

如何在服务器日志中识别AI爬虫
学习如何在服务器日志中识别并监控如 GPTBot、ClaudeBot 和 PerplexityBot 等AI爬虫。完整指南涵盖 user-agent 字符串、IP 验证及实用监控策略。...
2 分钟阅读
AI爬虫已成为网络流量的重要组成部分,主要AI公司部署了先进的机器人,用于内容抓取以进行训练和检索。这些爬虫以极大规模运作,每月约在全网产生5.69亿次请求,全球带宽消耗超过30TB。主要AI爬虫包括GPTBot(OpenAI)、ClaudeBot(Anthropic)、PerplexityBot(Perplexity AI)、Google-Extended(Google)和Amazonbot(Amazon),它们各自有不同的抓取模式和资源需求。理解这些爬虫的行为和特性对于网站管理员合理管理服务器资源、制定访问策略至关重要。
| 爬虫名称 | 公司 | 目的 | 请求模式 |
|---|---|---|---|
| GPTBot | OpenAI | 用于ChatGPT和GPT模型的训练数据 | 激进、高频请求 |
| ClaudeBot | Anthropic | 用于Claude AI模型的训练数据 | 频率适中,爬取较为礼貌 |
| PerplexityBot | Perplexity AI | 实时搜索与答案生成 | 中高频率 |
| Google-Extended | AI功能的扩展索引 | 可控,遵循robots.txt | |
| Amazonbot | Amazon | 产品与内容索引 | 可变,侧重电商内容 |
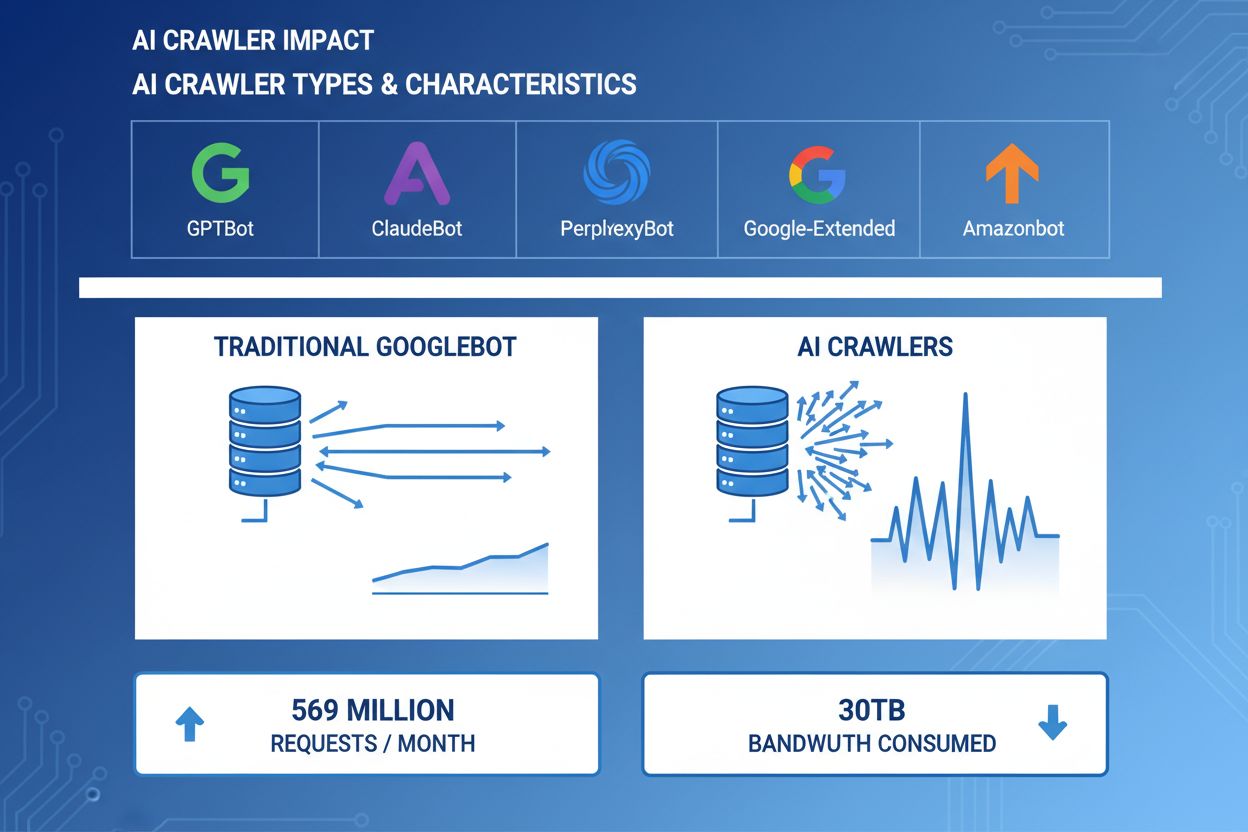
AI爬虫从多个维度消耗服务器资源,对基础设施性能造成可观影响。在爬虫活动高峰期,CPU使用率可能飙升300%以上,因为服务器需处理数千并发请求及HTML解析。带宽消耗是最直观的成本,受欢迎的网站每天可能向爬虫传输数GB数据。内存消耗显著增加,因服务器需维护连接池并缓存大量处理数据。数据库查询量倍增,爬虫请求页面会触发动态内容生成,带来额外I/O压力。对于内容库较大的站点,服务器为爬虫请求读取存储文件时,磁盘I/O会成为瓶颈。
| 资源 | 影响 | 真实案例 |
|---|---|---|
| CPU | 抓取高峰期飙升200-300% | 服务器平均负载从2.0升至8.0 |
| 带宽 | 占月总流量的15-40% | 500GB站点每月为爬虫服务150GB |
| 内存 | RAM消耗提升20-30% | 8GB服务器爬虫活跃时需10GB |
| 数据库 | 查询负载增加2-5倍 | 查询响应时间从50ms增至250ms |
| 磁盘I/O | 持续高读操作 | 磁盘利用率从30%跃升至85% |
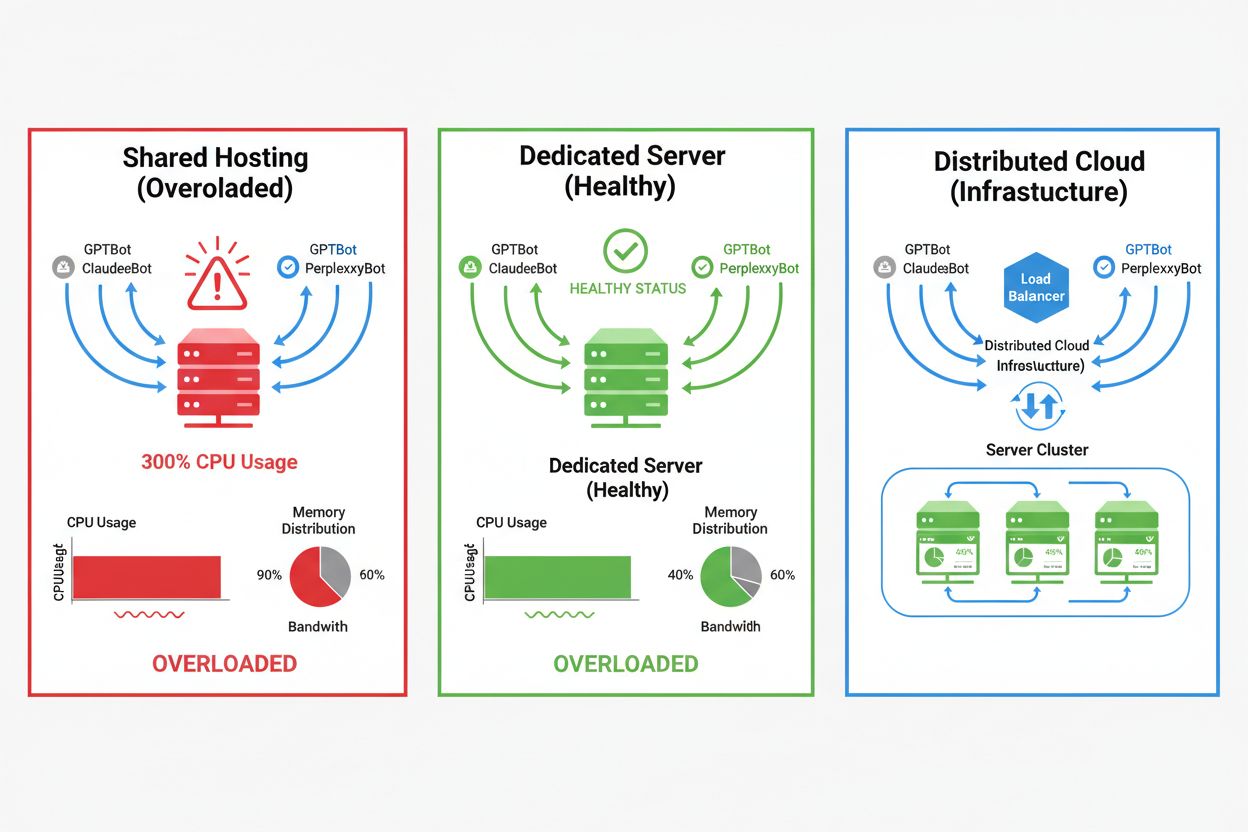
AI爬虫的影响因托管环境而异,其中共享主机环境受影响最为严重。在共享主机场景下,“吵闹邻居效应”尤为突出——当某个站点吸引大量爬虫流量时,会消耗本可分配给其他站点的资源,导致所有用户性能下降。独立服务器和云基础设施提供了更好的隔离与资源保障,使你能承受爬虫流量而不影响其他服务。但即使是独立基础设施,也需谨慎监控与扩容以应对多AI爬虫的叠加负载。
不同托管环境的主要区别:
AI爬虫流量的经济影响不仅限于直接带宽费用,还包括隐藏成本,显著影响你的利润。直接成本包括主机商因带宽用量增加而收取的额外费用,可能每月增加数百甚至数千美元,具体取决于流量和爬虫强度。隐藏成本体现在基础设施升级——你可能需升级更高档主机方案,增加缓存层,或为应对爬虫专门引入CDN服务。ROI计算变得复杂,因为AI爬虫对你的业务直接价值很低,却消耗了本可服务付费客户或提升用户体验的资源。许多网站主发现,容纳爬虫流量的成本超过了AI模型训练或AI搜索可见性带来的潜在收益。
AI爬虫流量直接通过消耗服务器资源,降低了真实访客的用户体验。Core Web Vitals指标会明显下降,在爬虫高发时,最大内容绘制(LCP)增加200-500ms,首字节时间(TTFB)延迟100-300ms。这些性能下降引发连锁负面效应:页面变慢降低用户参与度,提升跳出率,最终使电商及获客网站转化率下降。搜索排名也会受影响,因为Google排名算法将Core Web Vitals纳入考量,形成爬虫流量间接损害SEO的恶性循环。用户遭遇慢加载更易放弃访问转投竞争对手,直接影响收入和品牌口碑。
高效管理AI爬虫流量的第一步是全面监控与检测,理解问题规模后再实施对策。大多数Web服务器会记录user-agent字符串,标明每次请求的爬虫身份,为流量分析和过滤决策奠定基础。服务器日志、分析平台和专用监控工具可解析这些user-agent,识别和量化爬虫流量模式。
主要检测方法与工具:
防御过量AI爬虫流量的第一道防线,是配置合理的robots.txt文件,明确控制爬虫对你网站的访问。该文本文件放在网站根目录,可禁止特定爬虫、限制抓取频率、引导爬虫只抓取你希望收录的sitemap。应用层或服务器级的限速机制是另一保护手段,可按IP或user-agent对请求限流,防止资源耗尽。这些策略非阻断式且可逆,适合在采用更激进措施前作为起点。
# robots.txt - 屏蔽AI爬虫,允许合法搜索引擎
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# 允许Google与Bing
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# 对其他所有机器人设置抓取延迟
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
Web应用防火墙(WAF)和内容分发网络(CDN)通过行为分析和智能过滤,为爬虫流量提供企业级高级防护。Cloudflare及类似CDN厂商内置机器人管理功能,可基于行为模式、IP信誉和请求特征自动识别并拦截AI爬虫,无需手动配置。WAF规则可针对可疑请求发起验证,对特定user-agent限速,或直接屏蔽已知爬虫IP段。这些防护在边缘节点完成,恶意流量在抵达源站前就被过滤,大大降低基础设施负载。WAF和CDN方案的优势在于其能自适应新型爬虫和变化的攻击模式,无需频繁手动更新配置。
是否屏蔽AI爬虫需权衡保护服务器资源与保持AI搜索结果可见性之间的利弊。屏蔽所有AI爬虫会让你的内容无法出现在ChatGPT搜索、Perplexity AI答案等AI驱动的发现机制中,可能减少推荐流量与品牌曝光。而不限制爬虫访问则会消耗大量资源,降低用户体验,却未必为你的业务带来实质好处。最优策略应视实际情况而定:流量大、资源充足的网站可选择允许爬虫,资源有限者则应优先保障用户体验,屏蔽或限速爬虫。决策应结合所属行业、目标用户、内容类型和业务目标,而非一刀切。
如选择容纳AI爬虫流量,扩展基础设施是兼顾性能与负载的路径。纵向扩容——升级更高CPU、RAM和带宽的服务器——简单但成本高,且有物理上限。横向扩容——通过负载均衡器分流到多台服务器——长期更具可扩展性和弹性。AWS、Google Cloud和Azure等云平台提供自动扩容能力,流量高峰时自动增加资源,低谷时缩减,降低成本。CDN可将静态内容缓存于边缘节点,减轻源站负载,提高真人与爬虫的访问性能。数据库优化、查询缓存和应用级改进也能降低单请求资源消耗,无需额外扩充硬件。
在持续AI爬虫流量压力下,持续监控与优化对保持最佳性能至关重要。专用工具可让你洞察爬虫活动、资源消耗和性能指标,使爬虫管理策略决策更有数据支撑。从一开始就部署全面监控,能建立基线、发现趋势、衡量缓解措施的效果。
核心监控工具与实践:
AI爬虫管理格局持续演变,新标准和行业举措正重塑网站与AI公司的互动。llms.txt标准为AI公司提供内容使用权和偏好等结构化信息,或许能成为比一刀切允许/屏蔽更细致的选择。行业对补偿模式的讨论表明,未来AI公司或将为训练数据向网站付费,从根本上改变爬虫流量的经济学。要让基础设施适应未来,需要持续关注新标准、跟进行业动态,并保持灵活的爬虫管理政策。与AI公司建立关系、参与行业讨论并争取公平补偿,将随着AI日益成为网络发现和内容消费核心而愈发重要。在这一变化中脱颖而出的网站,必然是那些在创新与务实间找到平衡,既保护自身资源,又不失开放姿态迎接可贵曝光与合作机会的企业。
AI爬虫(GPTBot、ClaudeBot)提取内容用于LLM训练,通常不会带来流量回访。搜索爬虫(Googlebot)为搜索可见性建立索引,通常会带来推荐流量。AI爬虫操作更为激进,批量请求更大,且常常无视节省带宽的指令。
真实案例显示,单个爬虫每月可消耗30TB以上。消耗量取决于网站规模、内容体量和爬虫频率。仅OpenAI的GPTBot在Vercel网络上单月就产生了5.69亿次请求。
屏蔽AI训练爬虫(GPTBot、ClaudeBot)不会影响Google排名。但屏蔽AI搜索爬虫可能会减少在如Perplexity或ChatGPT搜索等AI驱动搜索结果中的可见性。
注意异常的CPU飙升(300%以上)、带宽使用量增加但真人访客不变、页面加载变慢,以及服务器日志中异常的user-agent字符串。Core Web Vitals指标也可能显著下降。
对于受爬虫流量影响较大的站点,独立主机能提供更好的资源隔离、控制和成本可预见性。共享主机环境会受“吵闹邻居”影响,一个站点的爬虫流量会影响所有托管站点。
使用Google Search Console获取Googlebot数据,服务器访问日志用于详细流量分析,CDN分析(如Cloudflare),以及AmICited.com等专用平台来全面监控和跟踪AI爬虫。
可以,通过robots.txt指令、WAF规则和基于IP的过滤。你可以允许有益的爬虫如Googlebot,同时通过针对user-agent的规则屏蔽消耗资源大的AI训练爬虫。
比较实施爬虫控制前后的服务器指标。监控Core Web Vitals(LCP、TTFB)、页面加载时间、CPU使用率和用户体验指标。Google PageSpeed Insights和服务器监控平台能提供详细洞察。
学习如何在服务器日志中识别并监控如 GPTBot、ClaudeBot 和 PerplexityBot 等AI爬虫。完整指南涵盖 user-agent 字符串、IP 验证及实用监控策略。...

了解影响你在ChatGPT、Perplexity和Google AI模式等AI搜索引擎中可见性的关键技术性SEO因素。学习页面速度、schema标记、内容结构和基础设施如何影响AI引用。...
了解如何在服务器日志中识别并监控GPTBot、PerplexityBot和ClaudeBot等AI爬虫。发现User-Agent字符串、IP验证方法以及跟踪AI流量的最佳实践。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.