,结构化数据(Schema.org标记)为模型提供可直接解析的可信信号,包括作者资质、发布日期、评审评分、事实核查状态等。完善schema标记的来源被引用更稳定,因为模型获得了机器可读的明确论断。
AI平台采用不同的引用样式,影响用户对引用的可见性。常见模式有:
内嵌引用(Perplexity风格):
“根据近期研究,2025年研究人员中AI使用率跃升至84%[1],其中62%专门用AI工具进行科研任务[2]。”
段末引用(Claude风格):
“2025年研究人员AI使用率升至84%,其中62%专门用AI工具进行科研任务。[来源:Wiley Research Report, 2025]”
脚注式引用(学术风格):
“2025年研究人员AI使用率升至84%¹,62%专门用AI工具进行科研任务²。”
来源列表(ChatGPT风格):
答案正文无内嵌引用,结尾附有“来源”区,列出3-5个链接。
悬浮引用(新兴模式):
下划线文本,鼠标悬停时显示来源信息,兼顾美观与可追溯性。
不同样式影响用户行为:内嵌引用便于即时点击,来源列表需用户主动操作,悬浮引用兼顾可见性与美观。各平台引用概率不同,多平台监测尤为重要。
理解引用位置的机制,能带来直接的业务收益。流量影响最为明显:被Perplexity内嵌引用的来源,获得的引荐流量是仅出现在ChatGPT“来源”面板中的3-5倍,因为用户更容易在阅读时点击内嵌引用。可见性与点击率的关系并不线性——被引用只有在用户点击时才有价值,这取决于引用位置、平台和语境。
品牌权威性会随时间累积:在多个AI平台持续被引用的来源,会形成更强的权威信号,从而提升传统搜索排名和未来AI引用概率,形成良性循环。竞争优势则属于率先优化AI引用的品牌——率先部署schema和结构优化的内容,目前获得了超额引用份额。SEO影响也超越AI:为AI引用优化的内容往往在传统搜索中表现更佳,因为结构清晰和权威信号对两者同样有效。AmICited的价值也愈发突出:在AI主导的信息发现环境下,不知道自己是否被引用,就像不知道自己的搜索排名一样,是可见性策略的巨大盲区。
优化AI引用需要内容结构和创作方式的具体调整。最有效的做法包括:
坚持这些做法的内容创作者,3-6个月内引用率可提升40-60%,引荐流量和品牌权威性同步增长。
引用监测已非可选项,而是理解AI主导发现环境下可见性的基础设施。监测意义很直观:你无法优化无法衡量的内容,而AI系统与平台不断演变,引用模式也随之变化。需跟踪的指标包括引用频次(被引用多少次)、引用位置(内嵌或来源列表)、平台分布(哪些平台引用最多)、查询语境(何种主题触发引用)、流量归因(AI引用带来多少引荐流量)等。
发现机会需要分析引用缺口:哪些主题竞争对手被引用而你没有,在哪些平台曝光不足,哪类内容表现不佳。这能揭示具体优化方向——比如你的操作指南因缺少schema未被引用,或你的研究内容因结构不便于内嵌提取而未出现在Perplexity。
AmICited解决了监测难题,能实时追踪你在ChatGPT、Perplexity、Gemini、Claude等主流AI平台的被引用情况。无需反复手动查询,AmICited自动监测引用模式,及时提醒新引用,并提供竞争对标数据,展示你的引用表现与同行的对比。对内容创作者、市场营销和SEO人员而言,AmICited让引用监测从手工、耗时的流程变为自动化、可洞察的系统。在AI主导的信息发现环境下,了解内容被引用的位置,已和了解搜索排名一样重要——AmICited让这种可见性得以大规模实现。
模型原生答案来自训练期间学习到的模式,而RAG在生成答案前会检索实时数据。RAG通常能提供更好的引用,因为它以具体来源为基础,使回应更透明、可追溯,对用户和内容创作者都更友好。
不同平台采用不同的架构。Perplexity和Gemini优先采用带有引用的RAG,而ChatGPT默认使用模型原生生成,除非开启了浏览功能。每个平台的设计理念和对透明度的追求决定了这一选择。
结构清晰、直接回答、合理标题和schema标记完善的内容,更容易被AI系统提取。以答案为先、善用列表和表格的内容更可能被引用,因为AI更容易解析和归属。
schema标记帮助AI系统理解内容结构和实体关系,从而更容易准确归属和引用您的内容。合理的schema实现会提高被引用概率,也有助于AI验证内容的可信度。
可以。注重以答案为先的结构、清晰的格式、事实准确、来源可靠和schema实现。监测您的引用,并根据表现数据持续优化,提高AI可见性。
像AmICited这样的工具可以监测您的品牌在ChatGPT、Perplexity、Google AI Overviews等平台上的被提及情况,直观展示您在AI回答中的引用方式和位置,助力优化。
尽管AI引用不会直接影响Google排名,但能提升品牌可见性和权威信号。被AI引用能带来流量并增强线上影响力,间接带来SEO收益。
两者互为补充。传统SEO专注于搜索结果排名,AI引用优化专注于出现在AI生成答案中。两种方法对现代信息发现环境下的全面可见性都很重要。
了解ChatGPT、Perplexity和Gemini等AI模型如何选择被引用的来源。理解AI引用机制、排名因素以及AI可见性优化策略。
了解知识库如何通过 RAG 技术提升 AI 的引用能力,实现 ChatGPT、Perplexity 和 Google AI 等平台的准确来源归属。
学习经验证的方法,让你的内容在ChatGPT、Perplexity及其他AI搜索引擎生成的答案中首当其冲地被引用。了解引用排名因素及优化技巧。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.